
Современный интернет развивается очень быстро и постоянно изменяется. Раньше были простые странички с текстом, сейчас — «живые» сайты с оригинальным дизайном, на жизнь которых влияем мы и которые, в свою очередь, меняются сами, подстраиваясь под окружающий мир словно хамелеоны.
Когда я понял, что время летит, сжигая старое и рождая новое — мне захотелось на мгновение остановиться, обернуться, посмотреть по сторонам. Было бы интересно вернуться в прошлое — там можно увидеть то, чего не видел ранее, то, чего в настоящем уже не существует, а в будущем будет другим. Удовлетворить простое любопытство, сравнить как выглядел сайт год назад и как выглядит сейчас — вот стимул, который заставил меня создать SaveWeb, который еще очень молод, но, кажется, уже умеет останавливать время :)
Идея
Идея регулярно сохранять состояние сайтов в виде скриншотов витала в моей голове давно. Сначала я не решался взяться за ее реализацию, много очевидных трудностей — нужны сервера, много дискового пространства для сохранения данных, широкий канал и другие ресурсы, которые сложно окупить. Ведь фактически идея убыточна с момента рождения, и в этом меня пытались убедить все. Однако, любопытство, интерес и скромная историческая значимость взяли верх и окончательно убедив в первую очередь себя, я принялся за создание прототипа.
Бекэнд
Для прототипа было взято 10 тысяч самых популярных сайтов из рейтинга Alexa, предварительно убрав некоторое количество мусора (к сожалению, не всё). Затем было написано два скрипта на Python — контроллер и, собственно, сама снималка скриншотов (далее — шотер). Шотер представляет из себя консольное приложение принимающее определенные параметры и на выходе выдающее результат в виде сохраненного скриншота (если удачно) или кода ошибки. Сам скриншот создается с помощью webkit (qt) запускающегося через Xvfb. Контроллер весь этот процесс контролирует и отвечает за логику и обработку результатов работы шотеров, так же обеспечивает многопоточность. Как показали эксперименты это наиболее оптимальное и стабильное решение для пакетного «скриншотинга» под никсами.
Фронтэнд
Вся и так несложная логика была написана на PHP. Сайты можно смотреть за определенную дату. Пополнение базы сайтов сделано в автоматическом режиме, если введенного URL нет — значит скоро будет. Так же на странице сайта можно понажимать клавишу R и побродить по историям существования других сайтов. Пожалуй из функционала это пока все :)
Дизайн
Минималистичный дизайн был нарисован задолго до начала разработки (в качестве документирования идеи) и он был сверстан в течении дня.
Вынужденные ограничения
К сожалению, у меня нет возможности полностью финансировать проект из собственного кармана (для желающих помочь материально — есть кнопка на сайте, буду очень благодарен), поэтому ресурсы несколько ограничены:
— Сайт, в понимание SaveWeb, это главная страница (фактически доменное имя). Страницы отдельно не сканируются. Это скорее концептуальное ограничение, однако в будущем может быть снято, если позволят ресурсы (их для этого должно быть очень много)
— Используется JPEG с сжатием (не очень сильным, но иногда заметным)
— Скриншот снимается размером 1280х1024, но дальше уменьшается по ширине до 1024 пикселей (для меньшего объема)
— По высоте скриншот обрезается до 3072 пикселей, соответственно если высота (длина) страницы больше, то в «кадр» попадет не всё
— Временно включен запрет на удаленную вставку изображений напрямую с сервера (hotlink protection)
Планы на будущее
— Естественно, хотелось бы снять как можно больше ограничений
— Собирать мета-информацию к сайтам: тиц, pr, alexa rank, другие показатели и параметры; рисовать по ним графики. Хочется разнообразить снимок сайта другой, не менее полезной и интересной информацией
— Англоязычная версия сайта (вот-вот появится)
— Есть много идей и мыслей по оптимизации работы системы в целом, сокращению издержек на ресурсы и прочее
— Внести дополнительные возможности в интерфейс сервиса, для большего удобства и наглядности (например, сделать режим сравнения)
Итого
Сейчас SaveWeb останавливает время примерно раз в месяц. На данный момент было пройдено несколько итераций и уже можно кое-что поразглядывать. Пока имеются средства и ресурсы на полгода работы проекта.
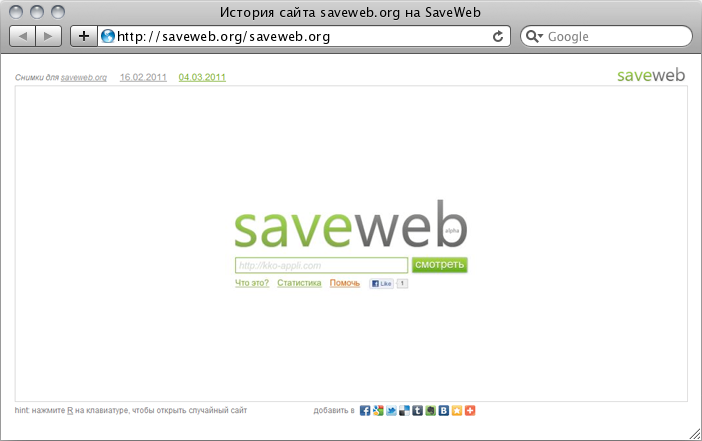
Рекурсивный SaveWeb. Если посмотреть за обе даты, то видны небольшие изменения :)
К чему все это?
Я описал создание простого, но амбициозного проекта, идея которого интриговала меня давно. Я очень рад что на данный момент уже создан прототип (или альфа-версия — кому как угодно). Сайты уже сохраняются и история уже создается, а значит главная цель выполнена. Однако я не собираюсь останавливаться на достигнутом и очень надеюсь, что через несколько лет мы по-прежнему сможем смотреть на результаты работы SaveWeb. Ведь чем дольше он работает, тем значимее его существование.
Этим постом я хотел бы поинтересоваться у хабрасообщества мнением по поводу данного проекта, собрать фидбек в виде идей и мыслей. И заранее спасибо вам за уделенное внимание.
А как же Wayback Machine?
В комментариях спрашивают, в чем отличие от всем известного проекта. Ожидал такие вопросы, поэтому отвечу в рамках статьи :)
Главное отличие в целях и подходах — Wayback Machine прежде всего сохраняет информационную составляющую ресурса, и пытается охватить как можно больше сайтов, любых. Идея SaveWeb — передать то, как выглядел интернет раньше, а не пытаться сохранить всё. Не нужно сохранять миллионы никому неизвестных сайтов, достаточно сохранить популярные, массовые — те самые, которые меняются словно хамелеоны.
Однако у Wayback Machine есть одно неоспоримое и огромное преимущество — время. Но с ним ничего не поделаешь, оно летит. Как говорится лучше поздно (начать), чем никогда ;)
