Comments 56
Прочитал с упоением, вообще возбуждаюсь от такого рода занятий как сборка и настройка железа.
Спасибо!
комментарий удален автором
В тексте статьи проскакивают цифры близкие к 1Т.
Почему близкие, на пике трафик по кластеру был 15TB/s
Будут ли фотографии ваших суперкомпьютеров доступны для неограниченного использования по свободной лицензии?
Спасибо.
Спасибо, интересно. Вопрос: в рейтинге топ-500 не указана ваша энергоэффективность. Вы не делали замеров?
Меряли, но почему-то забыли добавить данные, сейчас уже боюсь соврать по какой причине. Вообще на сайте https://yandex.ru/supercomputers есть данные по средней потребляемой мощности. На Червоненкис во время теста на пике был 1.01MW, Ляпунов в пике 530kW. В следующем июньском рейтинге добавим.
Да, это вам не pytorch syntetic benchmark на паре Tyan 8x2080ti PCIe3 2x10Gbit гонять, ради таких штук в Яндекс вернуться можно :).
Когда с 16.04 то переедете и на что?..
Например, оказалось, что большинство стандартных утилит для работы с HPC (High Performance Computing) поддерживают только IPv4. Яндекс, в свою очередь, уже много лет живёт в дата-центрах IPv6-only.
Пытался через openmpi году примерно в 2016м запустить ipycluster на нодах hahn, не осилил :).
хэшрейт-то какой?
Очень круто! По ходу чтения появилось пару вопрсоов:
90 GB/s в all-reduce тестах удалось достичь при запуске теста на всех 137 машинах (т.е. используя 137 * 8 = 1,096 карт)?
Если это не является коммерческой тайной, то какие бенчмарки вы запускали что-бы оценить 4 vs 8 сетевых карт на узел? В частности, оценивали ли вы, например, влияние конфигурации с 4ми картами на узел на тренировку таких моделей, как GPT-3 (Megatron-LM), в которой есть все 3 типа паралелизма (tensor/pipeline/data) и которой нужно 16 узлов с 8 GPU каждой для одной реплики?
(1) 90GB/s был получен в момент когда у нас было всего 64хоста и сразу-же отдали в продакшен потому что время поджимало. Остальные подключили через пару недель . В этом и была наша ошибка. Если бы стали прогонять на всех машинах то скорее всего поймали-бы баг c adaptive-route-ами.
(2) Очень хороший вопрос, у нас чуть хитрее тест выглядел, так как у нас все хосты уже собраны с 4сетевыми карточками, поэтому мы делали обратный тест. Сравнивали результаты где на хосте используется только 4GPU, и 8 GPU, тоесть в первом случае у нас получалось соотношение GPU:NET 1:1. На linpack разница получалась ~3%. Коллеги из ML хотели сделать такой-же эксперимент на Megatron-LM, но результат я не знаю. Но раз не пришли ругаться значит значительной разницы не заметили.
