Всем привет! На связи снова отдел продуктовой аналитики Одноклассников. Меня зовут Виктория Гордеева, я руковожу этим отделом, и сегодня я бы хотела поделиться нашими болями при проведении А/B-тестов.
A/B-тесты во многих кейсах сопровождаются разными проблемами — высокой дисперсией в метриках, недостаточным количеством пользователей, некорректной работой «сплитовалки». Для ОК наиболее частой проблемой было нарушение предпосылки SUTVA (Stable Unit Treatment Value Assumption) — из-за большой активности аудитории нам было сложно исключить сетевые эффекты (Network effect) с влиянием одного участника эксперимента на другого. Об этом и поговорим :)
Наш дар и наш крест: особенности ОК в контексте A/B-тестов
Наша ежемесячная аудитория в России превышает 36 млн уникальных пользователей, и все эти пользователи активно взаимодействуют друг с другом — каждый день создается более 1 миллиона дружб, отправляется около 66 миллионов сообщений, публикуется более 7 миллионов постов, просматривается в ленте свыше 3 миллиардов постов. Это классные продуктовые показатели, но в контексте проведения A/B-тестов такая активность аудитории значит, что исключить появление сетевых эффектов сложно, как и снизить их влияние на проводимые эксперименты.
С сетевыми эффектами мы сталкиваемся при проведении экспериментов самых разных категорий, ниже рассмотрим самые часто встречающиеся.
Эксперименты, влияющие на фидбэк и общение
Например, мы запускаем эксперимент, в результате которого пользователи в тесте начинают писать больше сообщений. Но рост отправки сообщений в тесте влияет и на пользователей из контрольной группы, так как они, в том числе, являются получателями этих «добавочных» сообщений, возникших в результате эксперимента. В итоге метрики меняются в двух группах, оценивать эксперимент становится сложно, а объективность результатов снижается.
Эксперименты, влияющие на пуши
Ситуация с ростом отправок пушей очень похожа. Мы проводим эксперимент, одним из результатов которого становится увеличение активности пользователей, приводящей к отправке пушей — о появлении друга в онлайне, новых постах, действиях в группах или любых других. Но пуши, как и сообщения, неизбежно затрагивают людей как из тестовой группы, так и из контрольной. Результат аналогичный — метрики активности меняются в двух группах и оценивать эксперимент становится проблематично.
Эксперименты, связанные с большими релизами
«Громкие запуски» (например, появление нового большого раздела на сайте) почти как кот в мешке — удержать их только в тесте очень сложно. Например, условный Петя Петров пишет своему другу Ивану Иванову впечатления о новой ленте, а друг не попал в тестовую выборку и не видит нововведений. В итоге Иван Иванов в замешательстве пишет другим друзьям, в ленте, в поддержку. И при каждом таком релизе подобных случаев может быть сотни, что тоже влияет на искажение метрик.
Эксперименты с ранжированием ленты новостей
Самый сложный продукт с точки зрения сетевых эффектов — это лента новостей ОК. При запуске экспериментов на изменение алгоритмов ранжирования появление сетевых эффектов практически неизбежно.
Например, мы запускаем A/B-тест, в ходе которого сравниваем две модели ранжирования: старая сортирует контент по вероятности лайка (у нас реакции называются «классы»), новая — по максимизации времени в ленте (timespent). Для эксперимента рандомно подбираем независимых пользователей в контрольную и тестовую группы с одинаковым распределением всех ключевых характеристик. И для теста, и для контроля наполняем ленту контентом с аналогичным соотношением:
50% — прямой контент, то есть, который возникает в результате непосредственно действия создания контента. Это посты про загрузку фотографии, написание текстового поста, заливку видео, добавление музыки.
50% — контент второго круга, то есть посты о действии с уже существующим контентом, то есть о лайках, репостах, комментариях.

Для наглядности оцениваем только две метрики — лайки и timespent. Они должны гарантированно меняться, потому что старая модель ранжирования нацелена на увеличение лайков, а новая — на увеличение времени.

Поначалу все хорошо и ожидаемо, в тесте растет timespent и падают лайки. А дальше в дело вступает сетевой эффект, и эксперимент превращается в головоломку:
Поскольку в новой модели количество лайков уменьшается, значит становится меньше кандидатов для контента второго круга. Сокращение числа кандидатов отражается не только на тестовой, но и на контрольной выборке.
В контроле изменяется баланс типа контента в ленте (например, контента второго круга становится 30%, а прямого — 70%). Это влечет изменение timespent и лайков. В свою очередь, это влияет на тест — там тоже меняется баланс контента, показатели timespent и лайков, при этом мы даже не можем однозначно спрогнозировать, как именно они изменятся.
Дальше этот цикл самовоспроизводится до достижения какого-то хрупкого равновесия.

