
В этой статье мы поговорим об особенностях машинного обучения, и о том, как можно соединить Deep Learning и Master Data Management. Разберем достаточно подробный пример использования глубокого обучения для управления данными.

Пользователь
В этой статье мы поговорим об особенностях машинного обучения, и о том, как можно соединить Deep Learning и Master Data Management. Разберем достаточно подробный пример использования глубокого обучения для управления данными.

Всем привет!
Мы хотим рассказать немного об entity resolution как об академической дисциплине, о доступных инструментах для решения этой задачи, и о нашем опыте с одним из инструментов.

Невозможно представить современную информационную систему (далее – ИС), которая бы стояла особняком, и не была бы интегрирована с другими. Особенно, если мы говорим о корпоративных или государственных данных. Вопросу интеграций посвящены целые книги, такие как «Шаблоны интеграции корпоративных приложений» Грегора Хопа. Некоторые издания пытаются рассматривать не только технические, но и организационные вопросы интеграции (например, «Предметно-ориентированное проектирование (DDD)» Эрика Эванса). Между тем, современный уровень технологий и высокий уровень компетентности разработчиков очень сильно снижает технические риски, выставляя на первый план организационные. В этой статье мы рассмотрим интеграции информационных систем именно с точки зрения организационных рисков.

Развитие технологий и все возрастающие объемы информации привели к тому, что слово «фейк» или «информационный фейк» прочно вошло в нашу жизнь. Всевозможные мошенники идут в ногу со временем и оперативно ставят себе на службу технологии, изобретая все новые способы влиять на людей. А значит, нам необходимо задуматься о том, как использовать накопившийся опыт и технологии управления информацией для распознавания фейков, т.е. для их автоматического отделения от реальных фактов. Сегодня мы расскажем о всем многообразии использования технологий управления данными для распознавания фейков.
Что же такое фейки?
Существует множество определений фейков, мы не будем на них останавливаться, но отметим, что в этой статье мы будем говорить не об ошибочной информации (такой как опечатки или случайно вкравшиеся неточности), а об информации искажавшейся намеренно.
Фейки можно встретить практически в любой форме — тексте, видео или аудио контенте. Поговорим сначала о последних. Для создания аудио и видео фейков существует специальный инструментарий, построенный на глубоком обучении (deep learning). Искаженные таким образом факты называются дипфейками [1, 2]. Кажется, что уже все видели их примеры — эти видеоклипы с различными знаменитостями, которые говорили или делали что-то, чего на самом деле не было (в [3] есть небольшой таймлайн с известными дипфейками), многие пранкеры используют дипфейки в своих звонках. Однако дипфейки это не развлечение, а серьезная угроза: продвинутые мошенники их уже освоили и во-всю пускают в дело [4, 5].
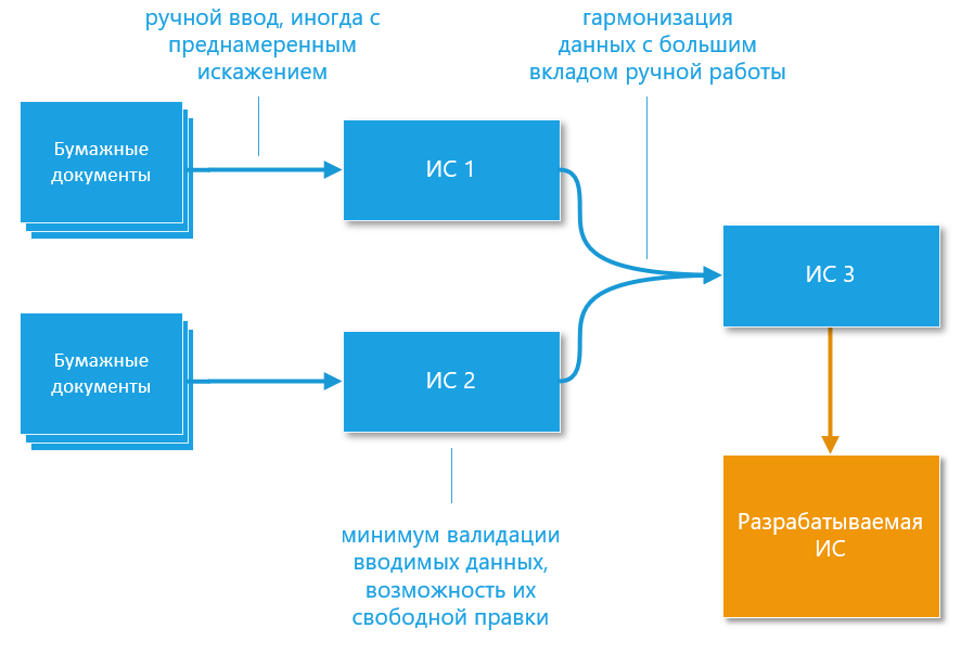
В нашей прошлой статье мы рассказывали о функциональных зависимостях и их применении в эксплорации и очистке данных. Сейчас расскажем о разработке информационных систем. Как сделать нужную для бизнеса информационную систему (ИС), которая полностью работает, и при этом не работает? Очень просто. Предоставьте разработчикам ИС ограниченный набор тестовых данных и лишите их возможности сопровождения системы на реальных данных.
Очень часто заказчики забывают важность предоставления своевременного и полного набора данных для информационных систем, что в итоге приводит к весьма плачевным результатам. В этой статье мы поделимся своим опытом в этой сфере и попытаемся обосновать важность получения правильных тестовых данных.

