

Текстов об «успешных DevOps-трансформациях» уже множество. Но одно дело — менять культуру в небольшой компании, а другое — в гиганте с полувековой историей. Если ты прославился закрытым десктопным продуктом, релизный цикл которого длится годы (Windows), как осваивать новые реалии (опенсорс, облака, постоянные деплои)?
О том, как менялась компания Microsoft, на нашей конференции DevOops рассказала Саша Розенбаум (на момент доклада — продакт-менеджер в GitHub). Не стоит ждать тут сенсационного срыва покровов, позволяющего немедленно принести девопс-культуру в любую компанию. Но отзывы зрителей показали: заглянуть внутрь гиганта, решения которого использует вся планета, им было интересно.
Поэтому мы сделали для Хабра текстовую версию доклада (а также прикладываем оригинальную видеозапись). Далее — повествование от лица спикера.
Вступление
Всем привет! Я очень рада сегодня быть с вами на конференции DevOops 2020, у которой такое классное название.
Меня зовут Саша Розенбаум (к певцу Розенбауму отношения не имею), и сейчас я продакт-менеджер в GitHub.
Расскажу немного о себе. Я начала свою карьеру программистом около 15 лет назад (да, тоже не могу поверить, что это было так давно). Потом стала больше работать с инфраструктурой, затем работала несколько лет в Microsoft архитектором и помогала большим компаниям перемещать свою инфраструктуру в облако Microsoft.
Найти меня можно в Twitter или в GitHub под ником DivineOps. Мой твиттер в основном о том, какие котики классные, но если у вас возникнут какие-то вопросы, можете задавать их там.
Сегодня я расскажу вам историю про Microsoft, которая немножко включает в себя и GitHub. Итак, как же появился DevOps, и как Microsoft продвигался к DevOps? Начнём с того, что сейчас приложения будущего сильно отличаются от того, что было даже десять, а уж тем более двадцать лет назад. Сейчас мы наблюдаем бурный технологический прогресс.

