Всем привет! Меня зовут Игорь Дергунов и я руководитель инновационной лаборатории Digital Design, которая занимается оптимизацией бизнес-процессов с помощью методов машинного обучения. В процессе работы над проектами в данной сфере быстро приходит осознание необходимости учета и структурирования проводимых экспериментов. В нашем случае мы воспользовались инструментом MLflow, который предоставляет функциональность для отслеживания экспериментов и управления жизненным циклом моделей машинного обучения.
И все шло хорошо, результаты проверки гипотез (параметры обучения, метрики, артефакты и модели) сохранялись, их было удобно наглядно сравнивать, и все были довольны. Так продолжалось достаточно долгое время, пока не возникла необходимость вернуться к эксперименту, который выполнялся какое-то время назад и был приостановлен.
В этот момент может выясниться, что несмотря на залогированные артефакты, получить модель, которая выдаст тот же результат, сложно или даже невозможно. А нам бы хотелось, чтобы эксперименты были воспроизводимы, ведь в прошлый раз были получены обнадеживающие метрики, достаточные для запуска пилотного проекта.

Причин невозможности воспроизводимости эксперимента может быть множество. Например, по артефактам эксперимента невозможно определить:
Полный набор использованных параметров
В каком окружении проводился эксперимент
Какой код был использован для обучения модели
Какой датасет использовался, и каким образом подготавливались данные
Наличие ссылки на репозиторий, в котором содержится код, использованный для подготовки данных и обучения, тоже не является гарантией воспроизводимости. Ведь существует человеческий фактор, и перед конкретным запуском в код могли быть внесены изменения, которые не отразили в системе контроля версий.
В данной статье мы рассмотрим, как, используя функционал MLflow project, сохранить необходимую информацию, чтобы повысить воспроизводимость ML экспериментов.
Что такое Mlflow?
MLflow — это набор инструментов с открытым исходным кодом, которые помогают управлять жизненным циклом разработки модели машинного обучения, начиная с ранних экспериментов и заканчивая регистрацией модели в специальном репозитории для дальнейшего развертывания ее в качестве REST endpoint-а с целью осуществления предсказаний в реальном времени.
MLflow состоит из 4 основных компонентов.
Mlflow Tracking
Это API для фиксации параметров, метрик и прочих артефактов при запуске экспериментов по машинному обучению, а также пользовательский интерфейс для визуализации полученных результатов. MLflow Tracking позволяет сохранять результаты экспериментов и запрашивать их с помощью API Python, REST, R API и Java API.
Основная концепция MLflow Tracking run - единичная итерация эксперимента. Также в MLflow присутствует понятие Experiment, который позволяет логически сгруппировать несколько запусков (run).

Каждый run содержит следующую информацию:
Code Version — хэш гит коммита.
Start & End Time — время начала и завершения run.
Source — имя файла, с помощью которого был запущен run, или название проекта и entrypoint, если run был запущен с помощью MLflow Project.
Parameters — пары входных параметров в формате ключ-значение.
Metrics — значение метрик в формате ключ-значение. Метрики могут изменяться в ходе выполнения run (например, можно отслеживать изменение функции потерь), а MLflow позволяет логировать данные изменения и визуализировать историю изменений в виде графика.
Artifacts — файлы в произвольном формате. Например, могут быть залогированы полученные модели в pickle формате или картинка с полученной матрицей ошибок в формате png.
MLflow Models
Это стандартный формат для упаковки и хранения моделей машинного обучения. Он использует концепцию flavor - своего рода обертку, которая позволяет использовать модель в различных инструментах и фреймворках без необходимости дополнительных интеграций. MLflow Models позволяет использовать модели из Scikit-learn, Keras, TenserFlow, и других популярных фреймворков.
Также MLflow Models позволяет публиковать модели по REST API или упаковывать их в Docker-образ.
MLflow Registry
Это централизованное хранилище моделей, набор API, а также пользовательский интерфейс для управления полным жизненным циклом модели MLflow. Он позволяет отслеживать происхождение модели (какой эксперимент и run создали модель), обеспечивает управление версиями модели и осуществляет переходы между этапами жизненного цикла модели. В контексте MLflow есть три стадии жизненного цикла: Staging, Production и Archived.
