Comments 38
Очень интересно, спасибо за статью!
А есть где-нибудь исходники симуляции?
А есть где-нибудь исходники симуляции?
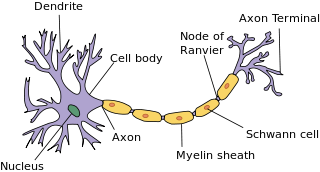
пару соседних нейронов, как правило, связывает не один синапс, а порядка десятка
Не понял этого момента. Аксон один, соответственно он может соединиться только с одним дендритом через синапс. А если нейроны соединены больше чем одним синапсом, то значит они соединены несколькими дендритами. Я понял, что дендриты это «вход». Какой смысл объединять несколько входов, если они могут только принимать сигнал? Или через дендрит может быть исходящий сигнал тоже? Или у синапса на конце тоже есть мочалка дендритов, которыми он может соединяться с другими нейронами?
Возможно, кому-то покажется интересной еще одна тема: «Висцеральная теория сна»
О том, как одни и те же области мозга анализируют зрение, слух во время бодрствования, и внутренние «датчики» во время сна, откуда берутся периодические сигналы во время сна и т.д.
polit.ru/article/2014/05/04/pigarev/
О том, как одни и те же области мозга анализируют зрение, слух во время бодрствования, и внутренние «датчики» во время сна, откуда берутся периодические сигналы во время сна и т.д.
polit.ru/article/2014/05/04/pigarev/
Логичная теория, сразу понятна верность выражения — стукнулся так что искры из глаз посыпались, а также когда бухим черти и звуки мерещатся — это значит сигналы от внутренних органов перебивают сенсоры органов чувств.
Эта теория не доказывает, что звуки и черти мерещатся именно из-за сигналов от внутренних органов. И вообще не касается мистики и пограничных состояний сознания.
Искры из глаз объясняются гораздо проще. Клетки сетчатки, помимо света, реагируют и на механическое воздействие, но любой сигнал от них интерпретируется мозгом как свет. Можете убедиться в этом сами, аккуратно надавив пальцем себе на глазное яблоко.
Ждем в комментариях AlexeyR.
Алексей, так какая же примитивнейшая схема работы мозга?
Каков аналог фон-неймановской архитектуры мозга?
Вот мне пока из множества статей (как этой, так и ваших) пока не понятен базовый сценарий работы мозга.
Алексей, так какая же примитивнейшая схема работы мозга?
Каков аналог фон-неймановской архитектуры мозга?
Вот мне пока из множества статей (как этой, так и ваших) пока не понятен базовый сценарий работы мозга.
А еще лучше не схема или сценарий, а принцип.
предлагаю на роль такого принципа:
-наиболее эффективное извлечение информации(знание)
-моделирование будущего(воображение)
-максимизацию будущей свободы(власть)
Зная принцип, можно составить и схему, и сценарий.
предлагаю на роль такого принципа:
-наиболее эффективное извлечение информации(знание)
-моделирование будущего(воображение)
-максимизацию будущей свободы(власть)
Зная принцип, можно составить и схему, и сценарий.
Моя модель совсем другая. В двух словах не объяснишь.
Жаль, что нельзя просто объяснить основной принцип работы мозга, отбросив все несущественные усложнения.
Для меня ваша волновая модель показалась достаточно интересной.
Тем более она отчасти совпадает с описанным здесь фактором задержек.
Но в голове пока не складывается единой простой картины базовых принципов работы мозга.
Для меня ваша волновая модель показалась достаточно интересной.
Тем более она отчасти совпадает с описанным здесь фактором задержек.
Но в голове пока не складывается единой простой картины базовых принципов работы мозга.
Фактор задержек — это другая история. Так пытаются в спайковых моделях объяснить, как нейрон может улавливать тонкую временную разницу в следовании сигналов. При этом подразумевают, что в изменении интервалов закодирована определенная информация. Мне удалось показать совсем другой механизм, который на порядки надежнее и мощнее. Про базовые принципы если хотите в двух словах, то можно так. Мозг работает с понятиями смысл которых определен неоднозначно. Для каждого понятия есть спектр смыслов. Описание в нечетких понятиях может иметь разные толкования (реализации). Удалось показать модель, которая реализует две стадии описания: волновое описание — нечеткое и описание через активность миниколонок — четкое. Переработка информации в такой системе — это постоянный переход от нечеткого описания к четкому и обратно к нечеткому. Правила этих переходов не зашиты жестко в систему, а есть результат обучения. Механизм обучения с подкреплением позволяет обучиться оптимальным в определенном смысле информационным переходам.
А что вы подразумеваете под базовым сценарием работы мозга?
Думать? Говорить? Читать? Писать текст? Играть в футбол?
Думать? Говорить? Читать? Писать текст? Играть в футбол?
