Высокоуровневые языки программирования содержат в себе много абстрактных программистских конструкций, таких как функции, условные операторы и циклы — они делают нас удивительно продуктивными. Однако одним из недостатков написания кода на высокоуровневом языке является потенциальное значительное снижение скорости работы программы. Поэтому компиляторы стараются автоматически оптимизировать код и увеличить скорость работы. В наши дни логика оптимизации стала очень сложной: компиляторы преобразуют циклы, условные выражения и рекурсивные функции; удаляют целые блоки кода. Они оптимизируют код под процессорную архитектуру, чтобы сделать его действительно быстрым и компактным. И это очень здорово, ведь лучше фокусироваться на написании читабельного кода, чем заниматься ручными оптимизациями, которые будет сложно понимать и поддерживать. Кроме того, ручные оптимизации могут помешать компилятору выполнить дополнительные и более эффективные автоматические оптимизации. Вместо того чтобы писать оптимизации руками, лучше бы сосредоточиться на дизайне архитектуры и на эффективных алгоритмах, включая параллелизм и использование особенностей библиотек.
Данная статья посвящена оптимизациям компилятора Visual C++. Я собираюсь обсудить наиболее важные техники оптимизаций и решения, которые приходится применить компилятору, чтобы правильно их применить. Моя цель не в том, чтобы рассказать вам как вручную оптимизировать код, а в том, чтобы показать, почему стоит доверять компилятору оптимизировать ваш код самостоятельно. Эта статья ни в коем случае не является описанием полного набора оптимизаций, которые совершает компилятор Visual C++, в ней будут показаны только действительно важные из них, о которых полезно знать. Есть другие важные оптимизации, которые компилятор выполнить не в состоянии. Например, замена неэффективного алгоритма на эффективный или изменение выравнивания структуры данных. Такие оптимизации в этой статье мы обсуждать не будем.
Компиляторы постоянно совершенствуются, используемые ими подходы улучшаются. Несмотря на то, что они не совершенны, зачастую наиболее правильным подходом является всё-таки оставить низкоуровневые оптимизации компилятору, чем пытаться провести их вручную.
Существует четыре способа помочь компилятору провести оптимизации более эффективно:
Цель данной статьи состоит в том, чтобы показать вам, почему вы можете доверять компилятору выполнение оптимизаций, которые применяются к неэффективному, но читаемому коду (первый метод). Также я сделаю краткий обзор profile-guided оптимизаций и упомяну некоторые директивы компилятора, которые позволят вам улучшить часть вашего исходного кода.
Существует много техник оптимизаций компилятора, начиная от простых преобразований, вроде свёртки констант, заканчивая сложными, вроде управлением порядка команд (instruction scheduling). В этой статье мы ограничимся наиболее важными оптимизациями, которые могут значительно улучшить производительность вашего кода (на двухзначное количество процентов) и сократить его размер путём подстановки функций (function inlining), COMDAT оптимизаций и оптимизаций циклов. Я обсужу первые два подхода в следующем разделе, а затем покажу как можно контролировать выполнение оптимизаций в Visual C++. В заключение, я вкратце расскажу о тех оптимизациях, которые применяются в .NET Framework. На протяжении всей статьи я буду использовать Visual Studio 2013 для всех примеров.
Если LTCG включён (флаг
Front end также выполняет некоторые оптимизации (например, свёртка констант) независимо то того, включены или выключены оптимизации. Впрочем, все важные оптимизации выполняет back end, и их можно контролировать с помощью ключей компиляции.
LTCG позволяет back end-у выполнять многие оптимизации агрессивно (с помощью ключей компилятора
Я буду работать с программой из двух файлов исходного кода (
Файл
Код получился очень простой, но полезный. У нас есть несколько функций, которые делают простые вычисления, некоторые из них содержат циклы. Функция
Рассмотрим результат работы компилятора под тремя разными конфигурациями. Если вы будете разбираться с примером самостоятельно, то вам понадобится assembler output file (получается с помощью ключа компилятора
Если вы посмотрите сгенерированный assembly listing file для
Теперь обратимся к assembly listing file для
Пока инлайнинг функций включён (ключ
Если вы посмотрите на assembly listing file для
Как вы можете видеть, инлайнинг функций — это важно не только из-за того, что оптимизируется вызов функций, но также из-за того, что он позволяет компилятору выполнить многие дополнительные оптимизации. Инлайнинг обычно увеличивает производительность за счёт увеличения размера кода. Чрезмерное использование этой оптимизации приводит к такому явлению, которое называется code bloat. Поэтому при каждом вызове функции компилятор проводит вычисление затрат и выгод, после чего принимает решение о том, стоит ли инлайнить функцию.