Для небольшого телеграм-бота не хватило места на этих суперкомпьютерах :(
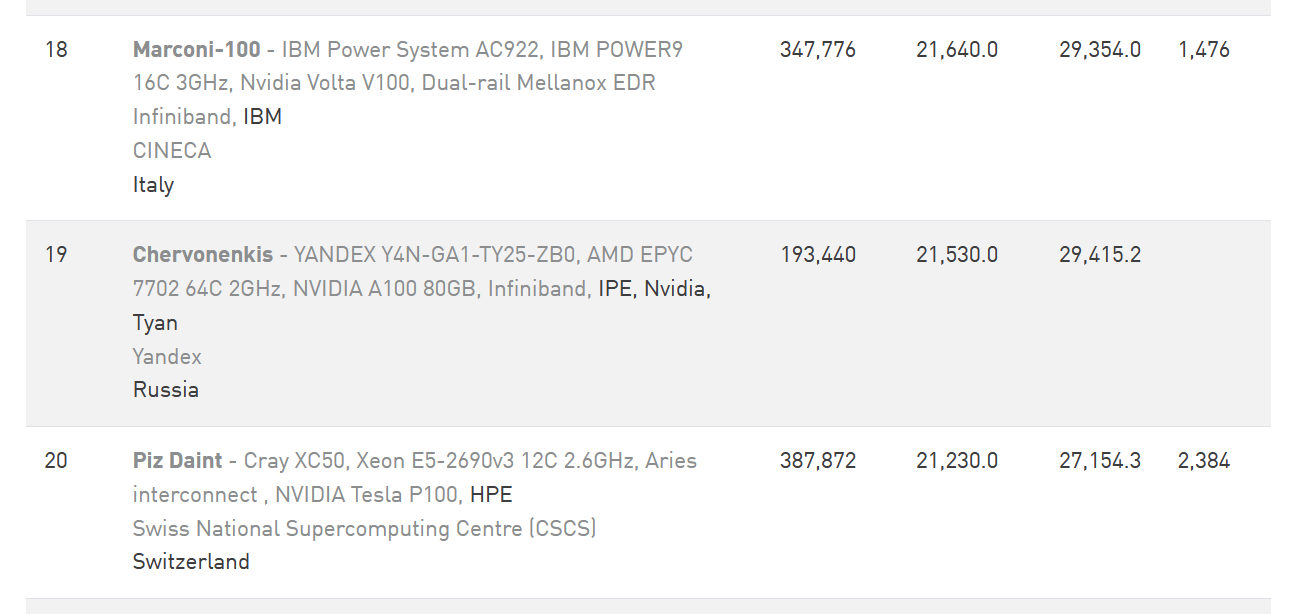
Кстати, составители рейтинга ошиблись в графе Manufacturer, теперь поправили и теперь все правильно: YANDEX,NVIDIA: https://www.top500.org/system/180029/
Читали "Жизнь 3.0" Тегмарка?
Не сочтите за наглую рекламу, но раз уж речь пошла про суперкомпьютеры, то стоит упомянуть одно мероприятие. Национальный Суперкомпьютерный Форум, который скоро будет проходить уже в десятый раз в Институте программных систем им. А.К. Айламазяна РАН (Переславль-Залесский). Он посвящен различным аспектам суперкомпьютерной отрасли, в том числе вопросам машинного обучения. Неплохая площадка для общения со специалистами, налаживания контактов между компаниями. Подать доклад уже не выйдет, так как прошли сроки, а вот приехать послушать вполне возможно. Пандемия накладывает ряд ограничений на подобные мероприятия, так что мы работаем с возможностью участия онлайн (Zoom) и ведем трансляцию докладов на YouTube (уже не первый год, записи докладов можно посмотреть по ссылке https://www.youtube.com/channel/UC1yFLfcOBeqHRTeZgs3UCzA).
P.S. Пора бы мне написать небольшую статейку про то, как мы ведем трансляцию конференции. Думаю, местной аудитории будет интересно. Да и чего полезного может подскажут.
Через nvidia-smi сборка метрик и в правду очень не бесплатна, особенно на Теслах. Для этих целей лучше использовать NVML (биндинг на Go) и писать свой экспортер делая 1 раз Initialize на старте.
У автора биндинга есть готовый экспортер для Prometheus (можно в коде подглядеть как и что), но там, как минимум, не было метрик по NVENC/NVDEC.
Да, именно в этом и была проблема, у нас уже есть центральный хостовый демон типа dcgm который управляет gpu через nvml и у него все эти метрики есть, но параллельно еще другие сервисы написали свой код который для простоты зовет nvidia-smi, раз в несколько секунд. Тоесть по факту они делали лишную работу, проще было у демона по unix-socket-у получить эту статистику. Я привел этот случай в качестве примера том как простой казалось бы баг может стоит 3-4%
Как видно из top500.org, не все кластеры используют Mellanox Infiniband, есть ещё некоторые стандартные или совсем кастомные интерконнекты: Tofu, Sunway, TH Express-2, Slingshot-10, Atos BXI V2, Aries interconnect, Intel Omni-Path, ...