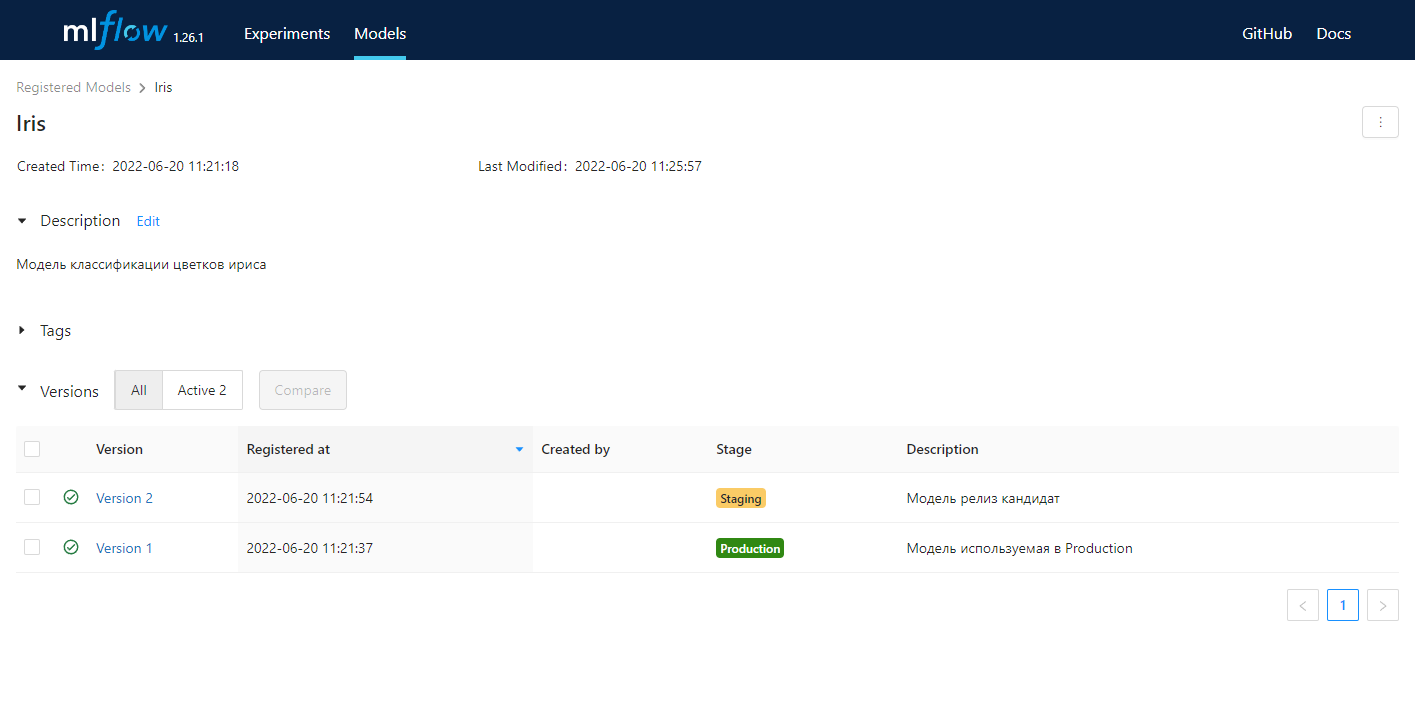
Используя удобный UI можно сравнивать разные версии моделей между собой, отображая только те строки, в которых есть различия. Таким образом, можно сравнить параметры обучения моделей и полученные метрики.
MLflow Projects
По сути, MLflow Projects — это соглашение для организации и описания вашего кода, позволяющее другим членам команды (или автоматизированным инструментам) запускать его. Каждый проект — это просто каталог файлов или репозиторий Git, содержащий ваш код. Проект содержит файл MLProject в формате yaml, в котором описываются основные атрибуты проекта: имя проекта, окружение для запуска и entrypoints - сценарии запуска проекта. Запустить проект можно используя CLI или API для Python.
В данной статье мы не будем рассматривать MLflow Registry и MLflow Models. Мы сосредоточимся на Mlflow Project для создания переиспользуемого параметризированного модуля, при запуске которого будут фиксироваться параметры и окружение запуска для возможности простого воспроизведения полученных результатов. Также мы будем использовать Mlflow Tracking для отслеживания запусков проекта.
