На Хабрахабре Tmux (ти-макс) упоминался неоднократно, тем не менее, решил написать еще одну шпаргалку, т.к. в других некоторые важные моменты не показаны.
Tmux (терминальный мультиплексор) позволяет работать с несколькими сессиями в 1 окне. Вместо нескольких окон терминала к серверу — вы можете использовать одно. Позволяет подключаться/отключаться к текущему состоянию сессии. Запущенные программы и процессы продолжают работать. (Можно использовать вместо nohup, dtach).
Например, на работе правим файлы в Vim. Окно терминала с открытыми файлами, процессами. Отключаемся от сессии. Далее подключаемся к этой сессии из дома и получаем те же окна с открытыми файлами в Vim, процессами и т.д. Можно продолжить работу с того же момента, на котором остановились. Также удобно при разрыве связи. Дополнительно можно работать совместно с другими в терминале, если подключены к одной сессии. Каждый видит, что делает другой.
Попытка заглянуть вглубь hashCode() привела к спелеологическому путешествию по исходному коду JVM, с рассмотрением структуры объектов и привязанной блокировки (biased locking), а также удивительных последствий для производительности, связанных с использованием hashCode() по умолчанию.
Это перевод обзора статьи «MemC3: Compact and Concurrent MemCache with Dumber Caching and Smarter Hashing» Fan et al. в Proceedings of the 10th USENIX Symposium on Networked Systems Design and Implementation (NSDI’13), pdf тут
Чуваки (бывший гугловец, чувак из университета Карнеги Меллон и еще один из Интел лабс) сделали улучшенный Memcached-совместимый кеш (по факту просто допилили мемкеш), и у них классные результаты производительности. Мне очень понравился обзор этой статьи в блоге "The morning paper" — описание алгоритмов и прочее.
abstract: разница между текущей производительностью и производительностью теоретической; latency и IOPS, понятие независимости дисковой нагрузки; подготовка тестирования; типовые параметры тестирования; практическое copypaste howto.
Предупреждение: много букв, долго читать.
Лирика
Очень частой проблемой, является попытка понять «насколько быстрый сервер?» Среди всех тестов наиболее жалко выглядят попытки оценить производительность дисковой подсистемы. Вот ужасы, которые я видел в своей жизни:
научная публикация, в которой скорость кластерной FS оценивали с помощью dd (и включенным файловым кешем, то есть без опции direct)
использование bonnie++
использование iozone
использование пачки cp с измерениема времени выполнения
использование iometer с dynamo на 64-битных системах
Это всё совершенно ошибочные методы. Дальше я разберу более тонкие ошибки измерения, но в отношении этих тестов могу сказать только одно — выкиньте и не используйте.
На сегодняшний день процедура реализации «failover» в Postgresql является одной из самых простых и интуитивно понятных. Для ее реализации необходимо определиться со сценариями файловера — это залог успешной работы кластера, протестировать его работу. В двух словах — настраивается репликация, чаще всего асинхронная, и в случае отказа текущего мастера, другая нода(standby) становится текущем «мастером», другие ноды standby начинают следовать за новым мастером.
На сегодняшний день repmgr поддерживает сценарий автоматического Failover — autofailover, что позволяет поддерживать кластер в рабочем состоянии после выхода из строя ноды-мастера без мгновенного вмешательства сотрудника, что немаловажно, так как не происходит большого падения UPTIME. Для уведомлений используем telegram.
Появилась необходимость в связи с развитием внутренних сервисов реализовать систему хранения БД на Postgresql + репликация + балансировка + failover(отказоустойчивость). Как всегда в интернете вроде бы что то и есть, но всё оно устаревшее или на практике не реализуемое в том виде, в котором оно представлено. Было решено представить данное решение, чтобы в будущем у специалистов, решивших реализовать подобную схему было представление как это делается, и чтобы новичкам было легко это реализовать следуя данной инструкции. Постарались описать все как можно подробней, вникнуть во все нюансы и особенности.
Про собеседования и найм сотрудников написано безумное количество книг, статей, блогов и прочих вместилищ информации. Да только информация эта до сих пор дошла не до всех в ней нуждающихся. Посему, хочется в очередной раз сказать пару слов о процессе найма.
Зачем всё это? Хочу перечислить основные косяки обеих сторон, вовлечённых в процесс трудоустройства в виде назиданий и советов не претендующих на истинность, а являющихся личным мнением автора. Все пункты опробованы на себе, то есть в большинство из них так или иначе вляпался по собственной дурости, либо по милости противоположной стороны. Плюс к этому, некоторые ситуации проходил с двух сторон: и как соискатель и как наниматель. Посему, есть с чем сравнить. Так же, некоторые пункты могут показаться читателю очевидными и «капитанскими», но, увы, многие до сих пор не знают о них и делают с точностью до наоборот. Как говорится: «то, что очевидно для вас, не очевидно для других».
