Добрый день, Хабрахабр. Это еще один пост в рамках моей программы по обогащению базы данных крупнейшего IT-ресурса информацией по алгоритмам и структурам данных. Как показывает практика, этой информации многим не хватает, а необходимость встречается в самых разнообразных сферах программистской жизни.
Я продолжаю преимущественно выбирать те алгоритмы/структуры, которые легко понимаются и для которых не требуется много кода — а вот практическое значение сложно недооценить. В прошлый раз это было декартово дерево. В этот раз — система непересекающихся множеств. Она же известна под названиями disjoint set union (DSU) или Union-Find.
Поставим перед собой следующую задачу. Пускай мы оперируем элементами N видов (для простоты, здесь и далее — числами от 0 до N-1). Некоторые группы чисел объединены в множества. Также мы можем добавить в структуру новый элемент, он тем самым образует множество размера 1 из самого себя. И наконец, периодически некоторые два множества нам потребуется сливать в одно.
Формализируем задачу: создать быструю структуру, которая поддерживает следующие операции:
MakeSet(X) — внести в структуру новый элемент X, создать для него множество размера 1 из самого себя.
Find(X) — возвратить идентификатор множества, которому принадлежит элемент X. В качестве идентификатора мы будем выбирать один элемент из этого множества — представителя множества. Гарантируется, что для одного и того же множества представитель будет возвращаться один и тот же, иначе невозможно будет работать со структурой: не будет корректной даже проверка принадлежности двух элементов одному множеству
Unite(X, Y) — объединить два множества, в которых лежат элементы X и Y, в одно новое.
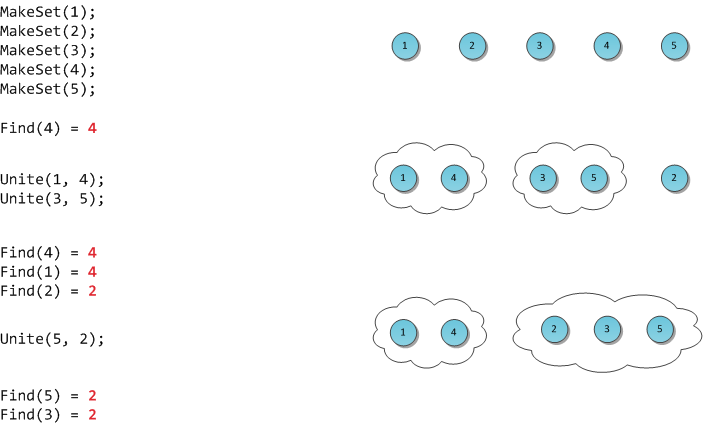
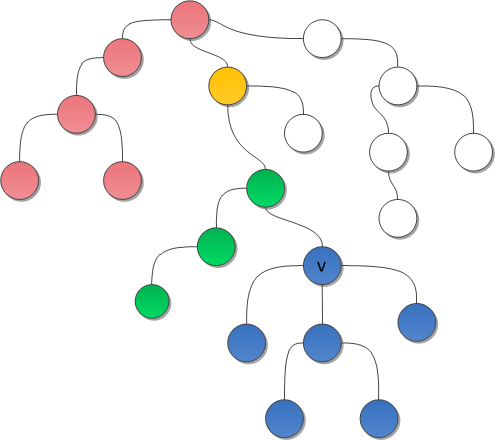
На рисунке я продемонстрирую работу такой гипотетической структуры.
Классическая реализация DSU была предложена Bernard Galler и Michael Fischer в 1964 году, однако исследована (включая временную оценку сложности) Робертом Тарьяном уже в 1975. Тарьяну же принадлежат некоторые результаты, улучшения и применения, о которых мы сегодня ещё поговорим.
Хранить структуру данных будем в виде леса, то есть превратим DSU в систему непересекающихся деревьев. Все элементы одного множества лежат в одном соответствующем дереве, представитель дерева — его корень, слияние множеств суть просто объединение двух деревьев в одно. Как мы увидим, такая идея вкупе с двумя небольшими эвристиками ведет к поразительно высокому быстродействию получившейся структуры.
Для начала нам потребуется массив p, хранящий для каждой вершины дерева её непосредственного предка (а для корня дерева X — его самого). С помощью одного только этого массива можно эффективно реализовать две первые операции DSU:
Чтобы создать новое дерево из элемента X, достаточно указать, что он является корнем собственного дерева, и предка не имеет.
Представителем дерева будем считать его корень. Тогда для нахождения этого представителя достаточно подняться вверх по родительским ссылкам до тех пор, пока не наткнемся на корень.
