
Если ваша задача заключается в аналитике данных или в машинном обучении, то успех её выполнения зависит от создаваемых вами конвейеров данных и способов их создания. Но даже для опытных дата-инженеров проектирование нового конвейера данных каждый раз становится уникальным событием.
Интеграция данных из множества разделённых источников и их обработка для обеспечения контекста содержит в себе и возможности, и трудности. Один из способов преодоления трудностей и получения новых возможностей в области интеграции данных — создание конвейера ELT (Extract, Load, Transform).
В этой статье мы подробно рассмотрим процесс ELT, в том числе его работу, преимущества и распространённые способы применения. Также мы поговорим о различиях между ELT и ETL (Extract, Transform, Load) и дадим советы по созданию и оптимизации конвейера ELT.
Что такое ELT?
ELT — это аббревиатура от extraction (извлечения), loading (загрузки) и transformation (преобразования). Это процесс интеграции данных, при котором из различных источников извлекается сырая информация (в её исходных форматах), загружается непосредственно в центральный репозиторий, будь то облачное хранилище данных, озеро данных или data lakehouse, где происходит преобразование данных в подходящие форматы для дальнейшего анализа и отчётности.

Процесс ELT
Сегодня ELT набирает популярность в качестве альтернативы традиционному процессу ETL (Extract, Transform, Load), при котором этап преобразования выполняется до загрузки данных в целевую систему. Одна из основных причин применения этой методики — необходимость своевременной обработки огромных объёмов данных в любом формате.
Сравнение ELT и ETL
ETL и ELT — это два подхода к перемещению и обработке данных из различных источников для business intelligence. Давайте рассмотрим ключевые различия между этими паттернами.
Порядок этапов обработки. При ETL все преобразования выполняются до загрузки данных в целевую систему. Например, системы Online Analytical Processing (OLAP) позволяют использовать только реляционные структуры данных, поэтому данные предварительно должны быть преобразованы в читаемый SQL формат. При ELT в целевую систему загружаются сырые данные, после чего по необходимости преобразуются.
Масштабируемость. Сегодня организации обрабатывают огромные объёмы различных данных, хранящихся во множестве систем. ELT упрощает управление и доступ ко всей информации, позволяя загружать и хранить для дальнейшего анализа и сырые, и очищенные данные. Если вы хотите использовать облачные хранилища данных или мощные инструменты обработки данных наподобие Hadoop, ELT может помочь вам в реализации большинства их возможностей и более эффективной обработке данных.
При переходе с ETL происходит отход от традиционного хранения на мощностях компании в сторону облачных решений; также это позволяет работать с различными источниками данных и перемещать большие объёмы данных. Однако вам всё равно нужно предварительно разобраться, как преобразовывать информацию, и создать соответствующую схему.
Гибкость. При ETL необходимо сначала решить, что вы собираетесь делать с данными, задать метрики и только после этого можно загружать и использовать данные. При ELT преобразование вместо начала переносится на конец процесса. Это обеспечивает бОльшую гибкость в том, как могут использоваться данные. Любые изменения в требованиях к аналитике не повлияют на весь процесс.
Также ELT упрощает модификацию конвейера под различные нужды. Например, если аналитикам нужно измерить что-то новое, им не придётся менять весь конвейер, достаточно изменить этап преобразования в конце. Или когда дата-саентисты хотят поэкспериментировать с разными моделями ML, они могут получить все данные от источников, а потом решить, какие признаки релевантны.
Доступность данных. ELT полезнее, чем ETL, в ситуациях, когда данные необходимо обрабатывать в реальном времени, например, при потоковой передаче данных от интегрированных IoT-устройств. Если это ваш случай, то ELT станет хорошим выбором, поскольку преобразования происходят уже после того, как данные попали в конечную точку назначения, то есть их можно использовать на ходу.
