
В предыдущей статье 10 Docker anti-patterns мы рассказали о популярных ошибках при создании образов контейнеров. Однако создание образов для вашего приложения - это только половина дела. Вам нужен способ развёртывания этих контейнеров в производственной среде. Использование кластеров Kubernetes для решения этой задачи уже стало стандартом.
Представляем аналогичное руководство для Kubernetes. Теперь вы сможете составить полную картину того, как создать образ контейнера и как правильно его развернуть (при этом избежав некоторых распространенных ошибок).
Обратите внимание, что это руководство посвящено развёртыванию приложений в Kubernetes, но не затрагивает настройку самих кластеров Kubernetes. Предполагается, что кластер Kubernetes уже развёрнут, правильно настроен и вы просто хотите развернуть в нём ваше приложение.
В этой статье не просто перечислены известные антипаттерны деплоя в Kubernetes, но и предлагаются соответствующие решения. Вы можете проверить ваши процессы развёртывания и исправить существующие проблемы без поиска дополнительной информации.
Список антипаттернов, которые мы рассмотрим:
Использование образов с тегом latest
Сохранение конфигурации внутри образов
Использование приложением компонентов Kubernetes без необходимости
Использование для деплоя приложений инструментов для развёртывания инфраструктуры
Изменение конфигурации вручную
Использование кubectl в качестве инструмента отладки
Непонимание сетевых концепций Kubernetes
Использование неизменяемых тестовых окружений вместо динамических сред
Смешивание кластеров Production и Non-Production
Развёртывание приложений без Limits
Неправильное использование Health Probes
Не используете Helm
Не собираете метрики приложений, позволяющие оценить их работу
Отсутствие единого подхода к хранению конфиденциальных данных
Попытка перенести все ваши приложения в Kubernetes
Желательно ознакомится с упомянутым руководством 10 Docker anti-patterns, поскольку некоторые из указанных выше антипаттернов будут ссылаться на него.
1. Использовать образы с тегом latest
Если вы уже имеете опыт создания собственных образов, эта рекомендация вас скорее всего не удивит. Создание образов с тегом "latest" в большинстве случаев является антипаттерном, поскольку "latest" - это просто имя тега (может быть присвоено любому образу в репозитории по решению владельца). Несмотря на первое впечатление, тег "latest" не означает "последний созданный". Это всего лишь тег по умолчанию, который используется, если вы указываете имя образа без тега.
Использование тега "latest" в Deployment ещё хуже, потому что в результате вы не будете знать из какого образа были запущены контейнеры.
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-bad-deployment
spec:
template:
metadata:
labels:
app: my-badly-deployed-app
spec:
containers:
- name: dont-do-this
image: docker.io/myusername/my-app:latestТэги образов могут меняться, поэтому тэг "latest", на самом деле, не несет в себе никакой полезной информации. Этот образ может быть создан 3 минуты назад, а может быть 3 месяца назад. Вам придётся проанализировать логи вашей системы CI или сохранить образ локально и изучить его содержимое, чтобы понять какую версию приложения он содержит.
Использование политики always pull policy вместе с тэгом "latest" может привести к непредсказуемому результату и даже быть опасным. Предположим, что ваш Pod работает не корректно и Kubernetes принимает решение пересоздать его на другом узле кластера (именно за это мы любим Kubernetes).
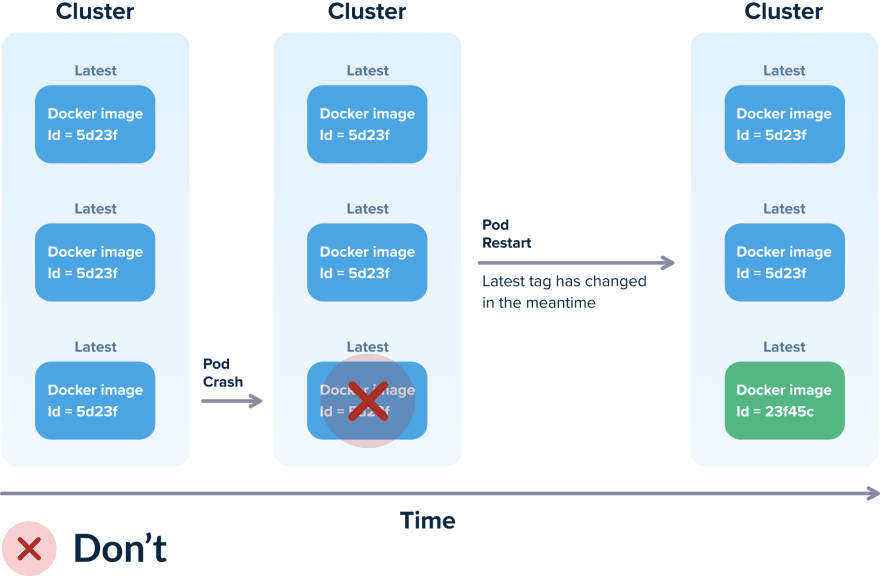
Kubernetes спланирует Pod, и, если pull policy позволяет, из репозитория будет загружен образ с тэгом "latest". Если за это время образ с тэгом "latest" в репозитории изменился, в новом Pod будет образ, который отличается от образов в остальных Pod этого Deployment. В большинстве случаев это не то, что вам нужно.