Но это еще не все: такая наивная реализация в случае вырожденного (вытянутого в линию) дерева может работать за O(N), что недопустимо. Можно было бы попытаться ускорить поиск. Например, хранить не только непосредственного предка, а большие таблицы логарифмического подъема вверх, но это требует много памяти. Или хранить вместо ссылки на предка ссылку на собственно корень — однако тогда при слиянии деревьев (Unite) придется менять эти ссылки всем элементам одного из деревьев, а это опять-таки временные затраты порядка O(N).
Мы пойдем другим путём: вместо ускорения реализации будем просто пытаться не допускать чрезмерно длинных веток в дереве. Это первая эвристика DSU, она называется сжатие путей (path compression). Суть эвристики: после того, как представитель таки будет найден, мы для каждой вершины по пути от X к корню изменим предка на этого самого представителя. То есть фактически переподвесим все эти вершины вместо длинной ветви непосредственно к корню. Таким образом, реализация операции Find становится двухпроходной.
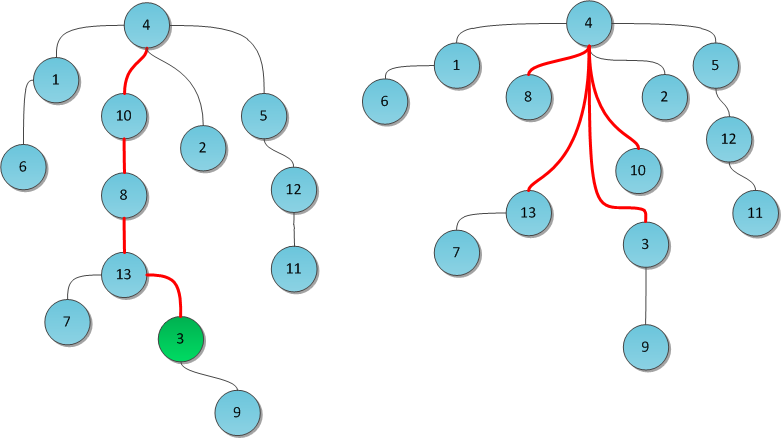
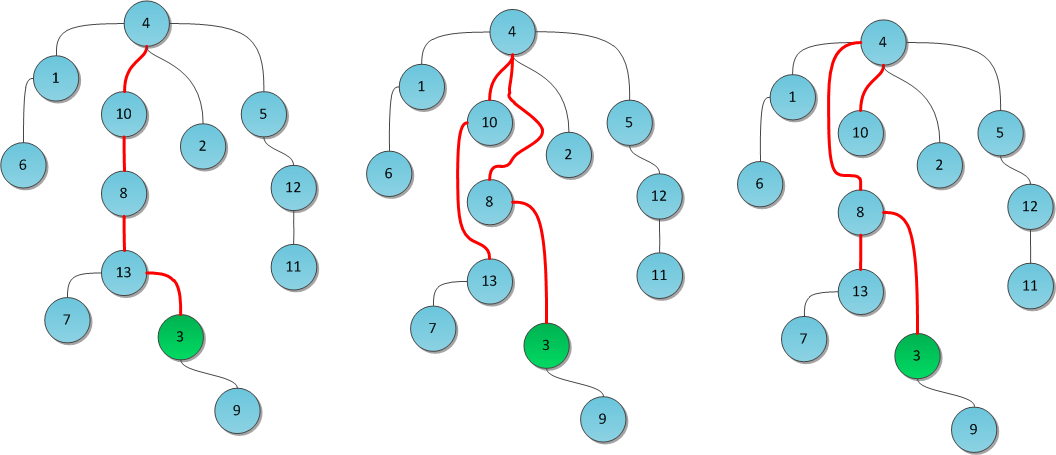
На рисунке показано дерево до и после выполнения операции Find(3). Красные ребра — те, по которым мы прошлись по пути к корню. Теперь они перенаправлены. Заметьте, как после этого кардинально уменьшилась высота дерева.
Исходный код в рекурсивной форме написать достаточно просто:
Со слиянием двух деревьев придется чуть повозиться. Найдем для начала корни обоих сливаемых деревьев с помощью уже написанной функции Find. Теперь, помня, что наша реализация хранит только ссылки на непосредственных родителей, для слияния деревьев достаточно было бы просто подвесить один из корней (а с ним и все дерево) сыном к другому. Таким образом все элементы этого дерева автоматически станут принадлежать другому — и процедура поиска представителя будет возвращать корень нового дерева.
