 «Закон масштабирования Деннарда и закон Мура мертвы, что теперь?» — пьеса в четырёх действиях от Дэвида Паттерсона
«Закон масштабирования Деннарда и закон Мура мертвы, что теперь?» — пьеса в четырёх действиях от Дэвида Паттерсона«Мы сжигаем мосты, по которым сюда мчимся, не имея других доказательств своего движения, кроме воспоминаний о запахе дыма и предположения, что он вызывал слёзы» — «Розенкранц и Гильденштерн мертвы», абсурдистская пьеса Тома Стоппарда
15 марта д-р Дэвид Паттерсон выступил перед аудиторией из примерно 200 наевшихся пиццы инженеров. Доктор вкратце изложил им полувековую историю конструирования компьютеров с трибуны в большом конференц-зале здания E в кампусе Texas Instruments в Санта-Кларе во время лекции IEEE под названием «50 лет компьютерной архитектуры: от центральных процессоров до DNN TPU и Open RISC-V». Это история случайных взлётов и падений, провалов и чёрных дыр, поглотивших целые архитектуры.
Паттерсон начал с 1960-х годов и новаторского проекта IBM System/360, основанного на ранних работах Мориса Уилкса по микропрограммированию 1951 года. По меркам IT это было давным-давно… Ближе к концу выступления Паттерсон показал потрясающую диаграмму. Она наглядно демонстрирует, как именно смерть закона масштабирования Деннарда, за которой следует смерть закона Мура, полностью изменили методы проектирования компьютерных систем. В конце он объяснил посмертные технологические последствия этих потрясений.
Всегда приятно наблюдать, как настоящий мастер занимается любимым ремеслом, а Паттерсон — действительно знаток компьютерной архитектуры и тех сил, которые ею управляют. Он преподавал эту тему с 1976 года и стал соавтором настоящего бестселлера «Компьютерная архитектура. Количественный подход» вместе с доктором Джоном Хеннесси. Книга недавно пережила шестое издание. Так что Паттерсон на порядок превзошёл сформулированный Малкольмом Гладуэллом рубеж в 10 000 часов, необходимых для достижения мастерства в каком-либо предмете. И это видно.
Паттерсон захватил внимание аудитории на 75 минут, разделив выступление на четыре акта. Как и в абсурдистской пьесе Тома Стоппарда «Розенкранц и Гильденштерн мертвы», кажется, ничто в этой истории — вообще ничто — не идёт как было запланировано.

Д-р Дэвид Паттерсон на конференции IEEE Santa Clara Valley Section 15 марта 2018 г. перед вручением ему премии Тьюринга от ACM за 2017 год. Источник: Стив Лейбсон
Первый акт: IBM System/360, DEC VAX и прелюдия к CISC
В 1950-х и 1960-х прошли грандиозные эксперименты с архитектурами наборов команд (ISA) для мейнфреймов (в то время кроме мейнфреймов практически не проектировалось компьютеров). Почти у каждого мейнфрейма была «новая и улучшенная» ISA. К началу 1960-х только IBM выпустила четыре линейки компьютеров: 650, 701, 702 и 1401, предназначенных для бизнеса, научных приложений и приложений реального времени. Все они — со взаимно несовместимыми архитектурами наборов команд. Четыре несовместимых ISA означали, что IBM разрабатывает и обслуживает четыре полностью независимых набора периферийных устройств (ленточные накопители, диски/барабанные накопители и принтеры), а также четыре набора инструментов для разработки программного обеспечения (ассемблеры, компиляторы, операционные системы и т.д.).
Ситуация явно не казалась устойчивой. Поэтому IBM азартно сыграла по-крупному. Она решила разработать один бинарно-совместимый набор инструкций для всех своих машин. Один аппаратно-независимый набор инструкций для всего. Главный архитектор Джин Амдал и его команда разработали архитектуру System/360, предназначенную для реализации в линейке от недорогих до дорогостоящих серий с 8-, 16-, 32- и 64-битными шинами данных.
Чтобы упростить разработку процессора к IBM System/360, команда разработчиков решила для трудно поддающейся проектированию логики управления использовать микрокод. Морис Уилкс придумал микрокод в 1951 году, и его впервые применили для компьютера EDSAC 2 в 1958 году. В некотором смысле микрокод был уже проверенной технологией к моменту запуска проекта System/360. И он снова доказал свою состоятельность.
