
Я долгое время думал, что написать сортировку массива слиянием так, чтобы она не использовала дополнительной памяти, но чтобы время работы оставалось равным O(N*log(N)), невозможно. Поэтому, когда karlicos поделился ссылкой на описание такого алгоритма, меня это заинтересовало. Поиск по сети показал, что про алгоритм люди знают, но никто им особо не интересуется, его считают сложным и малоэффективным. Хотя, может быть, они имеют в виду какую-то «стабильную» версию этого алгоритма, но нестабильная при этом все равно никому не нужна.
Но я все-таки решил попробовать.
Но я все-таки решил попробовать.


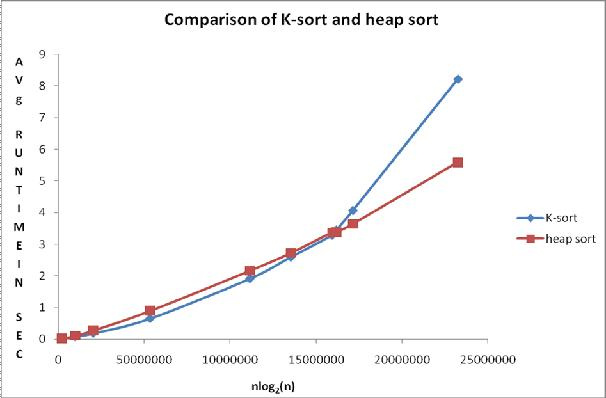
 Алгоритмы — это всего лишь пошаговые алгоритмы решения задач, и большинство таких задач уже были кем-то решены, протестированы и проверены. Можно, конечно, погрузиться в глубокую философию гениального Кнута, изучить многостраничные фолианты с доказательствами и обоснованиями, но хотите ли вы тратить на это свое время?
Алгоритмы — это всего лишь пошаговые алгоритмы решения задач, и большинство таких задач уже были кем-то решены, протестированы и проверены. Можно, конечно, погрузиться в глубокую философию гениального Кнута, изучить многостраничные фолианты с доказательствами и обоснованиями, но хотите ли вы тратить на это свое время?