Из-за важности инлайнинга компилятор Visual C++ предоставляет большие возможности по его поддержке. Вы можете сказать компилятору, чтобы он никогда не инлайнил набор функций с помощью директивы
Ключ
Компилятор не всегда может заинлайнить функцию. Например, во время виртуального вызова виртуальной функции: функция не может быть заинлайнена, т. к. компилятор не знает точно какая именно функция будет вызована. Другой пример: функция вызывается через указатель на функцию вместо вызова через её имя. Вы должны стараться избегать таких ситуаций, чтобы инлайнинг был возможен. Полный список всех подобных условий можно найти в MSDN.
Инлайнинг функций — это не единственная оптимизация, которая может применятся на уровне программы целиком. Большинство оптимизаций наиболее эффективно работают именно на этом уровне. В оставшейся части статьи я обсужу специфический класс оптимизаций, который называется COMDAT-оптимизации.
По умолчанию, во время компиляции модуля, весь код сохраняется в одиночной секции итогового объектного файла. Линковщик работает на уровне секций: он может удалять секции, соединять их или переупорядочивать. Это мешает ему выполнить три очень важных оптимизации (двухзначный процент), которые помогают уменьшить размер исполняемого файла и увеличить его производительность. Первая удаляет неиспользуемые функции и глобальные переменные. Вторая сворачивает идентичные функции и глобальные константы. Третья переупорядочивает функции и глобальные переменные так, чтобы во время выполнения переходы между физическими фрагментами памяти были короче.
Для включения этих оптимизаций линковщика, вы должны попросить компилятор упаковывать функции и переменные в отдельные секции с помощью ключей компилятора
Вы должны использовать LTCG всегда, когда это возможно. Единственная причина отказа от LTCG заключается в том, что вы хотите распространять итоговые объектные файлы и файлы библиотек. Напомним, что они содержат CIL-код вместо машинного. CIL-код может быть использован только компилятором и линковщиком той же версии, с помощью которой они были сгенерированы, что является значительным ограничением, ведь разработчикам придётся использовать ту же версию компилятора, чтобы использовать ваши файлы. В данном случае, если вы не хотите распространять отдельную версию объектных файлов для каждой версии компилятора, то вы должны использовать вместо этого генерацию кода. В дополнение к ограничению по версии, объектные файлы во много раз больше, чем соответствующие assembler object-файлы. Впрочем, не забывайте про огромное преимущество объектных файлов с CIL-кодом, которое заключается в возможности использовать WPO.
Если вы скопмилируете код с ключом

На данной схеме зелёный ромб показывает точку входа, а красные прямоугольники показывают точки выхода. Голубые ромбы представляют условные операторы, которые будут выполняться при выполнении функции
Размотка циклов осуществляется повторением тела цикла несколько раз внутри одной итерации нового (размотанного) цикла. Это повышает производительность, т. к. операции самого цикла будут выполняться реже. Кроме того, это позволяет компилятору выполнять дополнительные оптимизации (например, векторизацию). Недостатком размотки циклов является увеличение количества кода и нагрузка на регистры. Но несмотря на это, в зависимости от тела цикла подобная оптимизация может увеличить производительность на двухзначный процент.
В отличие от x86-процессоров, все процессоры x86-64 поддерживают SSE2. Более того, вы можете использовать преимущества инструкций AVX/AVX2 на последних моделях x86-64 процессоров от Intel и AMD с помощью ключа
На текущий момент компилятор Visual C++ не позволяет контролировать размотку циклов. Но вы можете влиять на неё с помощью
Если вы посмотрите на сгенерированный ассемблерный код, то можете заметить, что к нему можно применить дополнительные оптимизации. Но компилятор всё-равно уже сделал отличную работу и нет нужды тратить намного больше времени на анализ, чтобы применить минорные оптимизации.
Функция
В заключение мы посмотрим на такую оптимизацию, как вынос инвариантов цикла. Взглянем на следующий код:
Единственное изменение, которое мы сделали, заключается в добавлении дополнительной переменной, которая увеличивается на каждой итерации, а в завершении выводится на консоль. Нетрудно заметить, что данный код легко оптимизируется с помощью выноса инкрементируемоей переменной за рамки цикла: достаточно просто присвоить ей значение
Но вот загвоздка: если вы примените эту оптимизацию вручную, то итоговый код может потерять в производительности в определённых условиях. Можете ли вы сказать почему? Представьте, что переменная
В заключение хочется сказать, что если вы не компилятор и не эксперт по оптимизациям компилятора, то вы должны избегать таких преобразований своего кода, которые заставят выглядеть его так, будто бы он работает быстрее. Держите свои руки чистыми и доверьте компилятору оптимизировать ваш код.
