
Продолжаем изучать исходный код PostgreSQL
В этот раз исследуем главный цикл сервера:
- Принятие входящих подключений;
- Проверка окружения;
- Обработка упавших воркеров.

User
Продолжаем изучать исходный код PostgreSQL
В этот раз исследуем главный цикл сервера:
- Принятие входящих подключений;
- Проверка окружения;
- Обработка упавших воркеров.

Привет, Хабр! Меня зовут Антон, я – старший разработчик в отделе разработки баз данных в IBS. В этой статье я расскажу о том, как нашей командой была решена задача по сохранению в ClickHouse большого количества данных, генерируемых веб-приложением, с последующим получением сохранённых данных в агрегированном виде.
Решение задачи, описанной выше, было бы простым и вряд ли заслуживающим отдельной статьи на Хабре. Но наш случай представлял собой ряд нюансов: здесь есть технические дубли записей и бизнес-дубли (обновления), есть агрегированные данные и необходимость обновления агрегированных данных. А это уже пример не совсем типичного использования ClickHouse, которым мы и хотим поделиться.

Как:
1. тестировать на продуктивных данных и не бояться
2. получить 100 копий продуктивной БД и не создавать 100 серверов
3. узнать какой будет план запроса на продуктиве
4. дать каждому разработчику свою БД с данными и не разориться на оплате дисков
Если вам это нужно и у вас PostgreSQL, то эта статья для вас.

Это вторая часть моих копаний во внутренностях MySQL. В первой части [habr] были затронуты запись страниц данных на диск (с промежуточной записью в DoubleWrite buffer) и запись бинлогов (с батчингом в виде group commit). В этой части я расскажу про redo log и как все части MySQL координируются для достижения надежной работы.

Apache Cassandra - это распределенная NoSQL база данных. В этой статье будут описаны основные механизмы передачи, репликации и поддержания согласованности данных внутри сети.

Меня зовут Азат Якупов, я люблю данные и люблю использовать их в разных задачах. Сегодня хочу поделиться своим опытом относительно B-Tree индексов в PostgreSQL. Рассмотрим их топологию, синтаксис, функциональные B-Tree индексы, условные B-Tree индексы и включенные B-Tree индексы.
QQ Хабр! В этом гайде мы пройдемся по каждому шагу создания ботов в Telegram - от регистрации бота до публикации репозитория на GitHub. Некоторым может показаться, что все разжевано и слишком много элементарной информации, но этот гайд создан для новичков, хотя будет интересен и для тех, кто уже занимался разработкой в Telegram. Сегодня мы будем делать бота, который отвечает на заданные вопросы.

Привет! Меня зовут Иван Пономарёв, я разработчик в Synthesized, преподаю в МФТИ и EEUAS. На этом митапе Росбанка и Jug.ru я расскажу о тестировании Kafka Streams и, в частности, об особенностях инструмента TopologyTestDriver. Этот доклад я подготовил совместно с Джоном Рослером (John Roesler), разработчиком из Confluent, коммитером и одним из продакт-менеджеров Apache Kafka.
Я работаю техническим писателем в компании documentat.io. Мы занимаемся заказной разработкой технической документации, в том числе на английском языке. Иногда я дорабатываю уже существующие документы или спецификации к API на английском. Как правило, такие документы написаны русскоязычными разработчиками, которые неплохо владеют английским. И всё же они часто допускают характерные грамматические, пунктуационные и стилистические ошибки.
Корень этих ошибок один — разные языковые механизмы. Нам бывает легко запутаться в употреблении временных форм, порядке слов или непонятно зачем придуманных артиклях.
Поэтому в этой статье я постарался не просто дать рекомендации о том, как можно избежать распространённых ошибок, но и подсветить те отличительные черты английского языка, которые к этим ошибкам приводят.
21 сентября 2022 г. Itzik Ben-Gan
SQL Server 2022 представляет набор новых функций и операторов для работы с битами, предназначенных для расширения этих возможностей, а также упрощает их и делает более интуитивно понятными.
В практике использования T-SQL не характерна манипуляция данными на битовом уровне, но иногда приходится сталкиваться с такой необходимостью. Можно встретить решения, в которых набор флагов (да/нет, вкл/выкл, истина/ложь) хранятся в одной целочисленной или двоичной колонке, где каждый бит представляет отдельный флаг. Одним из примеров является использование битового представления набора разрешений пользователя/роли. Другой пример — использование битового представления набора настроек, включенных или отключенных в данной среде. Даже SQL Server хранит некоторые данные на основе флагов, используя битовое представление.

Это четвертая, финальная часть из цикла статей про метрики. В первой — вводной — я рассказал, почему метрики для сервисов устроены именно так, чем они отличаются от логов, и какую задачу решают. Во второй разобрались с форматом и типами метрик. В третьей — с перцентилями. Теперь, наконец, можно пойти и вывести что-нибудь на графики! На этот раз будет более хардкорно.

