В этой статье я покажу, как можно без программирования парсить, анализировать и визуализировать данные из RSS- и Atom-лент на примере загрузки и парсинга фида Apple iTunes, а также проведения последующего конкурентного анализа приложений. На самом деле, подобным образом можно загружать и анализировать данные из любых источников, которые возвращают их в форматах CSV, JSON или XML (включая REST API или SOAP-based сервисов).

Представим, что мы собираемся публиковать в App Store мобильное приложение по тематике “медитация”. И хотим посмотреть, как обстоят дела в этой нише.
Кто в топе?
Какие категории используют лидеры?
Какие цены?
Что с рейтингом и отзывами топовых приложений по странам?
Варианты локализаций?
и т.д.
При этом мы, конечно, ничего не знаем о существовании таких сервисов, как App Annie, Sensor Tower и аналогичных. Или знаем, но нам расхотелось делать в них детальный анализ, как только мы узнали стоимость месячной подписки. Поэтому будем действовать как экономные бутстрапперы и анализировать “сырые” данные от компании Apple. Тем более, что сделать это оказалось очень просто.
Если посмотреть на задачу конкурентного анализа более системно, то обычно она состоит из трёх этапов:
Найти, что конкуренты делают плохо или неправильно, и делать это хорошо, чтобы получить новых или текущих пользователей конкурента себе.
Выявить, что конкуренты делают хорошо, начать тоже это делать и стать более конкурентоспособным.
Найти то, что все (включая нас) делают одинаково, начать это делать по-другому, чтобы отстроиться.
Всё вроде бы несложно, но нам нужны данные.
Источники данных
Вернёмся к нашей исходной задаче. Для выполнения анализа конкурентов по тематике “медитация” нам нужен список приложений, которые есть в App Store. Самый простой и очевидный способ – сделать поиск по запросу “meditation” через интерфейс самого App Store и проанализировать результаты. Хотя и понятно, что это не оптимальный вариант: неудобно сравнивать параметры, нет возможности фильтровать/сортировать результаты, к тому же многие параметры, необходимые в анализе, просто не видны. Например, какие локализации есть у приложения. То есть нам нужен список атрибутов приложений в табличном виде. Сформировать таблицу – не проблема, вопрос в том, откуда выгрузить данные? С этим вопросом я пошёл в Google и после непродолжительного поиска нашёл два публично-доступных фида:
https://itunes.apple.com/search?term=meditation&entity=software&limit=200
https://itunes.apple.com/us/rss/customerreviews/page=1/id=1093360165/sortby=mostrecent/xml
Первый возвращает 200 найденных приложений по фразе, указанной в параметре “term”. Здесь формат выходных данных – JSON. Можно добавить параметр &country=ru и получить 200 записей по каждой стране, где ищется приложение, что уже неплохо.

Второй адрес – это список оценок и ревью для указанного приложения, у него поддерживается постраничная выдача по 50 записей, в общей сложности можно получить 500 свежих отзывов на приложение по каждой стране, где оно доступно. Формат вывода – XML, но можно заменить в адресе xml на json и получить JSON-массив. Говорят, что это какой-то неофициальный end-point. Не могу сказать наверняка, временами он сбоит и возвращает ошибку на запрос, но в целом – хорош для оперативного анализа. Насколько я понял, у него есть определенный rate limit, что-то около 20 запросов в минуту.

Кстати, есть ещё вот такой ресурс от Apple: https://rss.applemarketingtools.com/, это параметризованный генератор RSS-лент. Там тоже можно искать в App Store, но данных намного меньше, чем в RSS-ленте из iTunes. Поэтому он не подходит для ad hoc анализа, как и сам поиск в App Store.
Загрузка RSS-фида
Итак, источники данных у нас есть, теперь нужно перевести их в удобочитаемый вид, так как просматривать списки в форматах XML и JSON ещё более неудобно, чем в интерфейсе App Store.
Для загрузки и последующего анализа данных из текстовых файлов в форматах CSV, XML и JSON я использую сервис TABLUM.IO. Загрузка данных из файлов происходит в пару кликов (для локальных – просто перетащить файл на форму, для размещённых на удалённом сервере – через загрузчик “URL Downloader” по URL документа).

Поскольку результат поиска – это фид, доступный по URL, то для загрузки данных в TABLUM.IO будем использовать компонент “URL Downloader”.