UFO just landed and posted this here
Ещё Джефф часто упоминает проект Numenta, который как раз пытается реализовать его идеи(и не только его) в коде и к тому же находится в открытом доступе на GitHub
Ну, их Grok уже вовсю пашет, выискивая аномалии в данных предприятий.
Ну как пашет…
В их главной научной бумажке, кажется, 2009 года — HTM CLA — две абстракции:
одна сравнима с маленькой рекуррентной нейросетью (temporal pooler),
вторая — с маленькой однослойной нейросетью (spatial pooler).
Предполагается только обучение без учителя (т.к. обратной связи нет).
По моим оценкам, технология крайне вычислительно неэффективна (в т.ч. temporal pooler тяжело оптимизировать под видеокарту из-за особенностей алгоритма работы), поэтому даже на двумерных данных её не получается использовать. Обычные нейросети с обратным распространением как минимум в 100 раз эффективнее, увы.
Я как-то пробовал применять их алгоритм на MNIST со сдвигами… получил точность порядка 50% (при этом наивный байес дал около 72%, а нейросети при сравнимых вычислительных затратах дают 99%).
Заметьте, их научный коллектив до сих пор с 2009 года не выложил ни одного результата состязания нейросетей, что со всей очевидностью говорит о плачевном качестве их технологий.
В их главной научной бумажке, кажется, 2009 года — HTM CLA — две абстракции:
одна сравнима с маленькой рекуррентной нейросетью (temporal pooler),
вторая — с маленькой однослойной нейросетью (spatial pooler).
Предполагается только обучение без учителя (т.к. обратной связи нет).
По моим оценкам, технология крайне вычислительно неэффективна (в т.ч. temporal pooler тяжело оптимизировать под видеокарту из-за особенностей алгоритма работы), поэтому даже на двумерных данных её не получается использовать. Обычные нейросети с обратным распространением как минимум в 100 раз эффективнее, увы.
Я как-то пробовал применять их алгоритм на MNIST со сдвигами… получил точность порядка 50% (при этом наивный байес дал около 72%, а нейросети при сравнимых вычислительных затратах дают 99%).
Заметьте, их научный коллектив до сих пор с 2009 года не выложил ни одного результата состязания нейросетей, что со всей очевидностью говорит о плачевном качестве их технологий.
На живых логах они хорошо проблемы ловят, это имеет прикладную ценность.
Может быть они не ориентированы на академический паблишинг, политика у компаний может быть разной.
На рынке DL есть большая неопределнность в плане алгоритмов, архитектур и их эффективности их работы.
Метрик куча, отдельно пространство объемов и характера обучающих и тестовых данных, отдельно потребление ресурсов в виде памяти, памяти с большим временем доступа и камня.
MNIST отличный тест, но я затрудняюсь сказать, о чем говорит его успешное прохождение, вдруг идеальный алгоритм работы юнитов и конфигурация сетки провалятся, если поднять уровень задачи, допустим, до распознавания слов.
Без кластера на серьезных задачах далеко не уедешь, алгоритмическая часть и общая архитектура очень сильно влияет на то, какой у него будет аппаратный состав и, соответственно, цена. А это очень важное ноу-хау и вскрывать его раньше времени достаточно опрометчиво, вдруг, вопреки здравому смыслу, решающей для определенных алгоритмов мощность отдельного ядра, работающая с большими фреймами вычислений и небльшими синками с глобальным стейтом или еще что ни будь. А может важно, чтобы все юниты (нейроны, колонки, макроколонки, без разницы какие группы векторов) по первому чиху синкались на 100 соседей, а предсказательная способности отдельного юнита может быть, условно, на 1% выше рендома.
Выставить наружу облачную соску в составе коммерческого решения в этом плане безопасно.
Насколько я помню, последние публичные челленджи у нументы на форуме были где-то в области определения «емкости», то есть соотношения потребления памяти и предсказательной силы сетки, немного намекает. Потом был массовый хантинг спецов по кассандре и хадупу. На каком стеке и что у них сейчас вертится сказать сложно.
Если говорить об обучении без учителя, имхо, это очень интересное направление, так как биологическая реализация лежит и за пределами кортекса и обратного распространения сигнала в рамках него. У органической твари есть инпут на который идут сигналы, то, что ее чему-то «обучают», это ровно такой же инпут как и любые другие. Но есть система вознаграждения, состояние которой очень серьезно дифференциирует поступающие паттерны, а также другие проявления древних структур, которые стучатся изнутри.
Начальная дифференциация идет на уровне инстинктов, сделал X после этого погладили — приятно, пнули — больно. А дальше взаимодействие кортекса с RS и древними структурами в целом, доходит до того, что от портрета Бенджамина Франклина у высших приматов случается стояк, что очень далеко от стимулов, которые мы понимаем врожденно. Тебя могут пнуть один раз в жизни, а потом добрая часть поведения будет строится на результатах шока от этого пинка.