И эти приложения, у нас они называются облачные, интеллектуальные (cloud-native, intelligent), базируются на сотрудничестве с опенсорсом и программистами из других компаний или сообществ. И они фокусируются на ваших клиентах.
В наших приложениях будущего есть примеры подключения искусственного интеллекта к созданию воронки рекрутинга в HR-системе. Или примеры приложений, с помощью которых люди летают в космос. Или приложения, в которых существует совершенно новая платформа для рекламы в наших торговых корпорациях.
Люди не только летают в космос, но и занимаются исследованиями, например, черных дыр. Недавно была сфотографирована черная дыра, это была первая такая фотография в мире. Этот проект был создан с помощью опенсорса, благодаря сотрудничеству многих людей из совершенно разных компаний с разным бэкграундом.
Всё это происходит потому, что сейчас мы пользуемся совершенно другими инженерными методами, чем были десять лет назад. Именно поэтому компании начинают всё больше и больше интересоваться DevOps.
Зачем нужен DevOps?
Давайте обсудим, почему все говорят про эту методологию. Раз вы на конференции, которая ей посвящена, наверное, вас не нужно убеждать, что DevOps — это очень важно. Но, возможно, вы тоже не знаете всей истории.
Раньше считалось, что софт можно писать либо быстро, в ущерб стабильности, либо долго, и тогда он будет надежным. А того и другого одновременно быть не может.
Краткая история DevOps
Затем начали появляться совершенно новые подходы.
Примерно в 2008 году у людей начали появляться идеи о том, что такое DevOps, и как он может помочь развертывать код в продакшн быстрее.
В 2008 году Патрик Дебуа на одной из конференций рассказал людям про Agile для инфраструктуры, и с тех пор начались разговоры о том, как программисты (Dev) могут сотрудничать с эксплуатацией (Ops). Вместо того чтобы перекидывать баги друг на друга и говорить, что Dev нужны только новые фичи, а Ops — чтобы всё было стабильно, люди начали говорить о сотрудничестве, и что их общая цель — поставлять работающее программное обеспечение клиентам или пользователям. И на этом всё должно фокусироваться.
Прим. редактора: если захочется узнать об истоках DevOps подробнее — у нас об этом был отдельный хабрапост.
Кроме того, в 2009 году произошло еще несколько вещей.
Джон Оллспоу, работавший тогда в Flickr, на конференции Velocity рассказал, что Flickr публикует код в продакшн 10 раз в день. Ему почти никто не поверил. Или люди просто говорили: «Окей, у вас стартап и очень много денег, поэтому вы можете такое себе позволить. А вот в нашей организации такое совершенно нереально сделать».
Тогда же, в 2009 году в бельгийском Генте впервые была проведена конференция DevOpsDays, там было некоторое количество людей, которые обсуждали, что можно улучшить в нашей практике публикации кода в продакшн, чтобы всем лучше работалось.
В 2005 году появился Git, но еще не было SaaS платформы, где разработчики могли бы сотрудничать. Но системы контроля версий, в особенности внутри коммерческих корпораций были централизованные. Разработчики опенсорса тоже создавали свои собственные серверы и хранили там код. С появлением GitHub в 2008 году, появилась удобная и бесплатная SaaS платформа, где люди могли сотрудничать друг с другом, создавать опенсорс и вместе работать.
К 2009 году на платформе GitHub было уже было 50 тысяч программистов, которые сотрудничали над опенсорс-проектами. В 2010 году появился Microsoft Azure, который на тот момент назывался Windows Azure. Это тоже пример трансформации: на данный момент свыше 50% виртуальных машин на Microsoft Azure работают на Linux. Но когда он только появился, то даже по названию было понятно какую операционную систему Microsoft собирается поддерживать.
И начался он с того, что сначала были платформы как облачные услуги (platform as a service cloud services), которые были нацелены на программистов. Инфраструктуры там почти не было: всё было направлено на то, чтобы вы могли нажать одну кнопочку, и из Visual Studio код мог сразу уйти в облако и жить там на каком-то сервере. Так вышло, что из Dev я стала Ops, (или DevOps как мы теперь говорим, хотя мы вначале и не хотели чтобы DevOps стал названием должности и названием продукта, но и то и другое случилось), так как мы начали работать с Azure Cloud ещё в 2010 году и постепенно, когда Azure Cloud начал добавлять инфраструктуру, мы начали заниматься и инфраструктурой вдобавок к тому, чтобы заниматься разработкой.
В 2010 году вышла книга «Непрерывное развертывание ПО. Автоматизация процессов сборки, тестирования и внедрения новых версий программ» Джеза Хамбла и Дэвида Фарли (Вильямс, 2016). И по сей день эта книга фундаментальная в отрасли. Очень советую ее прочитать или хотя бы пролистать, если вы с ней не знакомы. На тот момент люди уже говорили о непрерывной интеграции, что мы можем компилировать и тестировать наш код каждый раз, когда кто-то коммитит изменение.
Но практически никто не говорил о том, что можно разворачивать в продакшн код, например, каждый день или каждый раз, когда кто-нибудь добавляет свой коммит. На тот момент это казалось чем-то недосягаемым. И мы видим, как за десять лет вся наша индустрия радикально изменилась, и теперь кажется совершенно обычным, что люди публикуют код несколько раз в день и даже больше.
В 2012 году появилось такое слово, как DevSecOps, стали говорить о том, чтобы интегрировать безопасность вместе с DevOps. У нас употребляется термин shift security left, то есть чем раньше мы интегрируем безопасность приложения в цикл разработки, тем лучше, чтобы как можно быстрее выявить баги, связанные с безопасностью. Над этим очень серьёзно работает GitHub, поскольку на данный момент это очень большая, ещё не разрешенная проблема.
