Привет читатель. Этот небольшой вступительный пост о нашем проекте — поисковом сервисе GrabDuck. О том, что это такое, какие проблемы мы пытались решить и, что из всего этого получается.
Проще говоря, история проекта в поисках своих благодарных клиентов, которую мы постарались сделать не нудной и интересной. Получилось или нет — судить вам. Кого заинтересовало, просим под Cut.
Большинству из нас знакома проблема с сохранением закладок в браузере. Мы постоянно читаем что-то новое и откладываем то, что интересно, чтобы быстро найти позже.
Я тоже так поступал. Все, что было интересно, я сохранял в качестве закладок в Google Chrome. Когда закладок стало много, начался долгий процесс их классификации — так появилась папка «Программирование», в ней «java», а рядом поместились «php» и «javascript». Потом куча других технологий, которые так или иначе интересовали меня. Со временем разбираться во всем этом стало тяжело — стандартная функциональность не позволяет сделать много. Некоторые ссылки можно было отнести сразу к нескольким папкам, а иногда я просто забывал о старой классификации и делал новую по соседству.
Когда закладок стало совсем много и не было времени сортировать их сразу, я нашел выход — у меня появилась папка «Входящие». Я дал себе слово, что буду по пятницам расчищать ее и начал сваливал туда все, что находил. Однако и это не сработало, по пятницам всегда находилось что-то более интересное. Так и лежали большинство моих закладок во входящих (как-то раз считал — было их там где-то далеко за 400). Со временем поймал себя на том, что просто иду во входящие и открываю от туда то, что мне нужно и о чем помню. А то, о чем не помнил я просто не открывал, а искал заново в Google.
Так и родилась идея GrabDuck. А почему я не могу искать в своих закладках также, как мы это регулярно делаем в поисковых системах — задавая поисковые запросы. Ведь чаще всего я пытаюсь найти нужную мне статью потому что (1) я знаю о чем именно была статья (и следовательно, могу в общих чертах сформулировать поисковый запрос) и (2) точно помню, что нужная статья где-то была у меня (а может и не одна).
«Стоп», — сказал я себе — ведь я на работе занимаюсь именно этим — поиском. Знаю, как он устроен, есть практический опыт. И вот на тебе — сапожник без сапог.
Так начался наш GrabDuck.
Что такое GrabDuck и каким мы видим его?
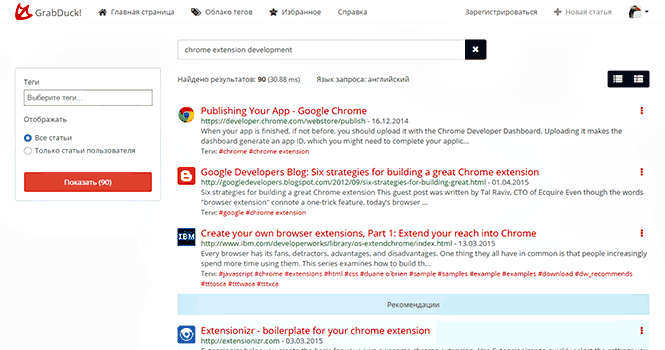
GrabDuck — это сервис хранения закладок, где можно искать «как в Google». Основная идея сервиса, это позволить пользователю бросить документ в «копилку» и забыть — система поможет найти его, когда он будет необходим.
Поэтому GrabDuck, это прежде всего поиск. Хороший полноценный полнотекстовый поиск по всем материалам которые я сохранил (не только по заголовку, но и по всей статье). Поиск, пытающийся найти фразы поискового запроса с учетом лексики, а не просто набор слов, который ввел пользователь. Это поиск, который постоянно обучается, какие поисковые запросы я ввожу и какие документы открываю чаще всего и адаптируется к моим предпочтениям.
Кроме того, как «бесплатный» бонус, система предлагает свои рекомендации из статей других пользователей, которые могут быть также интересны мне, опять таки, исходя из моих запросов и предпочтений. И, если рекомендованная статья действительно интересная, я могу добавить эту статью к себе.