Разворачиваем MLflow
Для начального запуска проектов нам потребуется python с установленными библиотеками mlflow, scikit-learn и matplotlib. Данные библиотеки можно установить с помощью pip.
requirements.txt
scikit-learn==1.1.1
matplotlib==3.5.2
mlflow==1.26.1
pip install -r requirements.txtТакже нам потребуется docker для развертывания MLflow сервера и в дальнейшем для запуска MLflow Project. Подготовить докер-образ с MLflow можно, используя следующий Dockerfile:
FROM python:3.9.13-slim
WORKDIR /app
RUN pip install --upgrade pip && \
pip install --no-cache-dir 'mlflow==1.26.1'
CMD mlflow server \
--backend-store-uri sqlite:////app/mlruns.db \
--default-artifact-root $ARTIFACT_ROOT \
--host 0.0.0.0Обратим внимание на дополнительные параметры, которые передаются в команду запуска mlflow server:
backend-store-uri - задает путь, где будет храниться информация о runs и experiments (может быть путь до базы или путь на файловой системе). Для простоты будем использовать локальную базу данных - sqlite, которую будем маппить через volume.
default-artifact-root - каталог для хранения артефактов для новых созданных экспериментов. Так как планируется использовать SQL бэкенд для хранения, то этот параметр является обязательным. Данный параметр будем брать из переменной окружения. Есть ряд альтернатив для хранения артефактов, в нашем примере будет использован FTP.
host - по умолчанию используется 127.0.0.1, но так как mlflow сервер запускается в докере, мы используем 0.0.0.0, чтобы получить доступ к Mlflow Tracking с хостовой машины.
Чтобы собрать образ с именем mlflow выполним команду:
docker build -f mlflow.dockerfile -t mlflow .Для корректной работы mlflow нам необходимо место для сохранения артефактов. Мы будем использовать FTP сервер, который также развернем в контейнере на базе образа stilliard/pure-ftpd. Для поднятия контейнеров с mlflow и с FTP сервером воспользуемся docker-compose:
version: '3.7'
services:
mlflow:
image: mlflow:latest
container_name: mlflow
environment:
- ARTIFACT_ROOT=ftp://mlflow:mlflow_password@${HOST_IP}/data
ports:
- "5000:5000"
volumes:
- D:\DockerData\volumes\mlflow:/app
depends_on:
- ftpd_server
ftpd_server:
image: stilliard/pure-ftpd:latest
container_name: ftpd_server
environment:
- FTP_USER_NAME=mlflow
- FTP_USER_PASS=mlflow_password
- FTP_USER_HOME=/home/ftpusers/mlflow
- PUBLICHOST=${HOST_IP}
ports:
- "21:21"
- "30000-30009:30000-30009"
volumes:
- D:\DockerData\volumes\ftp:/home/ftpusersВ определении переменных окружения PUBLICHOST и в ARTIFACT_ROOT присутствует IP адрес HOST_IP - это должен быть IP адрес хостовой машины. Его также можно задать через переменную окружения или задать вручную.
Теперь поднимем контейнеры:
docker-compose up -dЕсли все настройки были выполнены корректно, то в результате мы можем посмотреть UI mlflow по адресу: http://localhost:5000

Пока здесь пусто и самое время создать наш первый эксперимент!
Создаем первый run
Для экспериментов мы будем использовать всем известный датасет, который включен в библиотеку sklearn - iris. Данный датасет часто используется для демонстрации задач классификации. Загрузим датасет и обучим SVM модель:
import mlflow
from sklearn import datasets, svm
from sklearn.model_selection import train_test_split
mlflow.sklearn.autolog()
if __name__ == '__main__':
X, y = datasets.load_iris(return_X_y=True, as_frame=True)
# Используем только часть фичей
X = X.iloc[:, :2]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
with mlflow.start_run():
clf = svm.SVC(kernel="rbf", C=1)
clf.fit(X_train, y_train)
val_metrics = mlflow.sklearn.eval_and_log_metrics(clf, X_test, y_test, prefix="val_")Чтобы наши результаты были сохранены в MLflow, используется mlflow.start_run(). Перед запуском run мы включили автоматическое логирование для sklearn, которое отработает на вызов метода fit, сохранив параметры используемой модели, полученные метрики и саму модель. В конце мы валидируем нашу модель на отложенных данных через eval_and_log_metrics, которая самостоятельно определяет необходимые для расчета метрики и также логирует их.