Затраты. В общем случае ELT более экономен, чем ETL, поскольку для первоначальной реализации требует меньше специализированных инструментов и ресурсов. У большинства поставщиков облачных услуг есть тарифные планы, позволяющие платить в процессе использования. Кроме того, нет необходимости покупать дорогое оборудование, как в случае с традиционным ETL на мощностях компании. Впрочем, это не относится к облачному ETL.
В целом, и ETL, и ELT можно использовать в разных контекстах, в зависимости от потребностей организации.
Подробнее о сравнении этих двух подходов можно прочитать в нашей отдельной статье о сравнении ETL и ELT.
Способы применения ELT
Потребность в использовании ELT возникает в различных ситуациях:
- Например, если есть необходимость в принятии решений в реальном времени на основании данных. ELT — хороший выбор, поскольку позволяет выполнять аналитику практически в реальном времени. Это возможно благодаря тому, что целевая система может выполнять преобразование и загрузку данных параллельно, что ускоряет процесс.
- Если проект требует больших объёмов структурированных и неструктурированных данных, например, данных, генерируемых датчиками, GPS-трекерами и видеорегистраторами. В этом случае ELT может помочь в повышении производительности и во мгновенном обеспечении доступности данных.
- Если вы планируете проект аналитики big data, ELT хорошо подходит для решения проблем с big data, таких как объём, вариативность, скорость и достоверность.
- Если есть команда data science, которой требуется доступ к сырым данным для проектов машинного обучения. ELT позволяет ей напрямую работать с данными.
- Если ожидается рост проекта и вы хотите воспользоваться преимуществами высокой масштабируемости современных облачных хранилищ данных и озёр данных, то ELT поможет в этом.
Это всего лишь несколько примеров возможного использования ELT. Количество его применений больше и универсальнее.
Этапы процесса ELT
ELT — это процесс, состоящий из трёх основных этапов: извлечения, загрузки и преобразования. Ниже мы вкратце опишем каждый из этапов ELT.
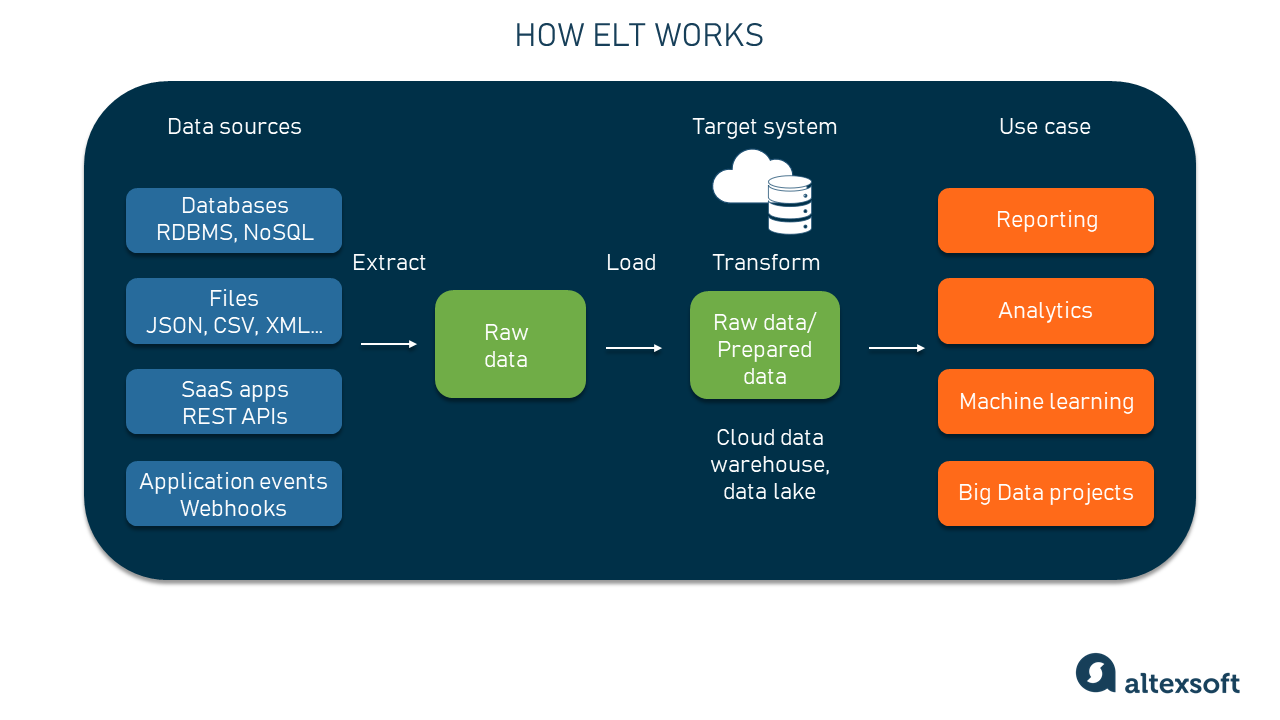
Как работает ELT
Extract (извлечение)
Этап «extract» (извлечения) включает в себя получение данных из таких источников, как базы данных, неструктурированные файлы или API. При этом могут использоваться SQL-запросы, веб-скрейпинг или другие методики извлечения данных. Существует три основных типа извлечения.
Полное извлечение. Из конкретного источника данных извлекаются все доступные данные. В этом процессе может использоваться извлечение всех строк и столбцов данных из реляционной базы данных, всех записей из файла или всех данных из конечной точки API.
