Было снежное воскресенье, притом еще и Прощенное, и с утра было принято решение сбросить с себя одеяло и начать подготовку своего отъетого за время масленицы тела к летнему пляжному сезону. Питер не очень благосклонен в данный сезон к занятиям спортом на улице, абонемент в спортзал закончился, так что после 5 км лыжного кросса энергия требовала выхода на свободу.
Конечно же, просто залипнуть в Интернет не получилось, и вспомнилась идея предсказания победителя премии «Оскар» в 2018 году, результаты которой будут известны совсем скоро 4-го марта. Данная идея была сформирована в общении с одним интересным человеком, так что спасибо ему за идею.
Возиться с формированием набора данных не хотелось, kaggle тоже не обладал таким, но хотелось сделать что-нибудь не обычное и интересное. Скорректировал задачу: определить общественное мнение по поводу победителя «Оскар»?
Но в начале надо разобраться что там в киноиндустрии твориться и кого хоть номинируют.
90-я церемония вручения наград премии «Оскар» за заслуги в области кинематографа за 2017 год состоится 4 марта 2018 года в театре «Долби» (Голливуд, Лос-Анджелес). Комик Джимми Киммел проведёт церемонию второй год подряд. Номинанты были объявлены 23 января 2018 года (кому интересно).
Итак, все номинации мне не интересны, поэтому будем исследовать общественное внимание по номинациям: лучший фильм, лучший актер, лучшая актриса, лучший саундтрек. Обозначим данные для подготовки запросов.
Но для начала необходимо обеспечить доступ к API Twitter.
Т.к. набора данных у меня не было, пришлось немного подумать и сформулировать критерии оценивания общественного мнения в Twitter:
1) Необходимость поиска и обработки сообщений распространяемых в текущий момент времени (resent), что позволит определить изменения общественного мнения, тенденции. Используем для этого метод API Twitter.
2) Необходимость определения потенциального распространения, т. е. в настоящее время у меня 10 подписчиков, я публикую сообщение, которое ретвитит 2 моих подписчика, у которых по 25 подписчиков. Т. о. количество распространений равно 2, а потенциально возможным равно 10+25+25=60.
3) Необходимость определения тональности сообщений, а также отношение позитива к негативу. Для этого сформируем два словаря позитивных и негативных слов. При помощи формулы Байеса (ссылка) определим условную вероятность тональности сообщения.
4) (Дополнительно) Определение языка сообщений. В разных странах по разному воспринимают кино. Сошлемся на менталитет.
Распространение упоминаний
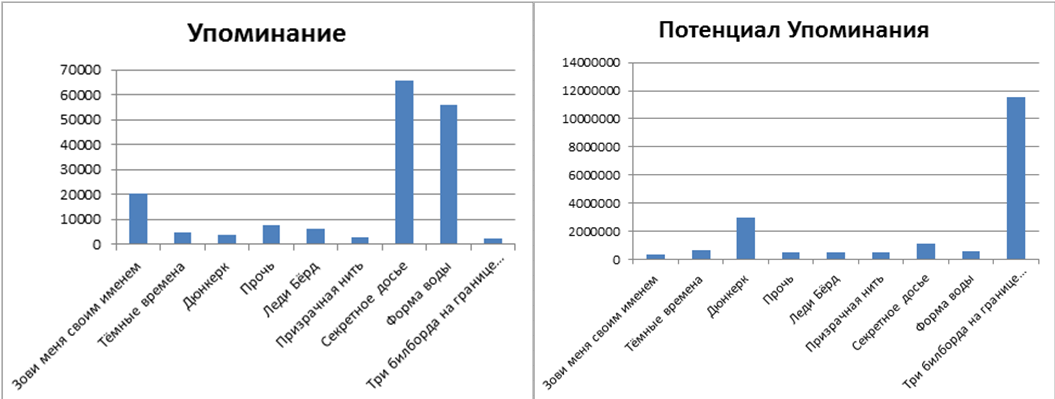
Отношение пользователей социальной сети Twitter к номинированным фильмам