В 2012–2013 годах начала появляться идея об инфраструктуре как о коде (infrastructure as code), что можно не только писать код, добавлять контроль версий и потом публиковать CI/CD в продакшн, но и делать так же с инфраструктурой. Можно написать какую-то автоматизацию, которая будет публиковать в продакшн даже виртуальные машины, чтобы они могли тоже автоматизироваться, быть в системе контроля версий и т. д. Начали появляться такие стартапы как Puppet, Chef, Ansible, которые занимались тем, чтобы автоматизировать инфраструктуру.
В 2014 году возникла идея об SRE (site reliability engineering), то есть об обеспечении надежности всех уровней системы, и был проведен первый SREcon. Люди начали говорить о том, как сделать код более надёжным и как фокусироваться на SLA (Service Level Agreement), SLO (Service Level Objective) и т. д. Поскольку речь о Microsoft, я упомяну еще несколько вещей, которые компания выпустила во всей этой истории.
В 2015 году Microsoft выпустила Azure Machine Learning — платформу машинного обучения в облаке. Мы работаем над тем, чтобы это становилось проще сделать, решаем нетривиальные проблемы DevOps для машинного обучения.
В 2017 году появилась оркестровка контейнеров. Сам Kubernetes появился ещё в 2014 году (первый релиз), а в 2017 году появился Microsoft Azure Kubernetes Service (AKS), и также другие облачные сервисы выпустили управляемые службы оркестраторов контейнеров для облачных приложений.
В 2019 году GitHub вырос и стал еще более значимым для сообщества. Если в 2009 на GitHub было 50 тысяч программистов, то в 2019 их стало уже 40 миллионов. На данный момент мы перевалили за 50 миллионов. Более 50 миллионов программистов, а также людей с другими бэкграундами, которые имеют репозитории или аккаунт на GitHub, сотрудничают над опенсорс-проектами, и многие из них активно работают над всеми этими программами.
Также в 2019 году GitHub выпустил компонент Actions для CI/CD и автоматизированной безопасности, о которой можно говорить очень долго. Теперь мы вносим вклад не только в опенсорс-код, но и в остальные практики DevOps — разработку и эксплуатацию.
Идеи приходят и уходят. Почему DevOps никуда не денется?
Многие идеи появляются и уходят, такое часто бывает. Но почему же прижился DevOps? Мы говорили о парадоксе доставки ПО: либо мы можем двигаться быстро и иметь какую-то инновацию, либо можем иметь стабильность — код не ломается, в продакшне нет инцидентов и т. д.
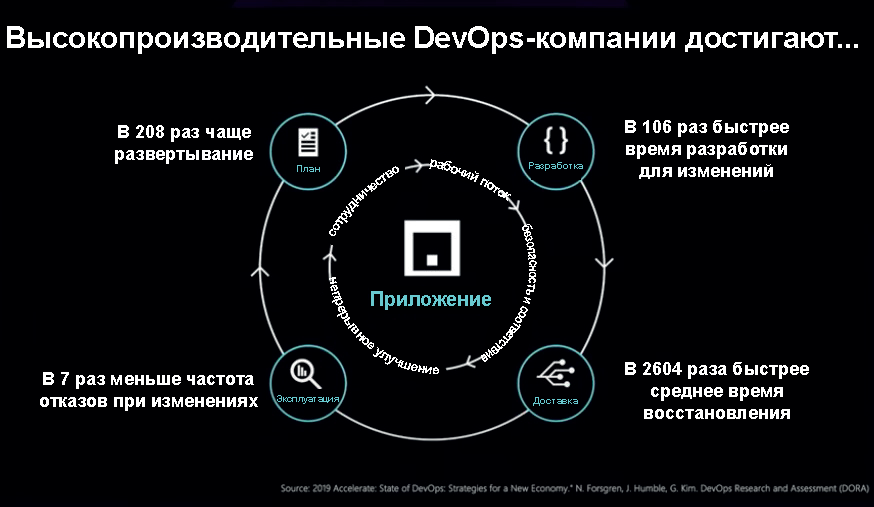
Но если посмотреть исследования, которые появились за последние несколько лет, то мы увидим, что это неправда. На самом деле у компаний, которые работают быстрее, также меньше всё ломается.
Почему? Это немного парадоксально, но подумайте об этом как о мышце. Если вы качаете мышцы только раз в три месяца, то никакого прогресса не будет. Но если вы тренируетесь каждую неделю или каждый день, то произойдёт заметное улучшение, вы натренируете её, и она станет сильнее.
Аналогично это работает в DevOps. Если публиковать код в продакшн раз в три месяца, то процесс будет долгим и болезненным. Но если публиковать его каждый день, то с каждым разом всё будет проходить легче.
Из исследований мы знаем, что у компаний, которые публикуют код чаще, намного меньше ошибок, возникающих во время развертывания, а восстановление проходит намного быстрее. Если что-то ломается, то такие компании в 2600 раз быстрее всё чинят, так как всё в системе контроля версий, всё восстанавливаемое, и всё можно очень быстро повторить. И это не какие-то чек-листы, которые живут в документах единственного на всю компанию человека, который знает, как правильно сделать.
Зачем Microsoft трансформация?
Ещё один интересный вопрос, если мы говорим про Microsoft: зачем нужна была трансформация?
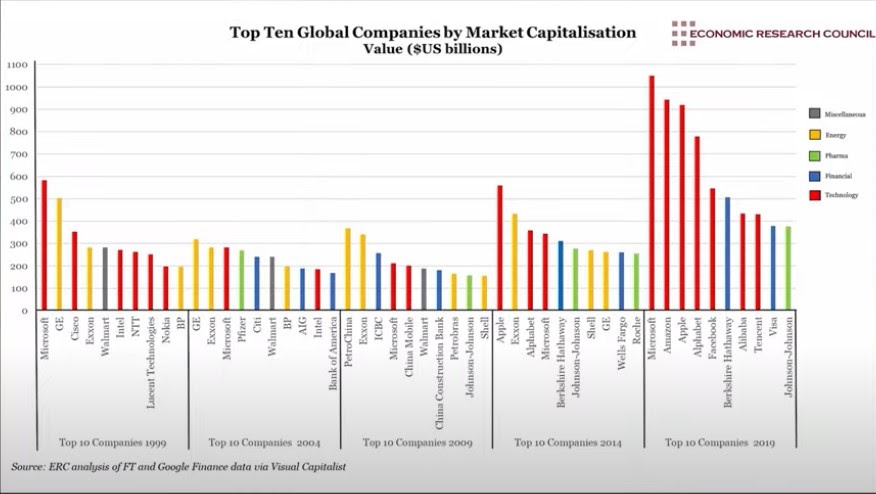
Мне очень нравится этот график. Он отражает то, у каких компаний была самая большая рыночная капитализация за последние двадцать лет — с 1999 по 2019 год. Можно заметить, что Microsoft единственные, кто всё это время находились в списке десяти самых больших компаний мира.
Но зачем Microsoft было всё менять, если у них и так всё было хорошо и они прекрасно себе зарабатывали деньги? Лично я считаю, что Microsoft как раз и находится в списке десяти крупнейших компаний мира, так как в ней не боятся всё менять и не думают, что если они делали что-то вчера, то и завтра это будет продолжать работать. Мы знаем, что в мире технологий всё меняется очень быстро, и поэтому если не меняться и делать все привычным путем, то не получится оставаться лидером в мире технологий.
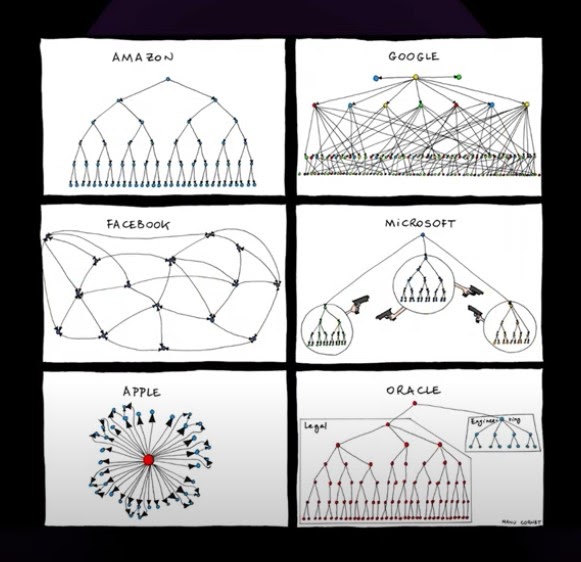
Этот шуточный график был нарисован в 2011 году, он показывает разные оргдиаграммы больших компаний. Но в каждой шутке есть доля правды, и в реальности оргдиаграммы этих компаний отчасти похожи на те, что тут нарисованы.
Остановлюсь на Microsoft. Там все выглядело примерно так:
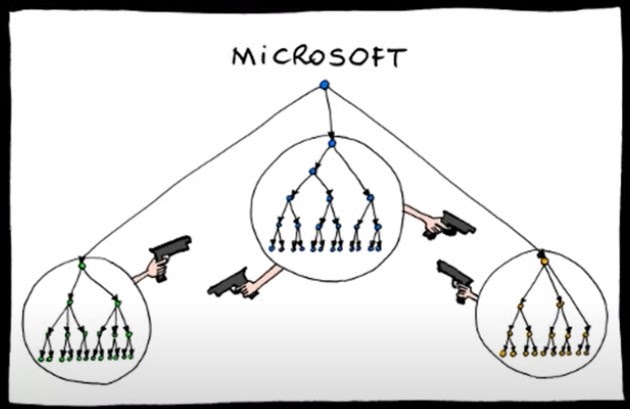
Между разными отделами постоянно шла какая-то война. Почему? Потому что были какие-то мотивы, чтобы люди не сотрудничали, а показывали свои личные результаты или результаты своего отдела. Давайте подумаем: допустим, если я глава Office, а вы глава Windows, то я не хочу полагаться на какие-то инструменты, которыми вы пользуетесь, на инструменты CI/CD. Почему? Потому что если мне нужна какая-нибудь новая фича, а вам в Windows это не нужно, то вы мне её и не сделаете. Тогда мой бонус зависит от того, что я полагаюсь на чьи-то инструменты.
И это приводило к тому, что каждый отдел разрабатывал свои собственные инструменты CI/CD и собственные тестовые фреймворки. И каждый отдельный разработчик делал новый фреймворк или инструмент, вносил это достижение в свой отчет, и в конце года на основе отчета ему присуждали бонусы и т. д.