Встает вопрос: какое дерево к какому подвешивать? Всегда выбирать какое-то одно, скажем, дерево X, не годится: легко подобрать пример, на котором после N объединений мы получим вырожденное дерево — одну ветку из N элементов. И тут в ход вступает вторая эвристика DSU, направленная на уменьшение высоты деревьев.
Будем хранить помимо предков еще один массив Rank. В нем для каждого дерева будет храниться верхняя граница его высоты — то есть длиннейшей ветви в нем. Заметьте, не сама высота — в процессе выполнения Find длиннейшая ветвь может самоуничтожиться, а тратить еще итерации на нахождение новой длиннейшей ветви слишком дорого. Поэтому для каждого корня в массиве Rank будет записано число, гарантированно больше или равное высоте его дерева.
Теперь легко принять решении о слиянии: чтобы не допустить слишком длинных ветвей в DSU, будем подвешивать более низкое дерево к более высокому. Если их высоты равны — не играет роли, кого подвешивать к кому. Но в последнем случае новоиспеченному корню надо не забыть увеличить Rank.
Вот так производится типичный Unite (например, с параметрами 8 и 19):
Однако на практике оказывается, что можно и не тратить дополнительные O(N) памяти на махинации с рангами. Достаточно выбирать корень для переподвешивания случайным образом — как ни удивительно, но такое решение дает на практике скорость, вполне сравнимую с оригинальной ранговой реализацией. Автор данной статьи всю жизнь пользуется именно рандомизированным DSU, и еще не было случая, когда тот бы подвёл.
Реализация на C#:
В силу применения двух эвристик скорость работы каждой операции сильно зависит от структуры дерева, а структура дерева — от списка выполненных до того операций. Исключение составляет только MakeSet — её время работы очевидно O(1) :-) Для остальных двух скорость очень неочевидна.
Роберт Тарьян доказал в 1975 г. замечательный факт: время работы как Find, так и Unite на лесе размера N есть O(α(N)).
Под α(N) в математике обозначается обратная функция Аккермана, то есть, функция, обратная дляf(N) = A(N, N) . Функция Аккермана A(N, M) известна тем, что у нее колоссальная скорость роста. К примеру, A(4, 4) = 22265536-3 , это число поистине огромно. Вообще, для всех мыслимых практических значений N обратная функция Аккермана от него не превысит 5. Поэтому её можно принять за константу и считать O(α(N)) ≅ O(1) .
Итак, имеем:
MakeSet(X) — O(1).
Find(X) — O(1) амортизированно.
Unite(X, Y) — O(1) амортизированно.
Расход памяти — O(N).
Совсем неплохо :-)
Для DSU известно большое число различных использований. Большинство связано с решением некоторой задачи в режиме оффлайн — то есть когда список запросов касательно структуры, которые поступают программе, известен заранее. Я приведу здесь несколько таких задач вместе с краткими идеями решений.
Дан неориентированный связный граф со взвешенными ребрами. Выкинуть из него некоторые ребра так, чтобы в итоге получилось дерево, причем суммарный вес ребер этого дерева должен быть наименьшим.
Одно из известных мест, где встает эта задача (хотя и решается иначе) — блокирование избыточных связей в Ethernet-сети для избегания возможных циклов пакетов. Протоколы, созданные с этой целью, широко известны, причем половина серьезных модификаций в них сделана Cisco. Более подробно см. Spanning Tree Protocol.
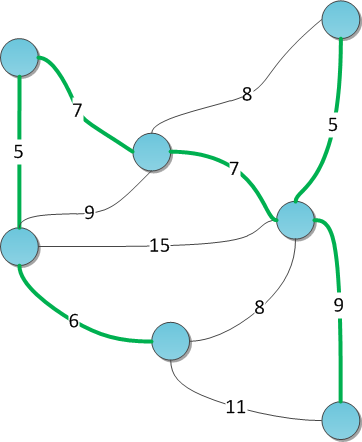
На рисунке показан взвешенный граф с выделенным минимальным остовом.
Алгоритм Краскала для решения этой задачи: отсортируем все ребра по возрастанию веса и будем поддерживать текущий лес минимального веса с помощью DSU. Изначально DSU состоит из N деревьев, по одной вершине в каждом. Идем по ребрам в порядке возврастания; если текущее ребро объединяет разные компоненты — сливаем их в одну и запоминаем ребро как элемент остова. Как только количество компонент достигнет единицы — мы построили искомое дерево.