В данном примере optimization list может быть пустым, а может содержать одно или несколько значений из набора:
Пустой список c параметром
Ключ
Директива
В чём же разница между RyuJIT и Visual C++ с точки зрения возможностей оптимизации? Ввиду того, что RyuJIT работает во время выполнения, он может выполнить такие оптимизации, на которые Visual C++ не способен. Например, прямо во время выполнения он может понять, что выражение в условном операторе никогда не примет значение
На сегодняшний день возможность контролировать оптимизации управляемого кода ограничена. Компиляторы C# и Visual Basic позволяют только включать или выключать оптимизации с помощью ключа
Данная статья посвящена оптимизациям компилятора Visual C++. Я собираюсь обсудить наиболее важные техники оптимизаций и решения, которые приходится применить компилятору, чтобы правильно их применить. Моя цель не в том, чтобы рассказать вам как вручную оптимизировать код, а в том, чтобы показать, почему стоит доверять компилятору оптимизировать ваш код самостоятельно. Эта статья ни в коем случае не является описанием полного набора оптимизаций, которые совершает компилятор Visual C++, в ней будут показаны только действительно важные из них, о которых полезно знать. Есть другие важные оптимизации, которые компилятор выполнить не в состоянии. Например, замена неэффективного алгоритма на эффективный или изменение выравнивания структуры данных. Такие оптимизации в этой статье мы обсуждать не будем.
Определение оптимизаций компилятора
Оптимизация — это процесс преобразования фрагмента кода в другой фрагмент, который функционально эквивалентен исходному, с целью улучшения одной или нескольких его характеристик, из которых наиболее важными являются скорость и размер кода. Другие характеристики включают количество потребляемой энергии на выполнения кода и время компиляции (а также время JIT-компиляции, если полученный код использует JIT).Компиляторы постоянно совершенствуются, используемые ими подходы улучшаются. Несмотря на то, что они не совершенны, зачастую наиболее правильным подходом является всё-таки оставить низкоуровневые оптимизации компилятору, чем пытаться провести их вручную.
Существует четыре способа помочь компилятору провести оптимизации более эффективно:
- Пишите читаемый код, который легко поддерживать. Не думайте про разные ООП-фичи Visual C++ как о злейшем враге производительности. Последняя версия Visual C++ сможет свести накладные расходы от ООП к минимуму, а иногда даже полностью от них избавиться.
- Используйте директивы компилятора. Например, скажите компилятору использовать то соглашение о вызове функций, которое будет быстрее того, которое стоит по умолчанию.
- Используйте встроенные в компилятор функции. Это такие специальные функции, реализация которых обеспечивается компилятором автоматически. Помните, что компилятор обладает глубоким знанием того, как эффективно расположить последовательность машинных команд так, чтобы код работал максимально быстро на указанной программной архитектуре. В настоящее время Microsoft .NET Framework не поддерживает встроенные функции, так что управляемые языки не могут их использовать. Однако Visual C++ имеет расширенную поддержку таких функций. Впрочем, не стоит забывать о том, что их использование хоть и улучшит производительность кода, но при этом негативно скажется на читаемости и портируемости.
- Используйте profile-guided optimization (PGO). Благодаря этой технологии, компилятор знает больше о том, как код будет вести себя во время работы и оптимизирует его соответствующем образом.
Цель данной статьи состоит в том, чтобы показать вам, почему вы можете доверять компилятору выполнение оптимизаций, которые применяются к неэффективному, но читаемому коду (первый метод). Также я сделаю краткий обзор profile-guided оптимизаций и упомяну некоторые директивы компилятора, которые позволят вам улучшить часть вашего исходного кода.
Существует много техник оптимизаций компилятора, начиная от простых преобразований, вроде свёртки констант, заканчивая сложными, вроде управлением порядка команд (instruction scheduling). В этой статье мы ограничимся наиболее важными оптимизациями, которые могут значительно улучшить производительность вашего кода (на двухзначное количество процентов) и сократить его размер путём подстановки функций (function inlining), COMDAT оптимизаций и оптимизаций циклов. Я обсужу первые два подхода в следующем разделе, а затем покажу как можно контролировать выполнение оптимизаций в Visual C++. В заключение, я вкратце расскажу о тех оптимизациях, которые применяются в .NET Framework. На протяжении всей статьи я буду использовать Visual Studio 2013 для всех примеров.
