Мы часто сталкиваемся с задачами, которые требуют работы нашего кода дольше, чем длится простой HTTP-запрос. Это могут быть как выгрузки данных для интеграции с партнерами, так и просто приложения, которые должны реагировать на события в системе в момент их появления. Конечно, можно использовать другие языки программирования, но это увеличит стек и усложнит систему.
Меня зовут Александр Пряхин, я TechUnit Lead в Авито. В IT работаю уже 14 лет. Из них 8 лет руковожу командами. Параллельно с этим преподаю и менторю. Сегодня разберем, как готовить демонов на PHP — от А до Я, и почему это актуально.

Проблемы с PHP
By design PHP работает так:

Есть HTTP-запрос. Web-server его принимает и передаёт на выполнение SAPI. Например, какой-нибудь PHP FPM. Дальше он передаётся в базу данных и вытаскивает какие-то данные, формирует ответ и возвращает его пользователю. То есть пользователь инициализирует все запросы, между которыми нет связи. При этом всё работает миллисекунды, край — несколько секунд, если какая-то небольшая страничка home page на shard хостинге.
Но если говорить о проектах, которые живут уже какое-то время, то появляются производные задачи. Например, в какой-нибудь e-commerce проект приходит бизнес и говорит:
— Нам хочется построить отчёт за год с разными срезами!
— А ещё мы хотим не каждую минуту обрабатывать события, а сразу на event реагировать!
— А ещё у нас приходит очередь событий и мы хотим их слушать!
— А ещё нам когорты хочется!
— И вообще мы хотим DWH у себя построить.
Из перечисленных задач можно выделить два кластера проблем:
С одной стороны, обработка большого объема данных для отчетов;
С другой, нам надо обрабатывать данные в небольшом количестве, но реагировать сразу и слушать постоянно.
Конечно, всё это уже не укладывается в работу PHP by design, потому что требует более сложного подхода.
Рождён, чтобы умирать?
Капитан очевидность скажет зачем нам нужен PHP, если есть другие языки. Давайте возьмем тот же самый Go и будем писать на нём. Есть даже статья «PHP рождён, чтобы умирать».
Но всё ли так просто??
С одной стороны, можно принести команде учебник, найти курсы и ментора. Экспертизы у команды при этом не будет, поэтому она будет дорожать. Очевидно, это совсем не идеальное решение, не серебряная пуля.
С другой стороны, можно нанять готового специалиста с рынка. Он придёт и закодит. Но это уже явное удорожание, потому что специалист с рынка — это дополнительное место в команде и расходы на фонд оплаты труда.
И тут стоит задаться вопросом: а так ли плох PHP? Действительно ли там нельзя решить поставленные задачи: большие обработки и демоны?
Попробуем разобраться на примерах.
Большие обработки
Классическая большая обработка чаще всего выражается в обработке огромного отчёта.

Чтобы построить отчёт, нужно набрать большой батч сырых данных и трансформировать его. Например, преобразовать или склеить данные, выстроить из них какую-то структуру и в итоге сформировать представление. Естественно, с ростом приложения и объёма данных, проработка отчёта будет разрастаться по времени и ресурсам. Это не круто, потому что придётся столкнуться:
если набирать сырые данные, то их может быть очень много или их надо собирать с различных источников;

если эти данные уже собраны, то их нужно как-то склеить. Но, опять же, их может оказаться очень много или они могут иметь сложную логику склейки.