В общем, если интересен чужой опыт и грабли — прошу под кат.
Облачные файловые хранилища продолжают набирать популярность, и требования к ним продолжают расти. Современные системы уже не в состоянии полностью удовлетворить все эти требования без значительных затрат ресурсов на поддержку и масштабирование этих систем. Под системой я подразумеваю кластер с тем или иным уровнем доступа к данным. Для пользователя важна надежность хранения и высокая доступность, чтобы файлы можно было всегда легко и быстро получить, а риск потери данных стремился к нулю. В свою очередь для поставщиков и администраторов таких хранилищ важна простота поддержки, масштабируемость и низкая стоимость аппаратных и программных компонентов.
Знакомьтесь: Ceph
Ceph — это программно определяемая распределенная файловая система с открытым исходным кодом, лишенная узких мест и единых точек отказа, которая представляет из себя легко масштабируемый до петабайтных размеров кластер узлов, выполняющих различные функции, обеспечивая хранение и репликацию данных, а также распределение нагрузки, что гарантирует высокую доступность и надежность. Система бесплатная, хотя разработчики могут предоставить платную поддержку. Никакого специального оборудования не требуется.
При выходе любого диска, узла или группы узлов из строя Ceph не только обеспечит сохранность данных, но и сам восстановит утраченные копии на других узлах до тех пор, пока вышедшие из строя узлы или диски не заменят на рабочие. При этом ребилд происходит без секунды простоя и прозрачно для клиентов.
Ранее в блоге на Хабре мы рассказывали о развитии нашего продукта — биллинга для операторов связи «Гидра», а также рассматривали вопросы работы с инфраструктурой и использования новых технологий. К примеру, мы рассмотрели плюсы Clojure и ситуации, когда стоит и не стоит использовать MongoDB.
Сегодня речь пойдет о работе с JSON, и в частности, о применении ограничений. Интересный материал на эту тему опубликовал в своем блоге разработчик Магнус Хагандер (Magnus Hagander) — мы представляем вашему вниманию главные мысли этого материала.
Проблемы трассировки и профилирования ядра мы уже затрагивали в предыдущих публикациях. Для анализа событий на уровне ядра существует много специализированных инструментов: SystemTap, Ktap, Sysdig, LTTNG и другие. Об этих инструментах опубликовано много подробных статей и обучающих материалов.
Гораздо меньше информации можно найти о «родных» механизмах Linux, с помощью которых можно отслеживать системные события, получать и анализировать отладочную информацию. Эту тему мы хотели бы рассмотреть в сегодняшней статье. Особое внимание мы уделим ftrace — первому и пока что единственному инструменту трассировки, добавленному в ядро. Начнём с определения основных понятий.
Насколько объектно Go ориентирован многократно и эмоционально обсуждалось. Попробуем теперь оценить насколько он функционален. Заметим сразу, оптимизацию хвостовой рекурсии компилятор не делает. Почему бы? «Это не нужно в языке с циклами. Когда программист пишет рекурсивный код, он хочет представлять стек вызовов или он пишет цикл.» — замечает в переписке Russ Cox. В языке зато есть полноценные lambda, closure, рекурсивные типы и ряд особенностей. Попробуем их применить функциональным манером. Примеры покажутся синтетическими оттого, что во первых написаны немедленно исполняемыми в песочнице и написаны на процедурном все же языке во вторых. Предполагается знакомство как с Go так и с функциональным программированием, разъяснений мало но код комментирован.
В неформальной беседе директор по распространению технологий компании Yandex рассказал студентам Университета Иннополис о нейронных сетях, технологиях будущего и объяснил, почему создание Self-Driving Car — уже скучная задача. Содержательная беседа о мире ИТ, современных знаниях и фантастах прошлого столетия. Всё это в одной лекции, которую обязательно нужно посмотреть!
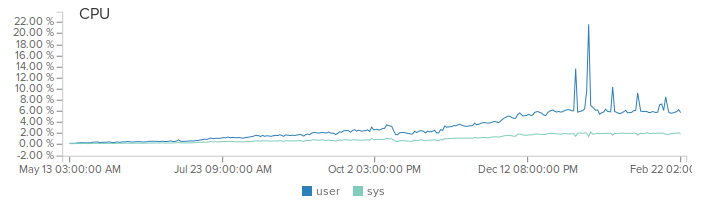
Всем привет. Эта статья продолжение 10к на ядро с конкретными примерами оптимизаций, которые были проделаны для повышения производительности сервера. С написания первой части прошло уже 5 мес и за это время нагрузка на наш продакшн сервер выросла с 500 рек-сек до 2000 с пиками до 5000 рек-сек. Благодаря netty, мы даже не заметили это повышение (разве что место на диске уходит быстрее).