Link-Time Code Generation
Генерация кода на этапе линковки (Link-Time Code Generation, LTCG) — это техника для выполнения оптимизаций над всей программой (whole program optimizations, WPO) для С/С++ кода. Компилятор С/С++ обрабатывает каждый файл исходного кода по отдельности и выдаёт соответствующий файл объектов (object file). Другими словами, компилятор может оптимизировать только одиночный файл, вместо того, чтобы оптимизировать всю программу. Однако некоторые важные оптимизации могут быть применимы только к программе целиком. Вы можете использовать эти оптимизации только во время линковки, а не во время компиляции, т. к. линковщик имеет полное представление о программе.Если LTCG включён (флаг
/GL), то драйвер компилятора (cl.exe) будет вызывать только front end (c1.dll или c1xx.dll) и отложит работу back end (c2.dll) до момента линковки. Полученные объектные файлы содержат C Intermediate Language (CIL), а не машинный код. Затем вызывается линковщик (link.exe). Он видит, что объектные файлы содержат CIL-код, и вызывает back end, который, в свою очередь, выполняет WPO и генерирует бинарные объектные файлы, чтобы линковщик мог соединить их вместе и сформировать исполняемый файл.Front end также выполняет некоторые оптимизации (например, свёртка констант) независимо то того, включены или выключены оптимизации. Впрочем, все важные оптимизации выполняет back end, и их можно контролировать с помощью ключей компиляции.
LTCG позволяет back end-у выполнять многие оптимизации агрессивно (с помощью ключей компилятора
/GL вместе с /O1 или /O2 и /Gw, а также с помощью ключей линковщика /OPT:REF и /OPT:ICF). В данной статье я буду обсуждать только inlining и COMDAT оптимизации. Полный список LTCG-оптимизаций приведён в документации. Полезно знать, что линковщик может выполнить LTCG над нативными, нативно-управляемыми и чисто управляемыми объектными файлами, а также над безопасно-управляемыми (safe managed) объектными файлами и safe.netmodules.Я буду работать с программой из двух файлов исходного кода (
source1.c и source2.c) и заголовочным файлом (source2.h). Файлы source1.c и source2.c приведены в листинге ниже, а заголовочный файл, содержащий прототипы всех функций source2.c, настолько прост, что его приводить я не буду.// source1.c
#include <stdio.h> // scanf_s and printf.
#include "Source2.h"
int square(int x) { return x*x; }
main() {
int n = 5, m;
scanf_s("%d", &m);
printf("The square of %d is %d.", n, square(n));
printf("The square of %d is %d.", m, square(m));
printf("The cube of %d is %d.", n, cube(n));
printf("The sum of %d is %d.", n, sum(n));
printf("The sum of cubes of %d is %d.", n, sumOfCubes(n));
printf("The %dth prime number is %d.", n, getPrime(n));
}
// source2.c
#include <math.h> // sqrt.
#include <stdbool.h> // bool, true and false.
#include "Source2.h"
int cube(int x) { return x*x*x; }
int sum(int x) {
int result = 0;
for (int i = 1; i <= x; ++i) result += i;
return result;
}
int sumOfCubes(int x) {
int result = 0;
for (int i = 1; i <= x; ++i) result += cube(i);
return result;
}
static
bool isPrime(int x) {
for (int i = 2; i <= (int)sqrt(x); ++i) {
if (x % i == 0) return false;
}
return true;
}
int getPrime(int x) {
int count = 0;
int candidate = 2;
while (count != x) {
if (isPrime(candidate))
++count;
}
return candidate;
}
Файл
source1.c содержит две функции: функцию square, вычисляющую квадрат целого числа, и главную функцию программы main. Главная функция вызывает функцию square и всех функции из source2.c за исключением isPrime. Файл source2.c содержит 5 функций: cube для возведения целого числа в третью степень, sum для подсчёта суммы целых чисел от 1 до заданного числа, sumOfCubes для подсчёта суммы кубов целых чисел от 1 до заданного числа, isPrime для проверки числа на простоту, getPrime для получения простого числа с заданным номером. Я пропустил обработку ошибок, т. к. она не представляет интереса в данной статье.Код получился очень простой, но полезный. У нас есть несколько функций, которые делают простые вычисления, некоторые из них содержат циклы. Функция
getPrime является самой сложной, т. к. она содержит цикл while, внутри которого вызывает функцию isPrime, которая также содержит цикл. Я буду использовать этот код для демонстрации одной из важных оптимизаций компилятора function inlining и нескольких дополнительных оптимизаций.Рассмотрим результат работы компилятора под тремя разными конфигурациями. Если вы будете разбираться с примером самостоятельно, то вам понадобится assembler output file (получается с помощью ключа компилятора