Потоковая обработка
Первый хинт, с которым можно идти работать и исправлять всё, что нужно — это потоковая обработка. Его правило звучит так: читать только то, что нужно обработать здесь и сейчас. Например, мы порциями получаем данные из большого источника. Типовая ошибка: «Я хочу получить всё сразу и начать обрабатывать». Так делать, конечно, не надо.
Тут на помощь приходит старый добрый генератор:
function readTheFile(string $path): \Generator {
$handle = fopen($path, "r");
while(!feof($handle)) {
yield trim(fgets($handle));
}
fclose($handle);
}Но оператор yield выбрасывает данные в момент их получения. То есть он не собирает всё, что наработал из файла в одну большую переменную, а сразу же по обработке выбрасывает полученные данные. В результате:
Объём памяти равен размеру самой большой итерируемой части. То есть мы работаем не со всем файлом, а с одной строкой;
Не происходит аллоцирования памяти для промежуточного хранения, потому что результат сразу выкидывается;
На выходе также нужно соблюдать правила обработки результата.
В примере выше мы рассматриваем работу с файлами, но как быть, если мы работаем с базой данных? Скажем, если наш запрос возвращает большой кусок данных, который при передаче в PHP съест уйму памяти? Для таких случаев мы тоже можем не выгружать сразу всю информацию в память, а обрабатывать данные последовательно. Что, кстати, является довольно классическим случаем, когда мы обходим в цикле полученный результат.
По умолчанию PHP использует буферизованные запросы, результаты которых сразу же загружаются из базы в память. Но если нам требуется формировать агрегированный результат по итогам обработки каждой строки, хранить всё вместе в памяти не стоит.
Небуферизованные запросы вместо явного набора данных возвращают объект типа Resource, который сможет обработать результат, например, построчно. То есть, в памяти PHP будет находиться только маленькая часть данных.
Выполнить небуферизованный запрос в MySQL можно, например, задав параметр в PDO:
$pdo->setAttribute(PDO::MYSQL_ATTR_USE_BUFFERED_QUERY, false);Здесь важно помнить, что соединение до конца обработки результата будет заблокировано. Освободить его принудительно можно при помощи метода free_result.
Ещё одна проблема в том, что PHP не умеет так делать, например, с Postgres, но решить эту проблему можно, обернув запрос в транзакцию и используя курсоры внутри:
$curSql = "DECLARE my_cursor CURSOR FOR SELECT * FROM huge_table";
$connection = new PDO("pgsql:host=whatever dbname=whatever", "user", "pass"); $connection->beginTransaction();
$stmt = $connection->prepare($curSql);
$stmt->execute();
$innerStatement = $connection->prepare("FETCH 1 FROM my_cursor");
while($innerStatement->execute() && $row = $innerStatement->fetch(PDO::FETCH_ASSOC)){
echo $row['field'];
}Говоря о применимости такого подхода, можно сделать вывод, что для небольших запросов отключать буферизацию не стоит, так как при наличии большого количества маленьких запросов она будет замедлять работу. Но если вы обрабатываете большой объём данных, это существенно сэкономит ресурсы.
Если вы погуглите про итераторы, то увидите уйму примеров, которые говорят выбрасывать эти данные и всё будет хорошо. Но на самом деле нет. Если их продолжить выбрасывать и каким-нибудь foreach складывать в консолидированную переменную или массив, то рост потребления памяти будет каждый раз кратным. То есть с каждым накоплением он будет вырастать и вырастать, особенно если работать с массивами.
Если мы хотим действительно экономить память, то и на выходе должны соблюдать правила обработки.

Как только приходит кусочек результата, его нужно процессить и выкидывать в промежуточное хранилище, например, в быстрый кэш. Но ни в коем случае не нужно его сохранять. Мы должны понимать, что работаем с конкретным кусочком данных, только тогда будем действительно экономить память. В противном случае мы будем её расходовать, только не в месте обработки файла, а на выходе, где всё это дело консолидируется и начинает жрать ресурсы.
Но если файл большой и обрабатывается при помощи генераторов, то это долго! А ждать не хочется, хочется обработать всё как можно быстрее.
Параллельные вычисления
И тут возникает второй хинт — можно взять большой кусок данных, попилить на ещё меньшие кусочки и каждый из них обработать своей обработкой, а промежуточные результаты консолидировать в один.