Чтобы определить путь к серверу MLflow, также нужно установить переменную MLFLOW_TRACKING_URI, используя IP адрес хостовой машины, в нашем случае этот будет http://192.168.1.108:5000/
Запустим выполнение скрипта и проверим через UI MLflow, что все корректно отработало и было залогировано.
python train.py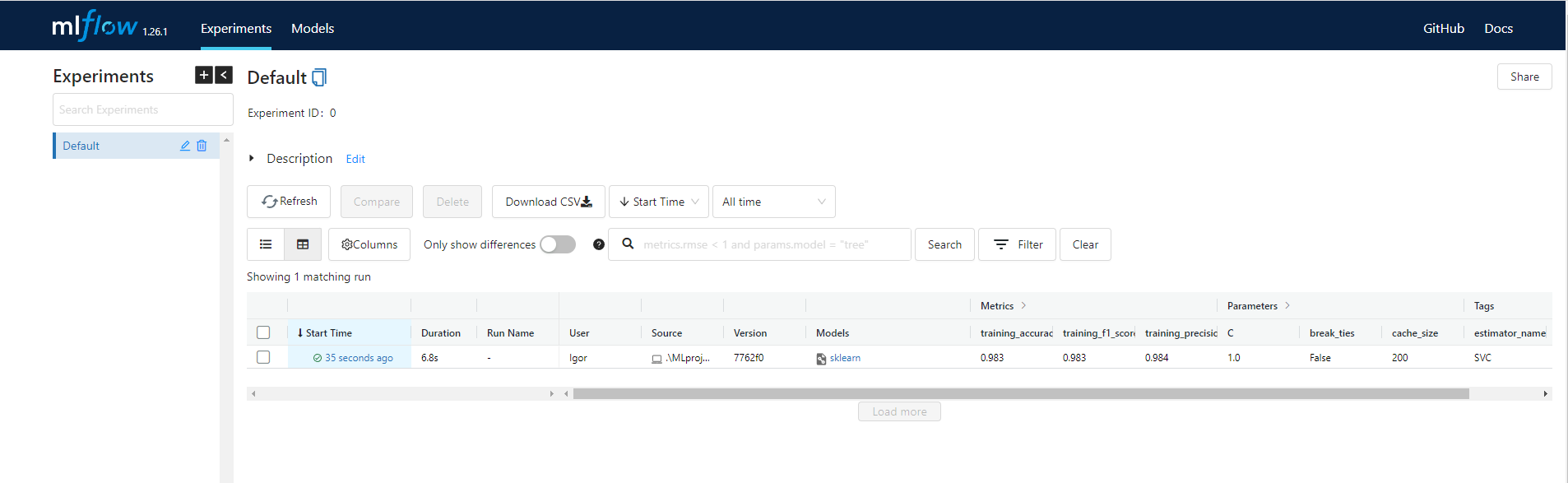
В эксперименте по умолчанию появился новый run, в котором залогированы с параметрами запуска и полученными метриками. Если перейдем в него, то также сможем посмотреть сохраненные артефакты.
