Онлайн рекомендательная система видео-контента, над которой мы работаем, является закрытой коммерческой разработкой и технически представляет собой многокомпонентный кластер из собственных и open source компонентов. Целью написания данной статьи является описание внедрения системы кластеризации docker swarm под staging-площадку, не нарушая сложившийся workflow наших процессов в условиях ограниченного времени. Представленное вашему вниманию повествование разделено на две части. Первая часть описывает CI/CD до использования docker swarm, а вторая — процесс его внедрения. Кто не заинтересован в чтении первой части, может смело переходить ко второй.
В далеком-далеком году требовалось как можно быстрее настроить процесс CI/CD. Одним из условий было не использовать Docker для деплоя разрабатываемых компонент по нескольким причинам:
Инфраструктура, стек и примерные исходные требования для MVP представлялись такими:
Одним из первых вопросов, который требуется решить на начальной стадии, это каким образом будет производиться разворачивание кастомных компонент в каком-либо окружении (CI/CD).
Сторонние компоненты решили ставить системно и обновлять их системно. Кастомные же приложения, разрабатываемые на C++ или Python, разворачивать можно несколькими способами. Среди них, например: создание системных пакетов, отправка их в репозиторий собранных образов и их последующая установка на серверах. По неизвестной уже причине был выбран другой способ, а именно: с помощью CI компилируются исполняемые файлы приложений, создается виртуальное окружение проекта, устанавливаются py-модули из requirements.txt и все эти артефакты отправляются вместе с конфигами, скриптами и сопутствующим окружением приложений на серверы. Далее осуществляется запуск приложений от виртуального пользователя без прав администратора.
В качестве системы CI/CD был выбран Gitlab-CI. Получившийся pipeline выглядел примерно так:
Стоит заметить, что сборка и тестирование производится на своем собственном образе, где уже установлены все необходимые системные пакеты и выполнены другие настройки.
Хотя каждый из этих скриптов в job-ах интересен по-своему, норассказывать я про них конечно же не буду описание каждого из них займет значительное время и не в этом цель статьи. Обращу лишь внимание, что стадия деплоя состоит из последовательности вызова скриптов:
Шло время. Стадию staging заменили preproduction и production. Добавилась поддержка продукта еще на одном дитрибутиве (CentOS). Добавилось еще 5 мощных физических серверов и десяток виртуальных. А разработчикам и тестировщикам становилось все сложнее обкатывать свои задачи на окружении более-менее приближенном к рабочему состоянию. В это время стало понятно что невозможно обойтись без него…

Итак, наш кластер представляет из себято еще зрелище систему из пары десятков отдельных компонент, не описанных Dockerfile-ами. Сконфигурировать его для деплоя на определенное окружение можно только в целом. Наша задача состоит в том, чтобы деплоить кластер в staging-окружение для обкатки его перед предрелизным тестированием.
Теоретически, одновременно работающих кластеров может быть несколько: столько сколько задач в завершенном состоянии или близком к завершению. Мощности, имеющихся в нашем распоряжении серверов, позволяют запускать несколько кластеров на каждом сервере. Каждый staging-кластер должен быть изолирован (не должно быть пересечения по портам, директориям и т.п.).
Самый ценный ресурс это наше время, а его у нас было немного.
Для более быстрого старта выбрали Docker Swarm в силу его простоты и гибкости архитектуры. Первое что мы сделали это создали на удаленных серверах менеджера и несколько нод:
Далее, создали сеть:
Далее, связали Gitlab-CI и ноды Swarm в части удаленного управления нодами из CI: установка сертификатов, настройка секретных переменных, а также настройка сервиса Docker на управляющем сервере. Вот эта статья нам сильно сэкономила время.
Далее, добавили job'ы создания и уничтожения стэка в .gitlab-ci .yml.
Из вышеприведенного фрагмента кода видно, что в Pipelines добавились две кнопки (deploy_staging, stop_staging), требующие ручного воздействия.

Имя стэка соответствует имени ветки и этой уникальности должно быть достаточно. Сервисы в стэке получают уникальные ip-адреса, а порты, директории и т.п. будут изолированными, но одинаковыми от стэка к стэку (т.к. конфигурационный файл одинаков для всех стэков) — то, чего мы и добивались. Стэк (кластер) мы разворачиваем с помощью docker-compose.yml, в котором описан наш кластер.
Здесь видно, что компоненты объединены одной сетью (nw_swarm) и друг другу доступны.
