Теоретические и практические исследования сходятся в том, что распространение инноваций отображается, как S-образная кривая. Действительно, S-образный паттерн диффузии инноваций, по всей видимости, является базовым антропологическим феноменом.
Это наблюдение берет начало в далеком 1895 году, когда французский социолог Габриэль Тард (Gabriel Tarde) впервые описал процесс социальных изменений посредством подражательного по своей природе механизма «группового мышления» и S-образного паттерна [1]. В 1983 году Эверетт Роджерс (Everett Rogers) разработал более совершенную четырехступенчатую модель инновационного процесса принятия решения, состоящую из: (1) знаний, (2) убеждения, (3) решения и реализации и (4) подтверждения.





 Как случилось, что искусственный интеллект успешно развивается, а «правильного» определения для него до сих пор нет? Почему не оправдались надежды, возлагавшиеся на нейрокомпьютеры, и в чем заключаются три главные задачи, стоящие перед создателем искусственного интеллекта?
Как случилось, что искусственный интеллект успешно развивается, а «правильного» определения для него до сих пор нет? Почему не оправдались надежды, возлагавшиеся на нейрокомпьютеры, и в чем заключаются три главные задачи, стоящие перед создателем искусственного интеллекта? 

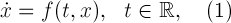
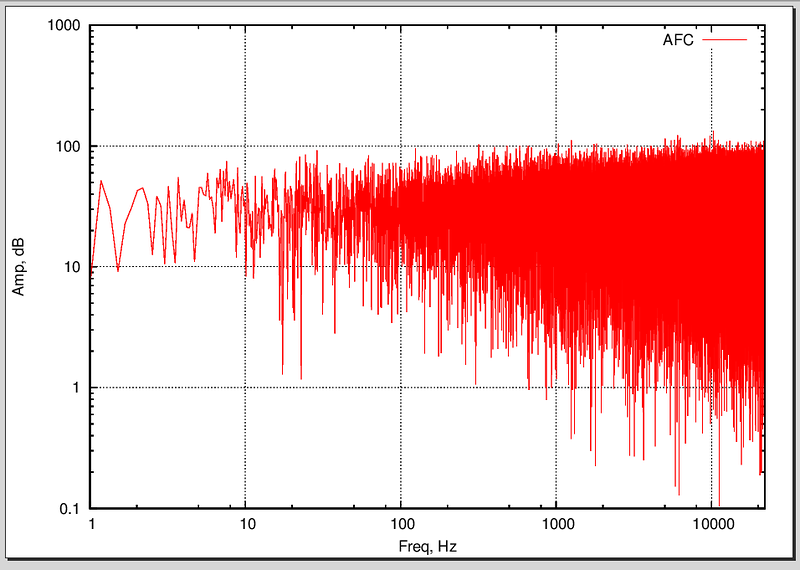
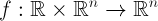 представляет собой сумму
представляет собой сумму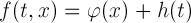
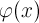 и тригонометрического полинома
и тригонометрического полинома 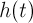 , являющегося
, являющегося 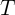 -периодической векторной функцией.
-периодической векторной функцией.