То есть выясним, про какие фильмы говорят на каких языках (соответственно и страны).
(представлена в табличной форме)
(представлена в табличной форме)
Конечно же, этот «срез» общественного мнения только отчасти может показать отношение к фильмам. Для более глубокого анализа необходимо собирать данные с Twitter в течении промежуточного времени, в особенности, при появлении инфоповодов. Но, на данный момент, лидером симпатий общественного мнения являются: Форма воды. Думаю даже вечером посмотреть!
Также социальные сети позволяют анализировать и классифицировать аудиторию. Ссылка на репозитарий и словари для обучения модели определения тональности.
Конечно же, просто залипнуть в Интернет не получилось, и вспомнилась идея предсказания победителя премии «Оскар» в 2018 году, результаты которой будут известны совсем скоро 4-го марта. Данная идея была сформирована в общении с одним интересным человеком, так что спасибо ему за идею.
Возиться с формированием набора данных не хотелось, kaggle тоже не обладал таким, но хотелось сделать что-нибудь не обычное и интересное. Скорректировал задачу: определить общественное мнение по поводу победителя «Оскар»?
Но в начале надо разобраться что там в киноиндустрии твориться и кого хоть номинируют.
Что такое Oscar (версия 20!8)
90-я церемония вручения наград премии «Оскар» за заслуги в области кинематографа за 2017 год состоится 4 марта 2018 года в театре «Долби» (Голливуд, Лос-Анджелес). Комик Джимми Киммел проведёт церемонию второй год подряд. Номинанты были объявлены 23 января 2018 года (кому интересно).
Итак, все номинации мне не интересны, поэтому будем исследовать общественное внимание по номинациям: лучший фильм, лучший актер, лучшая актриса, лучший саундтрек. Обозначим данные для подготовки запросов.
Номинация лучший фильм
- Зови меня своим именем
- Тёмные времена
- Дюнкерк
- Прочь
- Леди Бёрд
- Призрачная нить
- Секретное досье
- Форма воды
- Три билборда на границе Эббинга, Миссури
Twitter как платформа изучения общественного мнения
Но для начала необходимо обеспечить доступ к API Twitter.
CONSUMER_KEY = ''
CONSUMER_SECRET = ''
OAUTH_TOKEN = ''
OAUTH_TOKEN_SECRET = ''
auth = twitter.oauth.OAuth(OAUTH_TOKEN, OAUTH_TOKEN_SECRET,
CONSUMER_KEY, CONSUMER_SECRET)
twitter_api = twitter.Twitter(auth=auth)
Т.к. набора данных у меня не было, пришлось немного подумать и сформулировать критерии оценивания общественного мнения в Twitter:
1) Необходимость поиска и обработки сообщений распространяемых в текущий момент времени (resent), что позволит определить изменения общественного мнения, тенденции. Используем для этого метод API Twitter.
tweet=twitter_api.search.tweets(q=(e1.get()), count="100")
p = json.dumps(tweet)
res2 = json.loads(p)
2) Необходимость определения потенциального распространения, т. е. в настоящее время у меня 10 подписчиков, я публикую сообщение, которое ретвитит 2 моих подписчика, у которых по 25 подписчиков. Т. о. количество распространений равно 2, а потенциально возможным равно 10+25+25=60.
i=0
while i<len(res2['statuses']):
tweet=str(i+1)+') '+str(res2['statuses'][i]['created_at'])+' '+(res2['statuses'][i]['text'])+'\n'
retweet_count.append(res2['statuses'][i]['retweet_count'])
followers_count.append(res2['statuses'][i]['user']['followers_count'])
friends_count.append(res2['statuses'][i]['user']['friends_count'])
print u'Количество ретвитов', sum(retweet_count)
print u'Возможный охват', sum(followers_count)+sum(friends_count)
3) Необходимость определения тональности сообщений, а также отношение позитива к негативу. Для этого сформируем два словаря позитивных и негативных слов. При помощи формулы Байеса (ссылка) определим условную вероятность тональности сообщения.
def format_sentence(sent):
return({word: True for word in nltk.word_tokenize(sent.decode('utf-8'))})
pos = []
with open("pos_tweets.txt") as f:
for i in f:
pos.append([format_sentence(i), 'pos'])
neg = []
with open("neg_tweets.txt") as f:
for i in f:
neg.append([format_sentence(i), 'neg'])
training = pos[:int((.8)*len(pos))] + neg[:int((.8)*len(neg))]
test = pos[int((.8)*len(pos)):] + neg[int((.8)*len(neg)):]
classifier = NaiveBayesClassifier.train(training)
classifier.show_most_informative_features()
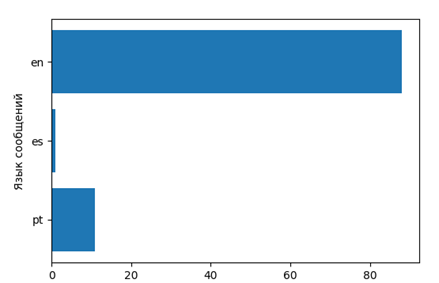
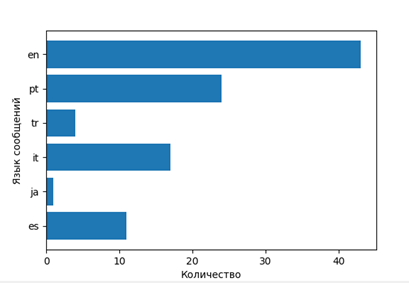
4) (Дополнительно) Определение языка сообщений. В разных странах по разному воспринимают кино. Сошлемся на менталитет.
stopwords = nltk.corpus.stopwords.words('english')
en_stop = get_stop_words('en')
stemmer = SnowballStemmer("english")
#print stopwords[:10]
total_word=[]
lang=[]
while i<len(res2['statuses']):
lang.append(res2['statuses'][i]['lang'])
w7=Label(window,text=u"АНАЛИЗ ЯЗЫКА ПУБЛИКАЦИЙ", font = "Times")
w7.place(relx=0.65, rely=0.1)
f = Figure(figsize=(6, 4))
a = f.add_subplot(111)
t = Counter(lang).keys()
y_pos = np.arange(len(t))
performance = Counter(lang).values()
error = np.random.rand(len(t))
s = Counter(lang).values()
a.barh(y_pos,s)
a.set_yticks(y_pos)
a.set_yticklabels(t)
a.invert_yaxis()
a.set_ylabel(u'Язык сообщений')
a.set_xlabel(u'Количество')
canvas = FigureCanvasTkAgg(f, master=window)
canvas.show()
canvas.get_tk_widget().place(relx=0.52, rely=0.12)#pack(side=TOP, fill=BOTH, expand=1)
canvas._tkcanvas.place(relx=0.52, rely=0.12)#pack(side=TOP, fill=BOTH, expand=1)
Вывод представлен в диаграммах
Распространение упоминаний
Отношение пользователей социальной сети Twitter к номинированным фильмам
Отобразим языковое распределение
То есть выясним, про какие фильмы говорят на каких языках (соответственно и страны).
- Зови меня своим именем