(Не обращайте внимание на пики, это баги при деплое)
Эта статья будет полезна всем тем кто работает с netty или только начинает. Итак, поехали.
Нативный Epoll транспорт для Linux
Одна из ключевых оптимизаций, которую стоит использовать всем — это подключение нативного Epoll транспорта вместо реализации на java. Тем более, что с netty это означает добавить лишь 1 зависимость:
и автозаменой по коду осуществить замену следующих классов:
NioEventLoopGroup → EpollEventLoopGroup
NioEventLoop → EpollEventLoop
NioServerSocketChannel → EpollServerSocketChannel
NioSocketChannel → EpollSocketChannel
Дело в том, что java реализация для работы с не блокирующими сокетами реализуется через класс Selector, который позволяет вам эффективно работать с множеством соединений, но его реализация на java не самая оптимальная. Сразу по трем причинам:
Метод selectedKeys() на каждый вызов создает новый HashSet
Итерация по этому множеству создает iterator
И ко всему прочему внутри метода selectedKeys() огромное количество блоков синхронизации
В моем конкретном случае я получил прирост производительности около 30%. Конечно же, эта оптимизация возможна только для Linux серверов.
Год подходит к концу, впереди длинные каникулы. Для многих каникулы — это отличная возможность посидеть и посмотреть вокруг, что же у нас нового и интересного происходит нынче в профессиональном джавовском мире.
В апреле в Москве мы провели в Москве большую Java-конференцию — JPoint 2015. Конференция собрала более тысячи разработчиков на площадке, еще несколько сотен — смотрели конференцию онлайн. Мы экспериментировали и с открытием (лекция Дмитрия Галкина о современном искусстве и программировании действительно шокировала многих) и с новыми форматами (круглые столы и экспертные дискуссии). Но ключевой темой конференции были и остаются доклады.
Видеозаписи всех докладов конференции лежат на Youtube. Мы, как всегда, собрали статистику из отзывов участников и посчитали рейтинг докладов. В этом посте — традиционный обзор лучших докладов конференции. Я сделаю короткий обзор десяти лучших докладов конференции с тем, чтобы вы немного больше знали о них и посмотрели именно то, что интересно вам.
Итак, поехали.
10 место
Сергей Walrus Куксенко, Oracle — Железные счётчики на страже производительности
Средняя оценка: 4.28
Этот доклад получил специальный приз жюри в номинации «аццкий хардкор». Общая идея доклада сводится к следующему: представьте, что вы уже наоптимизировали в своем приложении все, что можно — посмотрели на сеть, ОС, JVM и т.д. и поняли, что все уперлось в процессор. После этого мы попрофилировали, работать стало быстрее, но все равно процессор загружен на 100%. Что делать?
Оказывается, внутри процессора есть разные счетчики событий. Называется этот механизм Hardware Performance Counters. Архитектура современных процессоров очень сложна, в них может происходить очень много разного. Фокус в том, что мы можем включить некоторые счетчики внутри процессора, которые будут считать количество произошедших событий. То есть, некоторый железный профилировщик внутри процессора.
Какие именно события умеет считать этот процессорный профилировщик? Да практически любые. В современных интеловских процессорах, по утверждению Сергея, их около тысячи. Если вы хотите понять, какие события надо смотреть в первую очередь, куда вообще копать и какие с этим возникают трудности — обязательно посмотрите этот доклад.
В этом году Сергей снова прилетит к нам в Москву — правда уже не из Питера, а из Калифорнии. С темой он определится в январе. Скорее всего это будет снова что-то про оптимизацию производительности.
Наблюдать за развитием разных баз данных — увлекательное занятие, особенно — если понимаешь подводные течения. Одно из самых сильных сообществ вокруг СУБД в России — это PostgreSQL-сообщество. Две тематические конференции в год, консалтинговая компания и даже компания-разработчик модулей к PostgreSQL.
Руководитель и идеолог международного сообщества, Брюс Момжан, вот уже какой год приезжает к нам на HighLoad++. Этот год не исключение, Брюс будет рассказывать про «Upcoming PostgreSQL Features» — кому рассказывать про будущее этой СУБД, как не Брюсу?
Почему же, несмотря на такую активность, это база данных по-прежнему далеко не так распространена, как, например «базулька» MySQL. В чем подвох? Эту тему мы активно обсуждали на конференции PGDay'15, которую организовал один из докладчиков HighLoad++ Илья Космодемьянский.
Для начала небольшое исследование:
Крупнейшие платные CMS в России (Битрикс, Netcat, UMI) не поддерживают PostgreSQL;
Самые популярные бесплатные CMS (Wordpress, Drupal, Joomla) тоже (или поддерживают с трудом или поддерживают недавно);
Только каждый третий хостинг провайдер предлагает поддержку PostgreSQL.