/FA[s]) и map file (получается с помощью ключа линковщика /MAP) чтобы изучить выполняемые COMDAT-оптимизации (линковщик будет сообщать о них, если вы включите ключи /verbose:icf и /verbose:ref). Убедитесь, что все ключи указаны правильно, и продолжайте чтение статьи. Я буду использовать компилятор C (/TC), чтобы генерируемый код был проще для изучения, но всё излагаемое в статье также применимо к С++ коду.Конфигурация Debug
Конфигурация Debug используется главным образом потому, что все back end оптимизации выключаются, если вы указываете ключ/Od без ключа /GL. В этой конфигурации итоговые объектные файлы содержит бинарный код, который в точности соответствует исходному коду. Вы можете изучить полученные assembler output files и map file, чтобы убедиться в этом. Конфигурация эквивалентна конфигурации Debug в Visual Studio.Конфигурация Compile-Time Code Generation Release
Эта конфигурация похожа на конфигурацию Release (в которой указаны ключи/O1, /O2 или /Ox), но она не включает ключ /GL. В этой конфигурации итоговые объектные файлы содержат оптимизированный бинарный код, но при этом оптимизации уровня всей программы не выполняются.Если вы посмотрите сгенерированный assembly listing file для
source1.c, то заметите, что выполнились две важные оптимизации. Первый вызов функции square, square(n), был заменён на вычисленное во время компиляции значение. Как такое произошло? Компилятор заметил, что тело функции мало, и решил подставить её содержимое вместо вызова. Затем компилятор обратил внимание на то, что в вычислении значения присутствует локальная переменная n с известным начальным значением, которое не менялось между первоначальным присваиванием и вызовом функции. Таким образом, он пришёл к выводу, что можно безопасно вычислить значение операции умножения и подставить результат (25). Второй вызов функции square, square(m), также был заинлайнен, т. е. тело функции было подставлено вместо вызова. Но значение переменной m неизвестно на момент компиляции, так что компилятор не смог вычислить заранее значение выражения.Теперь обратимся к assembly listing file для
source2.c, он намного более интересный. Вызов функции cube в функции sumOfCubes был заинлайнен. Это, в свою очередь, позволило компилятору выполнить оптимизацию цикла (об этом подробнее в секции «Оптимизации циклов»). В функции isPrime были использованы инструкции SSE2 для конвертации int в double при вызове sqrt и конвертации из double в int при получении результата из sqrt. По факту, sqrt вызвалась единожды перед началом цикла. Обратите внимание, что ключ /arch указывает компилятору, что x86 использует SSE2 по умолчанию (большинство x86-процессоров и x86-64 процессоров поддерживают SSE2).Конфигурация Link-Time Code Generation Release
Эта конфигурация идентична конфигурации Release в Visiual Studio: оптимизации включены и ключ компилятора/GL указан (вы также можете явно указать /O1 или /O2). Тем самым мы говорим компилятору формировать объектные файлы с CIL кодом вместо assembly object files. А значит, линковщик вызовет back end компилятора для выполнения WPO, как было описано выше. Теперь мы обсудим несколько WPO, чтобы показать огромную пользу LTCG. Генерируемые assembly code-листинги для этой конфигурации доступны online.Пока инлайнинг функций включён (ключ
/Ob, который включён, если вы ключили оптимизации), ключ /GL позволяет компилятору инлайнить функции, определённые в других файлах независимо от ключа /Gy (мы обсудим его чуть позже). Ключ линковщика /LTCG опционален и влияет только на линковщик.Если вы посмотрите на assembly listing file для
source1.c, то можете заметить, что вызовы всех функций кроме scanf_s были заинлайнены. В результате компилятор смог выполнить вычисление функций cube, sum и sumOfCubes. Только функция isPrime не была заинлайнена. Однако если бы вы заинлайнили её вручную в getPrime, то компилятор по-прежнему выполнил бы инлайн getPrime в main.Как вы можете видеть, инлайнинг функций — это важно не только из-за того, что оптимизируется вызов функций, но также из-за того, что он позволяет компилятору выполнить многие дополнительные оптимизации. Инлайнинг обычно увеличивает производительность за счёт увеличения размера кода. Чрезмерное использование этой оптимизации приводит к такому явлению, которое называется code bloat. Поэтому при каждом вызове функции компилятор проводит вычисление затрат и выгод, после чего принимает решение о том, стоит ли инлайнить функцию.