Микрокод процессора немедленно отразился в конструкции мейнфреймов, особенно когда полупроводниковые чипы памяти оседлали закон Мура. Пожалуй, величайшим примером массивного использования микрокода стал DEC VAX, представленный в 1977 году. VAX 11/780, инновационный миникомпьютер на TTL и чипах памяти, стал эталоном производительности до конца столетия.
Инженеры DEC создавали ISA для VAX в то время, когда преобладало программирование на ассемблере, отчасти из-за инженерной инерции («мы всегда так делали»), а отчасти потому что рудиментарные высокоуровневые компиляторы в то время генерировали машинный код, который проигрывал составленному вручную лаконичному коду ассемблера. Инструкции VAX ISA поддерживали огромное количество удобных для программиста режимов адресации и включали в себя отдельные машинные инструкции, выполнявшие сложные операции, такие как вставка/удаление очереди и вычисление полинома. Инженеры VAX были в восторге от разработки аппаратного обеспечения, облегчавшего жизнь программистов. Микрокод позволил легко добавлять новые инструкции к ISA — и 99-разрядные микропрограммное управление VAX раздулось до 4096 слов.
Этот фокус по постоянному расширению количества инструкций, чтобы облегчить жизнь программиста на ассемблере, оказался реальным конкурентным преимуществом VAX от DEC. Программистам нравились компьютеры, которые облегчают их работу. Для многих компьютерных историков VAX 11/780 знаменует рождение процессорной архитектуры CISC (с полным набором команд).
Второй акт: случайные успехи и большие неудачи
Миникомпьютер DEC VAX 11/780 достиг пика популярности, когда начался бум микропроцессоров. Почти все первые микропроцессоры были машинами CISC, потому что облегчение нагрузки на программиста оставалось конкурентным преимуществом даже когда компьютер сжался до одной микросхемы. Гордону Муру из Intel, который придумал закон Мура ещё в компании Fairchild, поручили разработать следующую ISA на замену случайно ставшей популярной ISA для 8-битного Intel 8080/8085 (и Z80). Взяв одну часть от чрезвычайно успешного проекта IBM System/360 (одна ISA для управления всем), а другую — от линейки CISC-миникомпьютеров VAX от DEC, Гордон Мур тоже постарался разработать универсальную архитектуру набора инструкций — единую Intel ISA, которая будет жить до скончания веков.
В то время 8-разрядные микропроцессоры работали в 16-разрядном адресном пространстве, а у новой окончательной архитектуры набора команд Intel ISA было 32-разрядное адресное пространство и встроенная защита памяти. Она поддерживала инструкции любой длины, которые начинаются с одного бита. И она программировалась на новейшем и величайшем высокоуровневом языке: Ада.
Эта ISA должен был стать частью процессора Intel iAPX 432, и это был очень большой, очень амбициозный проект для Intel.
Если изучить историю «революционного» iAPX 432, то вы обнаружите, что она завершилась жесточайшим провалом. Аппаратное обеспечение, необходимое для архитектуры IAPX 432, вышло чрезвычайно сложным. В результате микросхему удалось выпустить с большим опозданием. (Она требовала 6-летнего цикла разработки и появилась лишь в 1981 году.) И когда микропроцессор наконец появился, то оказался исключительно медленным.
Мур в самом начале проекта понял, что разработка iAPX 432 займёт много времени, поэтому в 1976 году для подстраховки запустил параллельный проект по разработке гораздо менее амбициозного 16-битного микропроцессора, основанного на расширении успешной 8-битной ISA от 8080, с совместимостью на уровне исходного кода. У разработчиков был всего год, чтобы выпустить чип, поэтому им выделили всего три недели на разработку ISA. Результатом стал процессор 8086 и одна универсальная ISA, по крайней мере, на ближайшие несколько десятилетий.
Была только проблема: по описанию собственных инсайдеров Intel, микропроцессор 8086 вышел очень слабеньким.
Производительность Intel 8086 отставала от производительности ближайших конкурентов: элегантного Motorola 68000 (32-битный процессор в 16-битном одеянии) и 16-битного Zilog Z8000. Несмотря на слабую производительность, IBM выбрала Intel 8086 для своего проекта IBM PC, потому что инженеры Intel в Израиле разработали вариант 8088 — это 8086 с 8-битной шиной. Микропроцессор 8088 работал немного медленнее, чем 8086, но его 8-битная шина казалась более совместимой с существующими периферийными чипами и уменьшила затраты на производство материнской платы ПК.
По прогнозам IBM, планировалось продать около 250 000 компьютеров IBM PC. Вместо этого продажи превысили 100 миллионов, а Intel 8088 стал случайным, но абсолютным хитом.