Частичное извлечение данных с уведомлениями об обновлениях. При этой методике извлечение данных выполняется из системы-источника, которая способна отправлять уведомления в случае изменения записей. При каждом добавлении или изменении данных в системе вы получаете уведомление, поэтому можете решать, нужно ли их загружать. Чтобы это стало возможным, система-источник должна быть оснащена механизмом автоматизации или иметь управляемую событиями структуру с веб-хуками.
Инкрементное извлечение. Некоторые источники данных не могут отправлять уведомления в случае появления обновлений, но могут выявлять изменённые записи и предоставлять выдержку из этих записей. Это может включать в себя извлечение только тех строк и столбцов данных, которые были добавлены или изменены после последнего извлечения, или только тех записей, которые были добавлены или изменены в файле.
Оба инкрементных паттерна часто используются, когда есть цель хранить актуальную локальную копию информации, или когда источник данных очень велик и извлечение всех данных было бы непрактичным.
Хотя ELT чаще всего используется с неструктурированными данными, информация может поступать из различных структурированных и неструктурированных источников, например, баз данных SQL или NoSQL, систем CRM и ERP, текстовых файлов и документов, электронных писем, веб-страниц, SaaS-приложений и IoT-систем.
Load (загрузка)
Этап «load» (загрузки) включает в себя загрузку извлечённых данных в центральный репозиторий, например, в хранилище данных или озеро данных. Для этого используется инструмент или скрипт, загружающий данные в репозиторий.
Полная загрузка. Это процесс загрузки в целевой репозиторий всех доступных данных конкретного источника данных.
Инкрементная загрузка. С определёнными интервалами в репозиторий регулярно загружаются только новые или модифицированные данные.
Потоковая загрузка. Это процесс загрузки данных в репозиторий в реальном времени, по мере их доступности. Он может включать в себя загрузку данных из источника данных в процессе её генерации или изменения.
После того, как данные достигают места назначения, они находятся в полном вашем распоряжении для преобразований, зависящих от проекта и требований.
Transform (преобразование)
Этап «transform» (преобразования) включает в себя применение к данным различных преобразований, чтобы они были удобны для анализа и отчётности.
Может выполняться множество различных типов преобразований данных, и конкретные изменения зависят от потребностей и задач организации. Вот несколько примеров возможных преобразований.
Очистка. Это процесс выявления и исправления или удаления неточностей и несогласованностей в данных. Очистка данных часто необходима, поскольку данные становятся «грязными» или повреждёнными вследствие ошибок, дублирования и других проблем.
