В прошлый раз я предложил заглянуть в код MRI, чтобы разобраться с реализацией GIL и ответить на оставшиеся вопросы. Что мы сегодня и сделаем.
 Черновая версия этой статьи изобиловала кусками кода на C, однако, из-за этого суть терялась в деталях. В финальной версии почти нет кода, а для любителей поковыряться в исходниках я оставил ссылки на функции, которые упоминал.
Черновая версия этой статьи изобиловала кусками кода на C, однако, из-за этого суть терялась в деталях. В финальной версии почти нет кода, а для любителей поковыряться в исходниках я оставил ссылки на функции, которые упоминал.
После первой части остались два вопроса:
На первый вопрос можно ответив, взглянув на реализацию, поэтому начнем с него.
В прошлый раз мы разбирались со следующим кодом:
Считая массив потокобезопасным, логично ожидать, что в результате мы получим массив с пятью тысячами элементов. Так как в действительности массив не потокобезопасен, при запуске кода на JRuby или Rubinius получается результат, отличный от ожидаемого (массив с менее чем пятью тысячами элементов).
MRI дает ожидаемый результат, но это случайность или закономерность? Начнем исследование с небольшого куска кода на Ruby.
Чтобы разобраться в том, что происходит в этом куске кода, нужно взглянуть на то, как MRI создает новый поток, главным образом на код в файлах
Первым делом внутри реализации
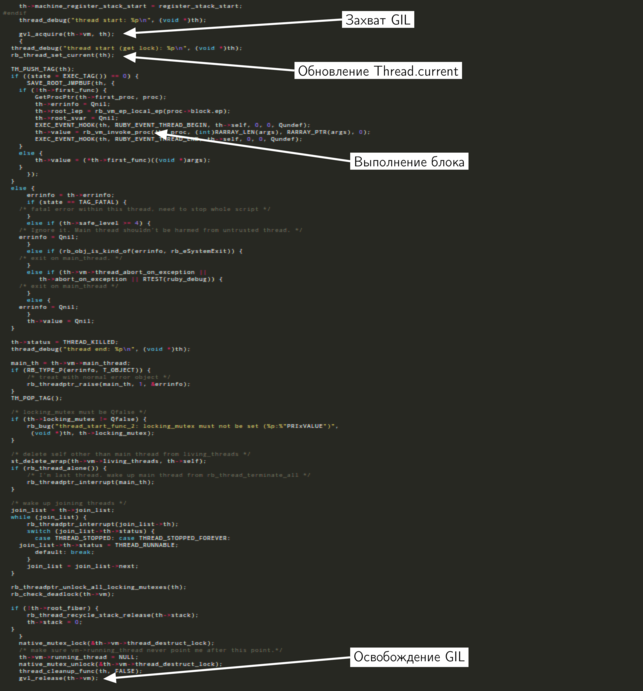
Для нас сейчас важен вовсе не весь код, поэтому я выделил те части, которые нам интересны. В начале функции новый поток захватывает GIL, перед этим дождавшись его освобождения. Где-то в середине функции выполняется блок, с которым был вызван метод
В нашем случае новый поток создается в главном потоке, значит, мы может предположить, что в текущий момент GIL удерживается именно им. Прежде чем продолжить выполнение, новый поток должен дождаться, пока главный поток освободит блокировку.
Посмотрим, что происходит, когда новый поток пытается захватить GIL.
Это часть функции
Первым делом она проверяет, удерживается ли уже блокировка. Если удерживается, то атрибут
Таймерный поток обеспечивает работу потоков MRI, не допуская ситуацию, в которой один из них постоянно удерживает GIL. Но прежде чем перейти к описанию таймерного потока, разберемся с GIL.
 Я уже несколько раз упоминал, что за каждым потоком в MRI стоит нативный поток. Так и есть, но данная схема предполагает, что потоки MRI работают параллельно, так же как и нативные. GIL этому препятствует. Дополним схему и сделаем ее более приближенной к действительности.
Я уже несколько раз упоминал, что за каждым потоком в MRI стоит нативный поток. Так и есть, но данная схема предполагает, что потоки MRI работают параллельно, так же как и нативные. GIL этому препятствует. Дополним схему и сделаем ее более приближенной к действительности.
