
Сразу оговоримся, не стоит воспринимать заголовок слишком буквально. Если звезды зажигают… и так далее.
Тем не менее, семейство протоколов Spannning Tree, если не отживает свой век в качестве основного инструмента резервирования в ethernet-сетях, то как минимум плавно перетекает в узкие и специфические ниши (само собой, их обсуждение выходит за всякие рамки этой статьи, но в приветствуется в комментариях).
И да, конечно, никто не отменял Spanning Tree как технологию защиты от человеческой ошибки.
Зачем оно нужно
Сперва позволим себе пару банальностей. Их, конечно, можно почерпнуть и из Википедии, но мы не можем удержаться.
Поскольку модель ВОС (она же ISO/OSI, если вам так больше нравится) забыла наделить канальный уровень функциями выбора оптимального пути передачи и исключения закольцовок, возложив оные на сетевой уровень, технология Ethernet таковыми функциями и не обладает. Вместо мороки с предварительным вычислением пути к адресу назначения ethernet-коммутатор, если не знает, куда посылать кадр — посылает его во все порты, кроме порта, через который передаваемый кадр был получен. А там, глядишь, найдется адресат, способный по содержимому сообразить, что это кадр для него. (Когда мы говорим о флудинге во все порты, за исключением совсем специальных случаев речь идет только о портах одного VLAN'а.)
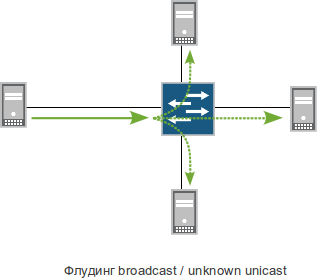
Коммутатор не был бы коммутатором, если б этим и ограничился. Все-таки он не настолько глуп, и чтобы не рассылать всем всё всегда, подглядывает в адреса источников и записывает их себе в табличку: MAC-адрес такой-то находится за таким-то портом. Процесс называется изучением MAC-адресов («мак-лернинг»). Сформировав такую таблицу (таблицу коммутации), коммутатор посылает кадры только в нужные порты.
Если же поверх Ethernet’а передается IP-трафик, а чаще всего так и есть, то кадров с неизвестными MAC-адресами назначения при хорошем раскладе (и прямых руках) возникать не должно, однако же тут никак нельзя обойтись без специальных кадров c адресом назначения «слать всем», передача которых сводится к тому же самому.
Итого, в ethernet-сетях флудинг, то есть копирование кадра во все возможные выходные порты является неотъемлемой частью процесса коммутации.
Теперь представьте, что случится, если в топологии сети обнаружится закольцовка. Одна из копий кадра вернется на расфлудивший его коммутатор, который снова его расфлудит, и так до тех пор, покуда у всех устройств в сети загрузка процессоров не достигнет ста процентов. Описываемая ситуация называется бродкастовым штормом. Кому доводилось наблюдать — не даст соврать, зрелище не для слабонервных.

Если вы с соседом сговорились забабахать домашнюю локалку, купив в магазине пару пластмассовых свитчиков, не пытайтесь для пущей скорости и вящей надежности соединить их двумя проводами вместо одного: лучше не станет, это уж как минимум.
С одной стороны — чего легче? — не втыкай лишних проводов, да и все. Но не так-то это просто. Ведь хочется, чтоб сеть была отказоустойчивой, с избыточными связями, резервируемыми узлами и автоматическим переключением при отказах. Иными словами, чтоб L2-сеть была как L3. Для достижения желаемого и, вместе с тем, чтоб уберечься от ужаса бродкастовых штормов, люди придумали специальные технологии для поиска циклов в топологии и принудительного их разрыва путем блокирования отдельных линков. Технологии эти и называются словом Spanning Tree.
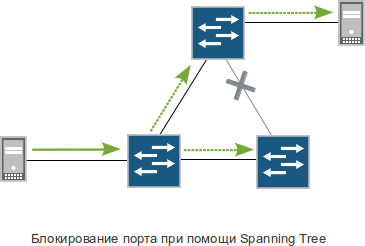
Именно технологии, во множественном числе. Ведь мало сказать «блокируют», важно еще понять, какой именно линк блокировать, через какой промежуток времени проверять, не пора ли разблокировать, как именно это делать, какие порты можно не проверять на наличие закольцовки, какие VLAN’ы по каким линкам передавать, как быстро все это происходит и т. д. Разные взгляды на эти и множество других вопросов породили целый ворох протоколов с общим названием Spanning Tree: STP, RSTP, PVST, PVST+, PVRST, MSTP, VSTP, наверняка есть и еще.
Читатели, всерьез изучавшие что-нибудь из вышеперечисленного, наверняка знакомы с ощущением, схожим на комбинацию сонливости и зубной боли, которое возникает в процессе изучения всех этих бесконечных состояний портов, механизмов формирования весов, алгоритмов выбора корневых коммутаторов, и прочей скукотени, уступающей в занудстве разве что учебнику анатомии. Те же, кто успешно справился с внедрением, эксплуатацией, траблшутингом и развитием сети хотя бы из полутора десятков коммутаторов, построенной на базе spanning tree, смело могут подавать в
Spanning Tree в переводе с английского означает «ветвящееся дерево». А дерево — это, в свою очередь, «связный ациклический граф», то есть граф без циклов (закольцовок), между двумя вершинами которого существует хотя бы один путь.
Почему оно не нужно
Теперь, наконец, о том, почему Spanning Tree стремительно теряет свою актуальность.
Вы, конечно, уже слышали, что в светлом будущем все будет во-первых общим, во-вторых виртуальным,
Технология объединения линков в агрегированные группы LAG aka EtherChannel появилась не вчера.
Кстати, не нужно путать само по себе объединение линков в LAG и протокол LACP, который помогает сделать это объединение (полу)автоматически, но из-за неумелого обращения в жизни от него больше проблем, чем пользы.
Идея проста. Два коммутатора — впрочем, не обязательно коммутатора, любых устройства, работающих на втором и более высоких уровнях — соединяются для надежности двумя проводами, а не одним. При этом коммутаторы настроены (вручную или посредством LACP) таким образом, что для них эти два провода являются одним линком. Слишком углубляться в детали не будем, об этом полно статей на любой вкус, лишь скажем, что агрегация может быть по одной из двух схем: «активный–активный» (наиболее популярная): трафик передается сразу по двум проводам с балансировкой нагрузки; и «активный–пассивный»: пока один линк в «апе», второй в «дауне», при падении основного происходит переключение на резервный.
В сущности, описанное выше — это простейший способ избавления от Spanning Tree на «одноколенном» уровне. Однако данный способ в общем случае требует, чтобы оба линка с каждой из сторон были подключены к одному коммутатору. Иначе возможны все те же закольцовки или осложнения, связанные с постоянным обновлением таблицы MAC-адресов.
Но тут на помощь приходит относительно (весьма относительно) современное изобретение — кластеризация коммутаторов. С ее помощью несколько физических устройств могут объединяться в одно логическое. Традиционно данную функцию принято считать «красивостью», призванной в первую очередь упростить управление. Однако же главные плюсы кластеризации коммутаторов совсем в другом. Помимо некоторых технико-коммерческих аспектов, кластеризация — это еще и сокращение количества узлов в топологии при сохранении резервирования физических устройств.