В итоге вместо интерпретируемых и объективных результатов эксперимента аналитик получает путаницу, с которой невозможно работать.
Муки выбора или поиск метода борьбы с сетевыми эффектами
В поисках способов борьбы с сетевыми эффектами мы начали изучать подходы, которые часто используют другие компании.
До vs после
Самый простой метод оценки влияния экспериментов — сравнение метрик до и после его запуска. Это простой подход, который легко внедрить и использовать. Но в контексте социальной сети у него больше минусов, чем плюсов:
Для полноценной оценки с учетом полного масштаба сетевых эффектов нужно раскатить изменения на всю соцсеть, потому что иначе не получить достаточную точность.
Сложно получить высокую чувствительность метрик из-за внешних факторов, которые могут оказать влияние. Например, мы сравниваем метрики по двум датам, но вторым днем может оказаться дождливый выходной день, когда активность аудитории и без новых запусков будет выше. Получить объективную оценку в таких условиях сложно.
«Натуральная» кластеризация
Также мы рассматривали «натуральную» кластеризацию — это метод, который подразумевает поиск плотно связанных кластеров, образовавшихся естественным образом. Пример такой кластеризации — разделение пользователей по странам.
На первый взгляд это хороший вариант получения изолированных друг от друга кластеров. Но и здесь есть ряд ограничений.
Кластера сложно масштабировать — если вдруг окажется, что для проведения A/B-теста нужно больше пользователей, придется вручную искать другие страны и перенастраивать эксперимент.
Кластера могут сильно отличаться поведенчески — даже если подобрать страны с похожими показателями DAU и MAU, а также соотношением полов и возрастов, это не гарантирует, что они одинаково используют социальную сеть. К тому же на метрики могут влиять национальные праздники и другие внешние факторы, которые в каждой стране свои.
Кластера могут быть слабо замкнутыми — например, пользователи из Беларуси часто взаимодействуют с пользователями из России, что уменьшает степень изоляции кластеров и влияет на метрики.
В результате и от этого метода мы отказались.
Обычная кластеризация
В простой кластеризации на первый взгляд все очевидно — нужно выделить кластера пользователей, сравнить их, запустить эксперимент и получить результат. Но, опять же, в контексте нашей соцсети такой подход не работает. Причин несколько.
Разные модели кластеризации дают значимо разные результаты выборок. Сценарий проведения тестов нельзя унифицировать и применять всегда — даже работающий вариант в какой-то момент не подойдет под новый эксперимент, из-за чего результаты старых и новых тестов будут не сопоставимыми.
Часто приходится выбирать между изолированностью кластеров друг от друга и качеством проводимого эксперимента — показатели одного из двух параметров неизбежно будут низкими.
Из-за небольшого количества кластеров можно получить низкий уровень MDE (Minimum Detectable Effect, минимальный обнаруживаемый эффект) и зашумленность тестируемых метрик.
С такими ограничениями мы не были готовы мириться, поэтому и от метода простой кластеризации мы тоже отказались.
Switchback-тестирование
Switchback-тестирование — хороший метод работы с сетевыми эффектами, но подходит он только для тестирования продуктов, у которых есть физическое взаимодействие в офлайне. Например, его применяют для таких продуктов, как такси, доставки, курьерские службы.