Небольшой обзор с комментариями о том какие технологии и для чего мы используем.

Наш сервер это Apache Tomcat на котором работают несколько Java приложений. Мы постарались следовать принципам Microservices Architecture и вынесли разные части приложения в разные модули, которые общаются между собой. В принципе, сейчас нам достаточно одного сервера на все, но в будущем, когда потребуется, мы можем, например, развернуть дополнительный модуль, который занимается парсингом статей на второй машине, таким образом повысив мощность только одного компонента системы, не меняя всего остального.
В качестве front-end сервера мы используем Nginx. Долго выбирали между Apache и Nginx, в результате остановились на втором. Причины просты — для нас он оказался более легковесным и простым в настройке.
Для хранения и работы с данными используем связку MySQL + Solr. Этакий гибрид, где каждый компонент занимается тем, что ему удается лучше всего.
MySQL отвечает за целостность и хранение данных в нормализированном виде. Мы всегда можем собрать из нескольких таблиц всю необходимую информацию о документе — контент страницы, мета данные, у кого страница есть в закладках, персональную для каждого пользователя информацию, например такую, как теги. Один большущий минус этой системы — MySQL очень медленный и практически не предоставляет возможностей для полнотекстового поиска. Следует сказать, что вообще, с точки зрения поиска, все fulltext search решения, которые предоставляют сейчас современные SQL продукты, это, как правило, какие-то базовые возможности, с которыми очень трудно и местами практически невозможно сделать что-то годное.
Итого, для поиска MySQL был не очень хорош. Поэтому, когда необходимо найти что-то по запросу пользователя, вступает в работу второй компонент — Solr, который отвечает за поиск и агрегацию информации. Каждый документ из базы, при создании или изменении, отправляется в Solr и на его основе создается представление, которое и будет использоваться непосредственно для поиска.
Таким образом имеем все преимущества классической SQL базы данных объединенные с быстротой и мощью, которые нам дает NoSQL.
Расмотрим, что происходит когда пользователь добавляет что-то в систему. Это может быть как один документ, добавляемый через расширение хрома, так и импорт большого количества закладок, суть не меняется и всегда данные проходят по одному и тому же алгоритму.
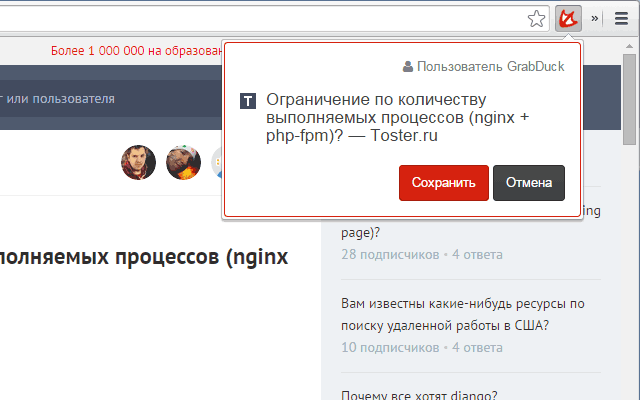
Для начала создается новый документ, в котором сохраняется URL и, если известно, заголовок. С этого момента пользователь видит документ у себя, хотя полнотекстовый поиск конечно же пока не доступен. Через какое-то время, как правило не позднее 5 минут запускается задача по парсингу. Для парсинга страницы и извлечения из нее статьи мы используем адаптированную нами библиотеку Snaktory. На выходе получаем содержимое статьи, мета информацию и теги.
Теперь нам необходимо проверить, если данная статья уже находиться в базе данных. Если да, то сохранять ее нет необходимости и пользователь пожет «переиспользовать» существующую. Совпадение проверяем по Каноническому URL. Как пример, любая статья на хабре имеет как минимум 3 разных валидных URL: для google/yandex, для мобильного отображения и для десктопа. При этом канонический URL будет всегда один и тот же. Эта же схема позволяет избежать нам дублицирования информации, если пользователь например захочет импортировать несколько раз один и тот же файл с закладками.