Тут Microsoft очень повезло — пришел Сатья Наделла, который стал CEO. У Наделлы инженерный бэкграунд, 20 лет он работал в инженерных отделах прежде чем стать топ-менеджером. Он сказал о том, что мы не эффективно расходуем время, раз за разом создавая одни и те же инструменты, которыми пользуются люди. В разных отделах происходит повторяющаяся работа. Он сказал: «Я без раздумий предпочту работу над продуктивностью работе над фичами».
Eсли вы читали книгу Джина Кима Unicorn Project, то знаете, что в большинстве компаний происходит не так. В них руководители больше всего хотят новые фичи, и не очень понимают, почему нужно работать над повышением продуктивности или сокращением технического долга. Но как я уже сказала, Microsoft в этом случае очень повезло.

Так появилась единая инженерная система (1ES), на которой теперь базируются все инженеры в Microsoft. На данный момент около 105-110 тысяч инженеров (сегодня в Microsoft более 150 тысяч работников) пользуются платформой DevOps, то есть одной инженерной системой. Есть 500 миллионов тестов, которые запускаются каждый день, 5 миллионов рабочих элементов, 85 тысяч развёртываний в день и т. д. Естественно, цифры меняются каждый месяц, но в целом всё обстоит приблизительно так.

Если мы хотим узнать, насколько единая инженерная система полезна для Microsoft, то можно провести такую аналогию: если мы сохраняем всем инженерам компании одну секунду в день, это равнозначно найму еще четырех человек в Microsoft. Если мы сохраняем им одну минуту, то это эквивалентно найму 163 человек в Microsoft. А если мы каким-то образом сохраняем им целый час в день, то создали почти 3 миллиарда дохода в год за счет того, что все пользуются одной и той же системой инструментов, которая может сохранять одновременно практики для всех отделов.
Важно отметить, что это не те цифры, на которые смотрит ваш непосредственный начальник и за которые вы получаете бонусы. Но по ним можно сделать простые вычисления и показать руководителям, для чего вам нужны инструменты CI/CD, стандартизация и прочие вещи.
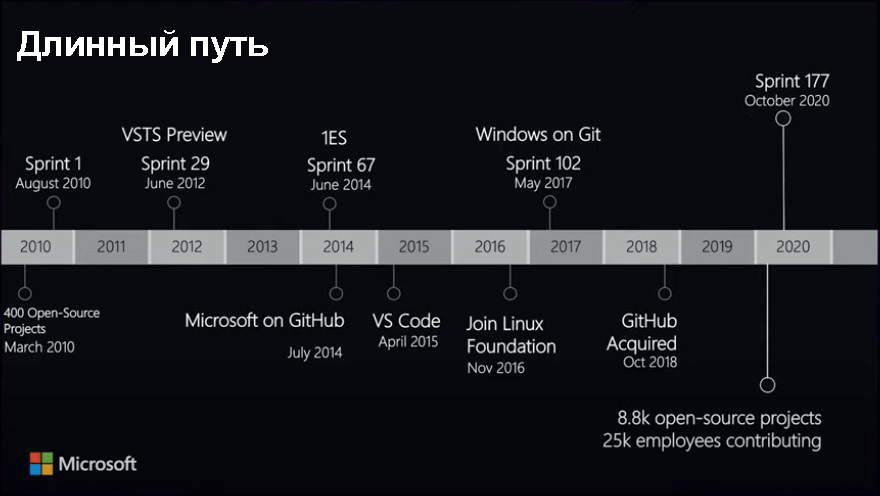
Хочу показать таймлайн Microsoft. В 2008 году началась работа над Team Foundation Server (предшественником MS Azure DevOps), и в 2010 году вышла первая версия TFS на DVD. Первая версия, которая была записана на DVD, с трудом скомпилировалась, с трудом прошла все тесты, и была записана с большим трудом. Несколько месяцев со скрипом все работали над этим адским мёрджем, и в конце всё скомпилировалось, записалось и было доставлено клиентам.
Но кроме этого ещё и клиентам нужно было нанять пару консультантов, которые помогли бы установить TFS. Просто так из коробки он не работал, его нужно было хорошенько доработать напильником, чтобы убрать все шероховатости, и всё нормально начало работать.
Выпустить первую версию заняло два года — с 2008 по 2010, и потом ещё два года — до VSTS Preview. И из этого цикла, который продолжался два года до релиза софта, мы на сегодня перешли к тому, что сейчас Microsoft публикует Azure DevOps и другие продукты несколько раз в день.
Такая трансформация — глобальная. Мы перешли от поставки лицензии на ПО раз в два-три года до того, что каждый день публикуем что-то в продакшн. К тому же у нас есть запущенная облачная служба — то есть поддерживаемые системы, которые живут в облаке и работают 24 часа в сутки. Их поддерживаете не вы на собственном сервере, а Microsoft.
Visual Studio Team Services вышел в 2012 году, а потом был переименован в Azure DevOps. В 2014 году впервые появилась организация Microsoft на GitHub, и там начали размещать разные опенсорс-проекты. Опенсорсные проекты у MS появились ещё до приобретения на GitHub — в 2010 году их число составляло 400. В 2014 году также появилась первая версия единой инженерной системы, на которую начали переходить разные отделы Microsoft, чтобы инструменты CI/CD у всех были одинаковые.
В 2015 году появился VS Code, который сразу был с открытым исходным кодом, и это тоже важная веха в Microsoft — компания решила запустить не коммерциализированный продукт, а сразу опенсорсный.
В 2016 году Microsoft присоединилась к Linux Foundation, что очень многих удивило. В 2017 году произошла ещё одна важная вещь — Windows перешел на Git. До этого код Windows хранился в нашей собственной системе контроля кода, которая называлась TFVC (существует до сих пор). В 2017 году Windows перешёл на Git, который изначально был создан для поддержки Linux.
В 2018 году Microsoft приобрела GitHub. Вот почему я тут перед вами в футболке с логотипом GitHub. На данный момент (декабрь 2020 года) у нас почти 9 тысяч опенсорс-проектов в Microsoft (суммарно за 10 лет), и 25 тысяч из примерно 150 тысяч работников в Microsoft активно работает над опенсорсом. Например, сотрудничает с Kubernetes и другими опенсорс-проектами, которыми пользуется множество людей.
Как Microsoft создает приложения будущего
Давайте углубимся в то, как мы этого всего достигли. Здесь очень много аспектов. Начну с одной из моих любимых вещей, которые Сатья Наделла принес в Microsoft — гибкое сознание.
Есть гибкое сознание (growth mindset) и негибкое сознание (fixed mindset). В последнем вы расцениваете, что ваши способности происходят из внутренних врожденных талантов, и поэтому каждый день должны доказывать, какой вы действительно умный, талантливый и классный.
Важность гибкого сознания
Наверняка вы знаете людей, которые приходят и хотят всем доказать, что они самые умные, круче и лучше всех. Некоторое время назад профессор Кэрол Дуэк выпустила книгу «Гибкое сознание. Новый взгляд на психологию развития взрослых и детей» (МИФ, 2013) о том, как тяжело учиться новым вещам, когда у вас негибкое сознание.
Если вы постоянно доказываете всем, что вы лучше всех, то не можете при этом изучать что-то новое, так как для этого нужна определенная уязвимость, чтобы сказать себе: «Окей, я не знаю, как это делать — я хочу этому научиться». Поэтому люди с гибким сознанием гораздо легче учатся новому и могут принять то, что будут делать ошибки, которые в конечном итоге ведут к успеху.
Почему это важно для компании? В мире технологий, а особенно сейчас, всё меняется очень быстро. Если раньше вы могли что-то изучить и эти знания были актуальны 2-3 года, пока, скажем, Microsoft писал новую версию TFS, то сейчас это так не работает — всё постоянно меняется. И поэтому всем нужно принять установку на рост, научиться гибкому сознанию и тому, что мы можем воспринимать все новое, постоянно учиться у других людей и получать доступные знания.


Компания Microsoft сделала упор на том, чтобы создать бо́льшую ясность того, над чем мы работаем, чтобы можно было чётче фокусироваться на наших клиентах; чтобы изменить способ сотрудничества; и на том, чтобы производить софт с прицелом на стабильность.
Создавайте ясность

Итак, как мы создаём ясность? Какое-то время назад вышла книга Джона Дорра «Измеряйте самое важное» (МИФ, 2019). В книге описывается система OKR, которая пришла из Intel (изначально она называлась MBOs), потом была перенята и модифицирована Google и теперь есть и в Microsoft. OKR (Objectives and Key Results) — это цели и ключевые результаты.
Вы назначаете цель. У вашей команды может быть от 3 до 5 целей, на которых вы фокусируетесь. Потом вы присоединяете к ним конкретные ключевые результаты. Важно, чтобы они говорили, чего вы хотите добиться, а не то, что планируете делать. Наша метрика — это счастливые клиенты, а не публикация восьми фич в продакшн каждый месяц.
Допустим, если у вас блог, то цель должна быть такая: мы хотим, чтобы блог с удовольствием прочитали 1000 человек, а не то, чтобы мы написали 8 постов, потому что это на самом деле этот никак нам не помогает. Измеряются результаты, а не действия.
Ключевые результаты подразделяются на фиксированные и желательные. Фиксированные — это то, что надо достичь на 100%. Не факт, что мы достигнем результата на 100%, но мы хотим, чтобы он все время приближался к этому показателю. Желательные (aspirational) — это некие амбициозные цели, которые мы не до конца можем достигнуть, но хотим к этому стремиться. Тут мы можем позволить себе, например, 70%. Важно, чтобы желательные ОКР не влияли негативно на бонусы работников, иначе возникает ситуация, когда люди специально занижают цели во время планирования, чтобы точно их достигнуть.
Это не единственная система, которой можно пользоваться, но в OKR есть кое-что очень полезное. Например, мы говорим о том, чего хотим добиться в конце, а также фокусируемся на всей организации, и всё очень наглядно. Мы начинаем с того, что создаем OKR для продукта, а потом спускаемся ниже на уровень отдельных сервисов в продукте и создаём OKR для них.