Из-за важности инлайнинга компилятор Visual C++ предоставляет большие возможности по его поддержке. Вы можете сказать компилятору, чтобы он никогда не инлайнил набор функций с помощью директивы
auto_inline. Вы также можете указать компилятору заданные функции или методы с помощью __declspec(noinline). А ещё можно пометить функцию ключевым словом inline и посоветовать компилятору выполнить инлайн (хотя компилятор может решить проигнорировать этот совет, если сочтёт его плохим). Ключевое слово inline доступно начиная с первой версии С++, оно появилось в С99. Вы можете использовать ключевое слово __inline компилятора от Microsoft и для С и для С++: это удобно, если вы хотите использовать старые версии С, которые не поддерживают данное ключевое слово. Ключевое слово __forceinline (для С и С++) заставляет компилятор всегда инлайнить функцию, если это возможно. И последнее, но не по важности, вы можете сказать компилятору развернуть рекурсивную функцию указанной или неопределённой глубины путём инлайнинга с помощью директивы inline_recursion. Учтите, что в настоящее время компилятор не имеет возможности контролировать инлайнинг в месте вызова функции, а не в месте её объявления.Ключ
/Ob0 отключает инлайнинг полностью, что полезно во время отладки (этот ключ срабатывает в Debug-конфигурации в Visual Studio). Ключ /Ob1 говорит компилятору, что в качестве кандидатов на инлайнинг должны рассматриваться только функции, помеченные с помощью inline, __inline, __forceinline. Ключ /Ob2 срабатывает только при указанных /O[1|2|x] и говорит компилятору рассматривать для инлайнинга все функции. На мой взгляд, единственная причина для использования ключевых слов inline и __inline — контролирования инлайнинга для ключа /Ob1.Компилятор не всегда может заинлайнить функцию. Например, во время виртуального вызова виртуальной функции: функция не может быть заинлайнена, т. к. компилятор не знает точно какая именно функция будет вызована. Другой пример: функция вызывается через указатель на функцию вместо вызова через её имя. Вы должны стараться избегать таких ситуаций, чтобы инлайнинг был возможен. Полный список всех подобных условий можно найти в MSDN.
Инлайнинг функций — это не единственная оптимизация, которая может применятся на уровне программы целиком. Большинство оптимизаций наиболее эффективно работают именно на этом уровне. В оставшейся части статьи я обсужу специфический класс оптимизаций, который называется COMDAT-оптимизации.
По умолчанию, во время компиляции модуля, весь код сохраняется в одиночной секции итогового объектного файла. Линковщик работает на уровне секций: он может удалять секции, соединять их или переупорядочивать. Это мешает ему выполнить три очень важных оптимизации (двухзначный процент), которые помогают уменьшить размер исполняемого файла и увеличить его производительность. Первая удаляет неиспользуемые функции и глобальные переменные. Вторая сворачивает идентичные функции и глобальные константы. Третья переупорядочивает функции и глобальные переменные так, чтобы во время выполнения переходы между физическими фрагментами памяти были короче.
Для включения этих оптимизаций линковщика, вы должны попросить компилятор упаковывать функции и переменные в отдельные секции с помощью ключей компилятора
/Gy (линковка уровня функций) и /Gw (оптимизация глобальных данных). Эти секции называются COMDAT-ами. Вы можете также пометить заданную глобальную переменную с использованием __declspec( selectany), чтобы сказать компилятору упаковывать переменную в COMDAT. Далее, с помощью ключа линковщика /OPT:REF можно избавиться от неиспользуемых функций и глобальных переменных. Ключ /OPT:ICF поможет свернуть идентичные функции и глобальные константы (ICF — это Identical COMDAT Folding). Ключ /ORDER заставит линковщик помещать COMDAT-ы в итоговые образы в специфическом порядке. Учтите, что все оптимизации линковщика не нуждаются в ключе /GL. Ключи /OPT:REF и /OPT:ICF должны быть выключены во время отладки по очевидным причинам.Вы должны использовать LTCG всегда, когда это возможно. Единственная причина отказа от LTCG заключается в том, что вы хотите распространять итоговые объектные файлы и файлы библиотек. Напомним, что они содержат CIL-код вместо машинного. CIL-код может быть использован только компилятором и линковщиком той же версии, с помощью которой они были сгенерированы, что является значительным ограничением, ведь разработчикам придётся использовать ту же версию компилятора, чтобы использовать ваши файлы. В данном случае, если вы не хотите распространять отдельную версию объектных файлов для каждой версии компилятора, то вы должны использовать вместо этого генерацию кода. В дополнение к ограничению по версии, объектные файлы во много раз больше, чем соответствующие assembler object-файлы. Впрочем, не забывайте про огромное преимущество объектных файлов с CIL-кодом, которое заключается в возможности использовать WPO.