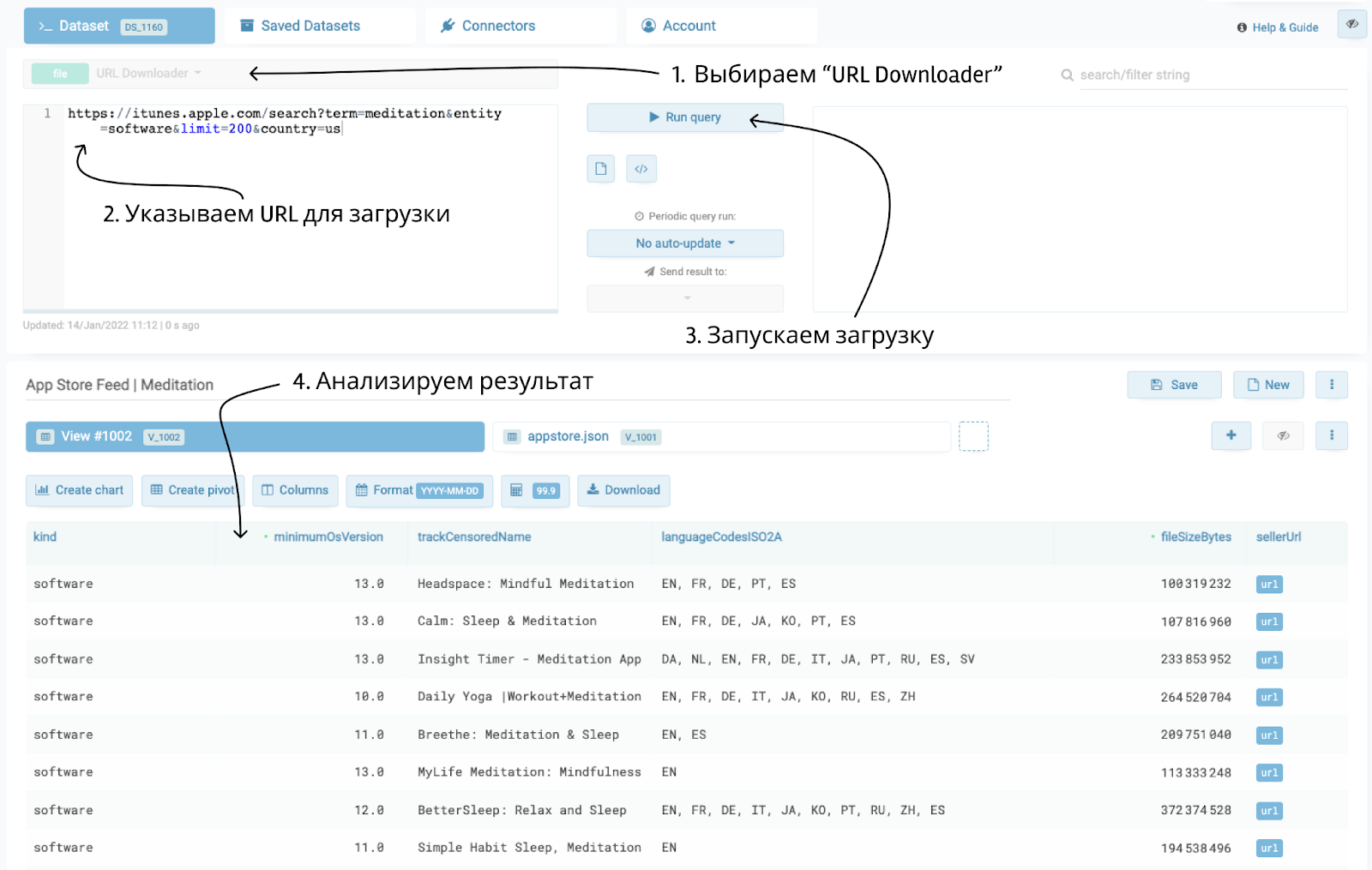
Это встроенный HTTP-клиент с возможностью загрузки и парсинга данных по URL, обогащённый набором параметров. С помощью него мы загрузим RSS-ленту с результатами поиска по нескольким странам сразу в общую таблицу. Он сам сделает парсинг, преобразует данные в реляционный вид, определит их типы и сохранит локально в виде таблицы.
Давайте посмотрим, какие данные доступны в результатах поиска:
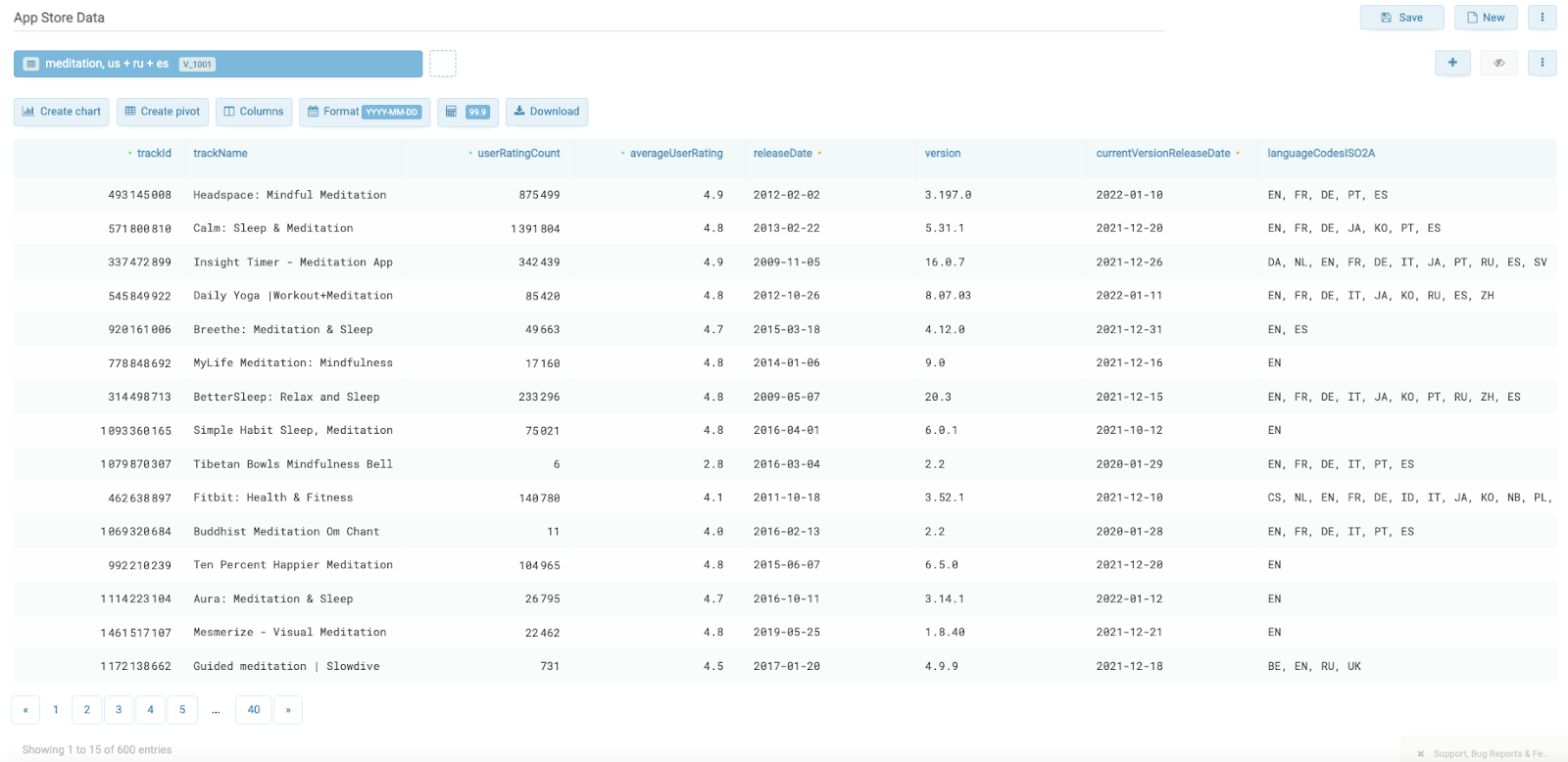
Я бы выделил следующие поля:
trackId – идентификатор приложения (его можно использовать в запросе на получение списка комментариев),
trackName – имя приложения (там есть ещё trackCensoredName, но оно чаще всего совпадает с trackName),
userRatingCount – число голосов в рейтинге,
averageUserRating – средний пользовательский рейтинг по данной стране,
releaseDate – дата релиза первой версии,
version – номер текущей версии приложения,
currentVersionReleaseDate – дата релиза самой свежей версии,
languageCodesISO2A – список стран (точнее, идентификаторов стран), где приложение доступно,
minimumOsVersion – минимальная версия операционки, на которой работает приложение,
genres – список категорий, в которых заявлено приложение (с локализацией)
primaryGenreName – основная категория приложения (на англ)
genreIds – то же, что genres, но в цифрах (удобно для анализа, потому что без локализации)
fileSizeBytes – размер приложения в байтах,
sellerName – компания-разработчик (или кто опубликовал),
formattedPrice – цена приложения с валютой,
price – цена приложения без валюты,
contentAdvisoryRating – возрастной рейтинг приложения,
averageUserRatingForCurrentVerion – пользовательский рейтинг приложения для самой свежей версии,
userRatingCountForCurrentVersion – число голосов в рейтинге для самой свежей версии,
trackContentRating – возрастной рейтинг контента,
bundleId – ID установочного пакета,
sellerUrl – адрес сайта-разработчика,
supportedDevices – список поддерживаемых платформ
В самом фиде полей больше (там есть всякие URL скриншотов, артворки, внутренние идентификаторы, и т.п.), но я не придумал, как с пользой можно их применить, поэтому пропущу.