Если ссылка не дублирующая, то следующий шаг, это определение языка документа. Это необходимо для двух вещей. Во-первых документ специальным образом адаптируется в поисковом индексе для поиска именно на данном языке (на настоящий момент мы поддерживаем русский и английский, на очереди немецкий). И второе, язык используется для фильтрации при рекомендациях. Например, если про пользователя известно, что он читает на английском и немецком языках, то рекомендации на русском показаны не будут, даже если по поисковому запросу есть какие-то документы на русском. Для определения языка используем библиотеку Language-detection. Большой минус, как библиотеки в частности, так и в целом наверное всех подходов по определению языка — качество резко падает при небольшом объеме текста, по нашим наблюдениям, для 100% результата, необходимо как минимум иметь 500 символов, после качество начинает хромать.
И последний шаг, на основе сохраненного документа, создается сущность в поисковом индексе Solr. С этого момента документ доступен как для прямого полнотекстового поиска так и для отображения в рекомендациях.
MVP готов, появились первые пользователи. Когда чего-то ищут, мы дружно радуемся. Особо мотивирует, когда есть комментарии по делу. Хотим сказать особое спасибо одному из наших пользователей anton_slim — человек реально прошелся по сервису и выкатил список того, что непонятно и криво — поправили.
Сейчас мы занимаемся активным тестированием сервиса и поэтому приглашаем всех пробовать и делиться впечатлениями.
В блоге планируем писать на тему поиска: как мы используем технологии, с какими проблемами сталкиваемся и как их решаем, вообщем все что может быть вам интересно.
Подписывайтесь и давайте общаться.
Проще говоря, история проекта в поисках своих благодарных клиентов, которую мы постарались сделать не нудной и интересной. Получилось или нет — судить вам. Кого заинтересовало, просим под Cut.
Введение
Оффтопик 1, который при первом прочтении можно пропустить
Да, мы знаем, что это гусь, а не утка. Так уж получилось, что, когда мы искали изображение для первой страницы, этот подозрительный гусь нам понравился больше всего, а «прошерстили» мы, поверьте, не один фото-банк. И потом, а кто сказал что должна быть именно утка? Да, это гусь и он наблюдает за тобой.
Нет, мы никак не связаны с проектом DuckDuckGo. Хотелось бы, но нет. Мы не DDG, мы GD. Вообще, какая-то мода пошла на альтернативных поисковых сервисах главными назначать уток, не избежали этого и мы. Хотя, когда придумывали название, даже в голову не приходило, что окажется похожими на что-то еще. Правда, правда!
Часто даваемые ответы
Да, мы знаем, что это гусь, а не утка. Так уж получилось, что, когда мы искали изображение для первой страницы, этот подозрительный гусь нам понравился больше всего, а «прошерстили» мы, поверьте, не один фото-банк. И потом, а кто сказал что должна быть именно утка? Да, это гусь и он наблюдает за тобой.
Нет, мы никак не связаны с проектом DuckDuckGo. Хотелось бы, но нет. Мы не DDG, мы GD. Вообще, какая-то мода пошла на альтернативных поисковых сервисах главными назначать уток, не избежали этого и мы. Хотя, когда придумывали название, даже в голову не приходило, что окажется похожими на что-то еще. Правда, правда!
Большинству из нас знакома проблема с сохранением закладок в браузере. Мы постоянно читаем что-то новое и откладываем то, что интересно, чтобы быстро найти позже.
Я тоже так поступал. Все, что было интересно, я сохранял в качестве закладок в Google Chrome. Когда закладок стало много, начался долгий процесс их классификации — так появилась папка «Программирование», в ней «java», а рядом поместились «php» и «javascript». Потом куча других технологий, которые так или иначе интересовали меня. Со временем разбираться во всем этом стало тяжело — стандартная функциональность не позволяет сделать много. Некоторые ссылки можно было отнести сразу к нескольким папкам, а иногда я просто забывал о старой классификации и делал новую по соседству.