Затем это идет в каждую отдельную команду, при желании и возможности OKR можно прописать для каждого члена команды. Уровни этой лесенки должны сочетаться: если ваши командные цели будут достигнуты, то и цели продукта тоже, и тогда она будет иметь смысл.
Всё это вместе помогает делать какую-то подстройку, руководители высшего уровня дают общую картину того, куда движется компания. Затем каждая команда выбирает свой способ реализации, то есть руководство не вмешивается в то, как вы пишете код в своей команде и т. д.
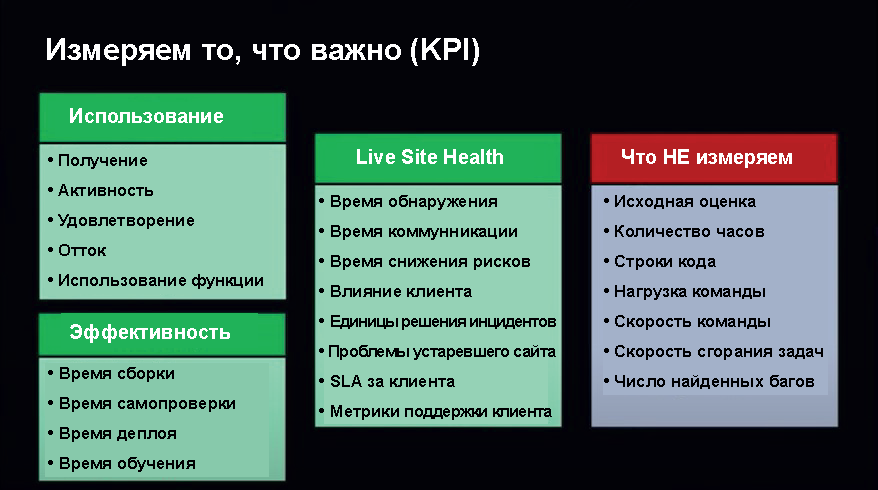
Необходимо измерять то, что вам важно. Например, в Azure DevOps мы измеряем использование, то есть привлечение клиентов: сколько клиентов к нам присоединяется, сколько пользуется продуктом, насколько они удовлетворены им. По сути, это всем известный NPS (Net Promoter Score — индекс определения приверженности потребителей товару). Также измеряется отток (churn) — сколько людей присоединяется и потом сразу уходит. Потом — эффективность, то есть сколько времени занимает компиляция, тестирование, развёртывание во все среды, а также Live Site Health — сколько времени занимает выявление и исправление инцидентов; также работа над SLA, например, SLA на определенного клиента, потому что иногда бывают баги, которые касаются только одного клиента, и на это тоже нужно смотреть, а не только на то, что влияет на всех.
На этом слайде мне больше всего нравится правая колонка — то, что мы НЕ измеряем (это тоже очень важно). Примеры — это насколько близко мы пришли к исходной оценке того, сколько времени это займёт, потому что на самом деле это не важно. Невозможно полностью предсказать, сколько времени займет написание какого-то ПО. И Microsoft теперь НЕ пишет жесткие сроки доставки. У нас есть мягкие дедлайны — мы говорим, что примерно выйдет в такой-то период, но без конкретной даты, потому что мы знаем, что лучше писать хорошее ПО, чем поставлять баги ради дедлайна.
Мы не измеряем, сколько строчек кода написано — это никому не нужно. Не измеряем количество найденных багов — тогда люди начинают находить очень много мелких ошибок, что тоже не помогает. Не измеряем объём сгорания задач в команде и ее скорость — эти метрики очень легко подогнать, и люди начинают блефовать и завышать оценки, чтобы добиться правильной скорости, что опять-таки никому не помогает.
Будьте одержимы клиентом
Мы фокусируемся на наших клиентах. В чем это выражается? Например, у нас была эволюция определения того, что мы считаем готовым, то есть когда мы закончили работу над какой-то фичей.
Первый этап — фича работает на моем компьютере, значит все нормально.
Потом мы стали считать, что фича готова, когда мы запускаем её в ветви разработки — это уже немножко лучше, потому что происходит слияние с командой.
Следующий этап был, когда фича идет в главную ветвь, что ещё лучше, и это значит, что все команды работают вместе и делают коммиты в главную ветвь.
Следующий, когда она проходит тесты — это вообще замечательно, особенно если тесты хорошие. Всё приближается к непрерывной интеграции.
Потом мы сказали — окей код готов только тогда, когда софт «живёт в продакшне», им все пользуются. И всё вроде бы прекрасно, кажется, что на этом можно было бы закончить эволюцию. На самом деле нет.
Следующий и на данный момент последний этап — это софт в продакшне, которым довольны ваши клиенты. Мы не просто выпустили продукт в продакшн, но и люди им пользуются и они им довольны. Потому что если мы пишем софт, которым никто не пользуется или которым люди очень недовольны, то цель не достигнута и мы не можем сказать, что закончили работу.
У нас происходит разработка через гипотезы: продакт-менеджеры Microsoft не решают, что мы знаем, чего хотят наши клиенты. Конечно, и раньше они проводили исследования клиентов, но в основном они решали, что знают, чего те хотят. Разработчики уходили в какой-то бункер, запирались там, писали, какой должен быть дизайн, потом работали два года над этим продуктом, выпускали, и потом, когда приходил фидбек, фиксили его. Но обычно на этом всё и заканчивалось, и потом клиентам надо ждать ещё два года для того, чтобы вышли какие-то новые фичи и патчи.
Сейчас мы делаем разработку через гипотезы — думаем, что какая-то фича хорошая и полезная, создаем базовый вариант этой фичи (туда тоже входит исследование клиентов, интервью и т. д до того, как это всё создается). Но потом софт выпускается в продакшн, допустим, под фиче-флагами, когда вы можете выбирать, пользоваться той или иной фичей или нет. Затем мы смотрим, как реагируют люди, довольны ли наши клиенты. Если недовольны, значит фича будет изменяться до тех пор, пока люди не будут ей довольны. А если совсем недовольны, возможно, мы просто не будем эту фичу дальше разрабатывать и поддерживать.
Фидбек от клиентов мы получаем всеми возможными способами: на Stack Overflow, на форумах Azure (ранее MSDN) и ещё на всяких разных площадках. Проектные, продуктовые и программные менеджеры активно собирают обратную связь на свои продукты.
Индекс потребительской лояльности NPS есть в самом продукте: периодически у вас может всплывать диалоговое окно, и мы много думали, как сделать его полезным, чтобы оно не отвлекало от работы и т. д. В самом продукте можно сделать предложение о том, что можно улучшить, добавить отчет об ошибках и т. д.
В самом продукте, даже если вы им пользуетесь бесплатно, можно дать фидбек. И у нас есть «чемпионы по клиентам» (customer champions) — крупным клиентам назначается сотрудник из инженерного отдела, который разговаривает с ними, допустим, раз в месяц. Такие сотрудники могут выступать адвокатами клиентов и влиять на продукт.
Превращение в фулстековую команду
Это тоже эволюция. Подходов может быть множество, но мне нравится подход Microsoft.
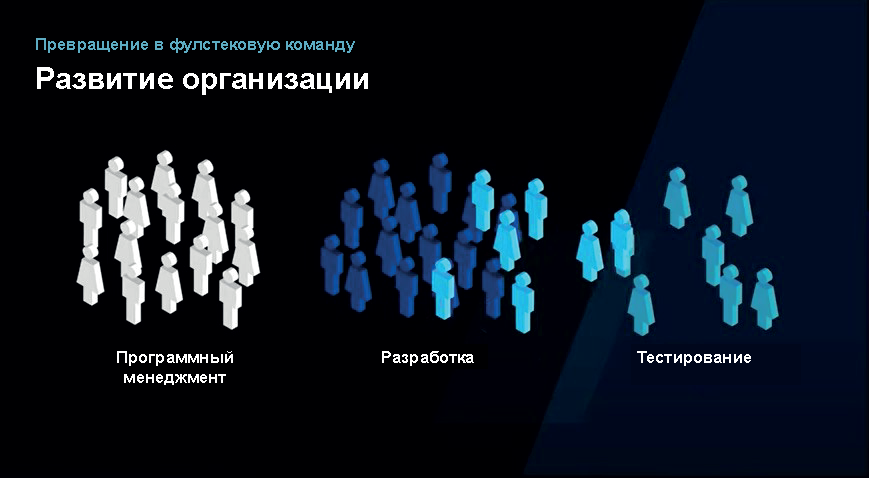
Вначале были программные менеджеры, разработчики и тестировщики, которые находились в разных отделах. Программисты «перекидывали что-то через стену» QA. Потом программисты и тестировщики стали просто называться инженерами, и этот барьер был убран.
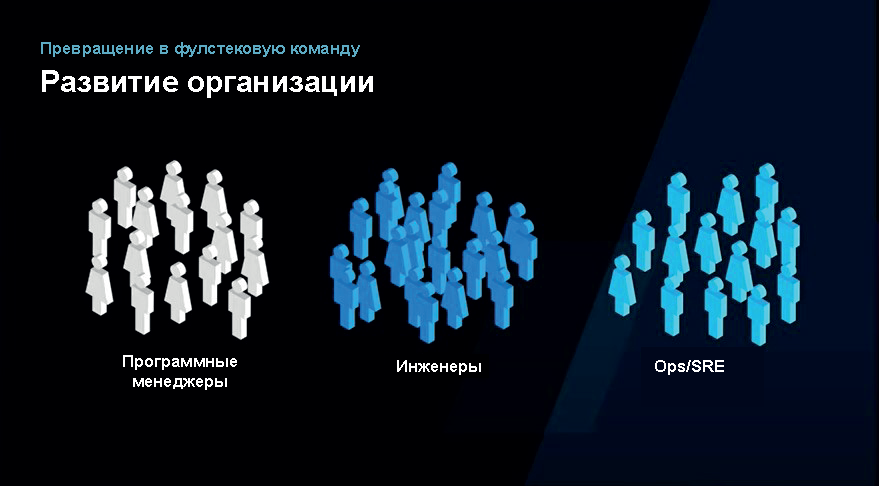
Потом какое-то время были только инженеры разработки. Когда у Microsoft появились SaaS продукты, добавилось направление Ops/SRE, так как мы начали запускать эти продукты в продакшн, облако и платформу как услугу. В отдельную группу входят программные менеджеры, которые не пишут код. Хотя многие из них имеют инженерный бэкграунд и умеют и программировать, и тестировать.