В мире кровавого энтерпрайза есть некоторое количество проектов-мамонтов. Они большие, у них базы данных на SQL Server, в этих базах тысячи и десятки тысяч объектов, миллионы строк кода T-SQL, огромная вариативность данных, всё хрупкое, неидемпотентное, недетерминированное и фигово документированное. Короче, как писал Roy Osherove в своей The art of unit-testing:
Finally, as a friend once said, a good bottle of vodka never hurts when dealing with legacy code.
В вольном переводе "Да там без поллитры не разберёшься!"
И вот у этих проектов есть беда — большие контуры тестирования и разработки, часто так или иначе модифицированные и уменьшенные копии основного продуктового контура. Да-да-да, тут сразу поналетят умные да в белой одежде и начнут объяснять, что надо писать тестовые наборы данных (а кто спорит?), что тестовый контур должен быть небольшим (а кто спорит?), что код должен быть переносимым между СУБД (спасибо, Кэп!), что всё было бы лучше, если бы проект переписали N лет назад (ха-ха) и прочие "станьте ёжиками" и "пусть едят пирожные". Нет, дорогие мои. Просто представьте, что у вас есть БД SQL Server с 25К объектов (таблиц и ХП) и миллионами строк запросов, и часть объектов создана с SET ANSI NULLS ON, а часть с SET ANSI NULLS OFF. И точно известно, что в части запросов эта разница используется. И БД на десятки ТиБ. И однодневный простой системы стоит больше, чем квартиры всех разработчиков, которые за последние 20 лет трогали этот код (из которых, кстати, сейчас работает только 7 последних самураев). Одно это может не давать перейти с SQL Server 2008 R2 на что-то более свежее пару лет.

SQL — концептуально странный язык. Вы пишете ваше приложение на одном языке, скажем, на JavaScript, а затем направляете базе данных команды, написанные на совершенно другом языке — SQL. После этого база данных компилирует и оптимизирует эту команду на SQL, выполняет её и возвращает вам данные. Такой метод кажется ужасно неэффективным, но, всё-таки, ваше приложение может проделывать сотни таких операций в секунду. Просто безумие!
Но на самом деле всё ещё страннее.

Меня зовут Сергей Петренко, вот уже четыре года я работаю над репликацией в Tarantool, и сегодня хочу рассказать про слабые места алгоритма Raft и способы их преодоления. Эта статья — вольный пересказ нашего с Борисом Степаненко доклада на Hydra 2022. Если читатель не знаком с Raft, то предлагаю ознакомиться с моей статьёй о нём.