Агрегирование. Это комбинирование данных из нескольких записей или источников для создания агрегированных данных. Примеры: суммирование общего количества продаж за указанный период или вычисление средней стоимости транзакции.
Фильтрация. Это процесс выбора подмножества данных на основании определённых критериев. Например, можно фильтровать данные, отображая записи только о клиентах в определённых регионах или с определённым уровнем активности.
Объединение. Это процесс комбинирования данных из нескольких таблиц или источников на основании общего ключа или атрибута. Например, потребитель данных может объединить таблицу данных о клиентах с таблицей данных о заказах, чтобы создать единую таблицу информации.
Нормализация. Это преобразование данных в единообразный формат или структуру: можно нормализовать даты в определённый формат или преобразовывать валюты в единую базовую валюту.
Обогащение. Это процесс добавления к данным внешних данных или контекста (метаданных). Например, можно добавлять демографические данные в записи о клиентах или географические данные в данные о продажах.
Разумеется, три этапа ELT не происходят сами по себе: для выполнения операций или автоматизации необходимы эффективные инструменты.
Инструменты создания конвейера ELT
К счастью для дата-инженеров и других задействованных в процессе специалистов, существует множество инструментов и технологий, которые можно использовать для создания конвейера ELT. Выбор зависит от конкретных потребностей и нужд. Ниже приведено несколько примеров технологий, которые можно использовать.
Apache Airflow
Apache Airflow — это опенсорсная платформа, позволяющая пользователям создавать конвейеры или процессы дата-инжиниринга, в том числе процессы ELT, а также управлять ими.
Дэшборд Airflow DAG
В Apache Airflow можно использовать DAG (Directed Acyclic Graph, направленные ациклические графы) для автоматизации рабочих процессов ELT, что гарантирует их выполнение в нужном порядке и в нужное время. Можно устанавливать зависимости между задачами, планировать выполнение задач в определённые интервалы времени и повторно запускать задачи в случае сбоев. Также можно использовать DAG для мониторинга состояния процессов и получения уведомлений в случае сбоев.
Airflow предоставляет и другие полезные возможности, например, отправку уведомлений по электронной почте в случае возникновения определённых событий и поддержку параллельного выполнения задач. Все эти возможности упрощают создание и поддержку процессов ELT.
Можно установить это ПО бесплатно или обратиться к поставщику, чтобы получить freemium-версию.
Matillion
Matillion — это ELT-инструмент, предназначенный для использования с облачными хранилищами данных наподобие Amazon Redshift, Google BigQuery, Snowflake и Azure Synapse. Она позволяет управлять задачами преобразования данных и находится между источниками сырых данных и инструментами business intelligence и аналитики.

Matillion Observability Dashboard предоставляет информацию о состоянии задач ELT
Matillion имеет удобный интерфейс для создания и планирования задач ELT. Интерфейс в стиле drag-and-drop позволяет автоматизировать процесс передачи и преобразования данных, поэтому пользователям не нужно писать код. Также он имеет тариф pay-as-you-go без необходимости оплаты за длительный срок пользования. Этот инструмент масштабируем, поэтому подходит для больших объёмов данных.
Существует четыре тарифных плана, в том числе и бесплатная модель. Самый дешёвый план начинается с $2 за кредит.
Hevo
Hevo Data — это инструмент интеграции данных, работающий по принципу no-code, являющийся полностью управляемым решением для задач ELT, то есть он выполняет процесс передачи и преобразования данных без необходимости писать код. Он может быстро передавать данные от более чем ста источников (сорок с лишним можно использовать бесплатно) в нужную систему обработки данных. После чего данные можно очищать и упорядочивать для анализа.

Дэшборд конвейера Hevo ELT
В ELT-методологии Hevo используются модели и процессы для преобразования данных и применяется интуитивный интерфейс внесения преобразований. Этот инструмент надёжен, автоматически управляет схемами и прост в использовании. Hevo можно масштабировать до обработки с минимальными задержками миллионов записей в минуту. Также он поддерживает инкрементную загрузку данных и мониторинг в реальном времени. Hevo имеет интерактивную службу поддержки через чат, электронную почту и телефон.