Параметры загрузчика
Для загрузки данных в табличном виде будем использовать следующих запрос (можете просто скопировать его в форму компонента URL Downloader):
https://itunes.apple.com/search?term=meditation&entity=software&limit=200&country={{loop}}
foreach="us,ru,es"
cols="trackId, trackName, userRatingCount, averageUserRating, releaseDate, version, currentVersionReleaseDate, languageCodesISO2A, minimumOsVersion, genres, primaryGenreName, genreIds, fileSizeBytes, sellerName, formattedPrice, price, contentAdvisoryRating, userRatingCountForCurrentVersion, averageUserRatingForCurrentVersion, trackContentRating, userRatingCountForCurrentVersi, bundleId, sellerUrl, supportedDevices"
extract='contentAdvisoryRating, (\d+)'
extract='trackContentRating, (\d+)'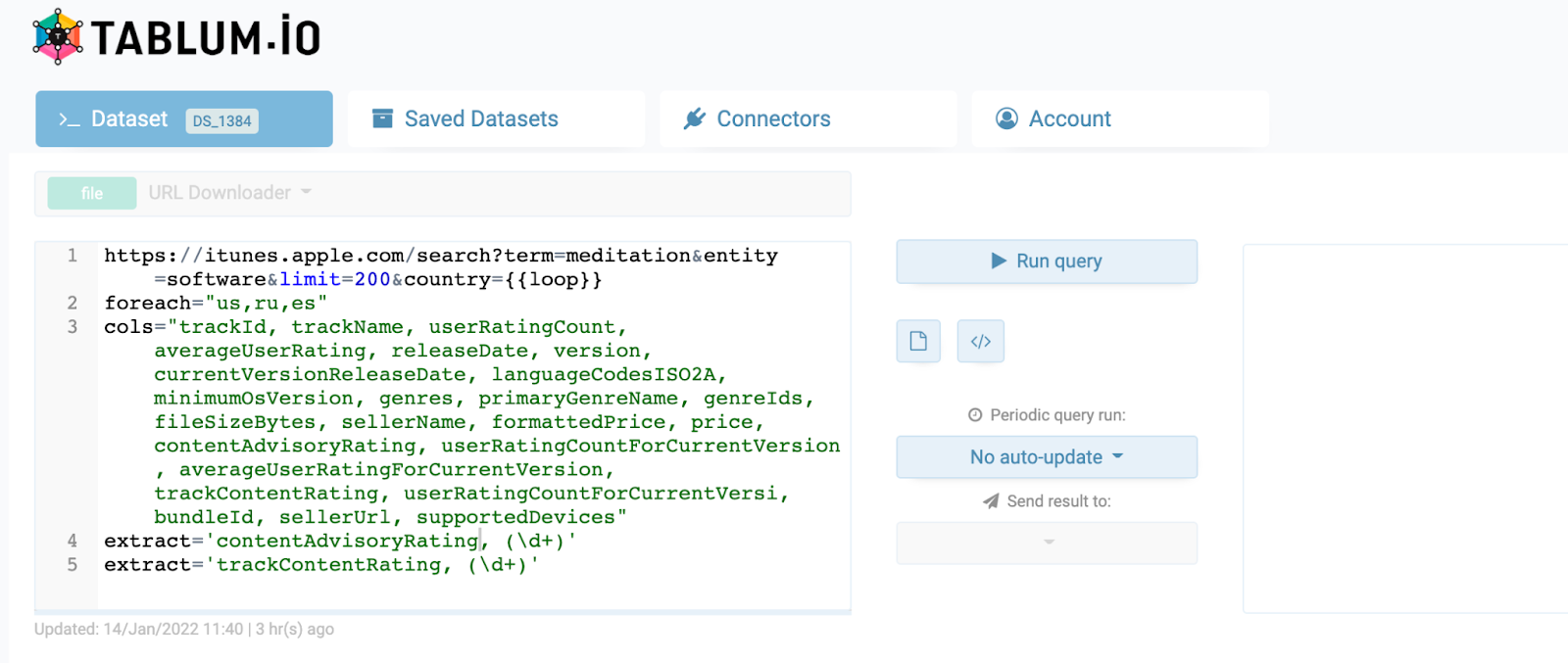
Первая строка – это URL фида. Поскольку мы загружаем его по нескольким странам (us, ru, es), то используем цикл и параметр {{loop}}, который на каждой итерации будет приобретать соответствующее значение.
Вторая строка (foreach=”...”) – это параметр цикла, то есть те самые значения “us”, “ru”, “es”.
Третья строка (cols=”...”) – список столбцов и их порядок, которые следует загружать (нам не нужны все поля из RSS-ленты).
Четвертая и пятые строки (extract=”...”) – это трансформер данных на основе регулярных выражений. В ленте значения contentAdvisoryRating и trackContentRating возвращаются как строковые значения (“18+”, “4+”), а мы хотим преобразовать их в число без знака “+”, поэтому говорим, что нужно из всей строки взять только числовое значение. Более подробно параметры “URL Downloader” описаны в документации: https://help.tablum.io/?#heading=h.6biizlbt9l0f
Анализ загруженных данных
Итак, у нас появились данные в удобном табличном виде, самое время заняться анализом конкурентов, посмотреть их сильные и слабые стороны, найти для себя возможности или точки роста. Смотрим топ выдачи по странам, разбираемся – почему они там оказались:
Заголовок. Как оформлен заголовок: длина заголовка, ключевые слова, используется ли максимально доступный лимит на длину заголовка.
Категории. Какая основная и дополнительные категории топовых приложений. Посмотреть, как это сделано у конкурентов. Например, Calm и Headspace находятся в Health & Fitness, но дополнительные категории у них разные: у Calm – Lifestyle, у Headspace – Productivity. Найдите релевантные вашему приложению, посмотрите, кто ещё в той же подкатегории, или наоборот, куда точно не следует размещаться, потому что там сильный конкурент.

Локализация. На каких языках доступен интерфейс. Например, у Calm на две локализации больше, чем у Headspace (есть японский и корейский языки). И у обоих, кстати, нет русского. Это тоже может быть вашим конкурентным преимуществом.

Операционные системы. Какая операционная система и платформа поддерживаются приложением. Например, для некоторых приложений может быть конкурентным преимуществом наличие версии для iWatch. Здесь же стоит посмотреть поле minimumOsVersion. Возможно, вы получите доп. преимущество, если будете работать на древних версиях операционки.