При такой стратегии развёртывания единственным решением этой проблемы будет пересоздание остальных Pod вручную, после этого они запустятся с актуальной версий образа.
Если ваши процессы развёртывания каким-либо образом зависят от использования тегов "latest", вы сидите на бомбе замедленного действия.
Чтобы избежать этой проблемы необходимо выбрать стратегию назначения тегов и придерживаться её для всех приложений.
Рекомендации по выбору стратегии:
Использование тегов с версией приложения (например, docker.io/myusername/my-app:v1.0.1).
Использование тегов с Git hash (например, docker.io/myusername/my-app:acef3e). Это несложно реализовать, но по Git hash труднее определить версию приложения.
Тэг так же может содержать номер build, дату или время build. Но такой подход применяется довольно редко.
Важно помнить, что теги образов не должные изменяться. Образ, помеченный как v2.0.5, должен создаваться только один раз и перемещаться из одной среды в другую.
2. Сохранение конфигурации внутри образов
Хранить конфигурацию внутри образов - это ещё один антипаттерн, связанный со сборкой образов. Образы должны создаваться таким образом, чтобы оставаться независимыми от среды, в которой вы их разворачиваете.
Этот подход хорошо себя зарекомендовал ещё до появления контейнеров. Позже он был включен в концепцию 12-factor app. Следуя этому подходу образы контейнеров должны создаваться только один раз, а затем перемещаться из одной среды в другую. Для этого образ не должен содержать настроек, связанных с конкретным окружением.
Если в вашем образе:
есть жёстко заданные IP-адреса
пароли или конфиденциальные данные
URL-адреса других сервисов
тег содержит “dev”, “qa”, “production”
...значит вы попали в ловушку создания образов, зависящих от среды.
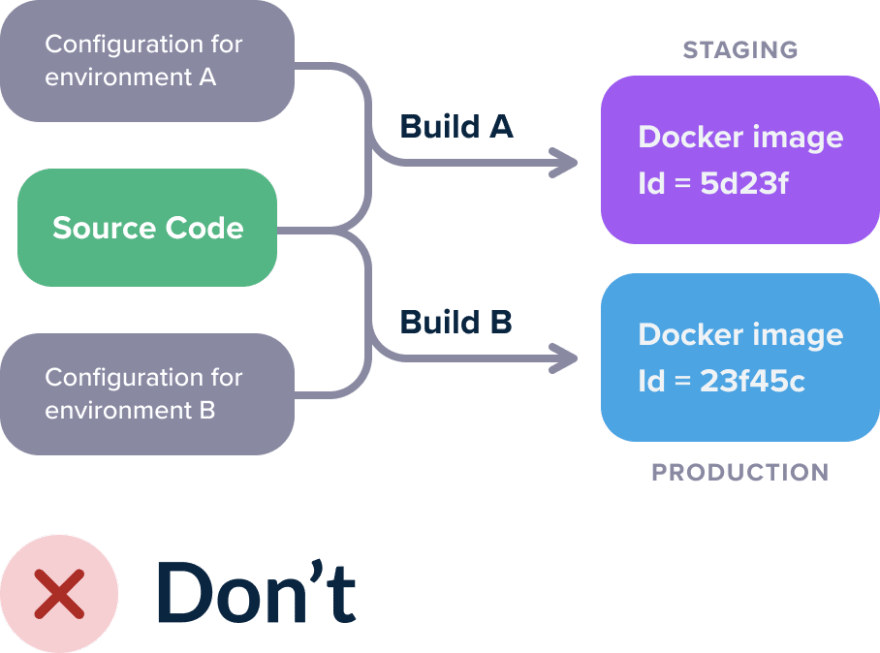
Это означает, что для каждого окружения вам придётся собирать образ заново. Так же может возникнуть ситуация, при которой вы развернули в production компоненты, которые не были протестированы ранее.