Третий акт: рождение RISC, VLIW и потопление «Итаника»
В 1974 году, сразу после появления первых коммерческих микропроцессоров, Джон Кок из IBM попытался разработать управляющий процессор для электронного телефонного коммутатора. Он подсчитал, что управляющему процессору необходимо выполнить около 10 миллионов инструкций в секунду (MIPS), чтобы соответствовать требованиям приложения. Микропроцессоры того времени были на порядок медленнее, и даже мэйнфрейм IBM System/370 не подходил для этой задачи: он выдавал около 2 MIPS.
Так команда Кока в рамках проекта 801 разработала радикально модернизированную архитектуру процессора с конвейерной шиной и быстрой схемой управления без микрокода — такое стало возможным за счёт уменьшения числа инструкций до минимума, чтобы упростить управление. (Машину назвали IBM 801, потому что её разработали в здании 801 Исследовательского центра IBM им. Томаса Дж. Уотсона). В проекте IBM 801 впервые реализовали архитектуру RISC (уменьшенный набор инструкций).
Прототип компьютера 801 был построен на мелких чипах Motorola MECL 10K, которые все вместе выдавали невиданную производительность 15 MIPS и легко вписывались в технические требования. Поскольку сокращённый набор инструкций менее удобен для программиста, чем набор инструкций CISC, команде Кока пришлось разработать оптимизирующие компиляторы. Они взяли на себя дополнительное бремя создания эффективного машинного кода из сложных алгоритмов, написанных на языках высокого уровня.
После этого Кок стал известен как «отец RISC». IBM так никогда и не выпустила телефонный коммутатор, но процессор 801 эволюционировал и в конечном итоге стал основой для большой линейки RISC-процессоров IBM, широко используемых в её мейнфреймах и серверах.
Позже несколько инженеров в DEC обнаружили, что около 20% инструкций CISC у VAX занимают около 80% микрокода, но составляют всего 0,2% общего времени выполнения программы. Такой расход! Учитывая результаты проекта IBM 801 и выводы инженеров DEC, можно было предположить, что архитектура CISC не такая уж замечательная.
Предположение подтвердилось.
В 1984 году Стэнфордский профессор Джон Хеннесси опубликовал в журнале IEEE Transactions on Computers знаковую статью под названием «Процессорная архитектура СБИС», где доказал превосходство архитектур и ISA на RISC для реализаций процессора СБИС (VLSI). Паттерсон резюмировал доказательство Хеннесси в своем выступлении: RISC по определению быстрее, потому что машинам CISC требуется в 6 раз больше тактов на инструкцию, чем машинам RISC. Даже хотя машине CISC требуется выполнить в два раза меньше инструкций для той же задачи, компьютер RISC выходит по сути втрое быстрее CISC.
Поэтому процессоры x86 в современных компьютерах только с виду выполняют программно-совместимые инструкции CISC, но как только эти инструкции из внешнего ОЗУ попадают в процессор, они тут же измельчаются/шинкуются на кусочки более простых «микрокоманд» (так Intel называет инструкции RISC), которые затем составляются в очереди и выполняются в нескольких RISC-конвейерах. Сегодняшние процессоры x86 стали быстрее, превратившись в машины RISC.
Несколько разработчиков процессорной архитектуры решили разработать ISA, которая станет намного лучше, чем RISC или CISC. С помощью очень длинных машинных команд (VLIW) стало возможным упаковать множество параллельных операций в одну огромную машинную инструкцию. Архитекторы окрестили этот вариант ISA как VLIW (Very Long Instruction Word). Машины VLIW заимствуют один из принципов работы RISC, возлагая на компилятор работу по планировке и упаковке в машинный код VLIW-инструкций, сгенерированных из высокоуровневого исходного кода.
Intel решила, что архитектура VLIW выглядит очень привлекательно — и начала разработку процессора VLIW, который станет её заявкой на вхождение в неминуемо наступающий мир 64-битных процессоров. Свою VLIW ISA компания Intel назвала IA-64. Как обычно, Intel разработала собственную номенклатуру и свои названия для привычных терминов. На интел-жаргоне VLIW превратилась в EPIC (Explicitly Parallel Instruction Computing). Архитектура EPIC не должна быть основана на наборе инструкций x86, отчасти для предотвращения копирования со стороны AMD.