Сегодня главным драйвером растущей популярности кластеризуемых коммутаторов является именно возможность объединения в LAG портов, находящихся на разных физических устройствах кластера. Таким образом мы получаем возможность подключить один коммутатор доступа (в который воткнуты пользовательские линки) к двум коммутатором агрегации без всякого Spanning Tree. Аналогичным образом, если уровней больше, коммуаторы агрегации можно при помощи LAG-группы подключить к ядру (если оно у вас есть) или магистрали.

Слово о масштабе
Изначально кластеризация появилась на коммутаторах формата 24/48×1GE (+ 2×10GE), то есть устройствах относительно небольшого масштаба. В зависимости от производителя и модели объединять такие коммутаторы в кластер можно либо с помощью специальных интерфейсов (PCI Express, InfiniBand и пр.), имеющих ограничение в длине до нескольких метров, либо посредством обычных портов 1 или 10 Gigabit Ethernet, в т. ч. оптических. В последних случаях появляется возможность строить территориально-распределенные коммутаторы и даже небольшие metro-ethernet-сети. В зависимости от конкретной реализации и модели обычно допускается объединение от двух до десяти устройств в один кластер.
Спустя некоторое время, производители стали внедрять кластеризацию и на больших модульных коммутаторах. В них для внутрикластерых линков как правило используюется несколько интерфейсов 10 Gigabit Ethernet. Максимальное количество таких устройств одного кластера обычно существенно меньше (2–4), впрочем, в этом нет особенного криминала.
Помимо модульных коммутаторов кластеризация также встречается на полноценных аппаратных маршрутизаторах старших линеек отдельных производителей. С теоретической точки зрения для маршрутизаторов эта функция менее актуальна в силу наличия в сетях IP/MPLS «родных» механизмов маршрутизации, балансиоровки нагрузки и трафик-инженеринга. Но поскольку такие устройства часто применяются и для выполнения L2-функций (PE для услуг L2VPN/VPLS или совмещения L3 и L2 в одной коробке), поддержка кластеризации на них также важна и применяется в первую очередь для того же самого: объединения в LAG интерфейсов разных физических устройств с целью резервирования подключений второго уровня.
И все-таки бесплатным светлое будущее не будет. В некоторых аспектах кластер коммутаторов таки хуже, чем много отдельных коммутаторов. Например, таблица MAC-адресов на всех устройствах как правило одна. Соответственно, верхняя планка максимального количества записей в ней распространяется на весь кластер. Для сети из 10 устройств масштаба небольшого города лимит в 10–15 тысяч MAC-адресов может оказаться существенным ограничением; некоторые реализации, например, требуют одновременной перезагрузки всех устройств кластера при обновлении софта. Подобного рода нюансов в зависимости от конкретной модели устройств может быть довольно много. Все это делает кластеризацию сомнительным подходом для построения операторских сетей.
Итого
Совмещение кластеризации коммутаторов и агрегирования интерфейсов разных устройств в LAG-группы — это наиболее эффективный на сегодня способ строить отказоустойчивые L2-сети предприятий, кампусов (нескольких расположенных рядом зданий единого административного управления), дата-центров и отдельных узлов сетей провайдеров. По большинству параметров: скорость переключения, устойчивость, надежность, простота настройки эксплуатации и траблшутинга, балансировка нагрузки — данный подход существенно превосходит вариации на тему Spanning Tree.
Однако эта технология — не панацея, не стоит воспринимать ее как механизм построения настоящих L2-сетей операторского масштаба.
Кроме того, Spanning Tree, хоть и теряет свою актуальность как механизм построения отказоустойчивой топологии и балансировки, но, как уже было сказано, остается актуальным способом защиты от человеческой ошибки. Поэтому, если, например, на коммутаторе включен по умолчанию протокол RSTP или PVST+, не стоит его выключать, если только вы не уверены, что знаете точно, зачем именно. Желательно также, чтоб на всех коммутаторах использовался один протокол, но это уже совсем другая история.