Функциональные зависимости – концепция, которой уже много десятков лет, её преподают практически в каждом курсе баз данных. Их классическое применение – нормализация схемы данных. В последние годы у концепции появилось множество иных приложений в контексте data science, касающиеся эксплорации и очистки данных.
В статье мы расскажем о функциональных зависимостях (точных и приближенных), опишем, что с ними можно делать в контексте работы с данными, и покажем, что с ними умеет делать наш профайлер Desbordante. Статья является продолжением нашей прошлой статьи, в которой мы рассказали о профилировании данных.

В предыдущей нашей публикации, «Как мы писали книгу по управлению данными» мы подробно рассказали о всех нюансах создания книги «Ценность Ваших Данных» [2] – от замысла до работы с издательством. В этой статье мы расскажем о создании труда с точки зрения научной составляющей – от нашего перевода и научной редактуры DAMA-DMBOK2 до создания собственной работы в области управления данными. В данной публикации хотелось бы еще раз проследить историю создания книги, более подробно рассмотрев основные вехи в формировании ее концепции. Во-первых, чтобы дополнительно прояснить замысел авторов. А во-вторых, чтобы поделиться полученным опытом трансформации изначального замысла в процессе написания и подготовки окончательного варианта текста. Возможно, изложенные нами сведения окажутся интересными как для читателей книги, так и для тех коллег, которые планируют издание собственного труда подобного рода.
Отправная точка
Началось все с того, что в течение 2018-2019 годов мы приняли участие в работе над переводом и научной редактурой второго издания руководства Международной ассоциации управления данными (DAMA) к своду знаний по управлению данными - DAMA-DMBOK2 [7]. Наша компания включилась в эту деятельность совершенно осознанно, поскольку мы хорошо понимали важность и полезность переводимого документа, уже давно ориентировались в своей проектной работе на его основные положения и англоязычный текст был нам хорошо знаком. Работа, с учетом необходимых организационных и подготовительных мероприятий, длилась почти полтора года. Особенно напряженными были последние шесть месяцев, когда первоначальный вариант перевода был подвергнут кардинальной переделке, связанной с преодолением целого ряда препятствий [4]. Тем приятнее осознавать, что результат нашего труда оказался востребованным. Мы получили много положительных отзывов о русском издании DMBOK2, его тираж уже несколько раз допечатывался, а варианты перевода отдельных терминов и ключевые текстовые фрагменты все чаще используются в различных отечественных публикациях.

Замысел
Несколько лет назад наша компания «Юнидата» стала научным руководителем и де-факто переводчиком российского издания DAMA-DMBOK. Уже тогда, продираясь через сложность терминологии, выверяя до миллиметра формулировки, облачая сухой текст в одежду российских языковых эквивалентов, мы стали задумываться о том, чтобы написать свою книгу. Еще бы: DMBOK умопомрачительно хороша, но далека от идеала. Во-первых, многих отпугивает объем и обилие терминов. Во-вторых, при всех своих размерах, она не охватывает все области, связанный с управлением данных. В-третьих, отсутствует российская специфика. Все это (и многое другое) и сформировало желание пойти дальше.
Какое-то время после выхода этой книги мы приходили в себя и переводили дух. Но идея росла и крепла. Тем более, что анализ «отечественных аналогов» или хотя бы книг, толково рассказывающих о данных, показал немыслимое: в нашей стране вообще нет хороших книг о данных. Удивительное дело!
Сначала мы хотели выдать внутреннюю брошюру, страниц на 250, которая бы прослеживала основной лейтмотив по управлению данными. Мы намеривались распространять ее среди сотрудников компании, формируя единый понятийный аппарат и понимание проблематики. Все это было нужно, чтобы говорить на одном языке. Однако быстро поняли, что книга начинает жить своей жизнь, многократно превосходя изначальный замысел.
Сообразно сменилась и концепция – теперь мы хотели уже научпоп, который бы растолковал «даже домохозяйкам» все премудрости управления данными. Какое-то время мы жили в этой концепции, стремясь упростить и несколько примитивизировать научные постулаты. Еще одним вариантом было создать «DMBOKдля чайников», но мы быстро (и совершенно оправданно) ушли от этого.