Системные компоненты (на основе redis, mysql) разделены от общего пула кастомных компонентов (в планах и кастомные разделить как сервисы). Стадия деплоя нашего кластера выглядит как передача CMD в наш один большой сконфигурированный image и в целом практически не отличается от деплоя, описанного в Части I. Подчеркну отличия:
Осталась только одна пока неописанная проблема: компоненты, которые имеют веб-интерфейс не доступны из браузеров разработчиков. Мы эту проблему решаем с помощью reverse proxy, таким образом:
В .gitlab-ci.yml после деплоя стэка кластера добавляем строчку деплоя балансировщика (который при комитах, только обновляет свою конфигурацию (создает новые конфигурационные файлы nginx по шаблону: /etc/nginx/conf.d/${CI_COMMIT_REF_NAME}.conf) — см. код docker-compose-nginx.yml)
На компьютерах разработчиков обновляем /etc/hosts; прописываем url до nginx:
Итак, деплой изолированных staging-кластеров реализован и разработчики теперь могут запускать их влюбом достаточном для проверки своих задач количестве.
Дальнейшие планы:
Отдельная благодарность за статью.
Часть I
В далеком-далеком году требовалось как можно быстрее настроить процесс CI/CD. Одним из условий было не использовать Docker для деплоя разрабатываемых компонент по нескольким причинам:
- для более надежной и стабильной работы компонент в Production (т.е. по сути требование не использовать виртуализацию)
- ведущие разработчики не хотели работать с Docker (странно, но было именно так)
- по идейным соображениям руководства R&D
Инфраструктура, стек и примерные исходные требования для MVP представлялись такими:
- 4 сервера Intel® X5650 с Debian (одна более мощная машина полностью под разработку)
- Разработка собственных кастомных компонент ведется на C++, Python3
- Основные 3rdparty-используемые средства: Kafka, Clickhouse, Airflow, Redis, Grafana, Postgresql, Mysql, ...
- Pipelines сборки и тестирования компонент отдельно для debug и release
Одним из первых вопросов, который требуется решить на начальной стадии, это каким образом будет производиться разворачивание кастомных компонент в каком-либо окружении (CI/CD).
Сторонние компоненты решили ставить системно и обновлять их системно. Кастомные же приложения, разрабатываемые на C++ или Python, разворачивать можно несколькими способами. Среди них, например: создание системных пакетов, отправка их в репозиторий собранных образов и их последующая установка на серверах. По неизвестной уже причине был выбран другой способ, а именно: с помощью CI компилируются исполняемые файлы приложений, создается виртуальное окружение проекта, устанавливаются py-модули из requirements.txt и все эти артефакты отправляются вместе с конфигами, скриптами и сопутствующим окружением приложений на серверы. Далее осуществляется запуск приложений от виртуального пользователя без прав администратора.
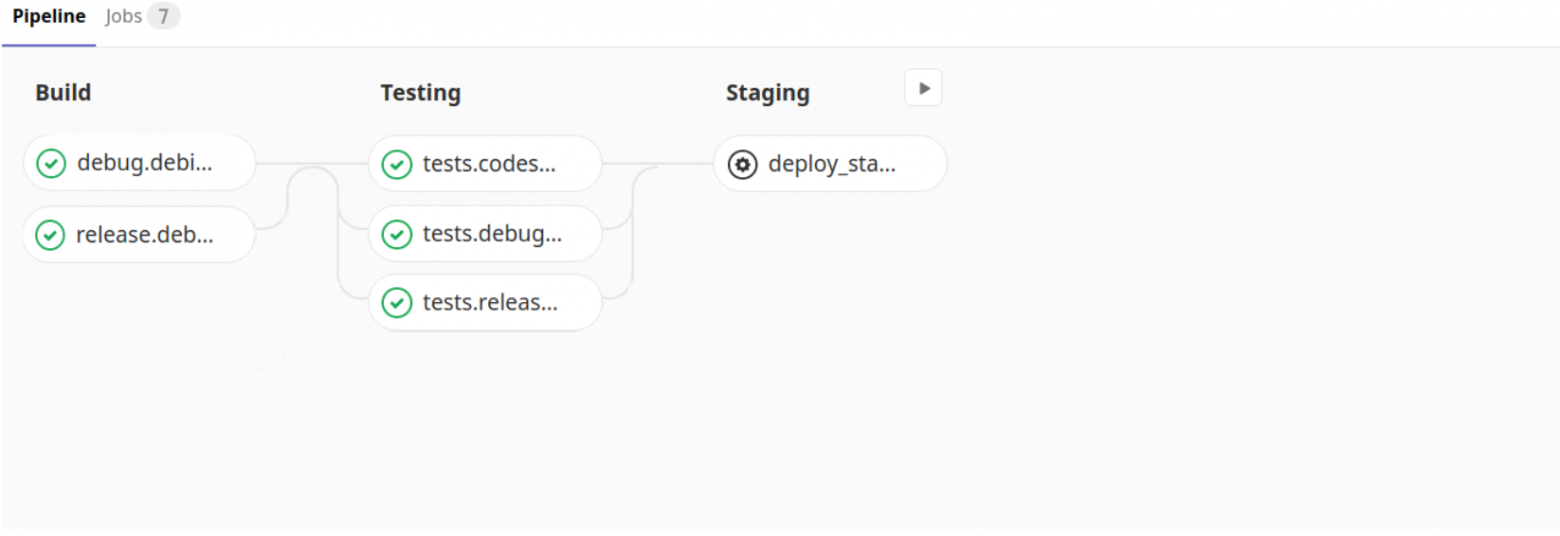
В качестве системы CI/CD был выбран Gitlab-CI. Получившийся pipeline выглядел примерно так:
Структурно gitlab-ci.yml выглядел следующим образом