Может быть, взаимодействие со структурой подкрепления не менее важно, чем то, как именно аккумулировать статистику по паттернам, с чем вполне справляются деревья суффиксов, фильтры сигнал/шум и прочие далекие от биологии структуры.
Если я вдруг заинтересовал, можно поглядеть тут и далее по ссылкам.
Может быть они не ориентированы на академический паблишинг, политика у компаний может быть разной.
На рынке DL есть большая неопределнность в плане алгоритмов, архитектур и их эффективности их работы.
Метрик куча, отдельно пространство объемов и характера обучающих и тестовых данных, отдельно потребление ресурсов в виде памяти, памяти с большим временем доступа и камня.
MNIST отличный тест, но я затрудняюсь сказать, о чем говорит его успешное прохождение, вдруг идеальный алгоритм работы юнитов и конфигурация сетки провалятся, если поднять уровень задачи, допустим, до распознавания слов.
Без кластера на серьезных задачах далеко не уедешь, алгоритмическая часть и общая архитектура очень сильно влияет на то, какой у него будет аппаратный состав и, соответственно, цена. А это очень важное ноу-хау и вскрывать его раньше времени достаточно опрометчиво, вдруг, вопреки здравому смыслу, решающей для определенных алгоритмов мощность отдельного ядра, работающая с большими фреймами вычислений и небльшими синками с глобальным стейтом или еще что ни будь. А может важно, чтобы все юниты (нейроны, колонки, макроколонки, без разницы какие группы векторов) по первому чиху синкались на 100 соседей, а предсказательная способности отдельного юнита может быть, условно, на 1% выше рендома.
Выставить наружу облачную соску в составе коммерческого решения в этом плане безопасно.
Насколько я помню, последние публичные челленджи у нументы на форуме были где-то в области определения «емкости», то есть соотношения потребления памяти и предсказательной силы сетки, немного намекает. Потом был массовый хантинг спецов по кассандре и хадупу. На каком стеке и что у них сейчас вертится сказать сложно.
Если говорить об обучении без учителя, имхо, это очень интересное направление, так как биологическая реализация лежит и за пределами кортекса и обратного распространения сигнала в рамках него. У органической твари есть инпут на который идут сигналы, то, что ее чему-то «обучают», это ровно такой же инпут как и любые другие. Но есть система вознаграждения, состояние которой очень серьезно дифференциирует поступающие паттерны, а также другие проявления древних структур, которые стучатся изнутри.
Начальная дифференциация идет на уровне инстинктов, сделал X после этого погладили — приятно, пнули — больно. А дальше взаимодействие кортекса с RS и древними структурами в целом, доходит до того, что от портрета Бенджамина Франклина у высших приматов случается стояк, что очень далеко от стимулов, которые мы понимаем врожденно. Тебя могут пнуть один раз в жизни, а потом добрая часть поведения будет строится на результатах шока от этого пинка.
Может быть, взаимодействие со структурой подкрепления не менее важно, чем то, как именно аккумулировать статистику по паттернам, с чем вполне справляются деревья суффиксов, фильтры сигнал/шум и прочие далекие от биологии структуры.
Если я вдруг заинтересовал, можно поглядеть тут и далее по ссылкам.
Последнее в общем виде называется Reinforcemence Learning, это такая трава, на которую переходят те, кому одной зоны мозга и одного классификатора мало, скажем, AlexeyR или DeepMind ( arxiv.org/pdf/1312.5602.pdf ) :)
А в целом, скажу, что Numenta — молодцы, что нашли выгодную коммерческую нишу.
Решение у них так себе, но если худо-бедно работает — то и слава богу.
Что прикольно — необходимое качество работы в этой области низкое, ну, поднимут несколько лишних инстансов или чего не хватит — всё будет лучше чем всегда держать большой резерв.
Просто видимо до них никто не интересовался такой странной и узкой областью.
А в целом, скажу, что Numenta — молодцы, что нашли выгодную коммерческую нишу.
Решение у них так себе, но если худо-бедно работает — то и слава богу.
Что прикольно — необходимое качество работы в этой области низкое, ну, поднимут несколько лишних инстансов или чего не хватит — всё будет лучше чем всегда держать большой резерв.
Просто видимо до них никто не интересовался такой странной и узкой областью.
Кроме того, обучение колонки нейронов локализовано — изменение сопротивления синапса зависит от поведения лишь двух соединённых им нейронов, и никаких других. В результате этого, обучение приводит к изменению сопротивлений вдоль пути следования сигнала, тогда как при обучении нейронной сети веса изменяются в обратном направлении: от нейронов, ближайших к выходу — к нейронам, ближайшим ко входу.