Всем привет. В этой статье хотим представить инструмент для профилирования данных. Расскажем об особенностях инструмента, о профилировании данных, и кому это будет полезно. И, конечно, его уже можно опробовать: ссылка будет в тексте статьи.

Данная работа является пересказом статьи Jingzhou Liu, Wei-Cheng Chang, Yuexin Wu, and Yiming Yang. 2017. Deep Learning for Extreme Multi-label Text Classification. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR '17). Association for Computing Machinery, New York, NY, USA, 115–124. https://doi.org/10.1145/3077136.3080834
Одно из направлений работ в нашей лаборатории Unidata Labs – классификация записей материально-технических ресурсов (МТР) с применением машинного обучения. В этой статье мы бы хотели кратко разобрать нашу постановку задачи как таковую, и после чего предложить разбор одного из методов, которым эта задача могла бы решаться.
Вкратце, продукт Юнидата МТР работает с данными, относящимися к материально-техническим ресурсам клиентов, которые представлены в Юнидата как реестр — т.е., коллекция записей. Записи МТР, как правило, содержат очень большое количество полей, но нас интересует только одно — полное наименование. Оно может выглядеть примерно так...

В прошлый раз я подробно рассказывал об особенностях компании-вендора. Теперь настало время поговорить о мифах и правде в работе компании-вендора. Если тема вам интересна, то давайте начнём.
Миф 1. Особые продуктовые специалисты
Один из наиболее стойких и распространенных мифов. Будто бы существует особый вид специалиста - продуктовый разработчик или продуктовый тестировщик. Очень редкий и ценный зверь. Мне кажется, что таких специальностей не бывает, но, что действительно существует, так это определенные особенности, присущие разработке продукта и как, следствие, продуктовая разработка может показаться скучной или тесной для некоторых людей.
Попробуем разобраться с качествами технического специалиста, которыми мы чаще всего оперируем для оценки в жизни:
Хороший vs Плохой
Соблазн применить эту категорию очень велик. «Хорошесть» или «плохость» не зависит от места работы, опыта работы, роста или цвета глаз. Это интегральная экспертная оценка ;-). Хорошего программиста видно по его коду, который компактен, понятен, легко поддерживается. Хорошего QA видно по въедливости, упорядоченности и понятности его кейсов. Видно его по вопросам, которые он задет до/при реализации/тестировании.
Это видно по скорости и уровню погружения в решаемую задачу и, в конце концов, по тому, к кому ходят задавать вопросы. И я не знаю, как это измерить в попугаях. Так вот, плотность хороших спецов в продуктах, аутсорсе, финтехе, abap, 1с, фронте и бэке одинаковая. И это качество точно не является специфичным для какой-то одной отрасли или направления.

Вступление
Наша группа компаний (ГК) еще и не была основана, но сразу имела тесную и неразрывную связь с наукой. Почему? Потому что наши основатели изначально работали в научной сфере. Разработки, лежащие в основе запатентованных технологий работы с данными и ставшие основой для нашего флагманского продукта – следствие их высоких теоретических знаний и исследовательских талантов. На пути реализации своих целей в бизнесе, они всегда старались сохранить связь с академической средой. Издавали и издают поныне научные статьи и книги, участвовали в разработке научных программ и сотрудничали со своими родными ВУЗами и кафедрами.
Постепенно к этой деятельности все больше привлекалась ГК, это была либо практическая деятельность – дипломные работы и практики студентов, либо осознанная благотворительность – ведение спецкурса для студентов нескольких кафедр СПбГУ на базе ГК и с активной «прокачкой» слушателей по методологии и практике проектной деятельности и программирования.

