 Некоторое время назад на хабре проскакивал топик про «континуации» от ХабраЮзера qmax. Он был весьма впечатлен идеей, а вот подробно рассказать не вышло. И вот недавно один из разработчиков Seaside, Джулиан Фитзелл написал потрясающую по своей доходчивости статью. С его разрешения я сделал ее перевод и хотел бы поделиться с хабрасообществом.
Некоторое время назад на хабре проскакивал топик про «континуации» от ХабраЮзера qmax. Он был весьма впечатлен идеей, а вот подробно рассказать не вышло. И вот недавно один из разработчиков Seaside, Джулиан Фитзелл написал потрясающую по своей доходчивости статью. С его разрешения я сделал ее перевод и хотел бы поделиться с хабрасообществом.Сразу хотелось бы сказать о терминологии. В качестве перевода слова continuation я использую наиболее близкое по смыслу «продолжение». Общая же терминология статьи для неискушенного в Smalltalk разработчика может показаться непривычной. Так, вместо стека вызовов используется «цепь контекстов», а вместо потока — «процесс». Если у вас останутся вопросы после прочтения — смело задавайте их в комментариях. Спасибо.
Это второй пост в серии обзоров предстоящего релиза Seaside. Взгляните на первый пост, посвященный обработке исключений.
Продолжения в Seaside
Seaside часто упоминают как «основанный на продолжениях» web фреймворк, и действительно, на заре развития продолжения использовались повсеместно, изображая магию. Seaside 2.8 до сих пор использует продолжения первого класса (что это значит я объясню чуть позже) в трех разных случаях:
- чтобы прекратить обработку запроса (request) и немедленно вернуть ответ (response);
- чтобы прервать выполнение кода и продолжить его после того, как пользователь кликнет на ссылке или последует по редиректу (например, чтобы установить cookies для пользователя);
- чтобы реализовать для компонентов схему call/answer.
Тем не менее, предстоящий релиз Seaside полностью устранит использование продолжений в ядре фреймворка. Первый из перечисленных случаев будет заново реализован с использованием исключений, а код для второго и третьего случая будет перемещен в необязательный, но доступный для установки пакет. Это означает, что вы сможете установить Seaside без использования продолжений вовсе. Этот факт должен улучшить переносимость между диалектами Smalltalk, которые на данный момент не поддерживают продолжения.
В тоже время, мы также заменим продолжения первого класса частичными продолжениями, и эта статья должна дать представление о том, что это значит, и для чего мы делаем эти изменения. Все это может сбить столку (особенно во время отладки!), так что не переживайте, а дайте информации улечься, а затем вернитесь к ней и перечитайте. Я упростил несколько вещей, пожертвовав деталями, в надежде сделать данную тему более понятной для людей, которых смущает сама идея работы продолжений. Я принимаю любые отзывы о том, как мне удалось соблюсти этот баланс.
Что такое продолжения?
Прежде всего, когда я упоминаю продолжения, я подразумеваю продолжения первого класса. Seaside также использует метод передачи продолжения для реализации цикла рендеринга (это параметр _k, который вы видите в URL'ах, генерируемых Seaside). Это близко связанное понятие, но не то о чем я буду рассказывать далее.
Продолжения часто определяют как «остаточные вычисления», но я считаю это немного нечетким определением, если вы еще не понимаете сути этого явления. Для меня самым простым объяснением является то, что продолжение сохраняет «снимок» запущенного процесса, который можно продолжить позже. Вы вызываете метод, который вызывает другой метод, который вызывает другой метод и так далее, а затем вы делаете «снимок» этой цепочки вызовов и сохраняете объект снимка где-либо. В будущем вы можете в любой момент восстановить его, отказавшись от кода, выполняющегося в текущий момент, и выполнение вашей программы будет продолжено с того самого места, с того самого метода, зафиксированного в «снимке». Это и есть продолжения первого класса.
