
Разработка собственной Kubernetes-платформы — большой и сложный проект со множеством взаимодействующих компонентов. В процессе неизбежно сталкиваешься с различными трудностями. Иногда их даже создаешь себе сам. В статье кратко рассмотрим три проблемы, с которыми нам пришлось столкнуться во время подготовки Deckhouse 1.43 к релизу, как мы их устраняли и какие выводы из всего этого сделали.

Перезапуск подов из-за ошибки в containerd
Проблема
Началось все с ошибки в upstream-версии containerd 1.6.14, которая коварно проникла в DH 1.43 и доехала до Stable незамеченной.
Баг заключался в рассинхронизации информации о поде на диске при обновлении указателя на его sandbox. К сожалению, заметить его можно было только после рестарта kubelet’а. Мы сразу выпустили фикс, но все оказалось глубже, чем просто рестарт проблемного containerd и последующий перезапуск kubelet’а.
Поды, создававшиеся в тот момент, когда в кластере был релиз с ошибкой, оставались с неправильной спецификацией. В результате kubelet после рестарта начинал перезапускать и эти поды. Проблема затронула все релизные каналы Deckhouse от Alpha до Stable.
Мы узнали о происходящем после выката Deckhouse 1.44 в каналы Alpha и Beta. В нем версия Kubernetes обновилась до 1.23 — соответственно, kubelet перезапустился и «убил» все «неправильные» поды в кластерах (включая клиентские), что привело к простоям.
Решение
Осознав размах проблемы, мы поняли, что самый простой путь ее решения — вручную перезапустить все поды. С помощью небольшого скрипта (под наблюдением дежурного, чтобы исключить простои) перебрали все поды и вручную перезапустили проблемные.
После чего в патче 1.43.8 обновили версию containerd до 1.6.18 — в ней эта проблема уже была устранена.
Как избежать подобных ошибок в будущем
На момент обновления в Deckhouse информация об ошибке в upstream-компоненте уже появилась в Сети. Было решено непосредственно перед выкатом проверять changelog той версии компонента, на которую мы переходим в релизе.
Неработающая авторизация в Alertmanager
Проблема
Обновили сертификат kube-rbac-proxy, но забыли добавить его в сайдкар-контейнер Alertmanager'а. В результате при проверке сертификатов kube-rbac-proxy использовал старый CA и возвращал ошибку авторизации.
Проблема обнаружилась в версии 1.42.6 — мы узнали о ней из телеграм-чата по Deckhouse.
Решение
Фикс был проведен в версии 1.42.7 и затем перенесен в 1.43.2.
Как избежать подобных ошибок в будущем
Было решено перенести kube-rbac-proxy в helm_lib. Это избавит нас от необходимости проводить множество одинаковых правок в разных местах, и, соответственно, значительно снизит вероятность ошибок. Свежая версия kube-rbac-proxy будет «подтягиваться» в Deckhouse, и правки автоматом «приедут» во все нужные места.
Также мы в очередной раз поняли, насколько важна оперативная обратная связь от пользователей и насколько полезным решением был выпуск community-версии Deckhouse в виде Open Source.
Проблемы с Istio на Ubuntu 18.04
Предыстория
В Linux есть две независимых реализации сетевого фильтра iptables: iptables-nft (nftables) и iptables-legacy (всем привычный iptables). Это два разных модуля ядра, отвечающих за маршрутизацию сетевых пакетов.
iptables-nft непривычен для тех, кто привык к классическому iptables. Поэтому разработчики ядра сделали эмуляцию старого формата с помощью нескольких утилит (iptables-translate, iptables-restore-translate, iptables-nft-restore), транслирующих привычные правила iptables в nft-формат.
Например, правило:
iptables -A INPUT -i eth0 -p tcp --dport 80 -j DROPбудет приведено к такому формату:
nft add rule ip filter INPUT iifname "eth0" tcp dport 80 counter droи уже затем попадет в ядро.
В отличие от правил iptables, nft-формат — это JSON. Например, посмотреть текущие правила в системе можно посмотреть так:
$ cat /etc/nftables.conf
#!/usr/sbin/nft -f
flush ruleset
table inet filter {
chain input {
type filter hook input priority 0;
}
chain forward {
type filter hook forward priority 0;
}
chain output {
type filter hook output priority 0;
}
}Этот файл может быть огромным. Разобраться, что к чему, в таком файле практически невозможно, поэтому многие предпочитают использовать привычные инструменты, такие как iptables -A.
В ОС для управления системой фильтрации сетевых пакетов имеется одноименная команда iptables. С ее помощью можно просматривать/редактировать существующие таблицы маршрутизации и создавать новые.