Дано дерево и набор запросов вида: для данных вершин u и v вернуть их ближайшего общего предка (least common ancestor, LCA). Весь набор запросов известен заранее, т.е. задача сформулирована в режиме оффлайн.
Запустим для начала поиск в глубину по дереву. Рассмотрим некоторый запрос <u, v>. Пускай поиск в глубину пришел в такое состояние, что одна из вершин запроса (скажем, u) уже была посещена поиском ранее, и сейчас текущей вершиной в поиске является v, все поддерево v только что было осмотрено. Очевидно, что ответом на запрос будет либо сама вершина v, либо какой-то из её предков. Причем каждый из предков v по пути к корню порождает некоторый класс вершин u, для которых он является ответом: этот класс в точности равен уже просмотренной ветке дерева «слева» от такого предка.
На рисунке можно увидеть дерево с разбиением вершин на классы, при этом белые вершины — еще непросмотренные.
Классы таких вершин не пересекаются между собой, а значит, их можно поддерживать в DSU. Как только поиск в глубину вернется из поддерева — сливать класс этого поддерева с классом текущей вершины. И для поиска ответа поддерживать массив Ancestor — для каждой вершины собственно предок, породивший класс этой вершины. Значение ячейки этого массива для представителя надо не забыть переписать при слиянии деревьев. Зато теперь в процессе поиска в глубину для каждой полностью обработанной вершины v мы можем найти в списке запросов все <u, v>, где u — уже обработана, и вывести ответ:
Дан мультиграф (граф, в котором пара вершин может быть соединена более чем одним непосредственным ребром), к которому поступают запросы вида «удалить некоторое ребро» и «а сколько сейчас в графе компонент связности?» Весь список запросов известен заранее.
Решение банально. Выполним сначала все запросы на удаление, посчитаем количество компонент в итоговом графе, запомним его. Получившийся граф запихнем в DSU. Теперь будем идти по запросам удаления в обратном порядке: каждое удаление ребра из старого графа означает возможное слияние двух компонент в нашем «flashback-графе», хранящемся в DSU; в таком случае текущее количество компонент связности уменьшается на единичку.
Рассмотрим некоторое изображение — прямоугольный массив пикселей. Его можно представить как сетчатый граф: каждая вершина-пиксель непосредственно связана ребрами со своими четырьмя ближайшими соседями. Задача заключается в том, чтобы выделить на изображении одинаковые смысловые зоны, например, похожего цвета, и уметь для двух пикселей быстро определять, находятся ли они в одной зоне. Так, например, раскрашиваются старые черно-белые фильмы: для начала нужно выделить области с примерно одинаковыми оттенками серого.
Есть два подхода к решению этой проблемы, оба в конечном итоге используют DSU. В первом варианте мы проводим ребро не между каждой парой соседних пикселей, а только между теми, которые достаточно близки по цвету. После этого обычный прямоугольный обход графа заполнит DSU, и мы получим набор компонент связности — они же однотонные области изображения.
Второй вариант более гибкий. Не будем полностью убирать ребра, а присвоим каждому из них вес, рассчитанный на основании разности цветов и еще каких-то дополнительных факторов — своих для каждой конкретной задачи сегментирования. В полученном графе достаточно найти какой-нибудь лес минимального веса, например, тем же алгоритмом Краскала. На практике в DSU записывают не любое текущее соединяющее ребро, а только те, для которых на данный момент две компоненты не сильно отличаются по меркам другой специальной весовой функции.
Задача: сгенерировать лабиринт с одним входом и одним выходом.
Алгоритм решения:
Начнем с состояния, когда установлены все стены, за исключением входа и выхода.
На каждом шаге алгоритма выберем случайную стену. Если ячейки, между которыми она стоит, еще никак не соединены (лежат в разных компонентах DSU), то уничтожаем её (сливаем компоненты).
Продолжаем процесс до некоторого состояния сходимости: например, когда вход и выход соединены; либо, когда осталась одна компонента.
Существуют варианты реализации Find(X), которые требуют одного прохода до корня, а не двух, однако сохраняют ту же или почти ту же степень быстродействия. Они реализуют другие стратегии сокращения высоты дерева, в отличие от path compression.
Вариант №1: path splitting. По пути от вершины Х до корня перенаправить родительскую связь каждой вершины с её предка на предка предка (дедушку).
Вариант №2: path halving. Взять идею path splitting, однако перенаправлять связи не всех вершин по пути, а только тех, на которых делаем перенаправления — то есть «дедушек».