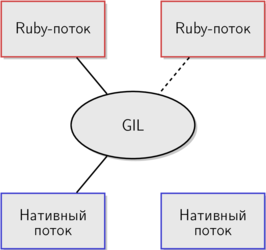 Чтобы задействовать нативный поток, Ruby-поток сначала должен захватить GIL. GIL служит посредником между Ruby-потоками и соответствующими нативными потоками, значительно ограничивая параллелизм. На прошлой схеме Ruby-потоки могли использовать нативные потоки параллельно. Вторая схема ближе к реальности в случае с MRI — только один поток может удерживать GIL в некоторый момент времени, поэтому параллельное выполнение кода полностью исключено.
Чтобы задействовать нативный поток, Ruby-поток сначала должен захватить GIL. GIL служит посредником между Ruby-потоками и соответствующими нативными потоками, значительно ограничивая параллелизм. На прошлой схеме Ruby-потоки могли использовать нативные потоки параллельно. Вторая схема ближе к реальности в случае с MRI — только один поток может удерживать GIL в некоторый момент времени, поэтому параллельное выполнение кода полностью исключено.
Для команды разработчиков MRI GIL защищает внутреннее состояние системы. Благодаря GIL, внутренние структуры данных не требуют блокировок. Если два потока не могут изменять общие данные одновременно, состояние гонки невозможно.
Для вас как разработчика написанное выше значит, что параллелизм в MRI сильно ограничен.
Как я уже говорил, таймерный поток препятствует постоянному удержанию GIL одним потоком. Таймерный поток — это нативный поток для внутренних нужд MRI, у него нет соответствующего Ruby-потока. Он стартует при запуске интерпретатора в функции
Когда MRI только запустился и работает только главный поток, таймерный поток спит. Но как только какой-нибудь поток начинает ожидать освобождения GIL, таймерный поток пробуждается.
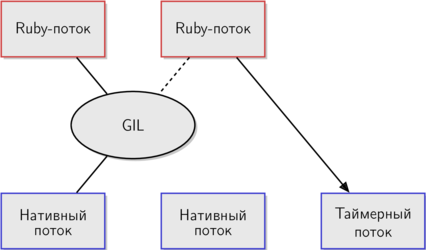
Эта схема еще точнее иллюстрирует, как реализован GIL в MRI. Поток справа только что запустился и, так как только он один ждет освобождения GIL, будит таймерный поток.
Каждые 100 ms таймерный поток выставляет флаг прерывания потока, который в данный момент удерживает GIL, с помощью макроса
Это похоже на концепцию квантования времени в ОС, если она вам знакома.
Установка флага не приводит к немедленному прерыванию потока (если бы приводила, можно было бы уверенно сказать, что выражение
В глубинах файла
Если флаг прерывания потока установлен, выполнение кода приостанавливается перед возвратом значения. Перед тем, как выполнить еще какой-либо Ruby-код, текущий поток освобождает GIL и вызывает функцию
Вот и ответ на первый вопрос:
То есть этот код:
гарантированно дает ожидаемый результат, будучи запущен на MRI (речь идет только о предсказуемости длины массива, насчет порядка элементов никаких гарантий нет — прим. пер.)
Но имейте в виду, что это никак не следует из Ruby-кода. Если вы запустите этот код на другой реализации, в которой нет GIL, он выдаст непредсказуемый результат. Полезно знать, что дает GIL, но писать код, который полагается на GIL — не самая лучшая идея. Поступая так, вы попадаете в ситуацию, подобную вендор-локу.
GIL не предоставляет публичный API. На GIL нет ни документации, ни спефицикации. Однажды команда разработчиков MRI может изменить поведение GIL или вовсе избавиться от нее. Вот почему написание кода, который зависит от GIL в его текущей реализации — не слишком хорошая идея.
Итак, мы знаем, что
А что насчет чего-нибудь такого?
Перед тем, как вызвать метод
Но GIL делает атомарными только методы, реализованные на C. Для методов на Ruby никаких гарантий нет.