Параллельные и асинхронные вычисления в PHP представлены различными фреймворками. Например Swoole достаточно мощный фреймворк, у которого есть следующий функционал:
Асинхронное выполнение;
Переключение контекстов;
Кэш между воркерами;
Много чего ещё.
Но я хочу познакомить вас с true параллельными вычислениями в PHP, а именно с библиотекой Parallel. Но сначала разберёмся с терминологией.
— Синхронное выполнение кода
Есть один системный поток. В нём главный и дочерние вызовы, то есть полноценный стек. Главный метод вызывает дочерний и пока тот не завершится, он на главный не переключится. То есть вызывающая функция ждёт полного завершения вызванной.

— Корутины (Coroutine)
Есть главный поток, который переключается в корутину, запускает её и, например, начинает отправлять запрос. В любой момент из этой корутины можно передать выполнение обратно основному потоку. Например, если известно, что запрос будет долго выполняться, то из корутины можно выброситься в главный поток, там поработать и вернуться в корутину, когда туда придет результат. То есть работа идет в том же одном потоке, и точно также выполнение передаётся между различными методами. Но один метод уже не блокирует другой, а другой метод может в какой-то момент забрать на себя всю работу. При этом можно ещё и асинхронно работать: вне зависимости от главного потока.

Корутины специализируются на том, чтобы снизить общую нагрузку на систему. За счёт квантования между выполнением различных методов, можно более эффективно расходовать выделенные ресурсы. Поэтому простоя как такового не будет.
— Потоки (threads)
Если говорить про полноценные потоки, то это уже независимая параллельная обработка.
Создание потока является более дорогой операцией, но при этом уже все операции идут строго параллельно. То есть если отправить 5 запросов, то все эти 5 запросов будут идти параллельно, не блокировать друг друга, и при этом полученные данные останутся непосредственно в потоках.
Потоки — не про экономию ресурсов, а про ускорение сложных вычислений, которые можно выполнить параллельно и потом консолидировать.
Parallel
Parallel — это альтернатива pthreads, который был достаточно давно и подвергался критике в отношении потока безопасности и прочего. Parallel доступен с версии 7.2 и выше. Он позволяет иметь полноценные потоки, а не корутины. Разница между ними в том, что корутина не блокирует основной поток, но работает внутри и обеспечивает асинхронную работу, то есть работу по событиям. А потоки — это уже выделенные сущности с параллельной работой.

Запуск потока
Чтобы запустить поток, достаточно подключить библиотеку Parallel и использовать самый базовый класс $runtime. Он создаёт поток, который нужно сохранить в соответствующую переменную и вызвать метод run. Те, кто изучал другие языки со встроенной многопоточностью, могут здесь увидеть сходство. Тут нет ничего принципиально нового.

При этом сам $runtime во время выполнения может принять на вход некий метод, который будет выполнять внутри себя.

По сути, это тип Closure: функция, выполняющаяся внутри потока. Обратите внимание, что если в канал передаётся замыкание, оно кэшируется. Это круто, так как для каждого нового потока не нужно по новой интерпретировать код, что, естественно, ускоряет работу системы в целом.
Передача информации
В дальнейшем поток может отдать результаты в объект типа $future, таким образом вернуть в основной поток то, что наделал. Это удобно для передачи информации при необходимости.

Кроме того, при передаче этих значений можно у $future вызвать метод value, который выведет то, что возвращает непосредственно переданный task внутрь потока.

Здесь достаточно дождаться результатов работы потока и вроде бы всё хорошо. Но, как правило, в многопоточности возникает необходимость обмена ресурсов между потоками.
Обмен ресурсов
Допустим, мы хотим работать с каким-то одним консолидирующим объектом, в который в режиме реального времени будут поступать данные. Когда этот консолидирующий объект набирает в себе достаточное количество информации, мы хотим завершить пополнение и отдать его наружу. То есть условно мы хотим иметь некий общий ресурс (переменную или объект) между потоками.
Для этого в Parallel существует класс Channel.

Он передаётся непосредственно в task и через него уже можно общаться между потоками, то есть обмениваться какими-то данными.