Несколько слов об авторе
Чтобы был понятен контекст, нужно сказать несколько слов об авторе. Я с 2004 года занимаюсь разработкой программного обеспечения, начав с позиции junior java developer'а в аутсорсинговой компании и сейчас занимая позицию CTO в компании-вендоре «Юнидата». По пути застал времена расцвета и заката ODC западных продуктовых компаний в отечественных аутоорс компаниях, частичную переориентацию классических аутсорс компаний на отечественный рынок заказной разработки, эру импортозамещения и прочих этапов развития рынка разработки программного обеспечения (ПО) в России (мне кажется эта тема еще ждет своего историка). Учитывая все это, считаю себя достаточно опытным, чтобы рассуждать о деятельности вендора в B2B сегменте, вместе с тем осознавая ограничение своего опыта рамками определенных сегментов рынка ПО.
О чем и для кого статья
В данной статье я хочу описать, что же такое на самом деле вендор ПО, какое место в ней занимает собственно разработка продукта, и чем это отличается или не отличается от других компаний-разработчиков ПО. Надеюсь, что этот материал будет полезен для людей, планирующих работу в области продуктовой разработки, чтобы понимать на что из может ожидать, а также для сотрудников, уже работающих в продуктовой разработке, для понимания того, как это функционирует на самом деле. Из-за своего объема текст разбит на 2 части. Перед вами первая из них.

Идея гедонистической адаптации говорит, что человек обладает механизмом, который склонен постепенно снижать воздействие ярких эмоциональных событий: положительных или отрицательных. Если человек выиграет миллион за прививку, или сильно заболеет, то в любом случае через 30-90 дней он вернётся к примерно тому же уровню счастья, что и до этого. Механизм помогает мириться с событиями, жить дальше, даже забывать какие-то вещи.
Есть события, к которым этот механизм не применим, и условия пандемии, как оказалось, в их числе. Да, нельзя сказать, что мы тут все беспрерывно страдаем. Однако же нет-нет, да и проскользнет в голове мысль, что «а раньше…». Эпидемические меры — это целая куча деталей, на каждую из которых обращаешь внимание даже спустя много времени.
А раньше мы проводили корпоративы два раза в год, собирались вместе и веселились (думаю, о корпоративе как инструменте уже все знают, и не нужно повторяться). Летом мы праздновали день рождения компании, зачастую устраивая спортивные мероприятия: парусную регату, рафтинг, веревочный парк и т.д.
Зимний корпоратив – это новый год. Праздничная и торжественная вечеринка, квест или викторина. Отличаемся ото всех только тем, что проводим корпоратив после январских праздников: мы даём сотрудникам больше времени на закрытие проектов перед каникулами, а в январе, когда все только раскачиваются, делаем перерыв в работе. Многие голосовали за этот вариант, в итоге уже несколько лет эта схема работает.
И тут пришел 2020-ый…
Только ленивый не говорил о пандемических изменениях. Поменялось всё, и представление об организации корпоративов тоже. Из-за введенных ограничений и из-за беспокойства за здоровье своих сотрудников руководство компаний было вынуждено перевести сотрудников на удаленную работу и, как следствие, отказаться от привычного оффлайн-формата работы и совместных мероприятий.

В середине августа мы приняли участие в международной научной конференции VLDB (Very Large Data Bases), и хотим поделиться актуальными идеями о работе с базами данных.
Если вы специалист по базам данных, или так или иначе связаны с ними, то приглашаем к чтению.

Одним из основополагающих инструментов при работе с данными является их поиск. В юнидате мы используем инструмент ElasticSearch как сервис полнотекстового поиска. В данной статье мы хотим поделиться нашим личным опытом развития fuzzy поиска в тематике материально-технических – ресурсов (далее МТР) как пример использования поиска в специализированных бизнес-кейсах. Статья не является руководством к применению, так как определенные решения могут не быть оптимальными вне контекста платформы, но могут быть полезны при решении похожих задач. Итак, приступим.

Сегодня мы начинаем новую серию публикаций, посвященных управлению персоналом. Как оказалось, в HR подразделении нашей компании происходят весьма своеобразные и любопытные процессы, узнать о которых широкой аудитории будет полезно и любопытно. И начнем мы со статьи, посвященной стажировке. Представьте классическую ситуацию: молодые студенты или аспиранты приходят на стажировку в крупную IT компанию и… начинается самое интересное.