Решение этой проблемы очень простое. Создавайте "generic" образы, которые не содержат никаких данных о конкретном окружении. Для конфигурирования приложений, запущенных из таких образов, используйте сторонние инструменты Kubernetes Configmaps/Secrets, Hashicorp Consul, Apache Zookeeper и др.
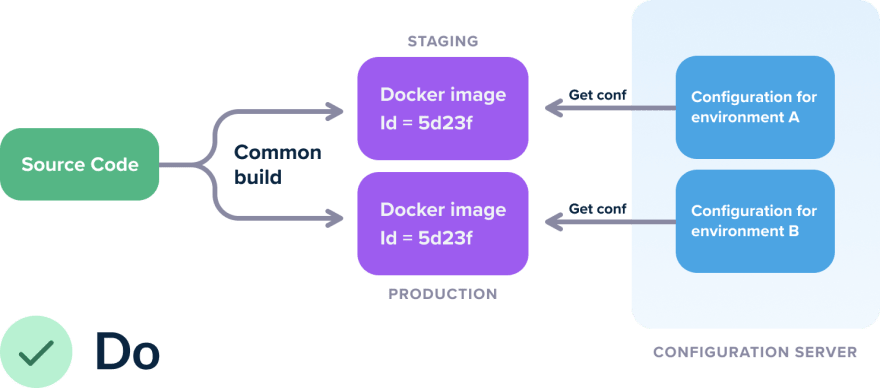
Теперь у вас есть образ, который вы можете развернуть в любом из ваших окружений. Если вам нужно будет изменить конфигурацию приложения, то пересобирать образ больше не придется.
3. Использование приложением компонентов Kubernetes без необходимости
Мы разобрались почему не стоит хранить конфигурацию внутри образов и почему важно, чтобы образ был независимым от окружения.
На самом деле приложение в контейнере также не должно знать, что оно работает внутри кластера Kubernetes. Если вы не разрабатываете приложение для обслуживания кластера, оно не должно обращаться к Kubernetes API или другие службы Kubernetes напрямую.
Этот проблема встречается довольно часто, когда команды только начинают работать с Kubernetes.
Рассмотрим несколько подобных ситуаций:
ожидать определенного именования сервисов или предполагать наличие определенных открытых портов
получать информацию из Kubernetes labels и annotations
запрашивать из Pod информацию о его конфигурации (например, его ip адрес)
потребность в init или sidecar контейнерах для правильной работы
обращаться к сервисам, установленным в Kubernetes через API (например, использовать Vault API для получение Secret из HashiCorp Vault, установленного в кластере Kubernetes)
читать данные из локального kubeconfig
обращаться к Kubernetes API из приложения напрямую
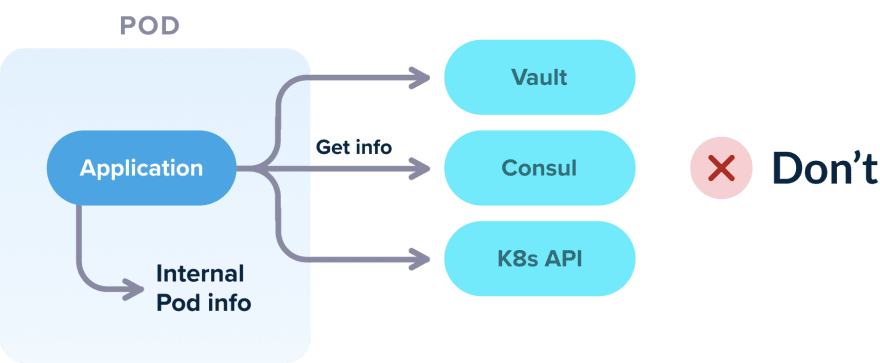
Конечно, для некоторых приложений, работающих в Kubernetes (скажем, вы создаете собственный оператор), действительно нужен прямой доступ к сервисам Kubernetes. Но остальные 99% приложений должны полностью игнорировать тот факт, что они работают внутри Kubernetes.

Лакмусовая бумажка, которая показывает, привязано ли ваше приложение к Kubernetes или нет, - это возможность запускать его с помощью других инструментов, таких как Docker Compose. Если создание docker-compose файла для вашего приложения не вызывает сложностей, это означает, что вы скорее всего следуете принципам 12-факторного приложения, и оно может быть установлено в любом кластере без необходимости специальных настроек.
Если вы разработчик, работающий над приложением, которое будет развернуто в Kubernetes, может возникнуть желание выполнить локальное тестирование в Kubernetes. Сегодня существует несколько решений для локального развертывания Kubernetes (minikube, microk8s, KinND и другие).