Пользователям Smalltalk проще понять это, потому что когда вы сохраняете Smalltalk образ и открываете его позже, то видите абсолютно ту же картину, что и при сохранении. Вы можете открыть сохраненный образ столько раз, сколько хотите, и каждый раз будете возвращаться к одному и тому же состоянию. Если вы сохраните образ в новый файл, то сможете вернуться к старому. Продолжения, в принципе, делают тоже самое, только вместо всего образа они сохраняют единственный процесс.
Реализация «Call and Answer»
Одна из самых эффектных особенностей Seaside — это возможность писать многоступенчатые задачи, которые требуют участия пользователя, в обычном итеративном стиле:
answer := self confirm: 'Do it?'.
answer ifTrue: [ self doItAlready ]
Это как раз то, что становится проще при использовании продолжений: мы хотим остановиться в середине метода и попросить пользователя ввести информацию. Если он ответит, то мы хотим продолжить выполнение с того места где остановились. А теперь давайте посмотрим, как продолжения первого класса могут быть использованы для достижения этого.
Как читать диаграммы
Небольшое отступление. Следующие ниже диаграммы изображают цепочки контекстов (хотя они достаточно абстрактны, что бы называть их стеком фреймов). Каждый раз, когда вы вызываете метод или выполняете блок, создается новый контекст на «вершине» цепочки. Каждый раз, когда метод возвращает значение или блок завершается, контекст с «вершины» удаляется. Контекст метода знает какой метод вызвал его, для какого объекта он был вызван, а также значение любой переменной определенной в данном методе. Он также знает контекст расположенный ниже него в цепочке. Если вы нуждаетесь в помощи чтобы понять этот процесс, тогда взгляните на иллюстрацию, на ней все изображено пошагово.
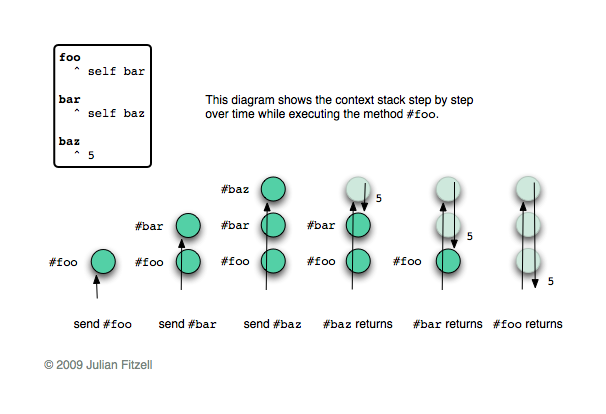
Нижеследующие диаграммы представляют цепочку контекстов обработки одного HTTP запроса. Каждый запрос — это результат клика на ссылке, порождающий выполнение колбэка. Каждый колбэк в конечном счете посылает или
#call: или #answer:.Диаграммы показывают цепочку контекстов в момент когда посылается
#call: или #answer, и изображают то, что случилось затем. Стрелки, направленные вверх, изображают прогресс по мере вызова методов, а вниз — по мере их завершения. Я изображаю исключения в виде пунктирной стрелки, хвост которой находится в месте возникновения исключения, а голова указывает на место его обработки. В случае, когда продолжение сохраняется, на диаграмме изображаются обе цепочки: та, что выполняется сейчас, и сохраненная; при этом стрелки направлены как обычно. Очевидно, что это очень упрощенные иллюстрации: я больше заинтересован в описание общей идеи, чем конкретных деталей.Что бы внести ясность, на каждой диаграмме отмечена серая полоса. Все что над ней — пользовательский код: та часть колбека, что будет выполнена. Все что под чертой — часть фреймворка: чтение из сокета, управление сессией и т.д.
Naïve (фр.) реализация
Окей, давайте взглянем на одну из возможных реализаций с использованием продолжений. Представим, что пользователь находится на web странице, содержащей ссылку «do it». Клик по ссылке выполняет колбэк приведенный выше в качестве примера, который должен спросить пользователя «Do it?». В процессе обработки данного запроса, происходит следующее:
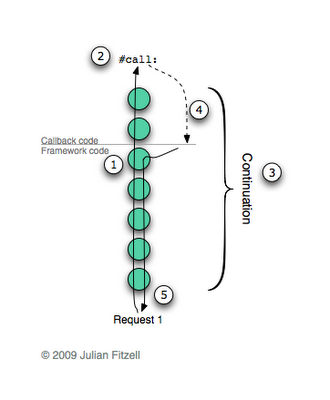
- Фреймворк ищет правильный колбэк и выполняет его.