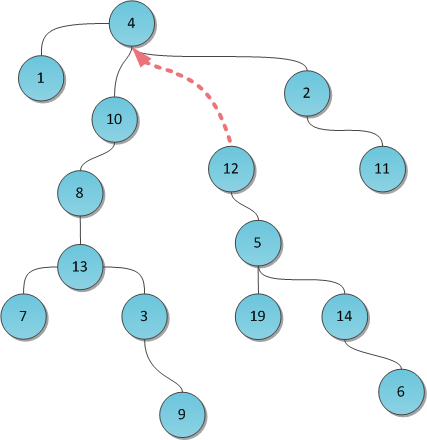
На рисунке взято все то же дерево, в нем выполняется запрос Find(3). По центру показан результат с применением path splitting, справа — path halving.
У системы непересекающихся множеств есть один большой недостаток: она не поддерживает ни в какой форме операцию Undo, потому что реализована насквозь в императивном стиле. Гораздо удобнее была бы реализация DSU в функциональном стиле, когда каждая операция не изменяет структуру на месте, а возвращает слегка модифицированную новую структуру, в которой произведены требуемые изменения (при этом большая часть памяти у старой и новой структур общая). Такие структуры данных в английской терминологии носят название persistent, они широко применяются в чистом функциональном программировании, где доминирует идея неизменяемости данных.
В силу чисто императивной идеи алгоритмов DSU её функциональная реализация с сохранением быстродействия долгое время казалась немыслимой. Тем не менее, в 2007 году Sylvain Conchon и Jean-Christophe Filliâtre представили в своей работе искомый функциональный вариант, в котором операция Unite возвращает измененную структуру. Если говорить честно, он не совсем функциональный, он использует императивные присваивания, однако они надежно скрыты внутри реализации, а интерфейс persistent DSU — чисто функциональный.
Основная идея реализации — использование структур данных, реализующих «персистентные массивы»: они поддерживают те же операции, что и массивы, однако все так же не модифицируют память, а возвращают измененную структуру. Такой массив можно легко реализовать с помощью какого-нибудь дерева, однако в таком случае операции с ним будут занимать O(log2 N) времени, а для DSU такая оценка оказывается уже чрезмерно большой.
За дальнейшими техническими подробностями отсылаю читателей к оригинальной статье.
Системы непересекающихся множеств в объеме данной статьи обсуждаются в знаменитой книге — Кормен, Лейзерсон, Ривест, Штайн «Алгоритмы: построение и анализ». Там же можно найти и доказательство того, что выполнение операций занимает порядка α(N) времени.
На сайте Максима Иванова можно найти полную реализацию DSU на C++.
В статье Wait-free Parallel Algorithms for the Union-Find Problem обсуждается парралельная версия реализации DSU. В ней отсутствуют блокировки потоков.
Всем спасибо за внимание :-)
Я продолжаю преимущественно выбирать те алгоритмы/структуры, которые легко понимаются и для которых не требуется много кода — а вот практическое значение сложно недооценить. В прошлый раз это было декартово дерево. В этот раз — система непересекающихся множеств. Она же известна под названиями disjoint set union (DSU) или Union-Find.
Условие
Поставим перед собой следующую задачу. Пускай мы оперируем элементами N видов (для простоты, здесь и далее — числами от 0 до N-1). Некоторые группы чисел объединены в множества. Также мы можем добавить в структуру новый элемент, он тем самым образует множество размера 1 из самого себя. И наконец, периодически некоторые два множества нам потребуется сливать в одно.
Формализируем задачу: создать быструю структуру, которая поддерживает следующие операции:
MakeSet(X) — внести в структуру новый элемент X, создать для него множество размера 1 из самого себя.
Find(X) — возвратить идентификатор множества, которому принадлежит элемент X. В качестве идентификатора мы будем выбирать один элемент из этого множества — представителя множества. Гарантируется, что для одного и того же множества представитель будет возвращаться один и тот же, иначе невозможно будет работать со структурой: не будет корректной даже проверка принадлежности двух элементов одному множеству
if (Find(X) == Find(Y)).Unite(X, Y) — объединить два множества, в которых лежат элементы X и Y, в одно новое.
На рисунке я продемонстрирую работу такой гипотетической структуры.
Реализация
Классическая реализация DSU была предложена Bernard Galler и Michael Fischer в 1964 году, однако исследована (включая временную оценку сложности) Робертом Тарьяном уже в 1975. Тарьяну же принадлежат некоторые результаты, улучшения и применения, о которых мы сегодня ещё поговорим.