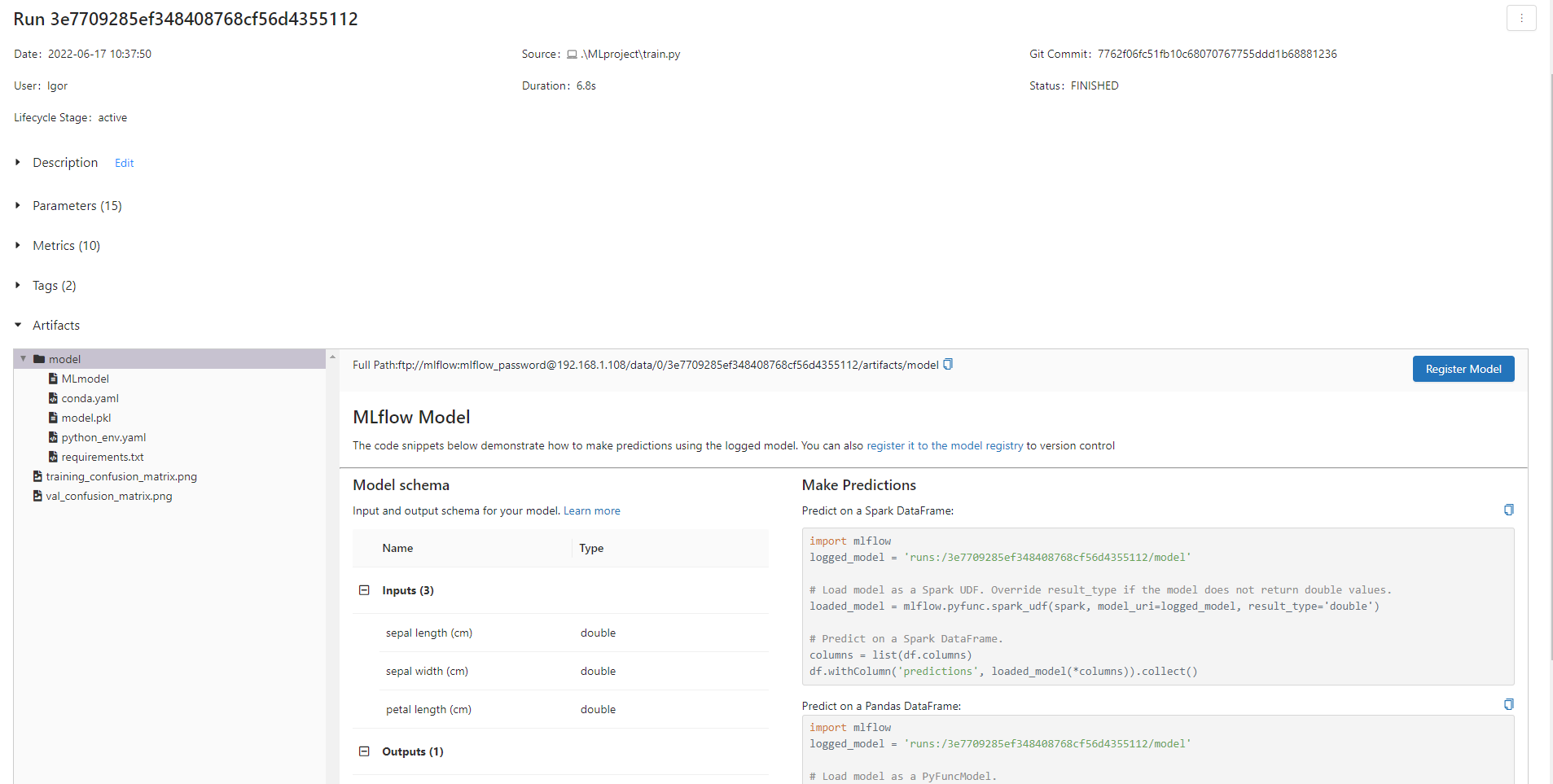
Создаем MLProject
Создадим папку MLproject, поместим в нее наш скрипт train.py и создадим файл MLproject
name: iris_example
entry_points:
main:
command: "python train.py"В самом проекте кроме имени зададим один entrypoint - main, который запускается в проекте по умолчанию. Entrypoint отвечает за выполнение какой-либо команды, которую можно задать в ключе command (можно вызвать любой python или bash скрипт). В main пока просто вызовем созданный ранее скрипт.
Для запуска проекта будем использовать CLI
mlflow run MLproject --env-manager=local --experiment-name=iris
2022/06/17 10:45:27 INFO mlflow.projects: 'iris' does not exist. Creating a new experiment
2022/06/17 10:45:28 INFO mlflow.projects.utils: === Created directory C:\Users\Igor\AppData\Local\T
2022/06/17 10:45:28 INFO mlflow.projects.backend.local: === Running command 'python train.py' in ru
2022/06/17 10:45:36 INFO mlflow.projects: === Run (ID '0601a2be45384f67856d7e513d7b5963') succeededВ результате мы получим run аналогичный предыдущему, который будет привязан к новому эксперименту, так как мы указали флаг --experiment-name=iris. Флаг --env-manager=local отвечает за то, чтобы исполнение кода произошло локально, используя существующие окружение. О доступных вариантах управления окружения поговорим чуть позже, а пока добавим возможность кастомизации параметров запуска проекта.