- Тёмные времена

- Дюнкерк

- Прочь
- Леди Бёрд

- Призрачная нить

- Секретное досье
- Форма воды

- Три билборда на границе Эббинга, Миссури

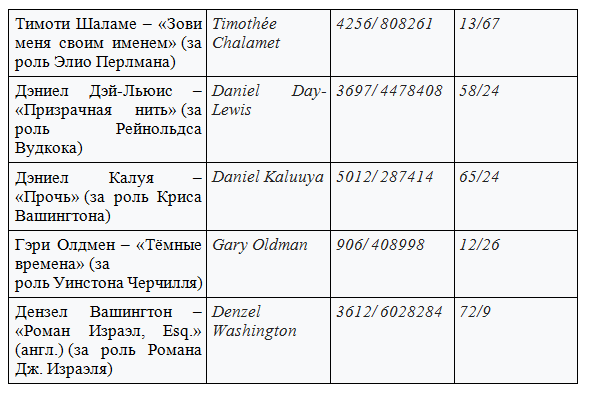
Номинация лучший актер
(представлена в табличной форме)
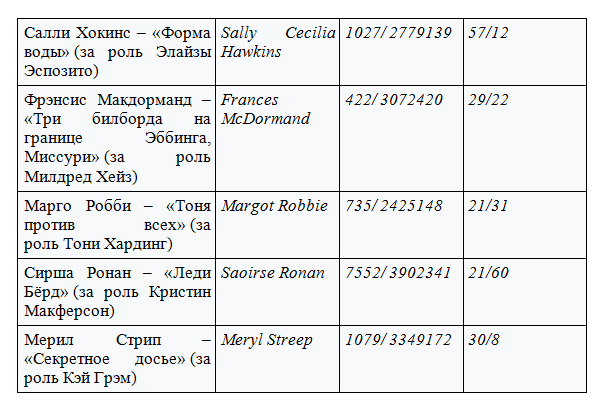
Номинация лучшая актриса
(представлена в табличной форме)
Предложения по совершенствованию
Конечно же, этот «срез» общественного мнения только отчасти может показать отношение к фильмам. Для более глубокого анализа необходимо собирать данные с Twitter в течении промежуточного времени, в особенности, при появлении инфоповодов. Но, на данный момент, лидером симпатий общественного мнения являются: Форма воды. Думаю даже вечером посмотреть!
Также социальные сети позволяют анализировать и классифицировать аудиторию. Ссылка на репозитарий и словари для обучения модели определения тональности.