Существует три тарифных плана, в том числе один бесплатный.
Как создать и оптимизировать конвейер ELT
Если вы запутались и не знаете, с чего начать работу с процессами ELT, то ниже приведены общие рекомендации по созданию и оптимизации конвейера.
Определитесь с масштабами и задачами конвейера
Чётко обозначьте цель конвейера ELT и данных, которые он будет извлекать, загружать и преобразовывать. Это поможет вам спроектировать конвейер и выбрать подходящие инструменты и технологии.
Выберите подходящие инструменты и технологии
Выберите инструменты и технологии, лучше всего подходящие под ваши потребности. Учтите такие факторы, как тип и объём данных, сложность логики преобразований, требования к производительности и масштабируемости.
Выполняйте эффективное извлечение данных
Оптимизируйте процессы извлечения данных, чтобы минимизировать время и ресурсы, необходимые для получения этих данных из исходных систем. Для этого может потребоваться использовать специальные экстракторы или оптимизировать SQL-запросы, применяемые для получения данных.
Составьте стратегию загрузки данных
Выберите подходящую стратегию загрузки данных на основании объёма и скорости передаваемых данных. Например, можно использовать пакетную загрузку больших объёмов данных из реляционных баз данных, и в то же время выполнять потоковую передачу непрерывно генерируемых данных, которые должны становиться доступными мгновенно.
Определитесь с преобразованиями
Подумайте, как оптимизировать процессы преобразования данных и управлять ими, чтобы минимизировать время и ресурсы, необходимые для преобразования. Для этого могут потребоваться конфигурирование SQL-запросов, параллельная обработка и распределённые вычисления.
Выполняйте мониторинг конвейера
Выполняйте мониторинг показателей конвейера ELT и выявляйте узкие места или проблемы, снижающие его эффективность. Используйте эту информацию для оптимизации конвейера и повышения его показателей.
Производите тестирование ELT
Тщательно тестируйте конвейер ELT, чтобы гарантировать его правильное функционирование и генерацию точных результатов. Тестирование ELT — важный этап разработки и поддержки процесса ELT, поскольку он помогает обеспечить высокое качество загружаемых и преобразуемых данных, а также может использоваться для анализа вниз по потоку и принятия решений.
Существует множество полезных инструментов тестирования ELT.
JUnit — фреймворк модульного тестирования для языка программирования Java. В контексте тестирования ELT фреймворк JUnit можно использовать для тестирования отдельных модулей кода, отвечающих за процессы ELT.
Selenium — опенсорсный инструмент, свободно доступный под лицензией Apache License 2.0. В первую очередь он предназначен для тестирования веб-приложений. Selenium может использоваться для автоматизации процесса извлечения данных из веб-источников или для тестирования функциональности процессов ELT, в которых задействуются веб-источники данных.
Postman — это инструмент, позволяющий разработчикам разрабатывать и проверять API. Его можно использовать для тестирования API, являющихся частью процессов ELT.
Существует множество разных инструментов для тестирования ELT, и их выбор зависит от конкретных потребностей и ограничений проекта. Они могут включать в себя инструменты обеспечения качества данных, инструменты автоматизации тестирования и даже ручное тестирование.
Подведём итог: процессы и инструменты ELT необходимы для любой организации, стремящейся максимально повысить ценность своих данных и принимать решения на основании точной и актуальной информации.
Понравилась статья? Еще больше информации на тему данных, AI, ML, LLM вы можете найти в моем Telegram канале.
- Как подготовиться к сбору данных, чтобы не провалиться в процессе?
- Как работать с синтетическими данными в 2024 году?
- В чем специфика работы с ML проектами? И какие бенчмарки сравнения LLM есть на российском рынке?