Добавляем поддержку параметров
В MLflow project присутствует возможность кастомизации исполняемой команды за счет указания параметров запуска. При определении параметра можно указать тип данных и значение по умолчанию. На данный момент доступны 4 типа данных: string, float, path и uri.
Определение параметра только с типом данных:
parameter_name: data_typeОпределение параметра с типом данных и значением по умолчанию:
parameter_name: {type: data_type, default: value} # Short syntax
parameter_name: # Long syntax
type: data_type
default: valueДобавим в наш проект возможность управлять параметрами модели SVM, а именно задавать параметры kernel and C.
entry_points:
main:
parameters:
kernel: {type: string, default: 'rbf'}
C: {type: float, default: 1}
command: "python train.py --kernel {kernel} --param_c {C}"Также мы добавили в команду запуска нашего скрипта поддержку новых параметров, для этого в команде достаточно указать имя параметра в фигурных скобках.
Чтобы эти параметры влияли на выполнение скрипта, поддержим чтение аргументов командной строки, используя argparse.
from argparse import ArgumentParser
def parse_args() -> tuple[str, float]:
parser = ArgumentParser()
parser.add_argument("--kernel", dest="kernel", type=str, default='rbf')
parser.add_argument("--param_c", dest="param_c", type=float, default=1)
args = parser.parse_args()
return args.kernel, args.param_cСчитаем переменные и используем их при инициализации модели.
kernel, param_c = parse_args()
with mlflow.start_run():
clf = svm.SVC(kernel=kernel, C=param_c)
clf.fit(X_train, y_train)
mlflow.sklearn.eval_and_log_metrics(clf, X_train, y_train, prefix="training_")
mlflow.sklearn.eval_and_log_metrics(clf, X_test, y_test, prefix="val_")
mlflow.sklearn.log_model(clf, 'model')При запуске проекта MLflow указанные в нем параметры автоматически логируются в run, что вызывает конфликты с автоматическим логированием, при включенном mlflow.sklearn.autolog(). Поэтому отключим автоматическое логирование и отдельно залогируем метрики на тренировочных данных, а также саму модель.
На практике это не является большой проблемой, потому что, на мой взгляд, логирование параметров в автоматическом режиме избыточно. Даже в нашем простом примере при использовании параметров модели по умолчанию было залогировано 15 параметров. В реальных примерах, в которых вместо модели, допустим, будет использован pipeline с препроцессингом, число параметров легко переваливает за 50, при этом, действительно, количество значимых и изменяемых параметров на порядок меньше.
Теперь запустим наш проект с другими параметрами. Для того чтобы задать значение параметра, нужно воспользоваться флагом -P.
mlflow run MLproject --env-manager=local --experiment-name=iris -P kernel='poly' -P C=2
2022/06/17 14:57:01 INFO mlflow.projects.utils: === Created directory C:\Users\Igor\AppData\Local\T
2022/06/17 14:57:01 INFO mlflow.projects.backend.local: === Running command 'python train.py --kern
2022/06/17 14:57:09 INFO mlflow.projects: === Run (ID '41eb2d4a414b4cbe8158d0036107dad1') succeededТакже убедимся, что значения по умолчанию корректно отрабатывают.
mlflow run MLproject --env-manager=local --experiment-name=iris
2022/06/17 16:05:36 INFO mlflow.projects.utils: === Created directory C:\Users\Igor\AppData\Local\T
2022/06/17 16:05:36 INFO mlflow.projects.backend.local: === Running command 'python train.py --kern
2022/06/17 16:05:44 INFO mlflow.projects: === Run (ID 'd413b53a9c094b2483dc9ca5c4f6e1ed') succeededФиксируем enviroment
В настоящее время MLflow поддерживает следующие варианты enviroment для запуска проекта:
Conda
Virtualenv
Docker
System enviroment (локальное окружение)
До текущего момента мы использовали локальное окружение, что может быть удобным с точки зрения повседневной работы, но создает сложности при попытке воспроизведения результатов наших экспериментов. При использовании conda или virtualenv при каждом запуске создается новое окружение, в котором устанавливаются все требуемые библиотеки. Требуемые версии python библиотек зафиксированы в отдельном файле.