При этом Channel является потокобезопасным: не нужно заморачиваться на тему мьютексов — состояния гонки. Channel — это полноценная обёртка для общего ресурса, который решает все классические проблемы обмена данными.
Если по каким-то причинам вам не нравится Channel, можно использовать класс Sync, написать свои мьютексы и жить так, как вам больше нравится в многопоточном мире. Также есть класс Event, который позволяет реагировать на события отправки, получения данных и прочего.
Но нужно понимать, что обмен ресурсов возможен только между потоками, процессами. Поэтому если есть два процесса, внутри которых запущены несколько потоков, то обмена через тот же Channel не получится. Вот ссылка на видео с бенчмарком: примерами и комментариями о том, как расходуются ресурсы в многопоточном приложении, и как оно в целом строится.
Коммуникация через внешние системы
Таким образом, если мы хотим параллельно работать с БД, то inter-process communication будет идти только через внешние системы. И тут возникают аспекты, которые нужно учитывать в работе с многопоточным приложением. Самый классический пример — это состояние гонки.
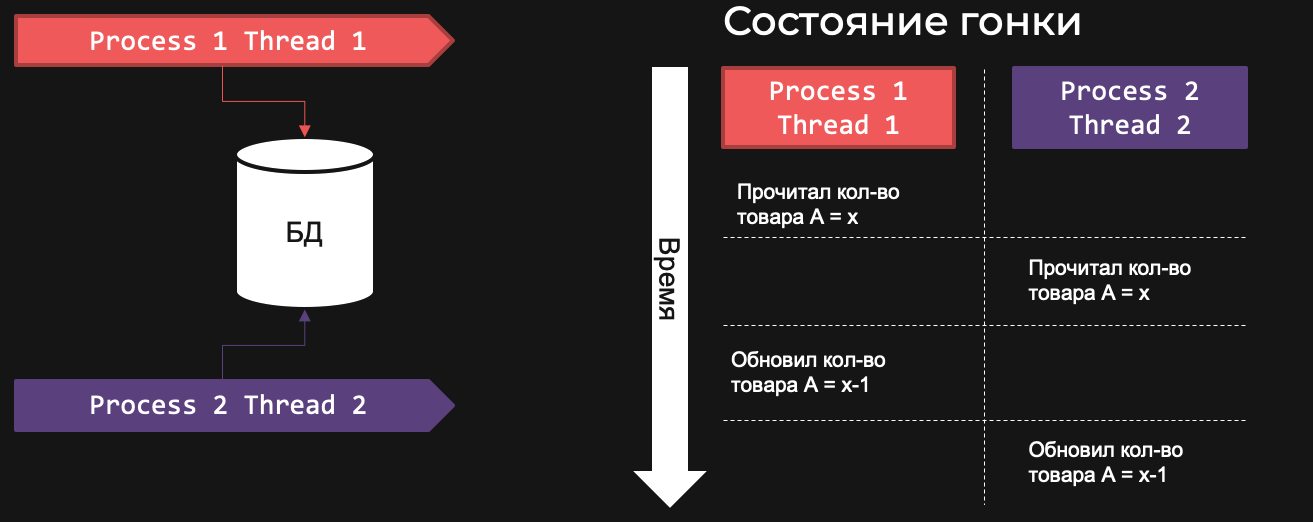
Итак, есть два потока в двух разных процессах, которые в эту БД лезут. Один процесс считает количество товара A и получает значение Х. В этот же момент второй поток во втором процессе читает количество этого же товара и тоже получает количество Х. Если дальше количество товара обновляется, оба потока будут отталкиваться от Х, полученного в самом начале, а не от обновленного значения.
Решением будет введение транзакций. Транзакции позволяют обеспечить необходимый уровень изоляции данных и не беспокоиться о том, что один поток перетрет данные другого потока. Но здесь нужно понимать, что транзакции могут снизить скорость работы приложения, потому что когда одна транзакция начинает блокировку обновления, другие встанут в очередь. В высоконагруженных приложениях это может привести к тому, что какие-то транзакции с большим количеством обновлений данных могут реально замедлить работу вплоть до deadlock.