Вот так выглядит список существующих правил, выведенных этой командой:
$ sudo iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy DROP)
target prot opt source destination
DOCKER-USER all -- anywhere anywhere
DOCKER-ISOLATION-STAGE-1 all -- anywhere anywhere
ACCEPT all -- anywhere anywhere ctstate
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
Chain DOCKER (2 references)
target prot opt source destination
ACCEPT tcp -- anywhere 172.20.0.2 tcp dpt:https
ACCEPT tcp -- anywhere 172.20.0.2 tcp dpt:httpВ зависимости от дистрибутива по умолчанию может быть включен nftables или iptables-legacy. Также могут быть включены сразу оба формата, а команда iptables просто ссылаться на один из них. Аналогично и с iptables-restore.
Одной из особенностей этих двух систем можно назвать их параллельную работу. Т.е. пользователь может писать правила и в одну, и в другую, и обе системы будут работать независимо друг от друга.
Более того, они даже не будут мешать друг другу: можно одновременно добавить разрешающее правило в одну систему и запрещающее — в другую. Отработают оба, но какое из них будет первым — мы так и не поняли.
Проблема
Istio для перехвата запросов настраивает DNAT, перенаправляя исходящие запросы на порт 15001, а входящие — на 15006.
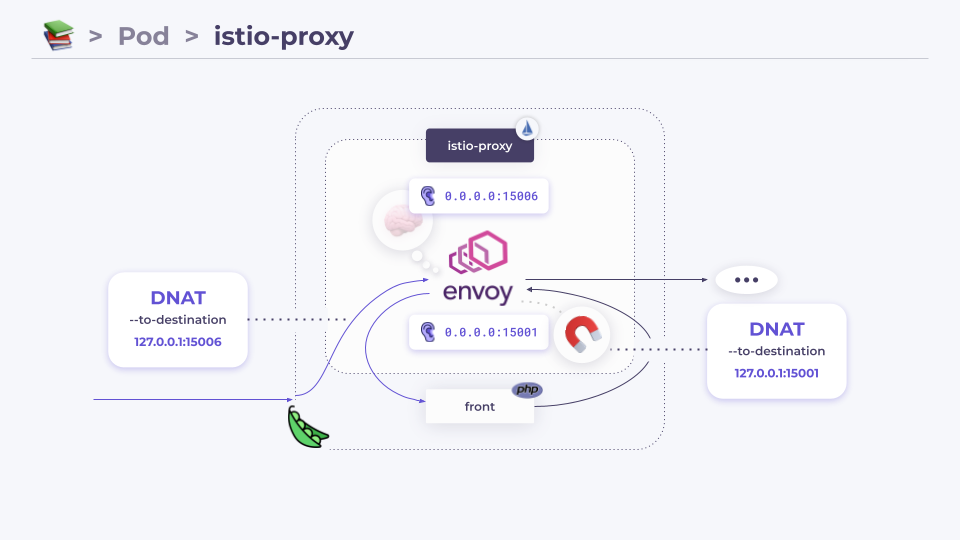
За настройку DNAT'ов отвечает init-контейнер: к каждому поду добавляется initContainer, выполняющий команды iptables-restore для цепочки из десятка файлов. Эти команды добавляются в ядро, причем по умолчанию используется nftables.
На современных дистрибутивах все работает как положено, но на некоторых устаревших CentOS-подобных системах возникает следующая ошибка:
2023-01-18T17:17:47.706257Z info Running command: iptables-restore --noflush /tmp/iptables-rules-1674062267706031953.txt694377717
2023-01-18T17:17:47.728011Z error Command error output: xtables resource problem: line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or directory): table nat
line 24: TABLE_ADD failed (No such file or dire
2023-01-18T17:17:47.728076Z error Failed to execute: iptables-restore --noflush /tmp/iptables-rules-1674062267706031953.txt694377717, exit status 4При этом iptables в таких условиях работает нормально.
Решение (не удалось)
В качестве возможного решения мы воспользовались iptables-wrapper. Он определяет правильный iptables системы и меняет соответствующий симлинк. К сожалению оказалось, что скрипт не рассчитан на работу внутри пода и может работать только внутри host network.
Тогда мы написали свой wrapper, который пытался использовать iptables-restore с nftables, а если это приводило к ошибке — переключался на iptables-legacy. Самое главное — он работал в проблемном дистрибутиве.
Увы, с другими дистрибутивами нам не повезло: правила добавлялись, но не действовали. То есть скрипт срабатывал, записывал правило в nftables (и оно там действительно появлялось — его можно увидеть), но по какой-то причине вместо nftables запускался iptables-legacy.
После нескольких неудачных попыток найти корень проблемы и заставить систему работать как положено решили отказаться от всей затеи и вернуться к upstream-версии: там все правила помещаются только в nftables. Дистрибутивы, которые так не умеют, считаются неподдерживаемыми. Понять, что возникли проблемы, можно по состоянию проблемного пода — он будет висеть с ошибкой CrashLoopBackOff.
Как избежать подобных ошибок в будущем
Этот случай заставил нас задуматься о необходимости расширить покрытие e2e-тестами для проверки различных конфигураций.
P.S.
Читайте также в нашем блоге:
