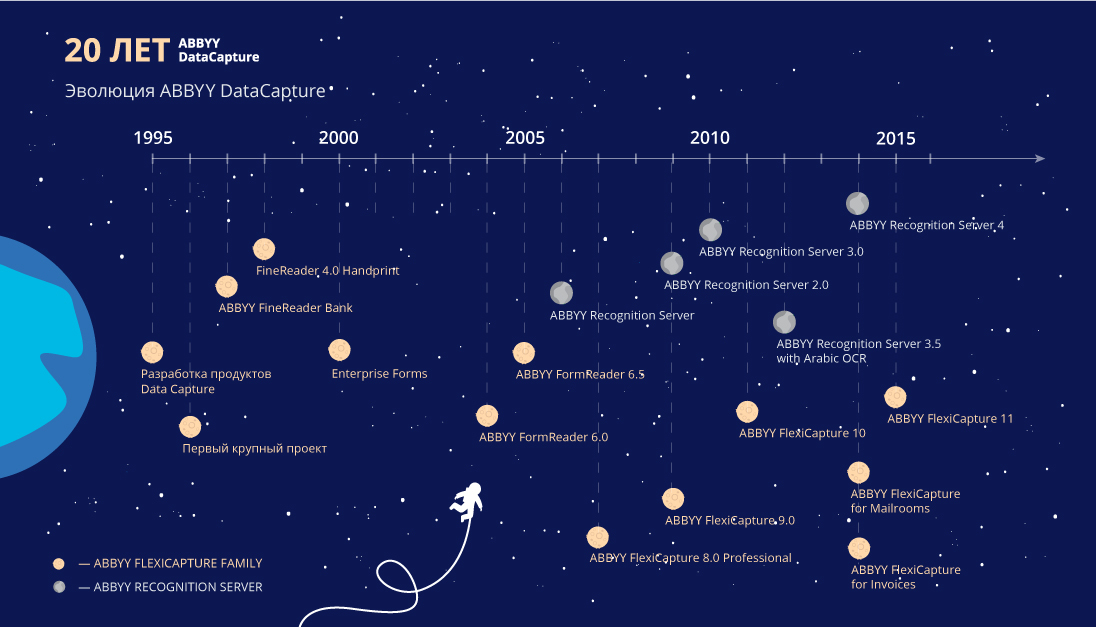
Многие знают ABBYY, прежде всего, благодаря нашим массовым программам – Lingvo, FineReader, различным мобильным приложениям. Но при этом очень важным для нас было и остается корпоративное направление. В частности, на базе наших технологий распознавания текстов мы создали решения в области потокового ввода документов и данных. Они нужны всем организациям, имеющим дело с большими объемами документов – от банков и страховых компаний, до государственных ведомств, нефтяных, энергетических, ритейл и многих других компаний. Недавно этому направлению в ABBYY исполнилось 20 лет.
В жизни любой технологической компании бывают периоды, когда бал правят разработчики. В середине 1995 года в компании «Бит», как называлась ABBYY до переименования в 1997 году, царила атмосфера технологической революции. Мы только выпустили новую версию FineReader 2.0 с прорывной технологией распознавания, написанной практически с нуля, и продукт на глазах завоевывал признание, побеждая в тестах и вызывая восторги у пользователей. Именно тогда мы решили вложиться по-серьезному в программную оболочку, так как с первой версии она практически не менялась. Оболочка версии 3.0 должна была быть большой и развесистой, как полагалось серьезному приложению в те времена, и в максимальной комплектации она должна была обеспечивать богатую функциональность. Разработчики решили, что кроме книг и офисных текстов нам надо научиться вводить еще два типа документов: печатные формы и табличные отчеты из баз данных. Таким образом, в комплекте FineReader, кроме версий Standard и Professional появилась версия Enterprise, где добавились эти две функции.
Сейчас я бы ни за что не взялся за такое, потому что это было безумие. Наши продукты решали задачу ввода описанных выше документов чисто гипотетически: за все время разработки мы не видели ни одного реального пользователя, которому это было бы нужно. Эти пользователи появились уже позднее, когда принесли свои реальные документы, а мы поняли, что нам нужно еще работать и работать. В частности, как выяснилось, задача ввода такого рода документов в реальности актуальна только когда их много. А когда их много, то «коробочным» продуктом, работающим на одном компьютере, тут не обойтись – нужна распределенная система со множеством рабочих мест. А еще нужно уметь поддерживать скоростные сканеры. И еще много чего всего, чего наша система тогда еще не умела. Не говоря уже о том, что формы в основном в те времена заполнялись от руки, а FineReader умел распознавать только печатный текст.
Несмотря на все эти особенности, у нас со временем появились первые клиенты. Среди них были крупные российские организации, которые в значительной степени предопределили развитие направления потокового ввода данных в ABBYY.
Например, была в свое время нынче расформированная структура, которая называлась «Налоговая полиция». В «лихие девяностые», когда крупные налоговые махинации были массовым явлением, требовались люди с оружием и соответствующими полномочиями, чтобы выявлять и обезвреживать различных хорошо оборонявшихся жуликов, наподобие всевозможных «фонарей», занимающихся крупным обналичиванием в обход закона и банков, которые их содержали. Пришли как-то в начале 1996-го года они и к нам, правда, не с проверкой, а с проблемой. У них регулярно возникали оперативные задачи по работе с первичной документацией – платежными поручениями, для выявления схем обхода законов и накопления доказательств. Задачи нужно было решать быстро, пока подозреваемые не замели следы и не исчезли за кордоном. Платежки были жуткого качества, часть из них была напечатана на пишущей машинке на бланках, причем бланки отличались по размеру и расположению полей, часть – на матричных принтерах на чистой бумаге. Нашей технологической команде за рекордно короткие сроки, буквально за 8 месяцев, удалось с нуля изготовить технологию поиска и извлечения полей на таких формах, которая стала основой технологии FlexiCapture.
Здесь уместно отметить, что изначально наши технологии умели извлекать данные из так называемых «жестких», стандартных форм. Все экземпляры таких документов до заполнения одинаковы, как говорится, «на просвет» – если наложить их друг на друга, то одинаковые поля окажутся в одном и том же месте. Достаточно определить координаты этих мест – и при обработке значения полей будут распознаны. Все легко и ясно. Но далеко не всегда ситуация так проста. Многие документы, из которых требуется извлекать данные, не являются жесткими формами. Вот и платёжки, которые нужно было обрабатывать Налоговой полиции, не имели стандартного вида: они очень сильно отличались на просвет, не говоря уже о том, что некоторые данные можно было найти только по содержанию. Для извлечения данных из них создали гибкое описание, которое позволяет оперировать не координатами полей, из которых необходимо извлекать информацию, а их расположением относительно опорных элементов и друг друга, а также типом распознаваемых данных и возможной их структурой.
Форма платежного поручения несколько раз менялась. Сначала была старая советская, потом ее немного переделали и разрешили печатать на чистых листах бумаги, а затем, Центробанк, устав от постоянной необходимости впихивать современные данные в устаревший формат, раз и навсегда поменял формат платежного поручения. Дальше он просто слегка мутировал: появлялись дополнительные поля, но логика расположения информации сохранялась, поэтому наши «гибкие» описания продолжали работать и данные извлекались правильно.
Уже чуть позже похожая задача возникла и в налоговой службе. Всевозможные инвестиционные фонды, которые появлялись в то время как грибы после дождя, огромными трейлерами свозили туда листы бумаги, на которых блеклыми чернилами с помощью матричного принтера были распечатаны отчеты о доходах их бесконечных акционеров. С их немалых доходов полагалось выплатить налоги, а это нужно было проконтролировать. Поэтому перед нами стояла задача ввести данные со всех этих форм обратно в компьютеры. Тут пригодилась та же самая технология, которая до того помогла Налоговой полиции. Продукт, который включал эту технологию, мы внутри компании называли FineReader Эталон. Это был кусок будущего FormReader-а.
Второй кусок FormReader-а пришел из другой истории. Где-то в году 1996-ом, примерно в одно время с Налоговой полицией, к нам обратился Пенсионный фонд с задачей ввода форм.
В 1995 году Пенсионный фонд принял решение централизованно хранить сведения о российских гражданах. Все работающие граждане должны были заполнить анкеты со своими персональными данными, а предприятия каждые полгода должны направлять в Пенсионный фонд сведения о выплаченных своим сотрудникам зарплатах. Вся информация собиралась в региональных отделениях Пенсионного фонда, вводилась в компьютер и посылалась в центральную базу данных. Весь этот гигантский объём – около 150 миллионов бланков – по закону должен был быть обработан за два первых месяца года.
В Пенсионном фонде сначала был один документ, который мы, собственно, и разработали, назывался «Анкета застрахованного лица». Это был одностраничный документ, и его нужно было подавать только один раз на каждого человека. Сейчас под рукой оказалась только маленькая картинка — просто чтоб вы могли составить себе представление об этой древности.

Все эти бланки были заполнены от руки гражданами, которые намеревались доверить свои сбережения Пенсионному фонду. Альтернатив не было. И это обозначало, что нам предстоит таким образом учесть все трудоспособное население страны – почти 70 миллионов граждан.