До недавнего времени в Одноклассниках в качестве основного Linux-дистрибутива использовался частично обновлённый OpenSuSE 10.2. Однако, поддерживать его становилось всё труднее, поэтому с прошлого года мы перешли к активной миграции на CentOS 7. На подготовительном этапе перехода для CentOS были отработаны все внутренние процедуры, подготовлены конфиги и политики настройки (мы используем CFEngine). Поэтому сейчас во многих случаях миграция с одного дистрибутива на другой заключается в установке ОС через kickstart и развёртывании приложения с помощью системы деплоя нашей разработки — всё остальное осуществляется без участия человека. Так происходит во многих случаях, хотя и не во всех.
Но с самыми большими проблемами мы столкнулись при миграции серверов раздачи видео. На их решение у нас ушло полгода.
Моя статья расскажет Вам как принять 10 миллионов пакетов в секунду без использования таких библиотек как Netmap, PF_RING, DPDK и прочие. Делать мы это будем силами обычного Линукс ядра версии 3.16 и некоторого количества кода на С и С++.
Сначала я хотел бы поделиться парой слов о том, как работает pcap — общеизвестный способ захвата пакетов. Он используется в таких популярных утилитах как iftop, tcpdump, arpwatch. Кроме этого, он отличается очень высокой нагрузкой на процессор.
Итак, Вы открыли им интерфейс и ждете пакетов от него используя обычный подход — bind/recv. Ядро в свою очередь получает данные из сетевой карты и сохраняет в пространстве ядра, после этого оно обнаруживает, что пользователь хочет получить его в юзер спейсе и передает через аргумент команды recv, адрес буфера куда эти данные положить. Ядро покорно копирует данные (уже второй раз!). Выходит довольно сложно, но это не все проблемы pcap.
Кроме этого, вспомним, что recv — это системный вызов и вызываем мы его на каждый пакет приходящий на интерфейс, системные вызовы обычно очень быстры, но скорости современных 10GE интерфейсов (до 14.6 миллионов вызовов секунду) приводят к тому, что даже легкий вызов становится очень затратным для системы исключительно по причине частоты вызовов.
Также стоит отметить, что у нас на сервере обычно более 2х логических ядер. И данные могут прилететь на любое их них! А приложение, которое принимает данные силами pcap использует одно ядро. Вот тут у нас включаются блокировки на стороне ядра и кардинально замедляют процесс захвата — теперь мы занимаемся не только копированием памяти/обработкой пакетов, а ждем освобождения блокировок, занятых другими ядрами. Поверьте, на блокировки может зачастую уйти до 90% процессорных ресурсов всего сервера.
Хороший списочек проблем? Итак, мы их все геройски попробуем решить!
Последние пару лет я пишу под ядро Linux и часто вижу, как люди страдают от незнания давнишних, общепринятых и (почти) удобных инструментов. Например, как-то раз мы отлаживали сеть на очередной реинкарнациинашего прибора и пытались понять, что за чудеса происходят с обработкой пакетов. Первым нашим позывом было открыть исходники ядра и вставить в нужные места printk, собрать логи, обработать их каким-нибудь питоном и потом долго думать. Но не зря я читал lwn.net. Я вспомнил, что в ядре есть готовые и прекрасно работающие механизмы трассировки и профилирования ядра: те базовые механизмы, с помощью которых вы сможете собирать какие-то показания из ядра, а затем анализировать их.
В статье я расскажу как реализовать файловую систему в юзерспейсе на Java, без строчки ядерного кода. А также покажу как связать Java и нативный код без написания кода на C, при этом сохранив максимальную производительность.
Недавно, во время собеседования в одну крупную компанию мне задали простой вопрос, что такое Load Average. Не знаю, на сколько правильно я ответил, но лично для себя пришло осознание, что точного ответа я на самом деле и не знаю.
Большинство людей наверняка знают, что Load Average — это среднее значение загрузки системы за некоторый период времени (1, 5 и 15 минут). Так же можно узнать некоторые подробности из данной статьи, про то, как этим пользоваться. В большинстве случаев этих знаний достаточно для того, что бы по значению LA оценивать загрузку системы, но я по специальности физик, и когда я вижу «среднее за промежуток времени» мне сразу становится интересна частота дискретизации на данном промежутке. А когда я вижу термин «ожидающие ресурсов», становится интересно, каких именно и сколько времени надо ждать, а так же сколько тривиальных процессов надо запустить, что бы получить за короткий промежуток времени высокий LA. И главное, почему ответы на эти вопросы не дает 5 минут работы с гуглом? Если вам данные тонкости так же интересны, добро пожаловать под кат.
После прочтения статьи на Хабре «Делаем ИК-пульт ДУ для фотоаппарата», захотелось поделиться опытом разработки ИК-пульта ДУ для фотоаппаратов в виде приложения под Android (от идеи до публикации).