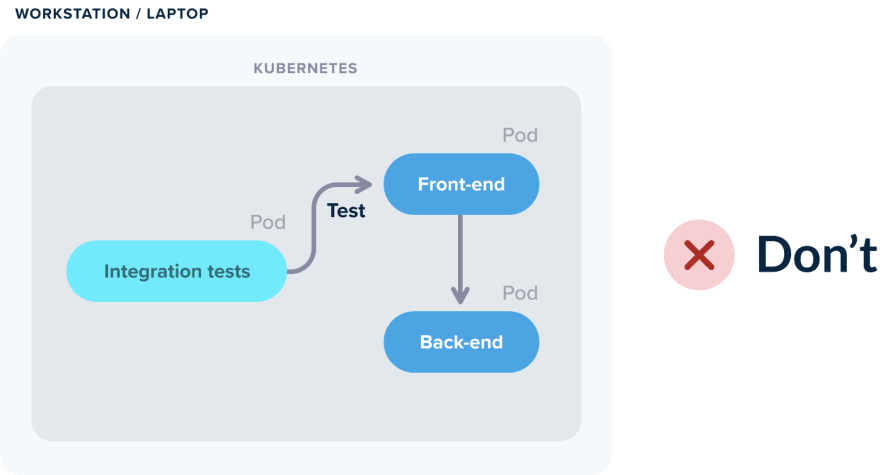
На самом деле, если ваше приложение правильно спроектировано, вам не понадобится Kubernetes для локального запуска интеграционных тестов. Вы можете запускать тесты в Docker или Docker Compose. При этом некоторые зависимости могут работать во внешнем кластере Kubernetes.

В качестве альтернативы вы также можете использовать любое из специализированных решений для локальной разработки Kubernetes, например Okteto, garden.io или tilt.dev.
4. Использование для развёртывания приложений инструментов для развёртывания инфраструктуры
В последние годы распространение Terraform (и подобных инструментов, таких как Pulumi) привело к распространению подхода «Infrastructure as Code», который позволяет командам описывать инфраструктуру в виде кода.
Но тот факт, что вы так же можете развернуть инфраструктуру в pipeline не означает, что развёртывание инфраструктуры и приложений должно происходить одновременно.
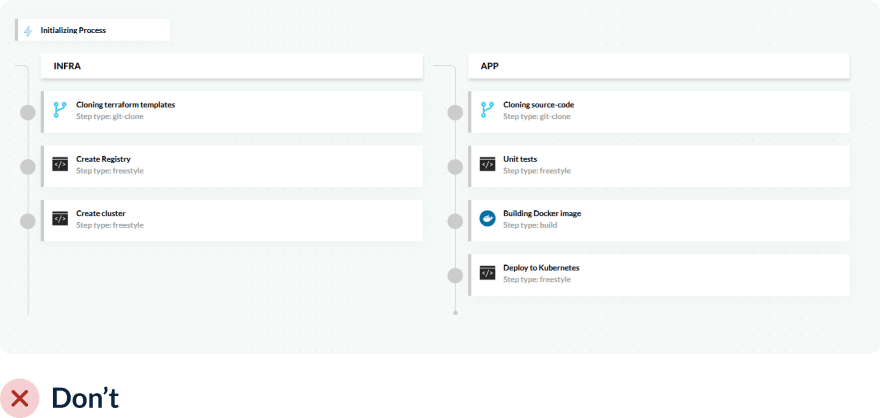
Многие команды, создают единый конвейер, который одновременно создает инфраструктуру (например, кластер Kubernetes) и развёртывает в нём приложения.
Хотя это прекрасно работает в теории (поскольку означает, что вы начинаете с нуля при каждом развёртывании), это довольно расточительно с точки зрения ресурсов и времени.
В большинстве случаев код приложения будет меняться намного быстрее, чем инфраструктура. Трудно сделать обобщение для всех компаний, но в большинстве случаев скорость изменения приложений может быть на порядок выше, чем скорость изменения инфраструктуры.
Если у вас есть один pipeline, который делает и то, и другое, вы разрушаете / создаёте инфраструктуру, которая не менялась, просто потому, что вы хотите развернуть новую версию приложения.
Pipeline, который развёртывает всё вместе (инфра / приложение), может занять 30 минут, в то время как pipeline, развёртывающий только приложение, может занять всего 5 минут. Вы тратите 25 дополнительных минут на каждое развёртывание без каких-либо причин, даже если инфраструктура не изменилась.

Второй недостаток заключается в том, что в случае возникновения проблем с этим pipeline непонятно, кто должен их устранять. Если я разработчик и хочу развернуть свое приложение в Kubernetes, меня не интересуют ошибки Terraform, виртуальные сети или тома хранения.