Масштабы поражали воображение, и мы взялись за дело. В результате появился еще один проект – FineReader Вектор, который включал в себя, помимо распознавания печатных форм, также возможность вводить формы, заполненные печатными буквами от руки. Формы, правда, в отличие от проекта Эталон, предполагалось иметь фиксированные, то есть поля не нужно было искать – они всегда находились в одних и тех же местах на странице. Пенсионный фонд, в результате, не стал дожидаться появления окончательного продукта, способного ввести все 70 миллионов форм по всей стране, и мы успели поставить его только в несколько крупных регионов. В других местах упорные и трудолюбивые сотрудники фонда от нечего делать ввели все формы вручную. Бедняги.
Затем потребовалась вторая форма, которая уже приходила в Пенсионный фонд каждый год, называлась «Индивидуальные сведения о доходах застрахованного лица», мы ее тоже разработали для Пенсионного фонда. Поначалу эта форма была предназначена для рукописного заполнения, затем появились программы, которые научились впечатывать в нее данные, и параллельно пенсионный фонд придумал способ принимать эти данные на дискетах. Помнится, как в отделения выстраивались очереди из сотрудников бухгалтерий, которые одна за другой впихивали в задумчивый дисковод 1,44 дюйма принесенные с собой на дискетах данные и вирусы, а затем отходили в надежде, что данные оказались где надо. Это было утомительно, поэтому многие, если закон позволял (а он требовал электронных данных при определенном количестве сотрудников), предпочитали приносить заполненные от руки бумажки. Сейчас все давно уже не так, и бумажными формами почти никто не пользуется, но тогда ими заполнялись целые склады.
Интерфейс ABBYY FormReader выглядел так:

Чуть позже на основе проекта Эталон появился успешный продукт FineReader Банк, который позволял операционистам банков практически мгновенно вводить платежные поручения. Нынче это почти диковинка – компании пересылают платежки в электронном виде, а в те времена бумажные платежки были основным средством перечисления денег. Операционистки FineReader Банк любили очень – он значительно облегчал им жизнь, избавляя от необходимости стучать по клавишам с утра до вечера.
Первый FormReader, объединивший в себе результаты работы над этими двумя проектами, вырос из коробочного FineReader-а, и сам по себе слабо подходил под задачи массового ввода. Поэтому пришлось делать к нему надстройку, которая позволяет множеству людей работать в одной системе. Все это было громоздко и не имело больших технологических перспектив, поэтому в какой-то момент мы решили создать новый продукт с нуля, изначально заточенный под распределенную работу, масштабирование и прочие энтерпрайзные требования.
Таким образом в 2007 году, спустя 10 лет после того, как ABBYY начала серьезно работать на рынке массового ввода данных, на свет появился FlexiCapture – технологии он наследовал от FormReader, но был написан полностью с нуля. Но все оказалось не так просто – чтобы пользователи смогли перейти на него, требовалось покрыть все возможности прежнего продукта, который разрабатывался много лет. Потребовалось два года, чтобы с появлением FlexiCapture 9.0 новый продукт смог полностью заменить прежний FormReader.
Вот так выглядел интерфейс восьмой версии ABBYY FlexiCapture:


FlexiCapture стал первым самостоятельным решением направления DataCapture в ABBYY и с самого начала был ориентирован на глобальный рынок – его продажи начались одновременно на всех крупных рынках – в США, странах Западной Европы. Покорить новому продукту рынок массового ввода данных сложно – он очень консервативен. На таких больших и тяжелых задачах люди не хотят рисковать, и поэтому полагаются, быть может, не на самые прогрессивные, но зато хорошо проверенные решения. За 7 лет своего существования FlexiCapture уже стал базовым решением, и применяется в самых масштабных проектах по всему миру, таких как переписи населения и другие крупные государственные проекты, системы автоматизации ввода документов корпоративного уровня в крупных интернациональных концернах и т.д.».
Современный ABBYY FlexiCapture постоянно улучшается и учится решать все новые задачи. Сегодня он помогает не только извлекать данные, но и классифицировать их, а кроме компьютера, работать с решением можно через мобильный клиент в облаке. Сложно представить, что когда-то, это значимое сегодня для компаний направление начиналось с амбиций молодой команды и ее стремления доказать, что технологии могут быть эффективнее сотен машинисток.
Ну и напоследок немного статистики. За 20 лет существования продуктов ABBYY для ввода данных:
• Нашими клиентами стали более 90 тысяч организаций во всем мире. Среди них — Deloitte, PepsiCo, Fuji Xerox, Allianz, L’Oréal, ВТБ, Сбербанк, Альфа-Банк, Райффайзенбанк, ММК, «Ингосстрах», СИБУР, Министерство здравоохранения республики Бангладеш, Национальная ассамблея Эквадора и многие-многие другие.
• С помощью наших решений организации ежегодно обрабатывают более 800 млн страниц. Это стопка бумаг высотой в 100 км!