- В процессе выполнения колбэка (внутри метода #inform: в приведенном примере), посылается сообщение
#call:. - Результат в каждом контексте сохраняется в продолжении для последующего использования
- Вызывается исключение, которое останавливает обработку колбэка и возвращает управление фреймворку
- Фреймворк продолжает работу и возвращает ответ браузеру (в Seaside, выполняется фаза рендеринга для отображения компонентов в ответе, но я здесь немного упрощаю).
В результате браузер должен отобразить приглашение «Do it?» и ссылку или кнопку, чтобы подтвердить действие. Когда пользователь кликнет по этой ссылке (или кнопке), будет задействован колбэк, который выполнит
self answer: true.. А когда будет получен второй запрос, произойдет следующее: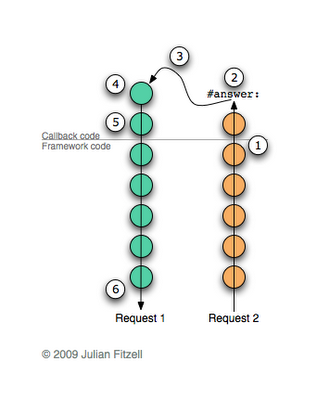
- Фреймворк ищет соответствующий колбэк и выполняет его.
- Колбэк посылает сообщение
#answer:. - Текущая цепочка контекстов отбрасывается и на ее место восстанавливается та, что мы сохранили в продолжении. Заметьте, что этот метод делает возврат второй раз. Это конечно странно, но не более странно, чем сохранять Smalltalk образ прямо посреди вычислений. Каждый раз когда будете открывать образ, вы увидите результат одного и того же вычисления.
- Теперь, когда мы восстановили прежнюю цепь контекстов, выполнение продолжится в первом колбэке так, как если бы наш вызов
#call:(место где мы сохранили продолжение) только что завершился - Восстановленный колбэк завершает свое выполнение (в нашем примере он проверяет значение ответа пользователя и посылает
#doItAlready) - Фреймворк посылает ответ браузеру
Но здесь есть проблема, и именно поэтому я назвал эту реализацию naïve. Как вы можете видеть, ответ некорректно возвращается по первому запросу. Сокет связанный с первым запросом к несчастью давно закрыт и браузер уже больше не ждет ответа. Браузер ожидает получить ответ, который судя по всему никогда не придет в сокет, связанный с запросом номер два. Уупс!
(Почти) Рабочий Call и Answer
Итак, первая реализация не работает, но я надеюсь она показала что же происходит с продолжениями. Проблема в том, что когда мы восстанавливаем продолжение, мы не хотим выкидывать абсолютно все, что сделал фреймворк. Как минимум нам нужен контекст, который вернет ответ в правильный сокет.
Простой способ ограничить кол-во контекстов захватываемых продолжением — это создать новый процесс. Новый процес запускается с новой, пустой цепочкой контекстов, так что когда мы создадим продолжение, только контексты в этой цепочке будут захвачены. Мы можем использовать семафор, чтобы заставить первый процесс ожидать, пока новый обрабатывает запрос. Когда второй процесс завершится, он зажжет семафор, и исходный процесс вернет ответ в правильный сокет.
Следующая диаграмма изображает данную схему (контексты разных процессов изображаются разными символами):

- В некоторый момент в коде фреймворка происходит создание нового процесса, а исходный ожидает сигнала семафора.
- Новый процесс находит и выполняет соответствующий запросу колбэк.
- Колбэк посылает сообщение
#call:. - Сохраняется продолжение (заметьте, что в этот раз продолжение начинается от точки запуска нового процесса).