Для нашего примера мы воспользуемся docker, который фиксирует не только версии python библиотек, но и окружение в целом - docker образ. Для начала соберем необходимый образ.
FROM python:3.9.13-slim
WORKDIR /app
COPY requirements.txt ./
RUN pip install --upgrade pip && \
pip install --no-cache-dir -r requirements.txt
CMD ["python"]В requirements.txt указаны те библиотеки, которые мы ставили локально на этапе подготовки окружения (scikit-learn, matplotlib, mlflow). Команда для сборки образа:
docker build -f .dockerfile -t iris_project:1.0.0.0 .Для того чтобы указать docker образ в качестве environment для проекта, необходимо добавить соответствующую секцию в файл конфигурации MLproject
docker_env:
image: iris_project:1.0.0.0Выполним очередной запуск проекта, убрав параметр env-manager=local
mlflow run MLproject --experiment-name=iris
2022/06/20 15:05:04 INFO mlflow.projects.docker: === Building docker image iris_example:7762f06 ===
2022/06/20 15:05:06 INFO mlflow.projects.docker: Temporary docker context file C:\Users\Igor\AppDat
2022/06/20 15:05:06 INFO mlflow.projects.utils: === Created directory C:\Users\Igor\AppData\Local\T
2022/06/20 15:05:06 INFO mlflow.projects.backend.local: === Running command 'docker run --rm -e MLF
7762f06 python train.py --kernel rbf --param_c 1' in run with ID 'a8cfd09b3b6547e597924653275425fd'
2022/06/20 15:05:15 INFO mlflow.projects: === Run (ID 'a8cfd09b3b6547e597924653275425fd') succeededПри запуске проекта создается новый образ docker на основе iris_project, который также содержит код нашего проекта. Полученный образ помечается как iris_example-, где — идентификатор коммита git. После создания образа MLflow выполняет main entrypoint проекта в контейнере, используя docker run.
Некоторые переменные окружения, такие как MLFLOW_TRACKING_URI, прокидываются внутрь контейнера во время выполнения проекта. Прокинуть дополнительные можно в секции docker_env конфигурации MLproject, также существует возможность задать volumes для контейнера.
Используем Git
Если открыть результаты нашего последнего запуска, то мы можем увидеть команду, с помощью которой был запущен проект, и, соответственно, этой же командой мы должны иметь возможность его воспроизвести.
