Cassandra. The road to 1 PB (1/7)
Центр Развития Перспективных Технологий - компания разработчик системы мониторинга товаров. Как IT компания с большим количеством данных мы используем множество NoSQL решений в своей повседневной работе. Одним из таких решений является Apache Cassandra.
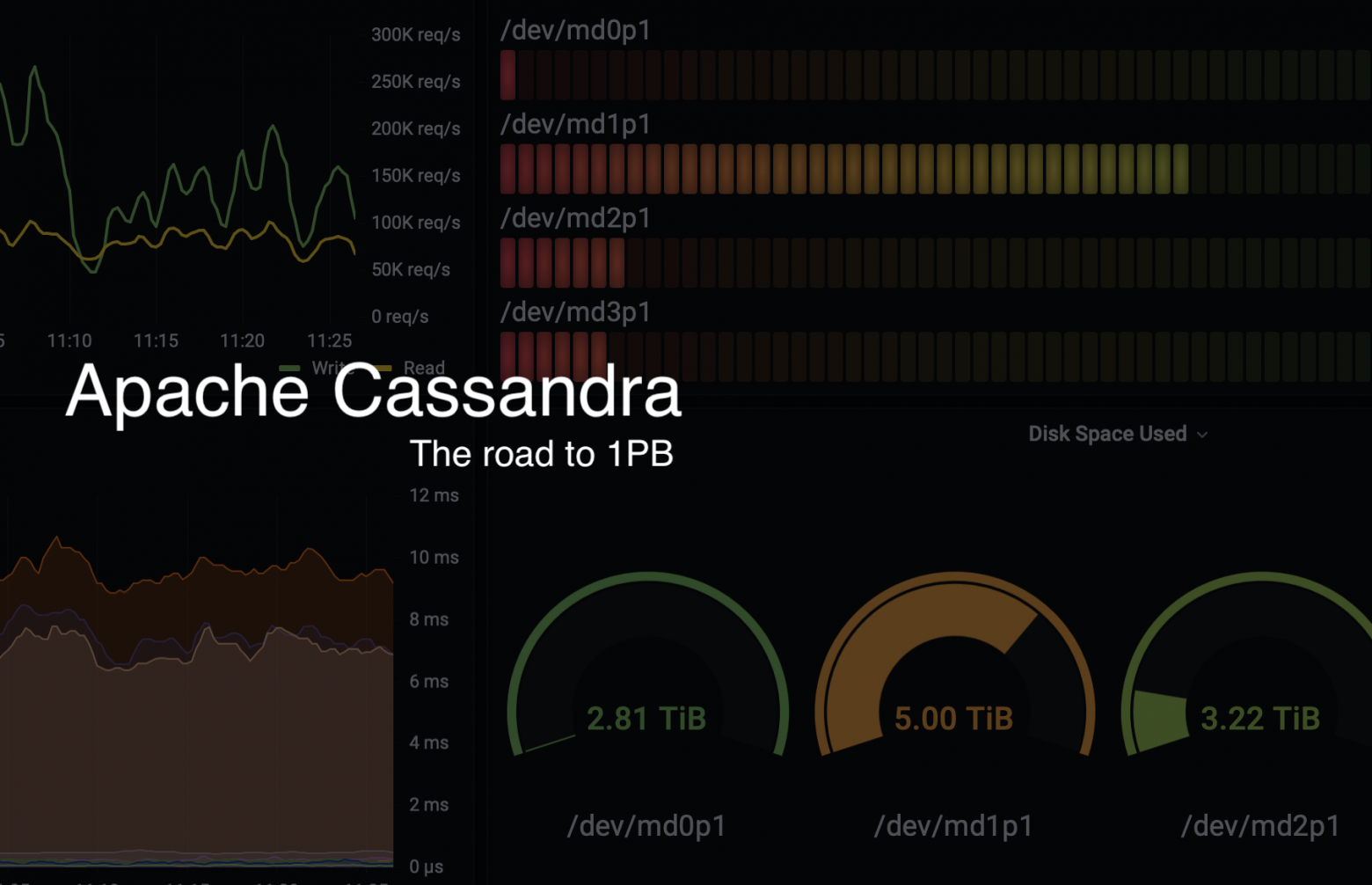
Суммарно, во всех кластерах Cassandra мы храним 0.4PB данных при общей емкости 0.9PB, стабильно производим 0.7млн операций записи и доступа к данным и 1.1млн когда необходимо разогнаться в трудные времена, при этом продолжаем непрерывно расширяться.
Отсюда лежит и название статьи, к моменту публикации последней главы из цикла петабайтный барьер емкости будет взят.
Материал подразумевает, что вы уже начали знакомиться с этой замечательной базой данных, хотите найти примеры её использования в российском сегменте интернета и будет полезен тем, кто постоянно ищет способ обучиться за счёт чужих ошибок. Ошибок мы совершили не мало, добро пожаловать!