Цена. Найти платные аналоги, посмотреть, как у них обстоят дела (рейтинг, загрузки, отзывы), где они в результатах поиска. Посмотреть бесплатные из тех же категорий, сравнить и определиться с вариантами монетизации. К сожалению, в этом фиде я не нашел данных об In-App Purchase, это бы дало дополнительную информацию при конкурентном анализе. Если нужно смотреть более детально, то стоит обратиться уже к специализированным сервисам, которые спарсили весь App Store и продают к нему интерфейс.

Рейтинг и число отзывов. Вполне очевидный критерий для анализа: посмотреть, сколько всего отзывов, средний рейтинг по странам и категориям. К сожалению, также не смог найти в этом фиде рейтинг по фичам и рейтинг по отзывам, поэтому или довольствуемся тем, что есть, или покупаем платный аккаунт в специализированных сервисах.



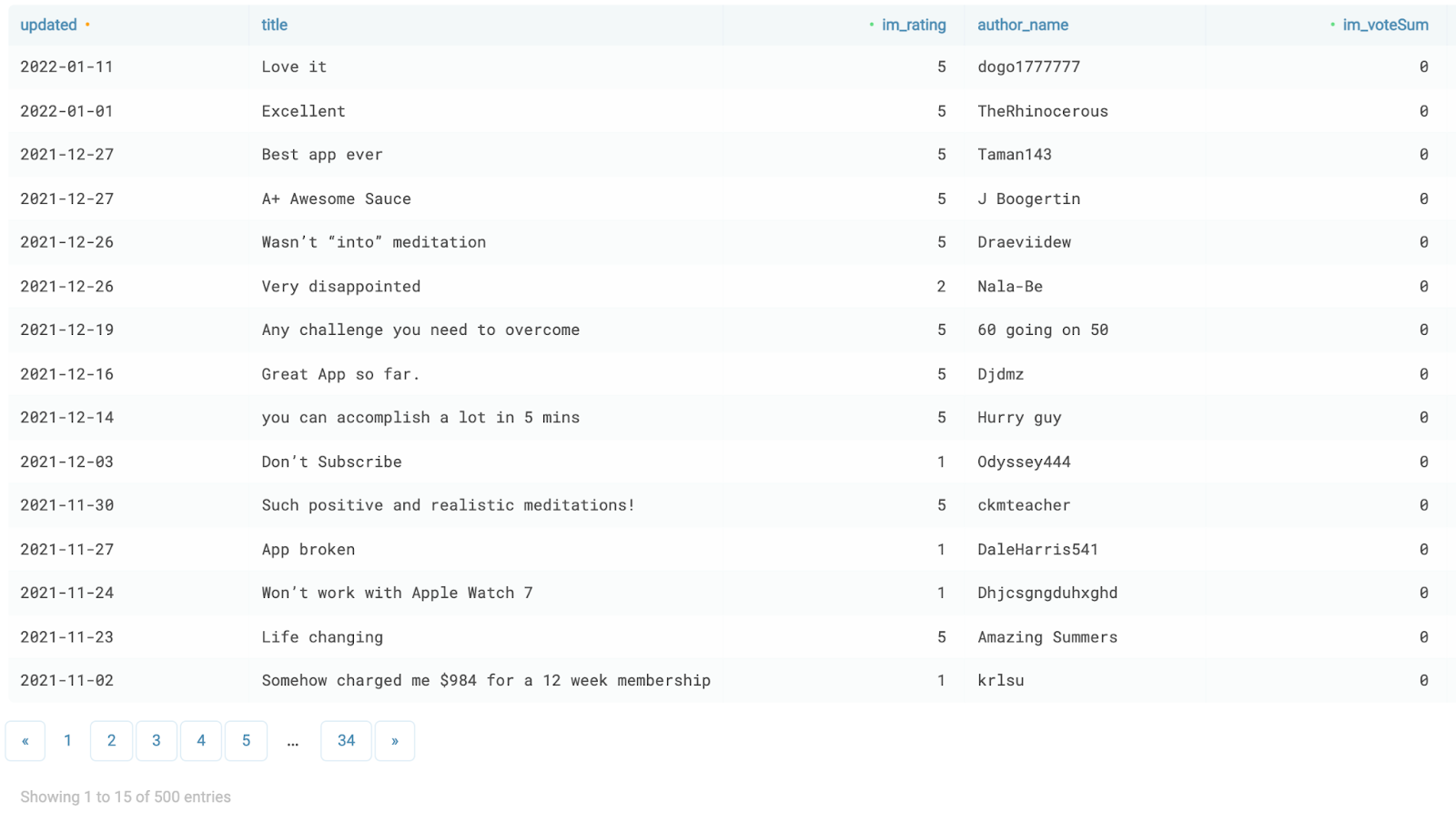
По отзывам можно получить расширенную выдачу, используя второй фид, который я упоминал выше. Для этого берем trackId приложения и в отдельном View сервиса TABLUM.IO выгружаем его по странам (в данном примере trackId = 1093360165 для “Simple Habit Sleep…” и выгружаются по 50 отзывов из США, России и Испании в общую таблицу):
https://itunes.apple.com/{{loop}}/rss/customerreviews/page=1/id=1093360165/sortby=mostrecent/xml
foreach="us,ru,es"
cols="updated,title,im_rating,author_name,im_voteSum, im_voteCount,content_0,im_version"