Потом мы пришли к тому, чтобы иметь фиче-команды, где для разработки определенной фичи есть и дизайнер, и фронтенд-инженер, и бэкенд-инженер и так далее. И теперь разработка фичи проходит не между разными командами, а в одной фиче-команде.
Например, вам не нужен дизайнер фуллтайм, а только на 20% времени, при этом этот дизайнер действительно ваш, находится с вами в одной команде, и вы работаете вместе с ним над одной функциональностью. Вместо команд с горизонтальной функциональностью (кто-то работает над базами данных, кто-то над API, UI и т. д.), мы делаем вертикальные фулстековые команды.
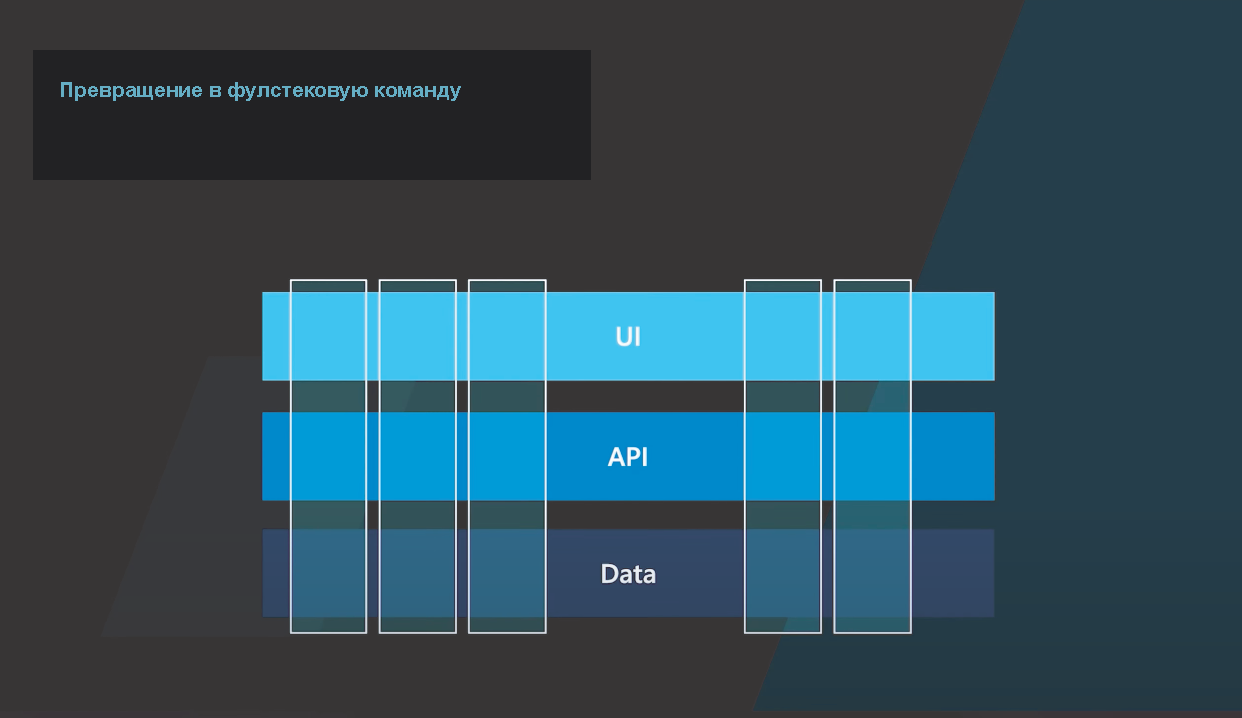
И для нас это работает очень хорошо, так как добавляет чувство собственности и люди не перекидывают задачи через забор (это в QA, а это в UI и т. д). Допустим, если приходит какой-то отзыв от клиента, и человек, который занимается базами данных, его тоже видит и понимает, что причастен к созданию этой функциональности, тогда он более настроен этим заниматься и что-то исправлять, а не только относится к этому, как к проблеме UI.

И ещё такая вещь, которую я видела только в Microsoft: самоформирующиеся команды. Раз в год или два (по ситуации) мы устраиваем совещание, где вы можете выбирать, в какой команде хотите работать. Все продакт-менеджеры приходят и рассказывают, над чем они в данный момент работают, и инженеры могут выбрать, в какую команду хотят перейти. Мы знаем, что только чуть меньше 20% людей меняют команды, но всегда есть возможность перейти в другую команду, потому что, например, вы хотите работать с той технологией или потому, что та команда вам по каким-то причинам нравится больше.
Microsoft вообще очень поддерживает внутреннюю мобильность, чтобы люди имели постоянное развитие своей карьеры и не чувствовали, что засиделись. Если сотрудник придёт к своему начальнику и скажет, что хочет работать в другой команде, босс не рассердится, а поддержит и постарается, чтобы у сотрудника получилось и его взяли туда, куда он хочет (я проверяла это на собственном опыте).
Измените способ сотрудничества, разработки и доставки
Следующий этап — изменение способа сотрудничества. Принципы опенсорса — внешнее сотрудничество — появились и в нашей компании. В английском это называется InnerSource — люди вместе работают над кодом внутри компании.

Inner source сейчас развивается и постепенно начинает внедряться в разные крупные компании. Из опенсорса нам знакомо такое понятие, как воронка вкладов (contribution funnel): большинство людей будут просто пользоваться вашим кодом, то есть качать пакеты или, может быть или заведут свой форк. Некоторые люди будут вкладывать время, например, опишут какие-то баги, дополнят документацию или сделают что-то ещё. Еще меньше людей действительно будут писать код в таком проекте. И очень маленький процент от всех этих людей будут «владеть» проектом, то есть станут его мейнтейнерами, будут сотрудничать и давать фидбек, который на самом деле очень важен.