--- variables: # минимальная версия ЦПУ на серверах, где разворачивается кластер CMAKE_CPUTYPE: "westmere" DEBIAN: "MYREGISTRY:5000/debian:latest" before_script: - eval $(ssh-agent -s) - ssh-add <(echo "$SSH_PRIVATE_KEY") - mkdir -p ~/.ssh && echo -e "Host *\n\tStrictHostKeyChecking no\n\n" > ~/.ssh/config stages: - build - testing - deploy debug.debian: stage: build image: $DEBIAN script: - cd builds/release && ./build.sh paths: - bin/ - builds/release/bin/ when: always release.debian: stage: build image: $DEBIAN script: - cd builds/release && ./build.sh paths: - bin/ - builds/release/bin/ when: always ## testing stage tests.codestyle: stage: testing image: $DEBIAN dependencies: - release.debian script: - /bin/bash run_tests.sh -t codestyle -b "${CI_COMMIT_REF_NAME}_codestyle" tests.debug.debian: stage: testing image: $DEBIAN dependencies: - debug.debian script: - /bin/bash run_tests.sh -e codestyle/test_pylint.py -b "${CI_COMMIT_REF_NAME}_debian_debug" artifacts: paths: - run_tests/username/ when: always expire_in: 1 week tests.release.debian: stage: testing image: $DEBIAN dependencies: - release.debian script: - /bin/bash run_tests.sh -e codestyle/test_pylint.py -b "${CI_COMMIT_REF_NAME}_debian_release" artifacts: paths: - run_tests/username/ when: always expire_in: 1 week ## staging stage deploy_staging: stage: deploy environment: staging image: $DEBIAN dependencies: - release.debian script: - cd scripts/deploy/ && python3 createconfig.py -s $CI_ENVIRONMENT_NAME && /bin/bash install_venv.sh -d -r ../../requirements.txt && python3 prepare_init.d.py && python3 deploy.py -s $CI_ENVIRONMENT_NAME when: manual
Стоит заметить, что сборка и тестирование производится на своем собственном образе, где уже установлены все необходимые системные пакеты и выполнены другие настройки.
Хотя каждый из этих скриптов в job-ах интересен по-своему, но
- createconfig.py — создает файл settings.ini с настройками компонент в различном окружении для последующего деплоя (Preproduction, Production, Testing, ...)
- install_venv.sh — создает виртуальное окружение для py-компонент в определенной директории и копирует его на удаленные серверы
- prepare_init.d.py — подготавливает сркипты старта-стопа компонент на основании шаблона
- deploy.py — раскладывает и перезапускает новые компоненты
Шло время. Стадию staging заменили preproduction и production. Добавилась поддержка продукта еще на одном дитрибутиве (CentOS). Добавилось еще 5 мощных физических серверов и десяток виртуальных. А разработчикам и тестировщикам становилось все сложнее обкатывать свои задачи на окружении более-менее приближенном к рабочему состоянию. В это время стало понятно что невозможно обойтись без него…
Часть II
Итак, наш кластер представляет из себя
Теоретически, одновременно работающих кластеров может быть несколько: столько сколько задач в завершенном состоянии или близком к завершению. Мощности, имеющихся в нашем распоряжении серверов, позволяют запускать несколько кластеров на каждом сервере. Каждый staging-кластер должен быть изолирован (не должно быть пересечения по портам, директориям и т.п.).
Самый ценный ресурс это наше время, а его у нас было немного.