Вся суть DevOps - дать разработчикам инструменты самообслуживания. Принуждение их заниматься инфраструктурой, когда в этом нет необходимости, - это шаг назад.
Правильным решением, конечно же, является разделение деплоя приложений и инфраструктуры по отдельным pipeline. Pipeine инфраструктуры будет запускаться реже, чем pipeline приложения, что ускорит развёртывание приложений (и сократит время выполнения).
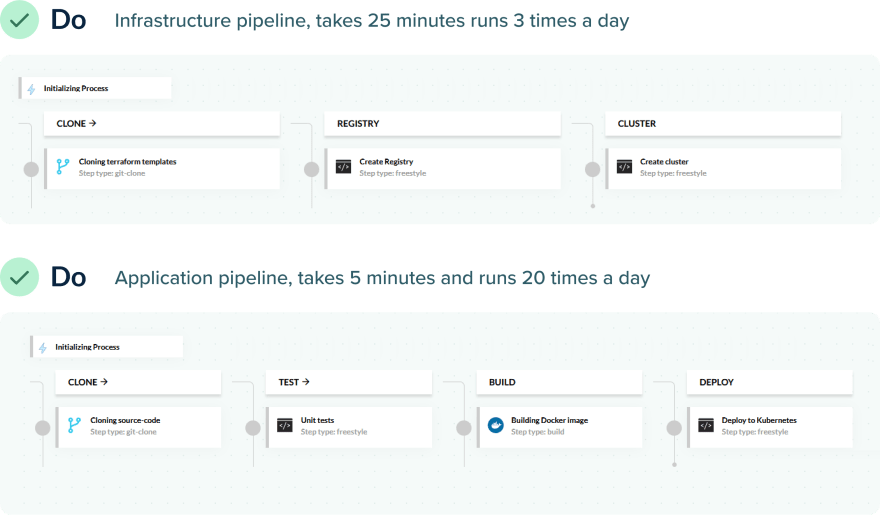
Разработчики также будут знать, что, когда pipeline для деплоя приложения выходит из строя, им не нужно разбираться с ошибками инфраструктуры или заботиться о том, как был создан кластер Kubernetes. Администраторы могут настраивать pipeline, разворачивающий инфраструктуру, не затрагивая разработчиков. Каждый может работать независимо.
Иногда мы видим этот антипаттерн (смешивание инфраструктуры с приложением), когда компании считают, что это единственный путь вперед, поскольку приложению требуется что-то, предоставляемое конвейерами инфраструктуры.
Классический пример - создание чего-либо с помощью Terraform, а затем передача вывода развёртывания (например, IP-адреса) остальной части конвейера в качестве входных данных для кода приложения. Если у вас есть это ограничение, это означает, что вы страдаете от предыдущего антипаттерна (привязка приложения инфраструктуре), и вам необходимо от неё избавиться.
5. Изменение конфигурации вручную
Дрейф конфигурации - хорошо известная проблема, существовавшая ещё до появления Kubernetes. Это происходит, когда две или более среды должны быть одинаковыми, но после определенных случайных развёртываний или изменений они перестают иметь одинаковую конфигурацию.
Со временем проблема становится ещё более критичной и может привести к серьёзным проблемам.
Kubernetes также может страдать от этой проблемы. Команда kubectl очень мощная и поставляется со встроенными командами apply/edit/patch, которые могут изменять ресурсы в работающем кластере.
К сожалению, этим методом часто злоупотребляют как ковбойские разработчики, так и администраторы-ниндзя. Когда в кластере происходят подобные изменения, они больше нигде не фиксируются.
Одна из наиболее частых причин неудачных развёртываний - это конфигурация среды. Например деплой в production может закончиться неудачей (даже если подобных проблем не было на stage), потому что конфигурация двух сред больше не совпадает.

Попаcться в эту ловушку очень легко. Исправления, «костыли» и другие сомнительные уловки всегда являются основными причинами подобных изменений.
Kubectl никогда не следует использовать для деплоя вручную. В соответствии с подходом GitOps вся конфигурация должна храниться в системе контроля версий.
Если все ваши развертывания происходят через Git commit:
У вас есть полная история того, что произошло в вашем кластере, в виде истории Git коммитов.
Вы точно знаете, что содержится в каждом кластере в любой момент времени и чем отличаются среды между собой.
Вы можете легко воссоздать или клонировать среду с нуля.
Вы можете откатить инфраструктуры на одно из предшествующих состояний.
Что наиболее важно, в случае сбоя развёртывания вы можете очень быстро определить, какое из последних изменений на него повлияло.