Хранить структуру данных будем в виде леса, то есть превратим DSU в систему непересекающихся деревьев. Все элементы одного множества лежат в одном соответствующем дереве, представитель дерева — его корень, слияние множеств суть просто объединение двух деревьев в одно. Как мы увидим, такая идея вкупе с двумя небольшими эвристиками ведет к поразительно высокому быстродействию получившейся структуры.
Для начала нам потребуется массив p, хранящий для каждой вершины дерева её непосредственного предка (а для корня дерева X — его самого). С помощью одного только этого массива можно эффективно реализовать две первые операции DSU:
MakeSet(X)
Чтобы создать новое дерево из элемента X, достаточно указать, что он является корнем собственного дерева, и предка не имеет.
public void MakeSet(int x) { p[x] = x; }
Find(X)
Представителем дерева будем считать его корень. Тогда для нахождения этого представителя достаточно подняться вверх по родительским ссылкам до тех пор, пока не наткнемся на корень.
Но это еще не все: такая наивная реализация в случае вырожденного (вытянутого в линию) дерева может работать за O(N), что недопустимо. Можно было бы попытаться ускорить поиск. Например, хранить не только непосредственного предка, а большие таблицы логарифмического подъема вверх, но это требует много памяти. Или хранить вместо ссылки на предка ссылку на собственно корень — однако тогда при слиянии деревьев (Unite) придется менять эти ссылки всем элементам одного из деревьев, а это опять-таки временные затраты порядка O(N).
Мы пойдем другим путём: вместо ускорения реализации будем просто пытаться не допускать чрезмерно длинных веток в дереве. Это первая эвристика DSU, она называется сжатие путей (path compression). Суть эвристики: после того, как представитель таки будет найден, мы для каждой вершины по пути от X к корню изменим предка на этого самого представителя. То есть фактически переподвесим все эти вершины вместо длинной ветви непосредственно к корню. Таким образом, реализация операции Find становится двухпроходной.
На рисунке показано дерево до и после выполнения операции Find(3). Красные ребра — те, по которым мы прошлись по пути к корню. Теперь они перенаправлены. Заметьте, как после этого кардинально уменьшилась высота дерева.
Исходный код в рекурсивной форме написать достаточно просто:
public int Find(int x) { if (p[x] == x) return x; return p[x] = Find(p[x]); }
Unite(X, Y)
Со слиянием двух деревьев придется чуть повозиться. Найдем для начала корни обоих сливаемых деревьев с помощью уже написанной функции Find. Теперь, помня, что наша реализация хранит только ссылки на непосредственных родителей, для слияния деревьев достаточно было бы просто подвесить один из корней (а с ним и все дерево) сыном к другому. Таким образом все элементы этого дерева автоматически станут принадлежать другому — и процедура поиска представителя будет возвращать корень нового дерева.
Встает вопрос: какое дерево к какому подвешивать? Всегда выбирать какое-то одно, скажем, дерево X, не годится: легко подобрать пример, на котором после N объединений мы получим вырожденное дерево — одну ветку из N элементов. И тут в ход вступает вторая эвристика DSU, направленная на уменьшение высоты деревьев.
Будем хранить помимо предков еще один массив Rank. В нем для каждого дерева будет храниться верхняя граница его высоты — то есть длиннейшей ветви в нем. Заметьте, не сама высота — в процессе выполнения Find длиннейшая ветвь может самоуничтожиться, а тратить еще итерации на нахождение новой длиннейшей ветви слишком дорого. Поэтому для каждого корня в массиве Rank будет записано число, гарантированно больше или равное высоте его дерева.
Теперь легко принять решении о слиянии: чтобы не допустить слишком длинных ветвей в DSU, будем подвешивать более низкое дерево к более высокому. Если их высоты равны — не играет роли, кого подвешивать к кому. Но в последнем случае новоиспеченному корню надо не забыть увеличить Rank.
Вот так производится типичный Unite (например, с параметрами 8 и 19):
public void Unite(int x, int y) { x = Find(x); y = Find(y); if (rank[x] < rank[y]) p[x] = y; else { p[y] = x; if (rank[x] == rank[y]) ++rank[x]; } }
Однако на практике оказывается, что можно и не тратить дополнительные O(N) памяти на махинации с рангами. Достаточно выбирать корень для переподвешивания случайным образом — как ни удивительно, но такое решение дает на практике скорость, вполне сравнимую с оригинальной ранговой реализацией. Автор данной статьи всю жизнь пользуется именно рандомизированным DSU, и еще не было случая, когда тот бы подвёл.