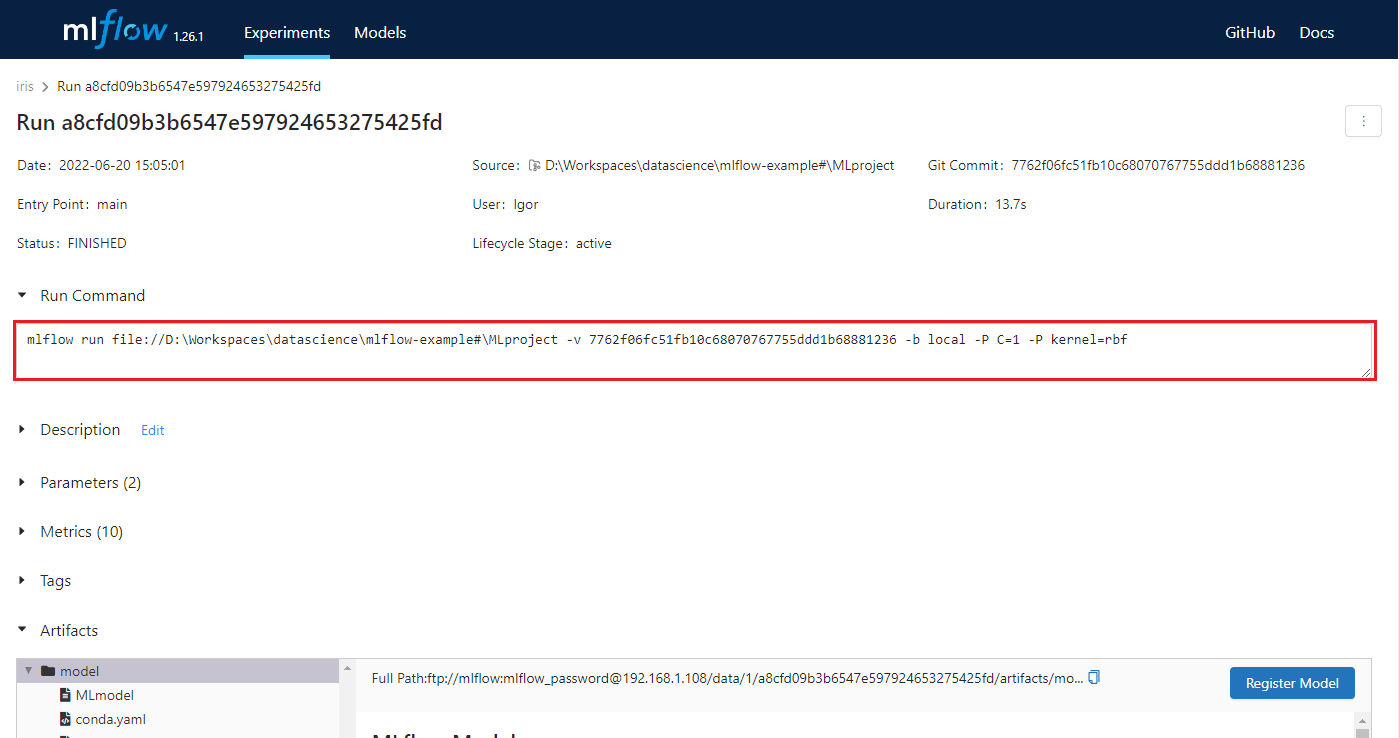
Однако, мы запускали проект из локальной директории, в которую вносили изменения и не фиксировали их. Соответственно, если запустить проект с указанным коммитом, то полученные результаты могут отличаться, или вообще запуск проекта может завершиться с ошибкой. В целях избежания подобных ситуаций мы можем указывать в качестве проекта не локальную папку, а путь до git репозитория.
mlflow run git@github.com:iadergunov/mlflow-example.git#MLProject --experiment-name=iris
2022/06/20 16:53:56 INFO mlflow.projects.utils: === Fetching project from git@github.com:iadergunov/mlflow-example.git#MLProject into C:\Users\Igor\AppData\Local\Temp\tmp_n4xfg5j ===
2022/06/20 16:54:01 INFO mlflow.projects.docker: === Building docker image iris_example:f17b968 ===
2022/06/20 16:54:01 INFO mlflow.projects.docker: Temporary docker context file C:\Users\Igor\AppData\Local\Temp\tmp7sbe_ooe was not deleted.
2022/06/20 16:54:01 INFO mlflow.projects.utils: === Created directory C:\Users\Igor\AppData\Local\Temp\tmpfp2b_rc5 for downloading remote URIs passed to arguments of type 'path' ===
2022/06/20 16:54:01 INFO mlflow.projects.backend.local: === Running command 'docker run --rm -e MLFLOW_RUN_ID=ed83202c689742968182e1ad66dc6f21 -e MLFLOW_TRACKING_URI=http://192.168.1.108:5000/ -e MLFLOW_EXPERIMENT_ID=1 iris_example:
66de730 python train.py --kernel rbf --param_c 1' in run with ID 'ed83202c689742968182e1ad66dc6f21' ===
2022/06/20 16:54:11 INFO mlflow.projects: === Run (ID 'ed83202c689742968182e1ad66dc6f21') succeeded ===Открыв результаты последнего запуска, мы можем посмотреть команду, которая позволит повторить запуск проекта. Также появилась ссылка на git коммит, при переходе по которой можно ознакомиться с исходным кодом, использованным для запуска.

Заключение
Если использовать подход описанный выше и дополнительно описать в MLproject процессы загрузки и обработки данных, мы можем полностью зафиксировать процесс обучения модели, и это гарантирует воспроизводимость наших экспериментов.
Ну почти...
Ведь могут измениться исходные данные, и из-за этого наш проект все равно может выдать совершенно другие результаты. Но это уже совсем другая история.