Внутреннее сотрудничество в компаниях происходит примерно так же. И чтобы к вам могли присоединиться, следует сделать наиболее простой для людей способ начать сотрудничество. Для начала нужно написать хороший README, где описано, что у вас за проект и зачем он нужен. Следующее — написать очень хороший CONTRIBUTING.md. Там должно быть описано, как нужно заниматься проектом, как компилировать, какие для этого нужны инструменты и т. д.
С выходом GitHub Codespaces это стало проще. В Codespaces можно работать, можно всё отконфигурировать и сделать всё ещё проще для людей. Также важно создать список «good first contribution» (хороший первый вклад), чтобы новые люди в проекте знали, с чего им начать и какой баг можно легко пофиксить.
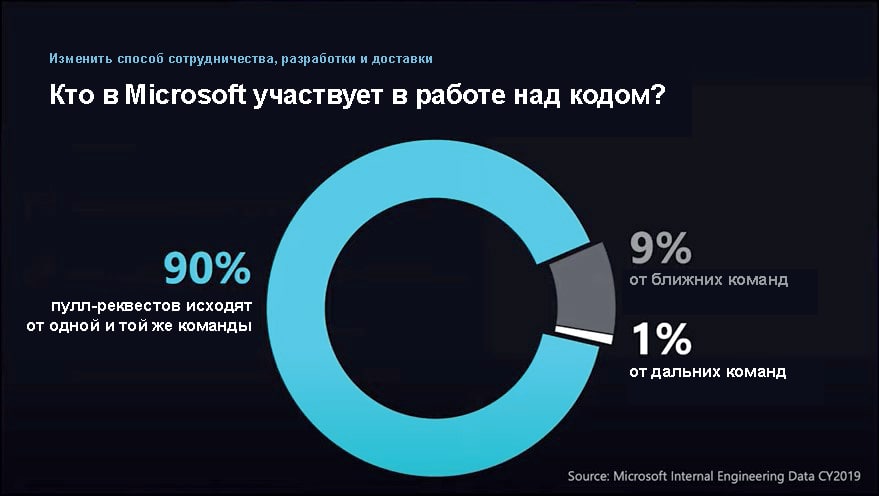
Внутри Microsoft 90% пулл-реквестов поступает от участников той же команды. Но потом 9% — из соседней команды и 1% от вот всех запросов приходит из команд, которые могут быть совершенно в другом отделе организации.
Что всё это значит? Почему InnerSource — это классно? Например, я работаю над UI для какого-то проекта, а у него есть API, который я беру из другого отдела. Мне нужны какие-то данные из этого API, а в этом API, например, мне не хватает какого-то параметра. Если у нас нет InnerSource, то я должна обратиться к людям из вашего отдела и просить их помочь мне решить эту проблему, которая для них, возможно, не в приоритете. Т. е. я должна ждать пока вы его добавите, или же идти к вашему начальству и добиваться, чтобы эта задача была в приоритете.
Но если есть InnerSource, то всё будет расписано: как делать вклад в проект, как можно сделать пулл-реквест в ваш API и т. д., какие инструменты для этого нужны.
Тогда я могу посмотреть ваш код и ваши процессы разработки, и просто добавить этот новый параметр в ваш API. Ваша команда теперь может проверить, что он проходит все тесты, посмотреть код-ревью, убедиться, что всё соответствует вашим стандартам, а потом его смёрджить, и тогда я сама себя разблокирую. Так в InnerSource появляется общая возможность продвигаться быстрее.

Я начала с того, что в Microsoft люди почти не сотрудничали друг с другом, потому что каждый был мотивирован на собственный бонус. Одно из изменений в Microsoft касается процесса ревью: теперь есть три круга, где мы смотрим не только на ваши индивидуальные результаты, но и на то, как вы помогли успеху других и воспользовались их работой, чтобы добиться лучших результатов. Сотрудников Microsoft поощряют к сотрудничеству.
Начальники в нашей индустрии часто жалуются на то, что люди в их команде не хотят сотрудничать. Но когда люди друг с другом соревнуются и не сотрудничают, это не значит, что у вас плохая команда. Это значит, что никаких положительных стимулов для совместной работы нет, а вместо этого поощряются индивидуальные героические результаты.
Итерации наболевшего
Следующий шаг — итерации самого наболевшего: решать ту проблему, которая больше всего вам мешает. Сразу всё решить невозможно, и нам нужно что-то приоритизировать. Как узнать, что именно? В Microsoft мы берем ту одну проблему, которая больше всего мешает, и начинаем работать над ней.
Приведу пример, как в Azure DevOps переписывали тесты. Изначально были тесты, которые прогонялись больше 24 часов. А выпустить новый апдейт чаще, чем раз в день, было невозможно, потому что даже тесты выполнялись дольше, чем за день. Их было несколько тысяч, и переписать их все за день было невозможно. И мы не могли сказать: «Окей, теперь ещё три года мы будем только переписывать тесты», потому что клиентам все ещё нужны результаты, новые фичи в продакшн и т. п.
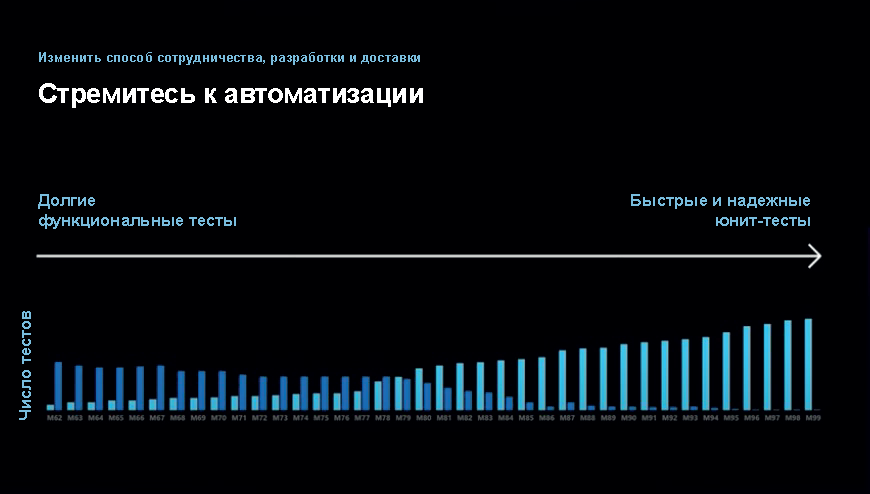
Постепенно, продолжая работать над новым кодом, команда начала переписывать тесты, убивать самые плохие и долгие, добавлять хорошие, которые проходят быстрее и более надёжны.