Реализация на C#:
public void Unite(int x, int y) { x = Find(x); y = Find(y); if (rand.Next() % 2 == 0) Swap(ref x, ref y); p[x] = y; }
Быстродействие
В силу применения двух эвристик скорость работы каждой операции сильно зависит от структуры дерева, а структура дерева — от списка выполненных до того операций. Исключение составляет только MakeSet — её время работы очевидно O(1) :-) Для остальных двух скорость очень неочевидна.
Роберт Тарьян доказал в 1975 г. замечательный факт: время работы как Find, так и Unite на лесе размера N есть O(α(N)).
Под α(N) в математике обозначается обратная функция Аккермана, то есть, функция, обратная для
Итак, имеем:
MakeSet(X) — O(1).
Find(X) — O(1) амортизированно.
Unite(X, Y) — O(1) амортизированно.
Расход памяти — O(N).
Совсем неплохо :-)
Практические применения
Для DSU известно большое число различных использований. Большинство связано с решением некоторой задачи в режиме оффлайн — то есть когда список запросов касательно структуры, которые поступают программе, известен заранее. Я приведу здесь несколько таких задач вместе с краткими идеями решений.
Остов минимального веса
Дан неориентированный связный граф со взвешенными ребрами. Выкинуть из него некоторые ребра так, чтобы в итоге получилось дерево, причем суммарный вес ребер этого дерева должен быть наименьшим.
Одно из известных мест, где встает эта задача (хотя и решается иначе) — блокирование избыточных связей в Ethernet-сети для избегания возможных циклов пакетов. Протоколы, созданные с этой целью, широко известны, причем половина серьезных модификаций в них сделана Cisco. Более подробно см. Spanning Tree Protocol.
На рисунке показан взвешенный граф с выделенным минимальным остовом.
Алгоритм Краскала для решения этой задачи: отсортируем все ребра по возрастанию веса и будем поддерживать текущий лес минимального веса с помощью DSU. Изначально DSU состоит из N деревьев, по одной вершине в каждом. Идем по ребрам в порядке возврастания; если текущее ребро объединяет разные компоненты — сливаем их в одну и запоминаем ребро как элемент остова. Как только количество компонент достигнет единицы — мы построили искомое дерево.
Алгоритм Тарьяна для поиска LCA оффлайн
Дано дерево и набор запросов вида: для данных вершин u и v вернуть их ближайшего общего предка (least common ancestor, LCA). Весь набор запросов известен заранее, т.е. задача сформулирована в режиме оффлайн.
Запустим для начала поиск в глубину по дереву. Рассмотрим некоторый запрос <u, v>. Пускай поиск в глубину пришел в такое состояние, что одна из вершин запроса (скажем, u) уже была посещена поиском ранее, и сейчас текущей вершиной в поиске является v, все поддерево v только что было осмотрено. Очевидно, что ответом на запрос будет либо сама вершина v, либо какой-то из её предков. Причем каждый из предков v по пути к корню порождает некоторый класс вершин u, для которых он является ответом: этот класс в точности равен уже просмотренной ветке дерева «слева» от такого предка.
На рисунке можно увидеть дерево с разбиением вершин на классы, при этом белые вершины — еще непросмотренные.
Классы таких вершин не пересекаются между собой, а значит, их можно поддерживать в DSU. Как только поиск в глубину вернется из поддерева — сливать класс этого поддерева с классом текущей вершины. И для поиска ответа поддерживать массив Ancestor — для каждой вершины собственно предок, породивший класс этой вершины. Значение ячейки этого массива для представителя надо не забыть переписать при слиянии деревьев. Зато теперь в процессе поиска в глубину для каждой полностью обработанной вершины v мы можем найти в списке запросов все <u, v>, где u — уже обработана, и вывести ответ:
Ancestor[Find(u)].Компоненты связности в мультиграфе
Дан мультиграф (граф, в котором пара вершин может быть соединена более чем одним непосредственным ребром), к которому поступают запросы вида «удалить некоторое ребро» и «а сколько сейчас в графе компонент связности?» Весь список запросов известен заранее.
Решение банально. Выполним сначала все запросы на удаление, посчитаем количество компонент в итоговом графе, запомним его. Получившийся граф запихнем в DSU. Теперь будем идти по запросам удаления в обратном порядке: каждое удаление ребра из старого графа означает возможное слияние двух компонент в нашем «flashback-графе», хранящемся в DSU; в таком случае текущее количество компонент связности уменьшается на единичку.