Раз уж вы строите свои кластеры, то не пробовали пойти ещё глубже и реализовать собственный интерконнект или соединять сервера напрямую по PCI-Express 4.0 x 128 lanes через PLX PCIe-switch, который поддерживает virtual Ethernet NICs, NIC DMA and Tunneled Window Connection (TWC) http://www.alexeyab.com/2017/04/the-fastest-interconnect-for-hundreds.html
В принципе, даже в одну PCIe сеть можно объединить множество CPU и GPU без Ethernet/Infiniband, гораздо больше, чем 8.
Чтобы использовать
GPU-nVLink-GPU-CPU -> PCIe -> CPU-GPU-nVLink-GPU или
GPU-nVLink-GPU -> PCIe -> GPU-nVLink-GPU
вместо
GPU-nVLink-GPU-CPU -> PCIe -> Infiniband -> PCIe -> CPU-GPU-nVLink-GPU
Эта цепочка не правильная:
GPU-nVLink-GPU-CPU -> PCIe -> Infiniband -> PCIe -> CPU-GPU-nVLink-GPU
Используется RDMA, это значит данные идут напрямую из GPU на Infiniband, а не через CPU:
GPU-nVLink-GPU -> PCIe -> Infiniband -> PCIe -> GPU-nVLink-GPU
Если не используется PCIe-switch, как было предложено, то GPU и Infiniband физически подключены не напрямую, а через CPU, поэтому не могут обойти CPU в принципе. В этом случае RDMA позволяет обойти RAM и ожидание свободных CPU-Cores, но всегда использует CPU-PCIe-Controller.
CPU состоит из (Cores, Cache L1/L2/L3, North Bridge (PCIe-controller, ...), ...).
Без RDMA и Без PLX-PCIe-switch, сигнал идет:
GPU->PCIe->CPU(PCIe-controller)->CPU(RAM/cache-L3)->CPU(Core)->CPU(PCIe-controller)->PCIe->Infiniband->PCIe->CPU(PCIe-controller)->CPU(RAM/cache-L3)->CPU(Core)->CPU(PCIe-controller)->PCIe->GPU
(CPU-cache-L3 снупит данные, которые идут из GPU в CPU-RAM)
С RDMA и Без PLX-PCIe-switch, сигнал идет:
GPU->PCIe->CPU(PCIe-controller)->PCIe->Infiniband->PCIe->CPU(PCIe-controller)->PCIe->GPU
С RDMA и С PLX-PCIe-switch, сигнал идет:
GPU->PCIe->PLX-PCIe-switch->PCIe->GPU
или GPU->PCIe->PLX-PCIe-switch->PCIe->PLX-PCIe-switch->PCIe->GPU
С RDMA и Без PLX-PCIe-switch и Без Infiniband:
GPU->PCIe->CPU(PCIe-controller)->PCIe->GPU
или GPU->PCIe->CPU(PCIe-controller)->PCIe->CPU(PCIe-controller)->PCIe->GPU->...
Можно и сотни CPU, GPU и FPGA подключить между собой без Infiniband/Ethernet/PCI-switch/..., расшаривая Mapped Memory Windows через NTB PCIe-Bars. Вот 4 CPU подключены между собой по PCIe без Infiniband/Ethernet/PCI-switch/.... Эти окна физической памяти, в том числе память GPU-RAM по GPUDirect3.0, можно мапить в другой CPU и затем мапить через PT/VMA в виртуальную user-space, которая видна другому GPU по GPUDirect1.0(UVA) http://www.alexeyab.com/2017/04/the-fastest-interconnect-for-hundreds.html

Я могу ошибаться, но насколько я помню, North Bridge это часть чипсета, а не CPU. https://en.wikipedia.org/wiki/Northbridge_(computing)
А значит RDMA всё-таки не идёт череp CPU.
Плюс пару вопросов:
как подключать напрямую PCIe серверов, которые находятся в разных стойках?