Оптимизации циклов
Компилятор Visual C++ поддерживает несколько видов оптимизаций циклов, но мы будем обсуждать только три: размотка циклов (loop unrolling), автоматическая векторизация (automatic vectorization) и вынос инвариантов цикла (loop-invariant code motion). Если вы модифицируете код изsource1.c так, что в sumOfCubes будет передаваться m вместо n, то компилятор не сможет высчитать значение параметров, придётся компилировать функцию, чтобы она могла работать для любого аргумента. Итоговая функция будет хорошо оптимизирована, ввиду чего будет иметь большой размер, а значит компилятор не будет её инлайнить.Если вы скопмилируете код с ключом
/O1, то никакие оптимизации к sumOfCubes не применятся. Компиляция с ключом /O2 даст оптимизации по скорости. При этом размер кода значительно увеличится, т. к. цикл внутри функции sumOfCubes будет размотан и векторизован. Очень важно понимать, что векторизация будет невозможна без инлайнинга функции cube. Более того, размотка цикла также не будет столь эффективно без инлайнинга. Упрощённое графическое представление итогового кода приведено на следующей картинке (этот граф справедлив как для x86, так и для x86-64).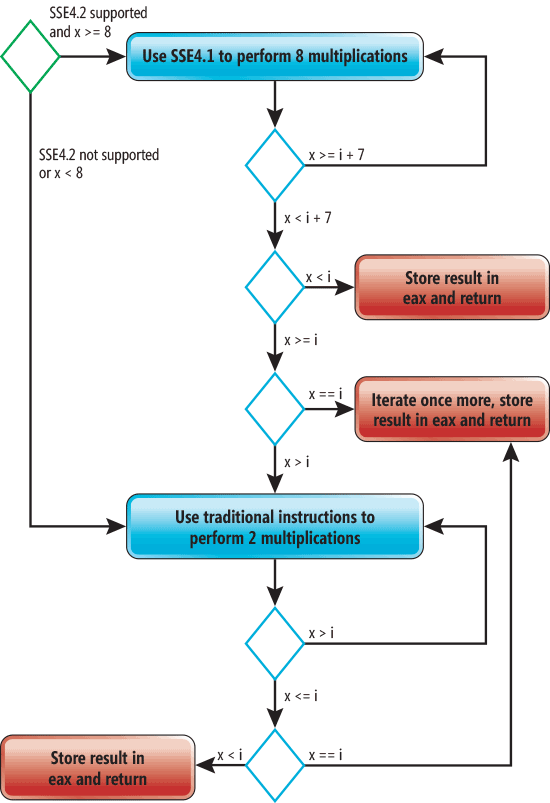
На данной схеме зелёный ромб показывает точку входа, а красные прямоугольники показывают точки выхода. Голубые ромбы представляют условные операторы, которые будут выполняться при выполнении функции
sumOfCubes. Если SSE4 поддерживается и x больше или равно 8, то SSE4-инструкции будут использованы для того, чтобы выполнять 4 умножения за 1 раз. Процесс выполнения одинаковой операции для нескольких переменных называется векторизацией. Также компилятор дважды размотает этот цикл. Это означает, что тело цикла будет повторено дважды на каждую итерацию. В результате выполнение восьми операций умножения будет происходить за 1 итерацию. Если x меньше 8, то для выполнения функции будет использован код без оптимизаций. Обратите внимание, что компилятор вставляет три точки выхода вместо одной — таким образом уменьшается количество переходов.Размотка циклов осуществляется повторением тела цикла несколько раз внутри одной итерации нового (размотанного) цикла. Это повышает производительность, т. к. операции самого цикла будут выполняться реже. Кроме того, это позволяет компилятору выполнять дополнительные оптимизации (например, векторизацию). Недостатком размотки циклов является увеличение количества кода и нагрузка на регистры. Но несмотря на это, в зависимости от тела цикла подобная оптимизация может увеличить производительность на двухзначный процент.
В отличие от x86-процессоров, все процессоры x86-64 поддерживают SSE2. Более того, вы можете использовать преимущества инструкций AVX/AVX2 на последних моделях x86-64 процессоров от Intel и AMD с помощью ключа
/arch. Указав /arch:AVX2, вы скажете компилятору также использовать инструкции FMA и BMI.На текущий момент компилятор Visual C++ не позволяет контролировать размотку циклов. Но вы можете влиять на неё с помощью
__forceinline и директивы loop c опцией no_vector (последняя выключает автовекторизацию заданных циклов).Если вы посмотрите на сгенерированный ассемблерный код, то можете заметить, что к нему можно применить дополнительные оптимизации. Но компилятор всё-равно уже сделал отличную работу и нет нужды тратить намного больше времени на анализ, чтобы применить минорные оптимизации.
Функция
someOfCubes не является единственной, цикл которой был размотан. Если вы модифицируете код и передадите m в функцию sum вместо n, то компилятор не сможет предподсчитать её значение и ему придётся генерировать код, цикл будет размотан дважды.В заключение мы посмотрим на такую оптимизацию, как вынос инвариантов цикла. Взглянем на следующий код:
int sum(int x) {
int result = 0;
int count = 0;
for (int i = 1; i <= x; ++i) {
++count;
result += i;
}
printf("%d", count);
return result;
}
Единственное изменение, которое мы сделали, заключается в добавлении дополнительной переменной, которая увеличивается на каждой итерации, а в завершении выводится на консоль. Нетрудно заметить, что данный код легко оптимизируется с помощью выноса инкрементируемоей переменной за рамки цикла: достаточно просто присвоить ей значение
x. Данная оптимизация называется выносом инварианта цикла (loop-invariant code motion). Слово «инвариант» показывает, что данная техника применима тогда, когда часть кода не зависит от выражений, включающих переменную цикла.Но вот загвоздка: если вы примените эту оптимизацию вручную, то итоговый код может потерять в производительности в определённых условиях. Можете ли вы сказать почему? Представьте, что переменная
x не положительна. В этом случае цикл не будет выполняться, а в неоптимизированной версии переменная count останется нетронутой. Версия соптимизированная вручную выполнит лишнее присваивание из x в count, которое будет выполнено вне цикла! Более того, если x отрицательно, то переменная count получит неверное значение. И люди, и компиляторы подвержены подобным ловушкам. К счастью, компилятор Visual C++ достаточно умён, чтобы догадаться до этого и проверить условие цикла до присваивания, улучшая производительность для всех возможных значений x.В заключение хочется сказать, что если вы не компилятор и не эксперт по оптимизациям компилятора, то вы должны избегать таких преобразований своего кода, которые заставят выглядеть его так, будто бы он работает быстрее. Держите свои руки чистыми и доверьте компилятору оптимизировать ваш код.