- Выбрасывается исключение, колбэк прекращает обработку и возвращает управление фреймворку
- Фреймворк создает ответ для браузера и зажигает семафор.
- Исходный процесс продолжает свое выполнение и возварщает ответ браузеру.
Пока, единственным преимуществом является то, что продолжение меньше. Но когда приходит второй запрос, становится очевидно, как данный подход решает нашу проблему:
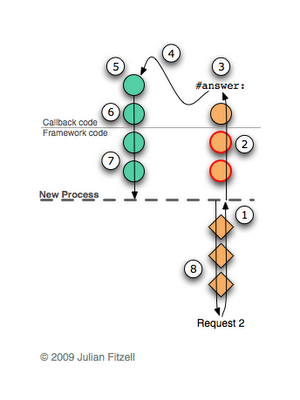
- В некоторый момент в коде фреймворка происходит создание нового процеса, а исходный ожидает сигнала семафора.
- Новый процесс находит и выполняет соответствующий запросу колбэк.
- Колбэк посылает сообщение
#answer:. - Текущая цепочка контекстов отбрасывается и восстанавливается та, что мы сохранили в продолжении (но обратите внимание, в этот раз отбрасываются только контексты в порожденном процессе, а ожидающий процесс остался незатронутым).
- После того как мы восстановили сохраненную цепочку контекстов, выполнение продолжается как будто-бы вызов
#call:только завершился. - Колбэк завершает выполнение.
- Фреймворк создает ответ для браузера и зажигает семафор, сообщая родительскому процессу о завершении своей работы.
- Исходный процесс продолжает выполнение, на этот раз корректно возвращая браузеру ответ.
Сейчас мы не только сделали продолжение меньше, но и добились того, что ответ на второй запрос вернулся по назначению. Именно такая реализация была использована в Seaside 2.8 и более ранних версиях.
Но здесь есть ряд существенных проблем:
- Создание межпроцессного взаимодействия увеличивает сложность системы.
- Исключения не могут преодолеть границу за которой новый процесс был создан. Действительно, если вы выбросите исклюлючение, то первый процесс никогда не узнает о нем (технически это преодолимо и можно симулировать данное поведение в какой-то мере, но это еще больше усложняет систему). Это значит, что обработка ошибок должна полностью производиться в порождаемом процессе. Что также добавляет трудностей, например, при работе с базой данных, которая использует исключения, чтобы пометить объекты как «грязные», или чтобы указать на состояние транзакции текущего процесса.
- Исключения выброшенные после восстановления продолжения будут пересекать восстановленную цепь контекстов. Также, когда исключение будет обработано, будет раскручена восстановленная цепочка контекстов, а не та, что была отброшена. Посмотрите на контексты фреймворка, раскрашенные красным на последней диаграме: у них не будет шанса завершить выполнение и все определенные ими страховочные блоки никогда не выполнятся. Верьте мне, когда я говорю что это может породить несколько коварных багов.
- Необходимо искать компромисс между размером и точностью в виду пунктов 2 и 3. Если вы запустите новый процесс сразу перед выполнением колбэка, то получите очень маленькое продолжение и более укороченную обработку исключений. К несчастью, ваши исключения не смогут быть проброшены достаточно далеко и код закончит выполняться в совершенно другом месте, например на фазе рендеринга.
- Отладка первращается в кошмар (ну как минимум в Squeak), когда код зависит от выполняющегося процесса. Я не уверен, что отладчики научатся переходить к процессу, непосредственно в котором произошла ошибка, но как минимум делать это безошибочно они не смогут.
Частичные продолжения
Частичные продолжения подразумевают, что вместо сохранения всей цепочки контекстов, мы сохраняем только ту часть, которая нам интересна. А когда востанавливаем частичное продолжение, мы заменяем им не всю цепь, а только ту часть, которая не представляет никакого интереса. Давайте взглянем как это работает.