В поле im_rating будет оценка от 1 до 5 и текст отзыва (как краткий, так и полный). Можно посмотреть, что и в каких странах пользователям нравится в приложении, и к чему претензии (сортируем по столбцу im_rating и читаем). По-умолчанию, возвращается 50 отзывов на запрос. Если делать итерации по одной стране, то можно получить 500 записей. Запрос должен быть такой:
https://itunes.apple.com/us/rss/customerreviews/page={{loop}}/id=1093360165/sortby=mostrecent/xml
loop="1,1,10"
cols="updated,title,im_rating,author_name,im_voteSum, im_voteCount,content_0,im_version"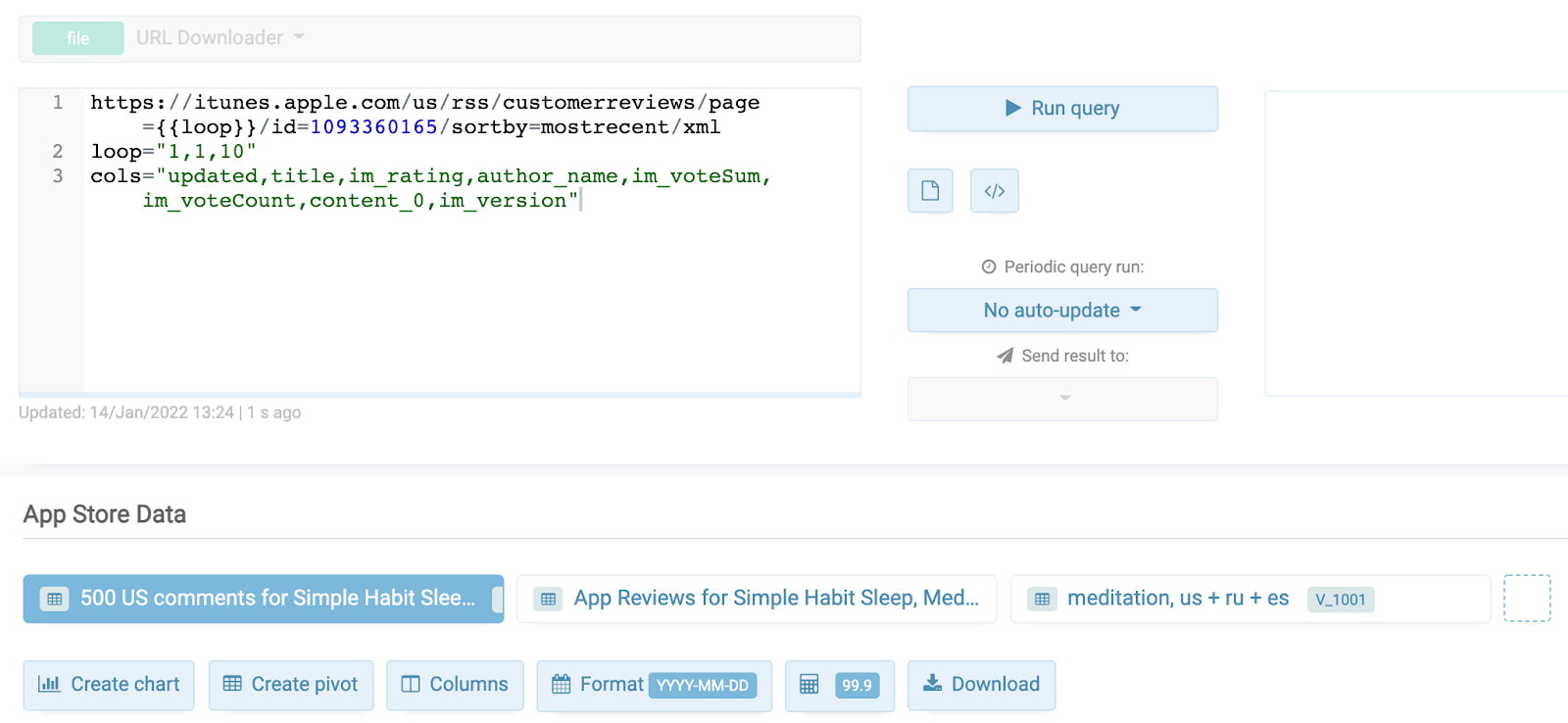
Кстати, забавно читать отзывы на приложение Excel for iPad. Я еще ни разу не встречал столько негатива в одном месте (причем, про все локализации).
Чего нет в открытом фиде, но будет не лишним также посмотреть при конкурентном анализе:
Информацию по In-app Purchase и стоимость подписки.
Наличие промо баннера у приложения.
Интерфейс
Несколько слов о работе с таблицами в сервисе TABLUM.IO. Большинство простых операций можно выполнить кликами мыши. Например, сортировка по значениям в столбце делается в выпадающем окне при клике по заголовку столбца:

Сводную статистику (например, кол-во уникальных значений, среднее, мин/макс) можно получить в выпадающем меню, выбрав пункт “SUM, COUNT, MIN, MAX…”.