Для более быстрого старта выбрали Docker Swarm в силу его простоты и гибкости архитектуры. Первое что мы сделали это создали на удаленных серверах менеджера и несколько нод:
$ docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION kilqc94pi2upzvabttikrfr5d nop-test-1 Ready Active 19.03.2 jilwe56pl2zvabupryuosdj78 nop-test-2 Ready Active 19.03.2 j5a4yz1kr2xke6b1ohoqlnbq5 * nop-test-3 Ready Active Leader 19.03.2
Далее, создали сеть:
$ docker network create --driver overlay --subnet 10.10.10.0/24 nw_swarm
Далее, связали Gitlab-CI и ноды Swarm в части удаленного управления нодами из CI: установка сертификатов, настройка секретных переменных, а также настройка сервиса Docker на управляющем сервере. Вот эта статья нам сильно сэкономила время.
Далее, добавили job'ы создания и уничтожения стэка в .gitlab-ci .yml.
В .gitlab-ci .yml добавилось еще несколько job
## staging stage deploy_staging: stage: testing before_script: - echo "override global 'before_script'" image: "REGISTRY:5000/docker:latest" environment: staging dependencies: [] variables: DOCKER_CERT_PATH: "/certs" DOCKER_HOST: tcp://10.50.173.107:2376 DOCKER_TLS_VERIFY: 1 CI_BIN_DEPENDENCIES_JOB: "release.centos.7" script: - mkdir -p $DOCKER_CERT_PATH - echo "$TLSCACERT" > $DOCKER_CERT_PATH/ca.pem - echo "$TLSCERT" > $DOCKER_CERT_PATH/cert.pem - echo "$TLSKEY" > $DOCKER_CERT_PATH/key.pem - docker stack deploy -c docker-compose.yml ${CI_ENVIRONMENT_NAME}_${CI_COMMIT_REF_NAME} --with-registry-auth - rm -rf $DOCKER_CERT_PATH when: manual ## stop staging stage stop_staging: stage: testing before_script: - echo "override global 'before_script'" image: "REGISTRY:5000/docker:latest" environment: staging dependencies: [] variables: DOCKER_CERT_PATH: "/certs" DOCKER_HOST: tcp://10.50.173.107:2376 DOCKER_TLS_VERIFY: 1 script: - mkdir -p $DOCKER_CERT_PATH - echo "$TLSCACERT" > $DOCKER_CERT_PATH/ca.pem - echo "$TLSCERT" > $DOCKER_CERT_PATH/cert.pem - echo "$TLSKEY" > $DOCKER_CERT_PATH/key.pem - docker stack rm ${CI_ENVIRONMENT_NAME}_${CI_COMMIT_REF_NAME} # TODO: need check that stopped when: manual
Из вышеприведенного фрагмента кода видно, что в Pipelines добавились две кнопки (deploy_staging, stop_staging), требующие ручного воздействия.
Имя стэка соответствует имени ветки и этой уникальности должно быть достаточно. Сервисы в стэке получают уникальные ip-адреса, а порты, директории и т.п. будут изолированными, но одинаковыми от стэка к стэку (т.к. конфигурационный файл одинаков для всех стэков) — то, чего мы и добивались. Стэк (кластер) мы разворачиваем с помощью docker-compose.yml, в котором описан наш кластер.
docker-compose.yml
--- version: '3' services: userprop: image: redis:alpine deploy: replicas: 1 placement: constraints: [node.id == kilqc94pi2upzvabttikrfr5d] restart_policy: condition: none networks: nw_swarm: celery_bcd: image: redis:alpine deploy: replicas: 1 placement: constraints: [node.id == kilqc94pi2upzvabttikrfr5d] restart_policy: condition: none networks: nw_swarm: schedulerdb: image: mariadb:latest environment: MYSQL_ALLOW_EMPTY_PASSWORD: 'yes' MYSQL_DATABASE: schedulerdb MYSQL_USER: **** MYSQL_PASSWORD: **** command: ['--character-set-server=utf8mb4', '--collation-server=utf8mb4_unicode_ci', '--explicit_defaults_for_timestamp=1'] deploy: replicas: 1 placement: constraints: [node.id == kilqc94pi2upzvabttikrfr5d] restart_policy: condition: none networks: nw_swarm: celerydb: image: mariadb:latest environment: MYSQL_ALLOW_EMPTY_PASSWORD: 'yes' MYSQL_DATABASE: celerydb MYSQL_USER: **** MYSQL_PASSWORD: **** deploy: replicas: 1 placement: constraints: [node.id == kilqc94pi2upzvabttikrfr5d] restart_policy: condition: none networks: nw_swarm: cluster: image: $CENTOS7 environment: - CENTOS - CI_ENVIRONMENT_NAME - CI_API_V4_URL - CI_REPOSITORY_URL - CI_PROJECT_ID - CI_PROJECT_URL - CI_PROJECT_PATH - CI_PROJECT_NAME - CI_COMMIT_REF_NAME - CI_BIN_DEPENDENCIES_JOB command: > sudo -u myusername -H /bin/bash -c ". /etc/profile && mkdir -p /storage1/$CI_COMMIT_REF_NAME/$CI_PROJECT_NAME && cd /storage1/$CI_COMMIT_REF_NAME/$CI_PROJECT_NAME && git clone -b $CI_COMMIT_REF_NAME $CI_REPOSITORY_URL . && curl $CI_API_V4_URL/projects/$CI_PROJECT_ID/jobs/artifacts/$CI_COMMIT_REF_NAME/download?job=$CI_BIN_DEPENDENCIES_JOB -o artifacts.zip && unzip artifacts.zip ; cd /storage1/$CI_COMMIT_REF_NAME/$CI_PROJECT_NAME/scripts/deploy/ && python3 createconfig.py -s $CI_ENVIRONMENT_NAME && /bin/bash install_venv.sh -d -r ../../requirements.txt && python3 prepare_init.d.py && python3 deploy.py -s $CI_ENVIRONMENT_NAME" deploy: replicas: 1 placement: constraints: [node.id == kilqc94pi2upzvabttikrfr5d] restart_policy: condition: none tty: true stdin_open: true networks: nw_swarm: networks: nw_swarm: external: true
Здесь видно, что компоненты объединены одной сетью (nw_swarm) и друг другу доступны.
Системные компоненты (на основе redis, mysql) разделены от общего пула кастомных компонентов (в планах и кастомные разделить как сервисы). Стадия деплоя нашего кластера выглядит как передача CMD в наш один большой сконфигурированный image и в целом практически не отличается от деплоя, описанного в Части I. Подчеркну отличия:
- git clone ... — получаем файлы, необходимые, чтобы произвести деплой (createconfig.py, install_venv.sh и т.п.)
- curl… && unzip ... — скачиваем и разархивируем артефакты сборки (скомпилированные утилиты)
Осталась только одна пока неописанная проблема: компоненты, которые имеют веб-интерфейс не доступны из браузеров разработчиков. Мы эту проблему решаем с помощью reverse proxy, таким образом:
В .gitlab-ci.yml после деплоя стэка кластера добавляем строчку деплоя балансировщика (который при комитах, только обновляет свою конфигурацию (создает новые конфигурационные файлы nginx по шаблону: /etc/nginx/conf.d/${CI_COMMIT_REF_NAME}.conf) — см. код docker-compose-nginx.yml)
- docker stack deploy -c docker-compose-nginx.yml ${CI_ENVIRONMENT_NAME} --with-registry-auth
docker-compose-nginx.yml
--- version: '3' services: nginx: image: nginx:latest environment: CI_COMMIT_REF_NAME: ${CI_COMMIT_REF_NAME} NGINX_CONFIG: |- server { listen 8080; server_name staging_${CI_COMMIT_REF_NAME}_cluster.dev; location / { proxy_pass http://staging_${CI_COMMIT_REF_NAME}_cluster:8080; } } server { listen 5555; server_name staging_${CI_COMMIT_REF_NAME}_cluster.dev; location / { proxy_pass http://staging_${CI_COMMIT_REF_NAME}_cluster:5555; } } volumes: - /tmp/staging/nginx:/etc/nginx/conf.d command: /bin/bash -c "echo -e \"$$NGINX_CONFIG\" > /etc/nginx/conf.d/${CI_COMMIT_REF_NAME}.conf; nginx -g \"daemon off;\"; /etc/init.d/nginx reload" ports: - 8080:8080 - 5555:5555 - 3000:3000 - 443:443 - 80:80 deploy: replicas: 1 placement: constraints: [node.id == kilqc94pi2upzvabttikrfr5d] restart_policy: condition: none networks: nw_swarm: networks: nw_swarm: external: true
На компьютерах разработчиков обновляем /etc/hosts; прописываем url до nginx:
10.50.173.106 staging_BRANCH-1831_cluster.dev
Итак, деплой изолированных staging-кластеров реализован и разработчики теперь могут запускать их в
Дальнейшие планы:
- Разделить наши компоненты как сервисы
- Завести для каждого Dockerfile
- Автоматически определять менее загруженные ноды в стэке
- Задавать ноды по шаблону имени (а не использовать id как в статье)
- Добавить проверку, что стэк уничтожен
- ...
Отдельная благодарность за статью.