кстати это и есть в точности правила Хебба
The general idea is an old one, that any two cells or systems of cells that are repeatedly active at the same time will tend to become 'associated', so that activity in one facilitates activity in the other.
позже аналогично этому правилу ввели противоположное — если нейроны активируются асинхронно, то связь слабеет или даже удаляется
так вот, к чему я это, нельзя обобщать, на все нейросети, правило что обучение идет в обратном порядке, это касается только бэкпропа и обучения с учителем, скажем Джефри Хинтон (хоть он и один из авторов бэкпропа) давно продвигает идею того, что мозг не работает по принципу supervised learning, а именно unsupervised
его идея заключается в том, что биологическая нейросеть занимается кластеризацие, а позже уже кто то (например родители ребенка) присваивают имена кластерам, скажем ребенок тычет пальцем в котов, а родители ему говорят что это коты, и мозг просто приписывает метку кластеру
вот что пишет Хинтон:
When we’re learning to see, nobody’s telling us what the right answers are we just look. Every so often, your mother says “that’s a dog”, but that’s very little information. You’d be lucky if you got a few bits of information even one bit per second that way. The brain’s visual system has 1014 neural connections. And you only live for 109 seconds. So it’s no use learning one bit per second. You need more like 105 bits per second. And there’s only one place you can get that much information: from the input itself.
а современные нейросети по типу машин Больцмана уже не используют идеи слоистости, и даже глубокие машины Больцмана хоть с виду и «слоеные», но обучение происходит не от конца к началу, а в «целом» (не если грубо говоря =)
вот кстати рекомендую интервью Хинтона http://www.reddit.com/r/MachineLearning/comments/2lmo0l/ama_geoffrey_hinton где он говорит что одна из целей его школы на близжайшие несколько лет это разработка концептов новых нейросетей с нейроколонками
Спасибо за подробный комментарий!
Словосочетанием «нейронная сеть» в тексте обозначена не совокупность всех имеющихся теорий о работе нейронов и их сетей, а конкретное семейство моделей.
Возможно, такое обозначение привело к некоторой путанице.
Словосочетанием «нейронная сеть» в тексте обозначена не совокупность всех имеющихся теорий о работе нейронов и их сетей, а конкретное семейство моделей.
Возможно, такое обозначение привело к некоторой путанице.
По-моему, в мозгу невозможно выделить «принципиальную схему». Проблема в том, что эволюция работает не на модулях и абстракциях, а на грязных хаках и быдлокоде. Свистелки и переделки неотделимы от архитектуры. ИМХО, имело бы смысл проследить эволюционное развитие мозга: насколько я понимаю, в нервной системе гидр никаких секретов нет.
Если бы все было так, как вы говорите, то организмы представляли бы из себя полнейшую кашу из белков, тогда как в реальности можно наблюдать вполне себе оформленные подсистемы (органы) и процессы (сон, пищеварение, размножение и т.д.). На микроуровне, конечно, степеней свободы больше на порядки. Эволюционное развитие наоборот стремится к организации. От простейших к млекопитающим. От инстинктивного поведения к разумному.
Они и представляют собой кашу из белков. Органы — это не модули, это, скорее оверлеи, функции между которыми распределены наиболее эффективным, а не наиболее логичным образом. Т. е. логично, что для пищеварения и для перекачки крови нужны две различных полости, это вовсе не признак модульности. А эволюция стремится к эффективности любой ценой.
UFO just landed and posted this here
UFO just landed and posted this here
Насколько мне известно, большинство сигналов в мозге распространяются химически, а не электрически.
Отбрасывание не попадающих «в такт» синапсов, на мой взгляд, это не фича, а «деталь реализации» для самой первой/древней функции нейрона — создание нерва для передачи сигнала по этому «проводу». На самом деле, как ещё можно было бы создать «провод», если каждый его участок может только выбрасывать вперёд свои контакты без понятия к кому они на самом деле подсоединились(?). Масса медиаторов потом появилась как раз для того, чтобы не появлялись залипы между разными каналами — дендриты ползут «на запах» только к своему целевому типу нейронов.
Есть ли данные о разбросе задержек?
То, что в статье в примере называется колонкой, ей не является. Колонка состоит из нейронов разных типов, а не просто группа.
Есть ли данные о разбросе задержек?
То, что в статье в примере называется колонкой, ей не является. Колонка состоит из нейронов разных типов, а не просто группа.
Спустя пять лет с прошлого своего поста пришёл к тем же самым взглядам, что и Джеймс Смит. Только одних пространственных паттернов стало недостаточно для кодирования образов, необходимо оценивать пространственно-временную картину. Хорошо, что сейчас не требуется всё выводить самостоятельно, так как Смит три года назад выпустил отличную объёмную работу «Space-Time Computing with Temporal Neural Networks».
Sign up to leave a comment.
Как работает мозг?