
Это ответ, точнее мысли по статье, опубликованной на Хабре: «Зарплаты в IT: сравнение Германии и России — где программисты и айтишники получают больше». Советую сначала ее прочитать и потом уже здесь продолжить.
Principal Software Engineer
Это ответ, точнее мысли по статье, опубликованной на Хабре: «Зарплаты в IT: сравнение Германии и России — где программисты и айтишники получают больше». Советую сначала ее прочитать и потом уже здесь продолжить.

Наш спикер и экс-CTO Слёрма Марсель Ибраев почти год живёт и работает системным инженером в Абу-Даби. Мы поговорили с Марселем, и он поделился, как прошёл собеседование на иностранном языке, хотя его английский и сейчас далёк от идеала, а до переезда в ОАЭ был ещё хуже.
А ещё рассказал про квартиру в ЖК с бассейном на крыше и назвал зарплату, на которую не стоит соглашаться айтишнику, планирующему жить в Эмиратах.

В процессе изучения разных алгоритмов и структур данных приходит понимание, что не все они применимы в прикладных задачах (в отличие от задач про Васю и Петю/Алису и Боба). Но тот факт, что алгоритм/структура данных не является полезной на практике не означает, что идеи в них содержащиеся не привлекают пытливые умы даже из чистого любопытства. Потому речь пойдёт о красивых (субъективно) и, что важно, простых с точки зрения концепции структурах данных.
Помните: если что-то не компилируется, это псевдокод.

На первом интервью чаще всего рекрутер может задать вопрос о зарплатных ожиданиях кандидата — “What Are Your Salary Expectations?”. Я принимаю участие в найме продукт-менеджеров, дизайнеров и инженеров и хочу поделиться с вами своим опытом как правильно отвечать на этот вопрос применительно к рынку США.
Я не рекомендую раскрывать никаких цифр как на ранней стадии процесса интервью, так и во время раунда интервью. В этой статье я расскажу почему именно такая стратегия является наиболее выигрышной.

В процессе написания программ мы часто сталкиваемся с данными, для которых возможен только ограниченный набор значений. Например, возраст, который не может быть отрицательным или email, который может иметь только определенный формат строки.
 Привет, меня зовут Костя Кардаманов, я работаю в отделе технологий разработки Яндекса. Обычно такой же фразой я приветствую и кандидатов на собеседовании. А сегодня я хотел бы рассказать вам, как и зачем мы проводим интервью по дизайну систем с бэкенд-разработчиками. Сразу скажу: для фронтендеров, мобильных разработчиков и ML-инженеров подобный тип собеседований применим слабо, так что эти специальности мы здесь обсуждать не будем.
Привет, меня зовут Костя Кардаманов, я работаю в отделе технологий разработки Яндекса. Обычно такой же фразой я приветствую и кандидатов на собеседовании. А сегодня я хотел бы рассказать вам, как и зачем мы проводим интервью по дизайну систем с бэкенд-разработчиками. Сразу скажу: для фронтендеров, мобильных разработчиков и ML-инженеров подобный тип собеседований применим слабо, так что эти специальности мы здесь обсуждать не будем. В статье описана ленивая реализация обхода дерева на языке C++ с использованием сопрограмм и диапазонов на примере улучшения интерфейса работы с дочерними элементами класса QObject из фреймворка Qt. Подробно рассмотрено создание пользовательского представления для работы с дочерними элементами и приведены ленивая и классическая его реализации. В конце статьи есть ссылка на репозиторий с полным исходным кодом.

CMake — это система сборки для C/C++, которая с каждым годом становится всё популярнее. Он практически стал решением по умолчанию для новых проектов. Однако, множество примеров выполнения какой-либо задачи на CMake содержат архаичные, ненадёжные, раздутые действия. Мы выясним, как писать скрипты сборки на CMake лаконичнее.

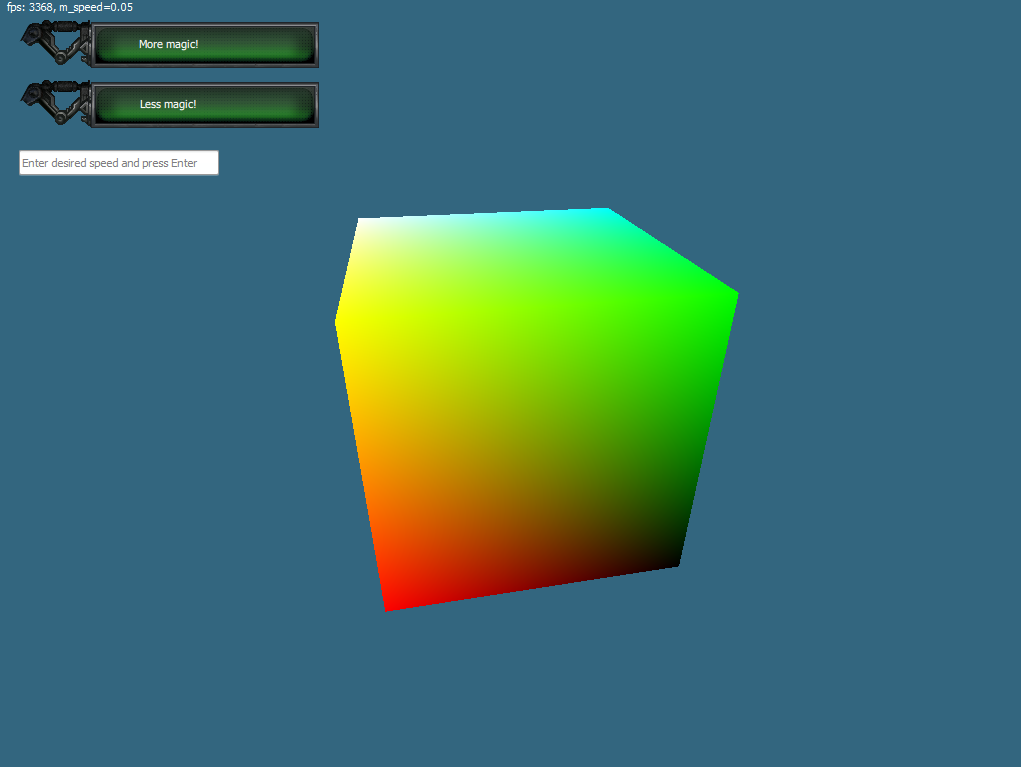
 В прошлом уроке мы научились раскрашивать наши объекты в разные цвета. Но для того, чтобы добиться некого реализма нам потребуется очень много цветов. В прошлый раз, мы раскрашивали вершины треугольника, если мы пойдем тем же путем, то нам понадобится слишком большое количество вершин для вывода картинки. Заинтересовавшихся, прошу под кат.
В прошлом уроке мы научились раскрашивать наши объекты в разные цвета. Но для того, чтобы добиться некого реализма нам потребуется очень много цветов. В прошлый раз, мы раскрашивали вершины треугольника, если мы пойдем тем же путем, то нам понадобится слишком большое количество вершин для вывода картинки. Заинтересовавшихся, прошу под кат.


 Статья обновлена с учётом полезных комментариев. Большое спасибо всем комментаторам за важные уточнения и дополнения.
Статья обновлена с учётом полезных комментариев. Большое спасибо всем комментаторам за важные уточнения и дополнения.