Является ли вызов
В первой части статьи мы увидели, что может произойти, если переключение контекста придется куда-нибудь на середину функции. GIL предотвращает подобные ситуации — даже если переключение контекста происходит, другие потоки не смогут продолжить выполнение, так как будут вынуждены ожидать освобождения GIL. Все это происходит только при условии, что метод реализован на C, не обращается к коду на Ruby и не освобождает GIL сам (в комментариях к оригинальной статье приводят пример — реализованное на C добавление элемента к ассоциативному массиву (Hash) не атомарно, так как обращается к коду на Ruby для того, чтобы получить хэш элемента — прим. пер.)
GIL делает невозможным состояние гонки внутри реализации MRI, но не делает код на Ruby потокобезопасным. Можно сказать, что GIL — это просто особенность MRI, предназначенная для защиты внутреннего состояния интерпретатора.
Переводчик будет рад услышать замечания и конструктивную критику.
 Черновая версия этой статьи изобиловала кусками кода на C, однако, из-за этого суть терялась в деталях. В финальной версии почти нет кода, а для любителей поковыряться в исходниках я оставил ссылки на функции, которые упоминал.
Черновая версия этой статьи изобиловала кусками кода на C, однако, из-за этого суть терялась в деталях. В финальной версии почти нет кода, а для любителей поковыряться в исходниках я оставил ссылки на функции, которые упоминал.В предыдущей серии
После первой части остались два вопроса:
- Делает ли GIL
array << nilатомарной операцией? - Делает ли GIL код на Ruby потокобезопасным?
На первый вопрос можно ответив, взглянув на реализацию, поэтому начнем с него.
В прошлый раз мы разбирались со следующим кодом:
array = []
5.times.map do
Thread.new do
1000.times do
array << nil
end
end
end.each(&:join)
puts array.size
Считая массив потокобезопасным, логично ожидать, что в результате мы получим массив с пятью тысячами элементов. Так как в действительности массив не потокобезопасен, при запуске кода на JRuby или Rubinius получается результат, отличный от ожидаемого (массив с менее чем пятью тысячами элементов).
MRI дает ожидаемый результат, но это случайность или закономерность? Начнем исследование с небольшого куска кода на Ruby.
Thread.new do
array << nil
end
Начнем-с
Чтобы разобраться в том, что происходит в этом куске кода, нужно взглянуть на то, как MRI создает новый поток, главным образом на код в файлах
thread*.c.Первым делом внутри реализации
Thread.new создается новый нативный поток, который будет использоваться Ruby-потоком. После этого выполняется функция thread_start_func_2. Взглянем на нее, не особенно вдаваясь в детали.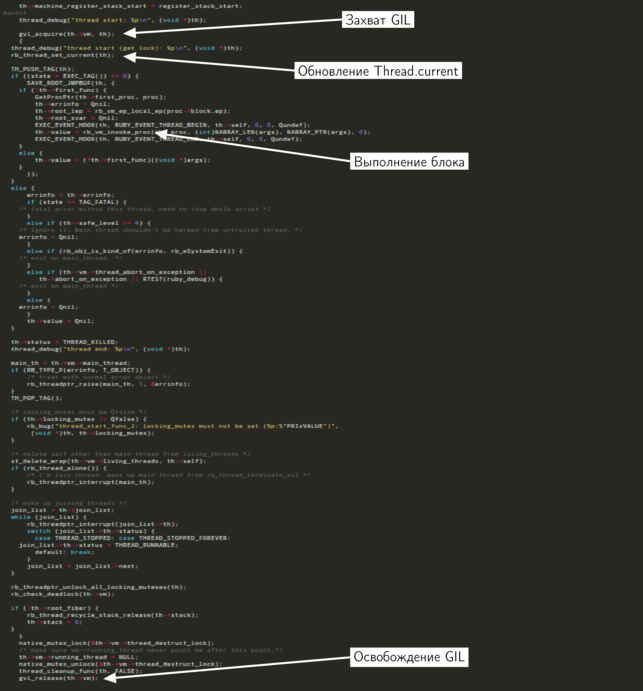
Для нас сейчас важен вовсе не весь код, поэтому я выделил те части, которые нам интересны. В начале функции новый поток захватывает GIL, перед этим дождавшись его освобождения. Где-то в середине функции выполняется блок, с которым был вызван метод
Thread.new. В конце концов блокировка освобождается и завершает свою работу нативный поток.В нашем случае новый поток создается в главном потоке, значит, мы может предположить, что в текущий момент GIL удерживается именно им. Прежде чем продолжить выполнение, новый поток должен дождаться, пока главный поток освободит блокировку.