Например, если наши два процесса начнут транзакции, то сначала первый поток обновит количество товаров в table 1, второй — в table 2. Дальше они захотят перекрестно обновить данные, но, естественно, начнут ждать друг друга. В этот момент и случится deadlock, так как они не дождутся разрешения этой проблемы. Поэтому нужно сделать следующее:
→ рассматривать транзакции атомарно.
Не нужно загонять 25 обновлений в одну транзакцию и ждать, что они дружно выполнятся. Старайтесь разбивать транзакции по смыслу и никто никого ждать не будет. Например, есть 2 запроса: один — select for update, второй — update.
→ соблюдать порядок обновлений.
Если в одном потоке обновить аккаунт 1, потом аккаунт 2, а во втором — аккаунт 2, а потом — аккаунт 1, то случится deadlock. Вот пример из документации postgres:
UPDATE accounts SET balance = balance + 100.00 WHERE accnum = 2;
UPDATE accounts SET balance = balance - 100.00 WHERE accnum = 1;
Если же порядок поменять, то deadlock не случится:
UPDATE accounts SET balance = balance + 100.00 WHERE accnum = 1;
UPDATE accounts SET balance = balance - 100.00 WHERE accnum = 2;
→ Отправлять блокирующие запросы в конец.
Все запросы на обновление и вставки данных должны быть максимально приближены к концу транзакции. Так другие запросы, которые имеют более низкий уровень блокировки, успеют в этот момент выполниться.
Специфика parallel
В целом, библиотека достаточно богатая, но у неё есть своя специфика работы:
Очень скудная документация и небольшой опыт сообщества: информация пока ещё нарабатывается и найти её довольно сложно;
Дебаг потоков специфичен и требует адаптации: нужно смотреть в каком потоке произошёл отвал, добавлять какие-то метрики, чтобы понять в каком потоке или потоках произошла ошибка;
Сборка в Docker (и вообще в принципе в контейнер) заставит попотеть, потому что потом придётся поизгаляться с подключением;
Parallel не снизит расход ресурсов, а только позволит ускорить большие сложные вычисления поверх большого объёма данных.
Демоны
Вернёмся к примеру с отчетом: чтобы построить отчёт, нужно набрать сырые данные, трансформировать их и сформировать представление. Но что, если сырые данные приходят по инициативе поставщика и их нужно получить здесь и сейчас через API? Можно сформировать cron и ждать обращения, но есть ограничения: cron запускается раз в минуту, а данные могут приходить чаще и тогда ничего сделать не получится. В таком случае нужно слушать события.
Запускается скрипт, случается событие, скрипт его обрабатывает и возвращает в ожидание. Таким образом нужно следующее:
Непрерывная работа;
Перманентное соединение с источником (необязательно);
EventDriven-логика, то есть не запуск обработки, а именно ожидание события;
Возможность ответить на событие по результату, то есть выполнить callback.
Непрерывная работа
Самый простой вариант реализовать непрерывную работу — это выполнить while (true) и всё будет вроде как работать, но не будет контроля:
процесс никак не отслеживается;
его можно грохнуть только через halt (консольку);
он как процесс Шредингера. То есть непонятно, что там происходит внутри, какие идут операции и как за всем этим следить.
Здесь может помочь старый добрый PCNTL. Цикл внутри никуда не денется, но если использовать расширение PCNTL, то демон внутри себя будет иметь свой PID:
$pid = pcntl_fork();Это позволит после запуска основного процесса сделать fork по аналогии с потоками и реализовать реакции на сигналы:
pcntl_signal(SIGTERM, 'my_handler');Если наш БД дописывает какой-нибудь батч результатов и мы делаем halt, то половина результатов не запишется, произойдёт краш, потеря консистентности. А если дружить с POSIX, с сигналами, то туда можно послать graceful restart, graceful stop. То есть мы сможем описать логику, которая будет дописывать текущую итерацию, коммититься и после этого уже останавливаться.
На практике, когда запускается многопоточный тест, сначала запускается основной процесс, а потом от него форкаются 4 процесса и они же отображаются в запуске. По ссылке можно посмотреть на GitHub простой многопоточный пример-песочницу для тех, кто хочет познакомиться с PCNTL.
Что слушать?
→ Постоянный опрос очереди на появление новых событий
Если работает демон, он слушает события сам по себе и позволяет отслеживать появление новых записей, например, в БД. Если используются очереди (Apache Kafka или RabbitMQ), можно слушать очередь и точно так же реагировать на появление новых записей, но не по cron, а именно через демон.
— Unix- или TCP-сокета
Более того, через демон можно слушать Unix- или TCP-сокеты, где уже более низкоуровневая передача данных и можно непосредственно слушать клиента.