Когда закладок стало совсем много и не было времени сортировать их сразу, я нашел выход — у меня появилась папка «Входящие». Я дал себе слово, что буду по пятницам расчищать ее и начал сваливал туда все, что находил. Однако и это не сработало, по пятницам всегда находилось что-то более интересное. Так и лежали большинство моих закладок во входящих (как-то раз считал — было их там где-то далеко за 400). Со временем поймал себя на том, что просто иду во входящие и открываю от туда то, что мне нужно и о чем помню. А то, о чем не помнил я просто не открывал, а искал заново в Google.
Так и родилась идея GrabDuck. А почему я не могу искать в своих закладках также, как мы это регулярно делаем в поисковых системах — задавая поисковые запросы. Ведь чаще всего я пытаюсь найти нужную мне статью потому что (1) я знаю о чем именно была статья (и следовательно, могу в общих чертах сформулировать поисковый запрос) и (2) точно помню, что нужная статья где-то была у меня (а может и не одна).
«Стоп», — сказал я себе — ведь я на работе занимаюсь именно этим — поиском. Знаю, как он устроен, есть практический опыт. И вот на тебе — сапожник без сапог.
Так начался наш GrabDuck.
О проекте
Оффтопик 2, который тоже можно пропустить
Нет, GrabDuck это не стартап. Устали от традиции называть все и вся громким словом — Стартап. Не хотим участвовать в этой бесконечной битве за инвестора. Хотим сделать хороший сервис, который будет приносить пользователям свою пользу.
Да, мы любим сервис и пользуемся им сами. Знаем, все так говорят, но мы правда пользуемся GD каждый день. Однажды, несколько месяцев назад, когда я показывал приятелю ранний прототип, он спросил: «а что будешь делать, если не пойдет?». «Не страшно, сервер не дорогой, буду платить и пользоваться сам», — ответил я. С тех пор пользуюсь.
Немного банальностей (или продолжение ответов)
Нет, GrabDuck это не стартап. Устали от традиции называть все и вся громким словом — Стартап. Не хотим участвовать в этой бесконечной битве за инвестора. Хотим сделать хороший сервис, который будет приносить пользователям свою пользу.
Да, мы любим сервис и пользуемся им сами. Знаем, все так говорят, но мы правда пользуемся GD каждый день. Однажды, несколько месяцев назад, когда я показывал приятелю ранний прототип, он спросил: «а что будешь делать, если не пойдет?». «Не страшно, сервер не дорогой, буду платить и пользоваться сам», — ответил я. С тех пор пользуюсь.
Что такое GrabDuck и каким мы видим его?
GrabDuck — это сервис хранения закладок, где можно искать «как в Google». Основная идея сервиса, это позволить пользователю бросить документ в «копилку» и забыть — система поможет найти его, когда он будет необходим.
Поэтому GrabDuck, это прежде всего поиск. Хороший полноценный полнотекстовый поиск по всем материалам которые я сохранил (не только по заголовку, но и по всей статье). Поиск, пытающийся найти фразы поискового запроса с учетом лексики, а не просто набор слов, который ввел пользователь. Это поиск, который постоянно обучается, какие поисковые запросы я ввожу и какие документы открываю чаще всего и адаптируется к моим предпочтениям.
Кроме того, как «бесплатный» бонус, система предлагает свои рекомендации из статей других пользователей, которые могут быть также интересны мне, опять таки, исходя из моих запросов и предпочтений. И, если рекомендованная статья действительно интересная, я могу добавить эту статью к себе.
Что мы используем
Небольшой обзор с комментариями о том какие технологии и для чего мы используем.
Наш сервер это Apache Tomcat на котором работают несколько Java приложений. Мы постарались следовать принципам Microservices Architecture и вынесли разные части приложения в разные модули, которые общаются между собой. В принципе, сейчас нам достаточно одного сервера на все, но в будущем, когда потребуется, мы можем, например, развернуть дополнительный модуль, который занимается парсингом статей на второй машине, таким образом повысив мощность только одного компонента системы, не меняя всего остального.
В качестве front-end сервера мы используем Nginx. Долго выбирали между Apache и Nginx, в результате остановились на втором. Причины просты — для нас он оказался более легковесным и простым в настройке.