Посмотрим, что происходит, когда новый поток пытается захватить GIL.
static void
gvl_acquire_common(rb_vm_t *vm)
{
if (vm->gvl.acquired) {
vm->gvl.waiting++;
if (vm->gvl.waiting == 1) {
rb_thread_wakeup_timer_thread_low();
}
while (vm->gvl.acquired) {
native_cond_wait(&vm->gvl.cond, &vm->gvl.lock);
}
Это часть функции
gvl_acquire_common, которая вызывается, когда новый поток пытается захватить GIL.Первым делом она проверяет, удерживается ли уже блокировка. Если удерживается, то атрибут
waiting увеличивается. В случае с нашим кодом, он становится равным 1. В следующей строке следует проверка, не равен ли атрибут waiting 1. Он равен, поэтому следующая строка будит таймерный поток. Таймерный поток обеспечивает работу потоков MRI, не допуская ситуацию, в которой один из них постоянно удерживает GIL. Но прежде чем перейти к описанию таймерного потока, разберемся с GIL.
 Я уже несколько раз упоминал, что за каждым потоком в MRI стоит нативный поток. Так и есть, но данная схема предполагает, что потоки MRI работают параллельно, так же как и нативные. GIL этому препятствует. Дополним схему и сделаем ее более приближенной к действительности.
Я уже несколько раз упоминал, что за каждым потоком в MRI стоит нативный поток. Так и есть, но данная схема предполагает, что потоки MRI работают параллельно, так же как и нативные. GIL этому препятствует. Дополним схему и сделаем ее более приближенной к действительности.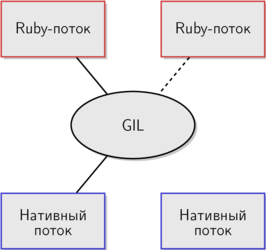 Чтобы задействовать нативный поток, Ruby-поток сначала должен захватить GIL. GIL служит посредником между Ruby-потоками и соответствующими нативными потоками, значительно ограничивая параллелизм. На прошлой схеме Ruby-потоки могли использовать нативные потоки параллельно. Вторая схема ближе к реальности в случае с MRI — только один поток может удерживать GIL в некоторый момент времени, поэтому параллельное выполнение кода полностью исключено.
Чтобы задействовать нативный поток, Ruby-поток сначала должен захватить GIL. GIL служит посредником между Ruby-потоками и соответствующими нативными потоками, значительно ограничивая параллелизм. На прошлой схеме Ruby-потоки могли использовать нативные потоки параллельно. Вторая схема ближе к реальности в случае с MRI — только один поток может удерживать GIL в некоторый момент времени, поэтому параллельное выполнение кода полностью исключено.Для команды разработчиков MRI GIL защищает внутреннее состояние системы. Благодаря GIL, внутренние структуры данных не требуют блокировок. Если два потока не могут изменять общие данные одновременно, состояние гонки невозможно.
Для вас как разработчика написанное выше значит, что параллелизм в MRI сильно ограничен.
Таймерный поток
Как я уже говорил, таймерный поток препятствует постоянному удержанию GIL одним потоком. Таймерный поток — это нативный поток для внутренних нужд MRI, у него нет соответствующего Ruby-потока. Он стартует при запуске интерпретатора в функции
rb_thread_create_timer_thread.Когда MRI только запустился и работает только главный поток, таймерный поток спит. Но как только какой-нибудь поток начинает ожидать освобождения GIL, таймерный поток пробуждается.
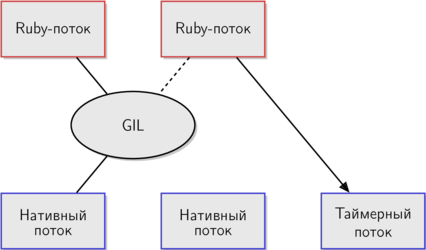
Эта схема еще точнее иллюстрирует, как реализован GIL в MRI. Поток справа только что запустился и, так как только он один ждет освобождения GIL, будит таймерный поток.