За три года мы добились того, что юнит-тесты (а у нас их сегодня 85 тысяч) проходят меньше чем за 7 минут. Это заняло долгое время, но зато мы знаем, что тесты надёжны: только если прошло 100% этих тестов, тогда мы знаем, что можем выпускать код в продакшн.
И мы используем пулл-реквест, чтобы контролировать изменения и знать, что в продакшн попадает только хорошее. У нас есть код-ревью, который происходит на пулл-реквесте, это такой чекпоинт. Также есть автоматизированные проверки, которые происходят на пулл-реквесте.
Важно, чтобы тесты проходили все — не может быть такого, что один тест не прошел, но всё нормально. Если есть нестабильные (flaky) тесты, которые то проходят, то нет, тогда мы их просто идентифицируем и убиваем, потому что это ненадёжная система.
Магистральная разработка
Кроме того, в Microsoft делают так называемую магистральную разработку (trunk based development). Меня часто спрашивают, как её можно делать. Допустим, мы три месяца работаем над какой-то функциональностью и не хотим её сразу показывать пользователям. Как тогда работать на главной ветви? У меня к вам вопрос: тестируете ли вы в продакшне?
В основном люди отвечают, что нет. Но открою вам секрет: все тестируют в продакшне. В любой момент, когда в продакшне есть баг, это значит, что вы тестируете там. И вместо этого, вы можете тестировать там целенаправленно.
Один из вариантов — это фиче-флаги (feature flags): весь код идет все время в главную ветвь. Если я три месяца работаю над какой-то фичей, то это весь этот код всё время живет в продакшене. Фиче-флаги, контролирующие, что видит пользователь, есть как с нашей стороны, так и со стороны пользователя (он может добровольно включить у себя что-то).
В результате получается, что весь код тестируется всё время. Я не кидаю через три месяца из какой-то ветви разработки в ветвь продакшна, и тогда всё ломается. Код тестировался всё время, и если что-то сломалось, когда включился фиче-флаг, то его можно просто выключить — тогда его больше никто не увидит — и код можно чинить. Кроме того, что мы проводим постепенное знакомство с новыми релизами, происходит собственный цикл (кольцо) развёртывания.
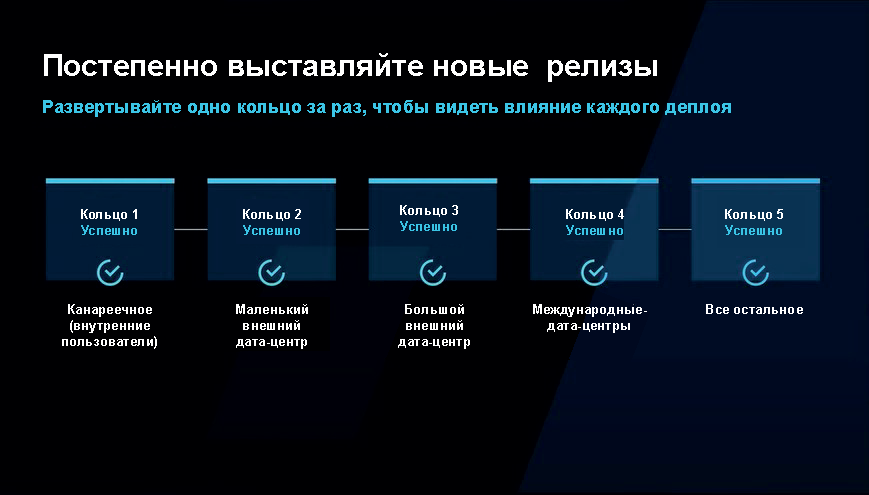
Начинается всё с канареечного развёртывания, где есть внутренние пользователи. В Microsoft 110 тысяч инженеров, что позволяет как следует протестировать код только с внутренними пользователями. Затем код выходит в самый маленький внешний дата-центр и прогрессивно проходит все кольца до того, как приходит ко всем пользователям.
Между этими кольцами проходит примерно 24 часа ожидания и, кроме того, в любой момент процесс можно остановить. Если находятся какие-то баги, то всё откатывается, и мы начинаем с нуля.
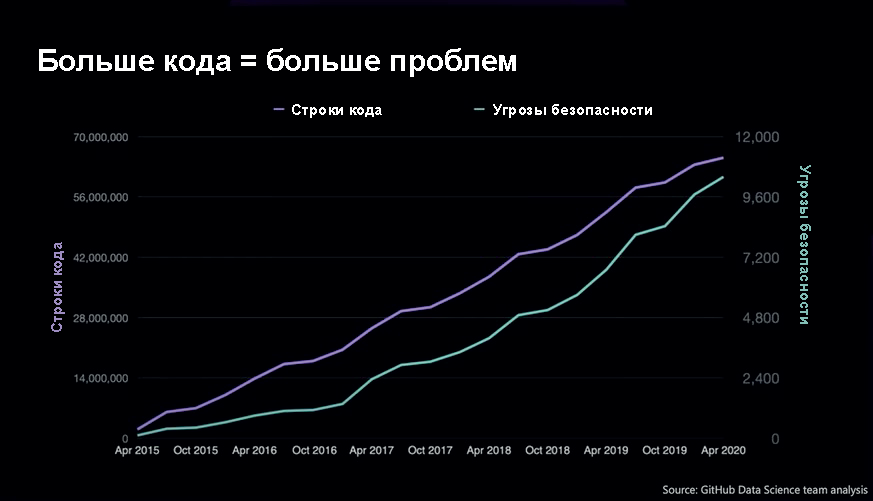
Еще одна вещь, которая очень важна, это безопасность цепочки поставок ПО, то есть сдвиг в сторону безопасности во время разработки. В GItHub провели исследование: чем больше кода мы пишем, тем больше проблем создаём. Фактически, мы не учимся на ошибках. Количество строк кода сильно коррелирует с угрозами безопасности.
И поэтому мы хотим включать как можно больше безопасности в наш цикл поставки ПО. И в коммиты, и в непрерывную интеграцию, и в непрерывную доставку, и после этого в анализ и т. д.
Говорить об этом можно долго, но эта тема выходит за рамки моего доклада Если вам интересно, то можете погуглить и поискать видео и документацию.
Создавайте для отказоустойчивости
Мы говорили о том, что выпускали ПО на DVD, а потом клиенты устанавливали и управляли серверами. И нам нужно было научиться, как запускать приложения в продакшн, то есть как справляться с инцидентами, поддерживать SLA и т. д.
Благодаря этому мы кое-чему научились, например тому, что нужно быть как можно более прозрачными с нашими клиентами. Когда есть инциденты в продакшене, не надо пытаться скрыть, что случилось. Мы научились обрабатывать инциденты на живой площадке, измерять и улучшать, учиться на ошибках и улучшать следующие этапы.

Наша дорога к DevOps продолжается, и сейчас, например, мы учимся удалённой работе. И сделать это нужно было очень быстро — перевести 150 тысяч сотрудников в марте 2019-го. Как сказал Сатья Наделла, нужно было очень быстро научиться тому, как работать удалённо и пройти двухлетнюю цифровую трансформацию за два месяца. Об этом тоже можно говорить очень долго.
Ещё мы работаем, например, над разработкой MLOps — практик машинного обучения, которые включают в себя DevOps. Microsoft работает над тем, чтобы поставить в облако Azure машинное обучение и иметь возможность добавить элементы пайплайна CI/CD в МО.
Мы также работаем над тем, чтобы обеспечивать ответственный жизненный цикл ИИ, потому что сейчас очень важно, чтобы ИИ тоже был ответственным и не был основан на предрассудках, так как он много где задействован в нашей повседневной жизни. Будущее более инновационно, чем когда-либо, мы живем в будущем и продолжаем двигаться к новым замечательным этапам.
Путь из тысячи километров начинается с одного спринта. DevOps — это не магия.
Спасибо большое за внимание! Больше информации по теме есть на странице The DevOps journey at Microsoft.
Сейчас Саша работает уже не в GitHub, а в Red Hat. Но по-прежнему выступает у нас на DevOops: в ноябре снова проведём конференцию, и там она представит доклад «SRE, Managed Services and the path to the future».
А помимо этого, там будет и много других докладов: и про конкретные инструменты (Kubernetes, Helm, GitHub Actions), и про общие подходы.
В общем, если тема DevOps интересна вам не только в отношении «что делают в Microsoft», но и в отношении «что делать нам», то на DevOops 2021 вам будет интересно. Конференция пройдёт 8–11 ноября в онлайне, более подробная информация и билеты — на сайте.