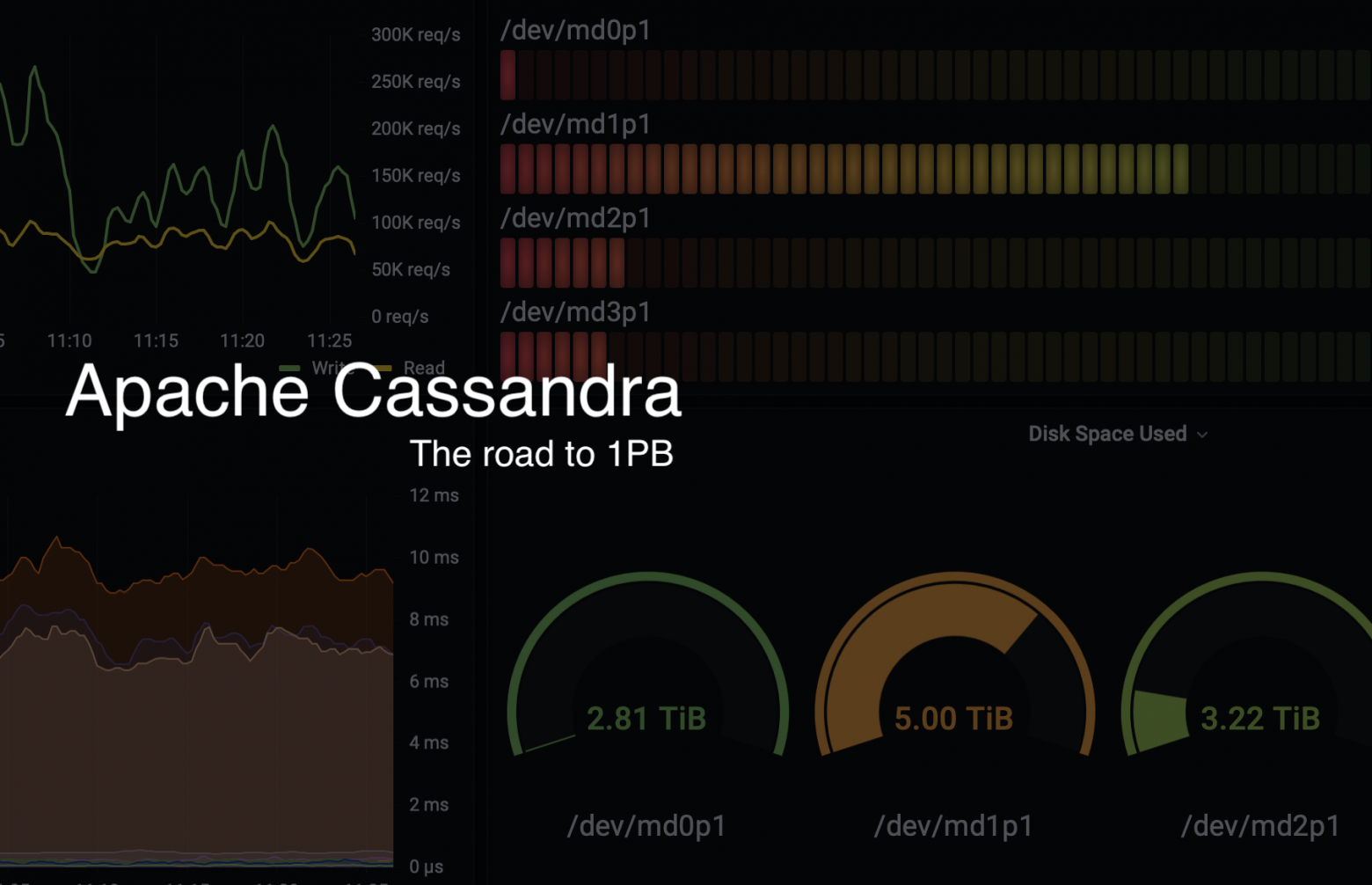
Центр Развития Перспективных Технологий - компания разработчик системы мониторинга товаров. Как IT компания с большим количеством данных мы используем множество NoSQL решений в своей повседневной работе. Одним из таких решений является Apache Cassandra.
Суммарно, во всех кластерах Cassandra мы храним 0.4PB данных при общей емкости 0.9PB, стабильно производим 0.7млн операций записи и доступа к данным и 1.1млн когда необходимо разогнаться в трудные времена, при этом продолжаем непрерывно расширяться.
Отсюда лежит и название статьи, к моменту публикации последней главы из цикла петабайтный барьер емкости будет взят.
Материал подразумевает, что вы уже начали знакомиться с этой замечательной базой данных, хотите найти примеры её использования в российском сегменте интернета и будет полезен тем, кто постоянно ищет способ обучиться за счёт чужих ошибок. Ошибок мы совершили не мало, добро пожаловать!

awk, а также увидите некоторые способы её использования при работе с текстом, включая вывод содержимого файла, а также его конкретных столбцов, строк и слов по указанным критериям. Приступим!
Как и у многих, в нашей компании возник вопрос импортозамещения. В целом вопрос понятный, много раз обсужденный со всех точек зрения. И вот настал счастливый момент, когда слова трансформировались в конкретные задачи с конкретными сроками. И одна из них была о замене СУБД для 1С.
Ну и конечно же, первым делом был поднят вопрос о кластеризации этой истории. Никто подвоха особого не ожидал, ибо у нас есть уже зарекомендовавшее себя решение в виде связки pg_auto_failover версии 1.6 от Citus (далее PGAF для краткости) и keepalived. Это решение нас целиком и полностью устраивает, поэтому выбор наш был очевиден.
Но когда мы начали настраивать выяснился очень неприятный момент - обычная сборка PGAF просто не работает с версией СУБД от PostgresPro - все ломается из-за жестко прописанных зависимостей. Тут то и началось "веселье".
Был вариант игнорировать зависимости, но в таком случае мы получаем проблемы при обновлении. В итоге нашли альтернативу - собрать из исходников самим, настраивая пути и зависимости самостоятельно, о чем и расскажу. В моем повествовании нет какой-то особой магии, но пару дней сберечь точно поможет.
Давным-давно, такие слова как "hot keys" и "keyboard shortcuts" мне не всегда удавалось перевести на русский без потери лица. Как-то раз, я написал "клавиатурные сокращения", чем сразу же привлёк косые взгляды и вызвал смелые медицинские фантазии... Но вроде бы сейчас принято везде говорить и писать "горячие клавиши". О них и поговорим.
Данная заметка — шпаргалка по линуксовой оболочке Bash. Если вам приходится часто иметь дело с терминалом в Linux (и вы не меняли Bash на другой шелл), то будет очень полезно использовать эти самые "сокращения" на благо себе и в мирных целях. Текст написан для начинающих пользователей, но кто знает — может быть и вы найдёте в нём что-то новое и полезное для себя.
Для удобства будем считать, что по умолчанию под терминалом мы понимаем стандартную в настольной редакции Ubuntu программу "Терминал Gnome".