Чтобы сформировать отдельный список уникальных значений из столбца – достаточно выбрать в меню пункт “Select Unique Values”. А чтобы вас не смущала консоль с SQL запросом, просто сверните ее иконкой в правом верхнем углу:

Иногда полезно построить сводную таблицу, чтобы получить выборку по каким-то группам. Например, при анализе рейтинга приложения можно посмотреть динамику оценок по месяцам. Для этого в таблице кликаем по кнопке “Create pivot” и выбираем, какие поля будут использоваться для группировки. В примере выше я выбираю следующее:
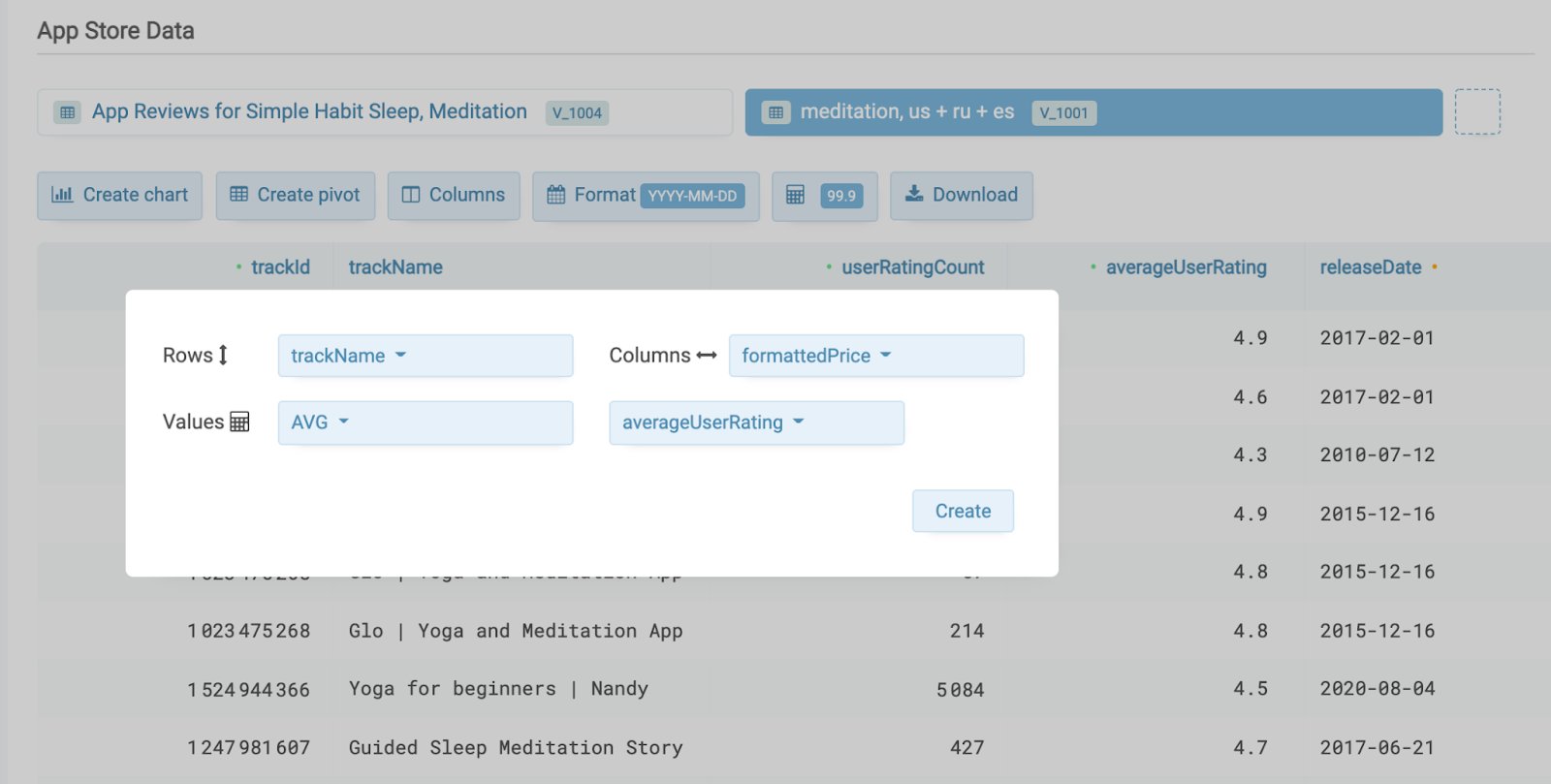

Но динамику оценок все-таки удобнее смотреть на графике, поэтому в сводной таблице кликаем по “Create chart” и строим график. Выбираем тип Column Chart и все пять столбцов для отображения на оси Y.