Unix-сокет подойдёт, если клиент работает в той же железке или в той же инфраструктуре. TCP-сокет подойдёт, если есть соединение с каким-то внешним источником данных, и нужно передавать более легковесные данные для того, чтобы ускорить обмен информацией. Это тоже можно делать непосредственно через PHP.
Как слушать?
Это набор классов, которые позволяют организовывать EventDriven-логику. Можно написать всё, вплоть до собственного HTTP-клиента.
Это набор классов, которые позволяют работать с сетевыми сокетами FNET и IFUNIX. Они представляют непосредственное соединение с Unix-сокетами, то есть к их файликам, через которые идет обмен данных.
Особенности
Если вы ходили по собеседованиям, наверняка сталкивались с вопросами из серии, как устроена память в PHP. А если вы готовились к этим собеседованиям, то наверняка знаете, что Zval-контейнер живёт в памяти, пока на него есть ссылки. В аспекте демонов это означает, что массив $eventData, в который поступают и никак не очищаются новые данные, со временем разрастется. А если в системе много событий, то это произойдёт достаточно быстро.

Накопление данных начнёт давать утечку памяти. Данные, которые не используются, будут тупо жрать память и в какой-то момент процесс убьёт OOM killer, потому что будет съедено очень много ресурсов.
Здесь помогают:
Старый добрый unset;
Итераторы и генераторы.

С ними мы опять же возвращаемся к парадигме: работать только с тем, что нужно в данный момент. Плюс, в процессе в один момент времени PHP держит открытым одно соединение к базе на пользователя. Это соединение может залипнуть, поскольку демон работает часами, днями и даже больше. В таком случае соединение вроде как есть, но данные по нему не ходят. Такое случается не только с БД, но и с другими ресурсами.
Если залезть на какой-нибудь форум, то можно найти совет «использовать persistent connect». Он ничем не поможет, потому что, когда висит одно соединение с БД или с внешним источником, нет никакой разницы между persistent или не persistent? В PHP соединение будет висеть, пока не остановится процесс.
Поэтому надо мониторить возможность соединения, ведь процесс один и работает долго. Не получится быстро отследить отвал, потому что после запуска сервера, вы ходите туда раз в неделю. А залипание может произойти через 5 минут после вашего последнего мониторинга и болтаться неделю.
Вот варианты решения:
— регулярный рестарт демона
Можно решить проблему в лоб — принудительно рестартануть демон. Конечно, это снизит вероятность залипания, но это не гарантирует, что их вообще не случится. Допустим, вы рестартуете демон раз в сутки, но залипание также может случиться через 5 минут после последнего рестарта, тогда всё оставшееся время оно будет висеть.
— тестовый запрос
Более умное решение: отправлять тестовые запросы. Нужно сделать ручку проверки внешнего ресурса, демона. Например, дёргать отправку запроса и, если запрос не укладывается в какое-то количество секунд или миллисекунд, то считать, что демон грохнулся, алертить и перезапускать демон. Это уже лучше, потому что на это можно повесить мониторинг, отслеживать и с этим работать.
— Тулзы APM (Application Performance Monitoring)
Можно использовать ElasticAPM, NewRelic, Pinba — всё, что умеет дешево и быстро сохранять трейсы и анализировать их, но ни в коем случае не Xdebug. Он очень сильно усложнит ситуацию, так как он тяжёлый и использовать его в продакшен-средах не стоит. Нужны APM расширения. Например, ElasticAPM:

Он ставится как модуль к PHP, автоматически собирает трейсы и показывает проблемы. NewRelic тоже отлично делает это из коробки. Также можно отслеживать healthcheck-ручки и прочее.
В целом APM расширения помогают смотреть при выполнении скрипта, как эволюционирует потребление ресурсов и оптимизировать процесс.
Состояние демона
Демон может зависнуть, упасть, взорваться из-за критических изменений окружения. Например, если расширится или сузится диск или поменяются сетевые настройки. Поэтому нужно отслеживать состояние демона и уметь его переподнимать. Здесь и становится важным PCNTL, потому что обязательно нужно иметь graceful возможности рестарта для того, чтобы демон мог остановиться, закончить текущие обработки и только тогда дать возможность рестарта.
Чтобы это сделать, есть точка запуска, в которой создаются демоны. Можно прописать запуск нескольких демонов, которые будут висеть уже в системе на выполнение. Через эту точку доступа можно посылать сигналы POSIX, которые нужны для жёсткого терминирования, graceful рестарта, kill и прочего. Можно точно также хранить соответствие ID запущенных демонов, чтобы понимать, какой демон обрабатывает тот или иной IP. Следит за определённой очередью и уже от этого строить мониторинг, прикручивать healthcheck-ручки к демонам, подвешивать их в APM и контролировать.

Кэширование DNS
FPM и PHP могут кэшировать DNS на момент запроса. FPM отрабатывает за несколько секунд, но есть внешние ресурсы, к которым обращение идет не по IP адресу, а именно по доменному имени. Если у доменного имени сменится IP адрес, то PHP демон, который закэшировался на момент своего запуска и работает, допустим, полгода, ляжет. Поэтому здесь нужен мониторинг и понимание, что в таких случаях лучше использовать более низкоуровневое подключение.
Чтобы такого вообще не возникало, демоны должны подчиняться следующим правилам:
Не нужно в один демон пихать всё подряд, то есть один демон — один процесс, как в Docker;
Множество зависимостей усугубит потребление ресурсов и усложнит деплой. Чем меньше зависимостей, тем лучше. Не нужно напихивать туда сразу все библиотеки, которые нравятся. Смотрите и отталкивайтесь от голого PHP, потому что чем больше будет модулей, тем больше расход ресурса и выше риск того, что код будет написан с утечками. Но здесь, опять же, виноват не PHP, а тот, кто на нём пишет.
При этом аспекты сборки тоже имеют своё место.

После того как демон собран, протестирован и упакован, старшая версия должна уметь завершить текущую обработку и остановиться, терпя переключение. После остановки, можно запустить новую версию и отслеживать какая версия демона работает в продакшене в тот или иной момент. Также демон должен уметь себя идентифицировать, поэтому в мониторинге неплохо отслеживать какие-то сигнатуры у этого демона: например, в какой версии он работает. Это можно сделать в той же самой healthcheck-ручке, которая также отслеживает работоспособность демона. После всего этого можно перезапустить новую версию, убедиться в этом на мониторинге и начать с ней работать.
Выводы
→ PHP живее всех живых и продолжает развиваться.
Необязательно расширять стек, если нужно что-то ускорить или организовать большую обработку. Также не обязательно брать новый язык программирования, если встают принципиально новые задачи. Лучше посмотреть что уже есть в проде и как это переиспользовать.
→ Эммет Браун из фильма «Назад в будущее» говорил: думайте, не где, а когда.
Разрабатывая демоны или большие обработки, следует думать на более длительном горизонте работы, чем несколько секунд.
→ Side-эффекты
Не стоит забывать о мониторинге, кэшировании и расшаривании ресурсов. Side-эффекты добавляются, потому что это в принципе новый пласт разработки. Но за счёт этого не тратятся ресурсы на изучение нового языка и найм новых программистов, но при этом есть целый пакет новой функциональности.