Позже инженеры HP PA-RISC тоже решили, что у RISC потенциал развития почти исчерпан — и тоже заразились болезнью VLIW. В 1994 году компания HP объединила усилия с Intel для разработки совместной 64-битной архитектуры VLIW/EPIC. Результат назовут Itanium. Объявили цель выпустить первый процессор Itanium в 1998 году.
Однако вскоре стало ясно, что будет трудно разрабатывать процессоры и компиляторы VLIW. Intel не объявляла название Itanium до 1999 года (острословы в Usenet сразу же окрестили процессор «Итаником»), а первый рабочий процессор выпустили только в 2001 году. «Итаник» в итоге благополучно утонул в 2017 году, когда Intel объявила о завершении работ над IA-64. (См. «Intel потопила Itanium: возможно, самый дорогой в мире неудачный проект процессора»).
Архитектура EPIC тоже стала эпичным провалом — микропроцессорной версией Джа-Джа Бинкса из «Звёздных войн». Хотя в своё время казалась хорошей идеей.
Процессоры Itanium, EPIC и VLIW умерли по нескольким причинам, говорит Паттерсон:
- Непредсказуемые ветвления, усложняющие планирование и упаковку параллельных операций в командные слова VLIW.
- Непредсказуемые промахи кэша замедляли выполнение и приводили к переменным задержкам выполнения.
- Наборы команд VLIW раздували объём кода.
- Оказалось слишком сложно создать хорошие оптимизирующие компиляторы для машин VLIW.
Пожалуй, самый известный в мире специалист по компьютерным алгоритмам Дональд Кнут заметил: «Подход Itanium… казался таким великолепным — пока не выяснилось, что желанные компиляторы по сути невозможно написать».
Кажется, компиляторы лучше справляются с простыми архитектурами типа RISC.
Из архитектур VLIW не получились универсальные микропроцессоры. Но позже они всё-таки нашли своё призвание, что переносит нас в четвёртый акт пьесы.
Четвёртый акт: закон масштабирования Деннарда и закон Мура мертвы, но DSA, TPU, и Open RISC-V живы
В пьесе Тома Стоппарда «Розенкранц и Гильденштерн мертвы» два незначительных персонажа, выхваченных из шекспировского «Гамлета», в конце последнего акта наконец-то понимают, что в течение всей пьесы были мертвы. В заключительном акте истории процессоров от Паттерсона умерли закон масштабирования Деннарда и закон Мура. Вот рисунок из последнего издания книги Хеннесси и Паттерсона, который графически показывает всю историю:
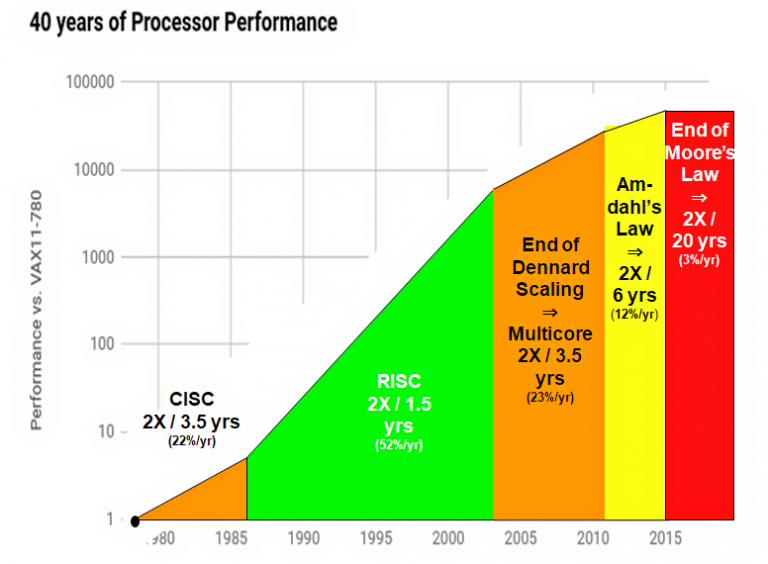
Источник: Джон Хеннесси и Дэвид Паттерсон, «Компьютерная архитектура. Количественный подход», 6-e изд. 2018
На графике видно, что микропроцессоры RISC обеспечили почти двадцать лет быстрого прироста производительности с 1986 по 2004 год, поскольку они эволюционировали по закону Мура (вдвое больше транзисторов на каждом новом витке техпроцесса) и закону масштабирования Деннарда (удвоение быстродействия при двукратном снижении энергопотребления на транзистор на каждом новом ветке техпроцесса). Затем закон масштабирования Деннарда умер — и отдельные процессоры перестали ускоряться. Потребление энергии на транзистор также перестало уменьшаться вдвое на каждом этапе.