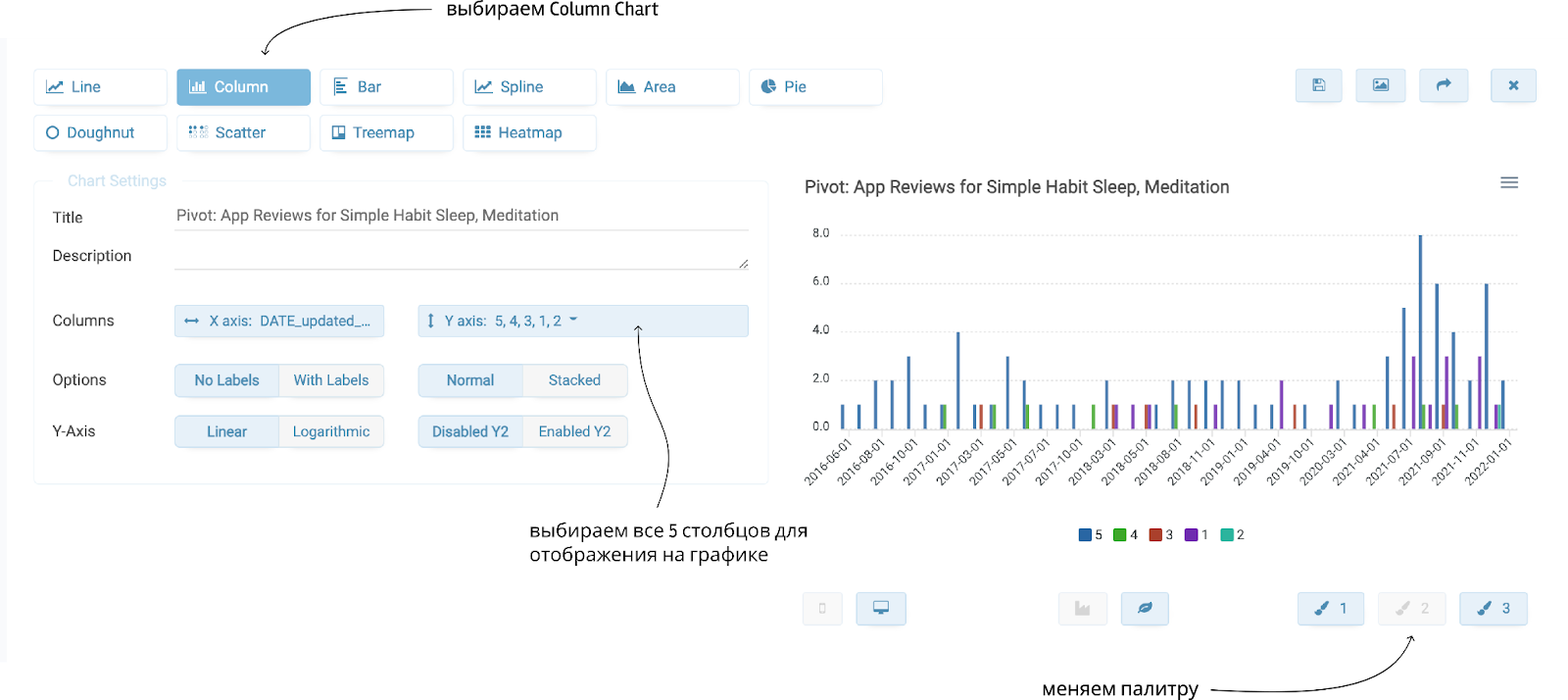
На графике видно, что с июля 2021 года выросло число положительных отзывов, а максимальное было в августе (интересно, что там произошло? Может быть релиз какой-то полезной фичи? Какой?)
Продвинутый анализ с помощью SQL
Стоит отметить, что таблица c загруженными данными в TABLUM.IO – это реляционная база данных, с которой можно работать запросами SQL (используя диалект SQLite). Если вы знакомы с синтаксисом SQL, то сможете существенно шире посмотреть на набор данных и “покрутить” его ещё более детально для получения новых инсайтов. Покажу на нескольких примерах.
Выбираем все данные по конкретному приложению и сравниваем показатели в разных странах:
SELECT * FROM DS_.V_1001 where trackId = '493145008' 
Можно заметить, что у испанских пользователей оценка Headspace ниже, чем у американских и российских. Интересно, почему? Также мы видим, что заголовок в русской версии не локализован Возможно, его следовало бы локализовать для лучшего поиска.
Следующим запросом можно получить таблицу с возрастом приложения (разница в днях между первым и последним релизами).
SELECT
trackId,
trackName,
releaseDate,
currentVersionReleaseDate,
(julianday(currentVersionReleaseDate) - julianday(releaseDate)) as age
FROM
DS_.V_1001По этой выборке можно смотреть “новичков”, кто зарелизился недавно, и “старожилов”. У последних, если они в топе, есть чему поучиться.
Можно найти все неудачные приложения, у которых оценка ниже 3.0 и было как минимум 10 отзывов (чтобы исключить “новичков”):
SELECT * from DS_.V_1001
WHERE averageUserRating < 3 AND userRatingCount > 10
ORDER BY averageUserRating“Заминусованных” на удивление оказалось не так много. CorePower Yoga – лидер по негативу: 1200 оценок, рейтинг 1.6. Это надо было постараться! (особенно учитывая то, что оно бесплатное)

Эпилог
Статья получилась объемная, поэтому если вы дочитали до конца – вы большой молодец и мой герой! )
Надеюсь, что примеры были достаточно иллюстративны и вы сможете самостоятельно выполнять описанные действия. Попробуйте сделать это в TABLUM.IO для ваших текущих задач.
Если вы интересуетесь судьбой проекта TABLUM.IO, подписывайтесь на русскоязычный канал в телеграме.