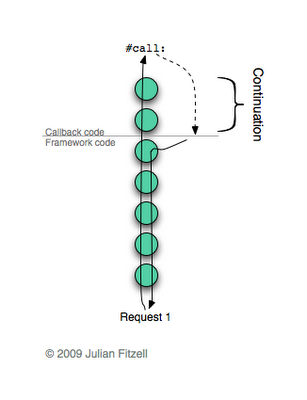
Когда приходит первый запрос, все происходит ровно также как и в первом примере, поэтому я не буду разбирать это пошагово, за исключением одной вещи: используя частичные продолжения, мы можем указать точный диапазон контекстов для сохранения в продолжении. В данном случае, мы сохраняем только те контексты, которые являются частью пользовательского кода — колбэком. Помните проблему из первой реализации? Код фреймворка обрабатывает один конкретный запрос; данные контексты фреймворка будут абсолютно бесполезны при обработке любого другого запроса (даже для одного и того же URL, все равно будет новый запрос). Так как колбэк может охватывать в своем выполнении несколько HTTP запросов, то только такие (назависящие от запроса) контексты колбэка нам и нужно сохранять для последующего востановления.
Помните также, что цепочка контекстов в реальной жизни может быть значительно длиннее, чем показана на данных диаграммах: так что мы сохраняем 5 контекстов вместо, скажем, 40! Ну как? Неплохая экономия.
А теперь взглянем на то, как обрабатывается второй запрос. Данная иллюстрация немного отличается и более сложна, потому что цепь контекстов меняется во время выполнения, так что я рассмотрю ее пошагово:
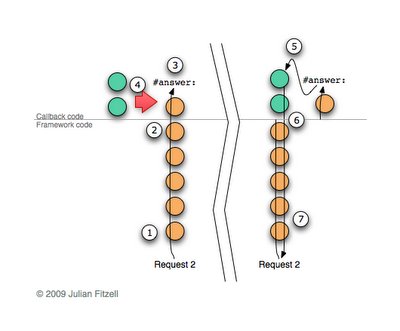
- Запрос попадает на обработку.
- Фреймворк ищет соответсвующий колбэк и выполняет его.
- Колбэк посылает сообщение
#answer:. - Затем ищется сохраненное частичное продолжение взамен существующему коду колбэка и сохраненные контексты буквально «трансплантируются» на место текущих, переписывая отправителей сообщений. Я вожу руками в воздухе, опуская детали, но вы должны поверить мне, все на самом деле происходит именно так. В правой части диаграммы показано состояние после завершения «трансплантации». Заметьте, что все контексты фреймворка остались незатронутыми, и мы все еще находимся в рамках исходного процесса.
- Продолжается выполнение сохраненного колбэка так, как если бы вызов метода
#call:только бы завершился. - Как только востановленный колбэк закончит свое выполнение, он вернет управление (потому что мы заменили отправителей) прямиком в код фреймворка, обрабатывающий текущий запрос.
- Далее сгенерируется ответ и будет передан через соответсвующий сокет браузеру.
Магия! Уверен, что выглядит именно так, но работает просто прекрасно. В итоге мы имеем коротенькие продолжения и нам не нужно создавать новый процесс, и весь код фреймворка получает шанс завершить свое выполнение успешно.
Вывод
Решение на частичных продолжениях на данный момент реализовано в разработческой версии Seaside и будет включено в следующий релиз. Squeak и VisualWorks уже поддерживают реализацию частичных продолжений в коде. GemStone близок к завершению их реализации в своей ВМ. Диалекты, которые не могут реализовать частичные продолжения, имеют выбор:
- могут симулировать частичные продолжения с различной степенью полноты, используя продолжения первого класса;
- могут продолжить использовать систему, похожую на ту, что была в Seaside 2.8;
- могут оставить их в покое. Как я отмечал выше, мы убрали использование продолжений и ядра Seaside: платформы могут просто прекратить поддержку для вызова
#call:и это сделать теперь легко, просто не предоставлять пакет Seaside-Flow.
Я надеюсь, что это было полезным и интересным чтивом и буду признателен вашим замечаниям обо всем, что показалось сложным или полезным для понимания. Happy Seasiding.