Сегментирование изображений
Рассмотрим некоторое изображение — прямоугольный массив пикселей. Его можно представить как сетчатый граф: каждая вершина-пиксель непосредственно связана ребрами со своими четырьмя ближайшими соседями. Задача заключается в том, чтобы выделить на изображении одинаковые смысловые зоны, например, похожего цвета, и уметь для двух пикселей быстро определять, находятся ли они в одной зоне. Так, например, раскрашиваются старые черно-белые фильмы: для начала нужно выделить области с примерно одинаковыми оттенками серого.
Есть два подхода к решению этой проблемы, оба в конечном итоге используют DSU. В первом варианте мы проводим ребро не между каждой парой соседних пикселей, а только между теми, которые достаточно близки по цвету. После этого обычный прямоугольный обход графа заполнит DSU, и мы получим набор компонент связности — они же однотонные области изображения.
Второй вариант более гибкий. Не будем полностью убирать ребра, а присвоим каждому из них вес, рассчитанный на основании разности цветов и еще каких-то дополнительных факторов — своих для каждой конкретной задачи сегментирования. В полученном графе достаточно найти какой-нибудь лес минимального веса, например, тем же алгоритмом Краскала. На практике в DSU записывают не любое текущее соединяющее ребро, а только те, для которых на данный момент две компоненты не сильно отличаются по меркам другой специальной весовой функции.
Генерация лабиринтов
Задача: сгенерировать лабиринт с одним входом и одним выходом.
Алгоритм решения:
Начнем с состояния, когда установлены все стены, за исключением входа и выхода.
На каждом шаге алгоритма выберем случайную стену. Если ячейки, между которыми она стоит, еще никак не соединены (лежат в разных компонентах DSU), то уничтожаем её (сливаем компоненты).
Продолжаем процесс до некоторого состояния сходимости: например, когда вход и выход соединены; либо, когда осталась одна компонента.
Однопроходные алгоритмы
Существуют варианты реализации Find(X), которые требуют одного прохода до корня, а не двух, однако сохраняют ту же или почти ту же степень быстродействия. Они реализуют другие стратегии сокращения высоты дерева, в отличие от path compression.
Вариант №1: path splitting. По пути от вершины Х до корня перенаправить родительскую связь каждой вершины с её предка на предка предка (дедушку).
Вариант №2: path halving. Взять идею path splitting, однако перенаправлять связи не всех вершин по пути, а только тех, на которых делаем перенаправления — то есть «дедушек».
На рисунке взято все то же дерево, в нем выполняется запрос Find(3). По центру показан результат с применением path splitting, справа — path halving.
Функциональная реализация
У системы непересекающихся множеств есть один большой недостаток: она не поддерживает ни в какой форме операцию Undo, потому что реализована насквозь в императивном стиле. Гораздо удобнее была бы реализация DSU в функциональном стиле, когда каждая операция не изменяет структуру на месте, а возвращает слегка модифицированную новую структуру, в которой произведены требуемые изменения (при этом большая часть памяти у старой и новой структур общая). Такие структуры данных в английской терминологии носят название persistent, они широко применяются в чистом функциональном программировании, где доминирует идея неизменяемости данных.
В силу чисто императивной идеи алгоритмов DSU её функциональная реализация с сохранением быстродействия долгое время казалась немыслимой. Тем не менее, в 2007 году Sylvain Conchon и Jean-Christophe Filliâtre представили в своей работе искомый функциональный вариант, в котором операция Unite возвращает измененную структуру. Если говорить честно, он не совсем функциональный, он использует императивные присваивания, однако они надежно скрыты внутри реализации, а интерфейс persistent DSU — чисто функциональный.
Основная идея реализации — использование структур данных, реализующих «персистентные массивы»: они поддерживают те же операции, что и массивы, однако все так же не модифицируют память, а возвращают измененную структуру. Такой массив можно легко реализовать с помощью какого-нибудь дерева, однако в таком случае операции с ним будут занимать O(log2 N) времени, а для DSU такая оценка оказывается уже чрезмерно большой.
За дальнейшими техническими подробностями отсылаю читателей к оригинальной статье.
Литература
Системы непересекающихся множеств в объеме данной статьи обсуждаются в знаменитой книге — Кормен, Лейзерсон, Ривест, Штайн «Алгоритмы: построение и анализ». Там же можно найти и доказательство того, что выполнение операций занимает порядка α(N) времени.
На сайте Максима Иванова можно найти полную реализацию DSU на C++.
В статье Wait-free Parallel Algorithms for the Union-Find Problem обсуждается парралельная версия реализации DSU. В ней отсутствуют блокировки потоков.
Всем спасибо за внимание :-)