Относительно недавно мы начали строить качественно новую версию платформы "Юнидата", в которой изменилось очень многое, включая архитектуру, технологии, подход. Даже основная идея продукта приросла новыми деталями.
Нам кажется, что здорово делиться опытом подобных изменений, поэтому мы хотим сделать несколько статей о том, как устроена изнутри "Юнидата". В этой, первой, статье речь пойдет о UI. О том, как было раньше, что побудило нас кардинально пересмотреть стек и организацию работы с кодом, и что получилось в итоге.
Об авторе статьи. Меня зовут Илья, я занимаюсь разработкой новой версии. Мне не довелось работать с предыдущими версиями "Юнидата", и в проект я пришел на этапе прототипа. Я могу быть не до конца объективен на тему того, почему было выбрано то или иное решение, если это происходило еще до моего присоединения к продукту. В причинах перехода я написал свое видение, после общения с командой.
Итак, всем, кто любит истории переезда с ноткой технических особенностей, добро пожаловать под кат.
Краткий тех.обзор
Сейчас мы имеем модульный монолит и на бэке и на фронте. Они расположены в отельных репозиториях + есть еще один, который содержит настройки для запуска всего приложения в контейнерах.
Кроме того, продукт разделён на Community Edition (хранится в публичном гитлабе) и Enterprise Edition.
Фронтенд состоит из 20 модулей (число не конечное). Мы используем свежую версию typescript и почти свежую react (сейчас 16, но перевод на 17 - дело ближайшего времени). Применяем MVC подход в каждом модуле: реакт только view-слой, своя observable модель (обязательно про нее напишем отдельную статью), mobx сторы в качестве контроллеров.
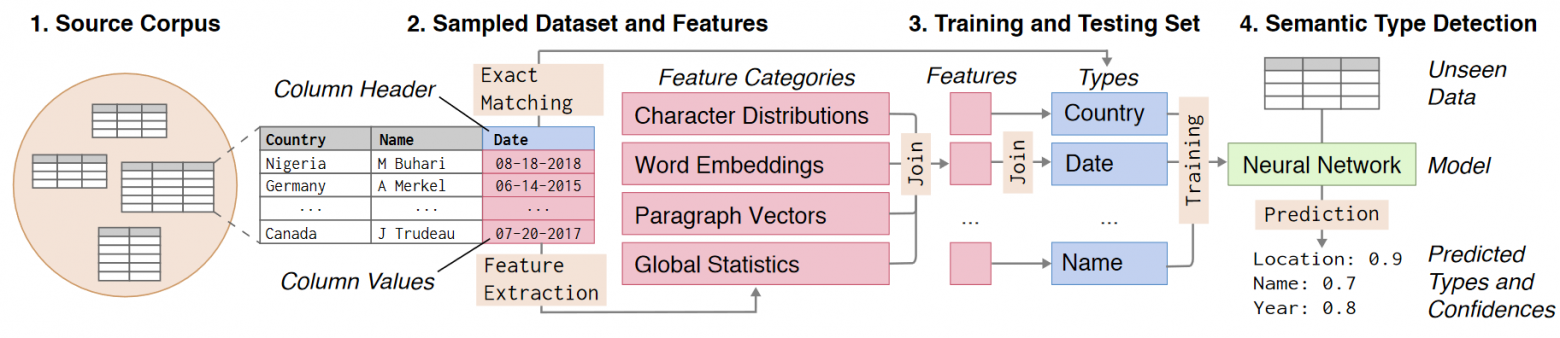
Представим, что у нас есть таблица с неизвестными данными причем у которых почему-то пропали названия колонок. Наша задача — восстановить эти названия и в общих чертах понять, что находится в каждой колонке.
Существуют специализированные системы подготовки и анализа данных. Большинство из них отлично справляются с определением атомарного типа колонки, такого как string, integer, boolean. Однако, с задачей определения семантического типа — собственно, того, что лежит в колонке (имя человека, название организации, город и пр.), не всё так хорошо. При этом, успешное определение семантического типа может дать гораздо больше, чем простое знание атомарного типа. Имея на руках семантические типы колонок можно скорее разобраться в незнакомой базе данных, и, например, быстро выделить все колонки, относящиеся к одной сущности реального мира.

Всем привет! Ранее мы упоминали, что платформа Unidata активно работает с бизнес-процессами и поддерживает нотацию BPMN в основе их проектирования. Для разработки БП мы используем open source движок Activiti BPMN, базирующийся на java. Среди доступных продуктов с открытым исходным кодом для проектирования бизнес-процессов мы выбрали Activiti по следующим причинам.