Для хранения и работы с данными используем связку MySQL + Solr. Этакий гибрид, где каждый компонент занимается тем, что ему удается лучше всего.
MySQL отвечает за целостность и хранение данных в нормализированном виде. Мы всегда можем собрать из нескольких таблиц всю необходимую информацию о документе — контент страницы, мета данные, у кого страница есть в закладках, персональную для каждого пользователя информацию, например такую, как теги. Один большущий минус этой системы — MySQL очень медленный и практически не предоставляет возможностей для полнотекстового поиска. Следует сказать, что вообще, с точки зрения поиска, все fulltext search решения, которые предоставляют сейчас современные SQL продукты, это, как правило, какие-то базовые возможности, с которыми очень трудно и местами практически невозможно сделать что-то годное.
Итого, для поиска MySQL был не очень хорош. Поэтому, когда необходимо найти что-то по запросу пользователя, вступает в работу второй компонент — Solr, который отвечает за поиск и агрегацию информации. Каждый документ из базы, при создании или изменении, отправляется в Solr и на его основе создается представление, которое и будет использоваться непосредственно для поиска.
Таким образом имеем все преимущества классической SQL базы данных объединенные с быстротой и мощью, которые нам дает NoSQL.
Как оно работает
Расмотрим, что происходит когда пользователь добавляет что-то в систему. Это может быть как один документ, добавляемый через расширение хрома, так и импорт большого количества закладок, суть не меняется и всегда данные проходят по одному и тому же алгоритму.
Для начала создается новый документ, в котором сохраняется URL и, если известно, заголовок. С этого момента пользователь видит документ у себя, хотя полнотекстовый поиск конечно же пока не доступен. Через какое-то время, как правило не позднее 5 минут запускается задача по парсингу. Для парсинга страницы и извлечения из нее статьи мы используем адаптированную нами библиотеку Snaktory. На выходе получаем содержимое статьи, мета информацию и теги.
Теперь нам необходимо проверить, если данная статья уже находиться в базе данных. Если да, то сохранять ее нет необходимости и пользователь пожет «переиспользовать» существующую. Совпадение проверяем по Каноническому URL. Как пример, любая статья на хабре имеет как минимум 3 разных валидных URL: для google/yandex, для мобильного отображения и для десктопа. При этом канонический URL будет всегда один и тот же. Эта же схема позволяет избежать нам дублицирования информации, если пользователь например захочет импортировать несколько раз один и тот же файл с закладками.
Если ссылка не дублирующая, то следующий шаг, это определение языка документа. Это необходимо для двух вещей. Во-первых документ специальным образом адаптируется в поисковом индексе для поиска именно на данном языке (на настоящий момент мы поддерживаем русский и английский, на очереди немецкий). И второе, язык используется для фильтрации при рекомендациях. Например, если про пользователя известно, что он читает на английском и немецком языках, то рекомендации на русском показаны не будут, даже если по поисковому запросу есть какие-то документы на русском. Для определения языка используем библиотеку Language-detection. Большой минус, как библиотеки в частности, так и в целом наверное всех подходов по определению языка — качество резко падает при небольшом объеме текста, по нашим наблюдениям, для 100% результата, необходимо как минимум иметь 500 символов, после качество начинает хромать.
И последний шаг, на основе сохраненного документа, создается сущность в поисковом индексе Solr. С этого момента документ доступен как для прямого полнотекстового поиска так и для отображения в рекомендациях.
Где мы сейчас
MVP готов, появились первые пользователи. Когда чего-то ищут, мы дружно радуемся. Особо мотивирует, когда есть комментарии по делу. Хотим сказать особое спасибо одному из наших пользователей anton_slim — человек реально прошелся по сервису и выкатил список того, что непонятно и криво — поправили.
Сейчас мы занимаемся активным тестированием сервиса и поэтому приглашаем всех пробовать и делиться впечатлениями.
В блоге планируем писать на тему поиска: как мы используем технологии, с какими проблемами сталкиваемся и как их решаем, вообщем все что может быть вам интересно.
Подписывайтесь и давайте общаться.