Промышленность компенсировала это, полагаясь исключительно на закон Мура по удвоению количества транзисторов — и быстро увеличивала количество процессоров на чипе, вступив в многоядерную эру. Интервал удвоения производительности вырос с 1,5 до 3,5 лет в течение этой эпохи, длившейся менее десяти лет, прежде чем вступил в силу закон Амдала (перефразированный как «в каждом приложении эксплуатируемый параллелизм ограничен»). Немногие приложения способны полностью загрузить десятки процессоров.
Тогда скончался и закон Мура.
По словам Паттерсона, результат такой, что с 2015 года рост производительности процессоров упал до ничтожных 3% в год. Удвоение по закону Мура теперь происходит на за 1,5 и даже не за 3,5 года. Теперь это двадцать лет.
Конец игры? «Нет», — говорит Паттерсон. В архитектуре процессоров можно попробовать ещё некоторые интересные вещи.
Один пример: специализированные архитектуры (DSA, Domain Specific Architectures) — специально разработанные процессоры, которые пытаются ускорить выполнение небольшого количества задач для конкретных приложений. Архитектуры VLIW не подошли для универсальных процессоров, но вполне имеют смысл для приложений DSP с гораздо меньшим числом ветвлений. Другой пример: Google TPU (Tensor Processing Unit), ускоряющий выполнение DNN (Deep Neural Network, глубокие нейросети) с помощью блока из 65 536 юнитов умножения-сложения (MAC) на одной микросхеме.
Оказывается, матричные вычисления с пониженной точностью — ключ к реализации действительно быстрых DNN. 65 536 восьмибитных блоков MAC в Google TPU работают на 700 МГц и выдают производительность 92 TOPS (тераопераций в секунду). Это примерно в 30 раз быстрее, чем серверный CPU и в 15 раз быстрее, чем GPU. Умножьте на сокращённое вдвое энергопотребление в 28-нанометровом TPU по сравнению с серверным CPU или GPU — и получите преимущество по энергопотреблению/мощности в 60 и 30 раз, соответственно.
По странному стечению обстоятельств, профессор Дэвид Паттерсон недавно уволился из Калифорнийского университета в Беркли после преподавания и работы там в течение 40 лет. Теперь он занимает должность «заслуженного инженера» в Google по проекту разработки TPU.
Еще одна интересная вещь — создание архитектур ISA с открытым исходным кодом, говорит Паттерсон. Предыдущие такие попытки, в том числе OpenRISC и OpenSPARC, не взлетели, но Паттерсон рассказал о совершенно новой ISA с открытым исходным кодом — это RISC-V, которую он помогал разрабатывать в Беркли. Посмотрите на SoC, говорит Паттерсон, и вы увидите много процессоров с разными ISA. «Почему?», — задаёт он вопрос.
Зачем нам универсальная ISA, ещё одна ISA для обработки изображений, а также ISA для видеообработки, для аудиообработки и DSP ISA на одном кристалле? Почему бы не сделать только одну или несколько простых ISA (и один набор инструментов разработки программного обеспечения), которые можно многократно использовать для конкретных приложений? Почему бы не сделать ISA с открытым исходным кодом, чтобы каждый мог использовать эту архитектуру безвозмездно и улучшать её? Единственный ответом Паттерсона на эти вопросы — RISC-V ISA.
Недавно сформирован Фонд RISC-V, похожий по концепции на успешный Linux Foundation. В него вошли уже более 100 компаний, и он взял на себя работу по стандартизации RISC-V ISA. Миссия Фонда — способствовать внедрению RISC-V ISA и её будущему развитию. Так совпало, что «отошедший от дел» доктор Дэвид Паттерсон занимает должность заместителя председателя Фонда RISC-V.
Как и Розенкранц и Гильденштерн, закон масштабирования Деннарда и закон Мура оказываются мёртвыми в конце исторической пьесы Паттерсона, но интересные события в компьютерной архитектуре только начинаются.
«Нет ничего более неубедительного, чем неубедительная смерть», — так говорилось в пьесе.
Эпилог: 21 марта, всего через неделю после выступления в IEEE, Ассоциация вычислительной техники (ACM) признала вклад Паттерсона и Хеннесси в компьютерную архитектуру, присудив им премию Тьюринга ACM 2017 года «за новаторский систематический, вычислительный подход к проектированию и оценке компьютерных архитектур, оказавший длительное влияние на микропроцессорную промышленность».