Контролирование оптимизаций
В дополнение к ключамO1, /O2, /Ox, вы можете контролировать специфические функции с помощью директивы optimize:#pragma optimize( "[optimization-list]", {on | off} )
В данном примере optimization list может быть пустым, а может содержать одно или несколько значений из набора:
g, s, t, y. Они соответствуют ключам /Og, /Os, /Ot, /Oy.Пустой список c параметром
off выключает все оптимизации вне зависимости от ключей компилятора. Пустой список с параметром on применяет вышеозначенные ключи компилятора.Ключ
/Og позволяет выполнять глобальные оптимизации, которые могут быть выполнены только внутри оптимизируемой функции, а не в функциях, которые её вызывают. Если LTCG включён, то /Og позволяет делать WPO.Директива
optimize очень полезна в случаях, когда вы хотите, чтобы разные функции были оптимизированы разными способами: одни по занимаемому размеру, а другие по скорости. Впрочем, если вы действительно хотите иметь контроль оптимизаций такого уровня, вы должны посмотреть в сторону profile-guided-оптимизаций (PGO), которые представляют собой оптимизацию кода с использованием профиля, хранящего информацию о поведении, записанную во время выполнения инструментальной версии кода. Компилятор использует профиль для того, чтобы обеспечить лучшие решения во время оптимизации кода. Visual Studio представляет специальные инструменты, чтобы применить эту технику как к нативному, так и к управляемому коду.Оптимизации в .NET
В .NET нет линковщика, который был бы вовлечён в модель компиляции. Вместо этого есть компилятор исходного кода (C# compiler) и JIT-компилятор. Над исходным кодом выполняются только минорные оптимизации. Например, на этом уровне вы не увидите инлайнинга функции или оптимизаций циклов. Вместо этого данные оптимизации выполняются на уровне JIT-компиляции. JIT-компилятор до версии .NET 4.5 не поддерживал SIMD. А вот JIT-компилятор с версии .NET 4.5.1 (который называется RyuJIT) поддерживает SIMD.В чём же разница между RyuJIT и Visual C++ с точки зрения возможностей оптимизации? Ввиду того, что RyuJIT работает во время выполнения, он может выполнить такие оптимизации, на которые Visual C++ не способен. Например, прямо во время выполнения он может понять, что выражение в условном операторе никогда не примет значение
true в текущей запущенной версии приложения, а затем применить соответствующие оптимизации. Также RyuJIT может использовать знания об используемой процессорной архитектуре во время выполнения. Например, если процессор поддерживает SSE4.1, то JIT-компилятор использует только инструкции SSE4.1 для реализации функции subOfCubes, что позволит сделать генерируемый код более компактным. Но нужно понимать, что RyuJIT не может тратить на оптимизации много времени, т. к. время JIT-компиляции влияет на производительность приложения. А вот компилятор Visual C++ может потратить на анализ кода много времени, чтобы найти возможности оптимизации для улучшения итогового исполняемого файла. Благодаря новой замечательной технологии от Microsoft под названием .NET Native вы можете компилировать управляемый код в самодостаточные исполняемые файлы с использованием оптимизаций Visual C++. В настоящее время эта технология поддерживает только приложения из Windows Store.На сегодняшний день возможность контролировать оптимизации управляемого кода ограничена. Компиляторы C# и Visual Basic позволяют только включать или выключать оптимизации с помощью ключа
/optimize. Для контроля JIT-оптимизаций вы можете применить атрибут System.Runtime.CompilerServices.MethodImpl к нужному методу с опцией из MethodImplOptions. Опция NoOptimization выключает оптимизации, опция NoInlining запрещает инлайнить метод, а опция AggressiveInlining (доступна с .NET 4.5) даёт JIT-компилятору рекомендацию, что ему следует заинлайнить данный метод.