Каждые 100 ms таймерный поток выставляет флаг прерывания потока, который в данный момент удерживает GIL, с помощью макроса
RUBY_VM_SET_TIMER_INTERRUPT. Эти подробности важны для понимания того, атомарно ли выражение array << nil.Это похоже на концепцию квантования времени в ОС, если она вам знакома.
Установка флага не приводит к немедленному прерыванию потока (если бы приводила, можно было бы уверенно сказать, что выражение
array << nil не атомарно).Обработка флага прерывания
В глубинах файла
vm_eval.c находится код обработки вызова метода в Ruby. Он устанавливает окружение для вызова метода и вызывает требуемую функцию. В конце функции vm_call0_body, прямо перед возвратом значения метода, проверяется флаг прерывания.Если флаг прерывания потока установлен, выполнение кода приостанавливается перед возвратом значения. Перед тем, как выполнить еще какой-либо Ruby-код, текущий поток освобождает GIL и вызывает функцию
sched_yield. sched_yield — это системная функция, которая запрашивает возобновление следующего в очереди потока планировщиком ОС. После этого прерванный поток пытается опять захватить GIL, перед этим дождавшись, пока другой поток освободит его. Вот и ответ на первый вопрос:
array << nil является атомарной операцией. Благодаря GIL все Ruby-методы, реализованные исключительно на C, атомарны.То есть этот код:
array = []
5.times.map do
Thread.new do
1000.times do
array << nil
end
end
end.each(&:join)
puts array.size
гарантированно дает ожидаемый результат, будучи запущен на MRI (речь идет только о предсказуемости длины массива, насчет порядка элементов никаких гарантий нет — прим. пер.)
Но имейте в виду, что это никак не следует из Ruby-кода. Если вы запустите этот код на другой реализации, в которой нет GIL, он выдаст непредсказуемый результат. Полезно знать, что дает GIL, но писать код, который полагается на GIL — не самая лучшая идея. Поступая так, вы попадаете в ситуацию, подобную вендор-локу.
GIL не предоставляет публичный API. На GIL нет ни документации, ни спефицикации. Однажды команда разработчиков MRI может изменить поведение GIL или вовсе избавиться от нее. Вот почему написание кода, который зависит от GIL в его текущей реализации — не слишком хорошая идея.
Что насчет методов, реализованных на Ruby?
Итак, мы знаем, что
array << nil — атомарная операция. В этом выражении вызывается один метод Array#<<, которому передается константа как параметр и который реализован на C. Переключение контекста, случись оно, не приведет к нарушению целостности данных — этот метод в любом случае освободит GIL только перед завершением.А что насчет чего-нибудь такого?
array << User.find(1)
Перед тем, как вызвать метод
Array#<<, нужно вычислить значение параметра, то есть вызвать User.find(1). Как вы возможно знаете, User.find(1) в свою очередь вызывает множество методов, написанных на Ruby.Но GIL делает атомарными только методы, реализованные на C. Для методов на Ruby никаких гарантий нет.
Является ли вызов
Array#<< все еще атомарным в новом примере? Да, но не забывайте о том, что еще нужно выполнить правостороннее выражение. Другими словам, сначала нужно сделать вызов метода User.find(1), который не является атомарным, и только потом значение, возвращенное им, будет передано в Array#<<.Что все это значит для меня?
В первой части статьи мы увидели, что может произойти, если переключение контекста придется куда-нибудь на середину функции. GIL предотвращает подобные ситуации — даже если переключение контекста происходит, другие потоки не смогут продолжить выполнение, так как будут вынуждены ожидать освобождения GIL. Все это происходит только при условии, что метод реализован на C, не обращается к коду на Ruby и не освобождает GIL сам (в комментариях к оригинальной статье приводят пример — реализованное на C добавление элемента к ассоциативному массиву (Hash) не атомарно, так как обращается к коду на Ruby для того, чтобы получить хэш элемента — прим. пер.)
GIL делает невозможным состояние гонки внутри реализации MRI, но не делает код на Ruby потокобезопасным. Можно сказать, что GIL — это просто особенность MRI, предназначенная для защиты внутреннего состояния интерпретатора.
Переводчик будет рад услышать замечания и конструктивную критику.