Какая топология подключения будет, если всё подключать через PCIe?
Уже 10 лет как North Bridge интегрирован в CPU (Intel/AMD/...). По вашей же ссылке: Modern Intel Core processors have the northbridge integrated on the CPU die, where it is known as the uncore or system agent.
Два CPU соединяются между собой напрямую оптоволоконным PCIe-кабелем длинной 30 метров.
Можно Tree, например, CPU со 128 lanes PCIe4.0 = 256 GB/s = 2048 Gbit/s на CPU, две ветки вниз по 512 Gbit/s и одна вверх 1024 Gbit/s. Но CPU должен поддерживать NTB, иначе PCIe-switch-и нужны. Это может выглядеть или как обычная TCP/IP сеть IPoPCIe, или память всех CPU/GPU может выглядеть как обычные массив/массивы в user-space куда можно писать по raw-указателю: somearray[713] = 123. (Там есть пару нюансов с реальной битностью физической адресации CPU, и нюанс с QPI)
1) Я правильно понял, у вас из сервера выходит пачка кабелей c разъемами вродe slimsas 8i, подключенных с одной стороны прямо в материнскую плату сервера, с другой стороны в плату JBOG со свитчами?
2) Не видно, как устроено питание JBOG. Там есть блоки питания в корпусе или есть отдельно полки питания?
3) Подобные корпуса для JBOG существуют ли в фабричных вариантах, которые можно было бы купить?
2) Какая разница, где у Яндекса юрлицо? Работают-то конкретные люди в России, а не юрлицо.
Возможно, на рынке нет фрикулинга, зато есть погружное охлаждение.
И обслуживание самого оборудования затрудняет очень-очень сильно. Поэтому используется преимущественно для одноразовой техники, типа майнеров.
В обслуживании несколько сложнее, зато намного дешевле и позволяет отводить гораздо больше тепла.
Однако такая схема не может отводить очень уж много тепла, поэтому перешли к погружному охлаждению, когда герметичного радиатора нет, а электроника просто купается в жидкости.
Однако такая схема не может отводить очень уж много тепла, поэтому идут опыты по охлаждению фазовым переходом, когда электроника не только купается в жидкости, но жидкость кипит на охлаждаемом месте.
Tyan и Inspur вполне спокойно продаются на российском рынке ;)
Статья греет душу приятными воспоминаниями о работе в суперкомпьютерном центре одного НИИ. Так давно не следил за топ500, а тут Mellanox, Infiniband - помню на ощупь эти приятные коннекторы, провода. Помню шум в старом ДЦ и насколько же тише в серверной с жидкостным охлаждением...
Если не секрет, какой используете планировщик, что-то свое? Я так понимаю, режим загрузки вашего кластера - все мощности под одну задачу, потом под другую? Думаю, это сильно отличается от режима в НИИ, где часто людям выделялось по 1-2 узла на время от нескольких часов до нескольких дней.
Кстати, не думали ещё в рейтинге топ-50 суперкомпьютеров СНГ отметиться? На первом месте там сейчас Сбер с 6.7 петафлопс на Линпак. У вас вроде бы теперь все призовые места - не припомню таких масштабных смещений раньше) Максимум когда кто-то 1 новый кластер собирал и вырывался вперёд на пару строчек:
Планировщик задач у нас свой называется YT. Он чем то похож на SLURM. По факту это дефолтный job-процессор для большинства задач в яндекс. Забавно что до появления GPU-задач его очень долго оптимизировали для повышения общей утилизации ресурсов (cpu,mem,disk) на обычных задачах (компиляция, map-reduce), а в случае GPU-задач это оказалось вредным потому что минимальный недостаток CPU приводил к просадке RDMA. Так что тут было много интерестного. Зато теперь YT умеет решать обе задачи хорошо. У нас средний размер задач 1-4хоста. Ребята сначала отлаживаются, а потом уже запускают на большое количество нод.
В Российский top-50 заявились. скоро должно обновится
Суперкомпьютеры Яндекса: взгляд изнутри