Подробнее о Switchback-тестировании можно прочитать здесь.
В нашем случае нет изолированных гео-зон, поэтому Switchback-тестирование нам не подошло.
Отчаяние и тлен или …
После первичного анализа вариантов казалось, что ни один из методов нам не подходит. В этот момент можно было опустить руки и продолжить жить с сетевыми эффектами. Но мы выбрали другой путь — пошли искать дальше.
В результате таких поисков мы нашли метод эго-кластеризации, который предложил Linkedin.
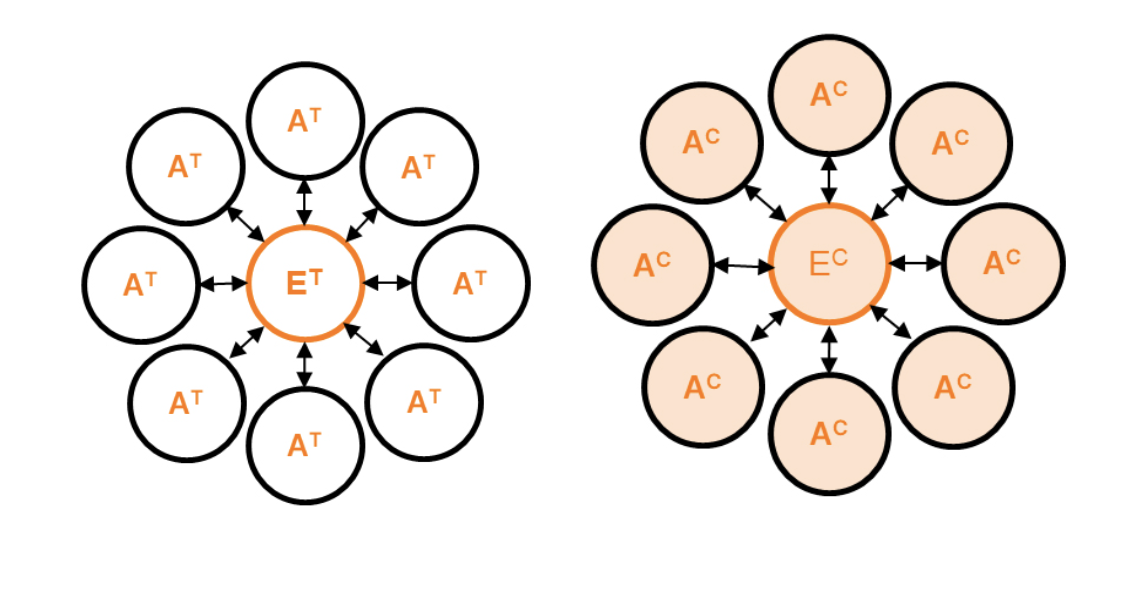
В отличие от обычный кластеризации, при которой все пользователи должны быть равны между собой, эго-кластеризация подразумевает, что кластер формируют эго-вершина и альтер-вершины, которые взаимодействуют с эго-вершиной и связаны с ней. Причем:
эго-вершина — пользователь, подходящий под критерии эксперимента;
альтер-вершины — пользователи, с которыми взаимодействует эго-вершина.
Такая кластеризация строится с использованием какого-либо графа взаимодействий, например, графа дружб, в котором каждый пользователь имеет много связей.
Алгоритм формирования эго-кластеров довольно простой. Так, нужно собрать граф и для каждой вершины графа и провести небольшие вычисления.
Если вершина не задействована в других кластерах, считаем:
degree — общее количество соседей вершины в графе, то есть потенциальных альтер-вершин;
free_degree — общее количество «неиспользованных» в других эго-кластерах соседей вершины в графе.
При этом мы учитываем ключевой параметр качества N, который указывает процент альтер-вершин из всех потенциальных, который обязательно нужно использовать. Например, когда нужно использовать 70% альтер-вершин.
Следом проводим вычисления.
Если free_degree/degree > N — сохраняем кластер из текущей вершины и всех ее неиспользованных соседей, и помечаем, что вершина и ее соседи использованы.
Если free_degree/degree < N — ничего не делаем.
После формирования эго-кластеров нужно решить, как именно запустить эксперимент, в зависимости от того, что нужно оценить.
Запуск и на эго-вершины, и на альтер-вершины в тесте

В таком случае, поскольку эксперимент охватывает и эго-вершины и ближайших соседей, имитируется запуск фичи на весь портал (всю соцсеть) — все ближайшие пользователи, с которыми взаимодействует эго-вершина, тоже получают фичу и оказывают свое влияние.
На контрольную выборку фича влияния не оказывает. Это дает возможность сравнивать эго-вершины в тесте и в контроле, чтобы оценить полный эффект от эксперимента на портал при его включении на 100% аудитории.
Запуск на альтер-вершины в тесте без включения на эго-вершины
Такой подход позволяет определить чистый сетевой эффект и оценить, насколько соседи влияют на эго-вершины при включении какой-то фичи.

Запуск на альтер-вершины в тесте
Эту реализацию можно обсчитать при запуске любым из описанных выше способов, так как во всех случаях альтер-вершины включаются в тест. Фактически подобный сценарий запуска эксперимента позволяет провести простой A/B-тест и сравнить альтер-вершины теста и контроля. За счет этого можно увидеть, как отличаются метрики при запуске обычного A/B-теста от запуска по эго-кластерам.
Ограничения и проблемы
В каждой бочке меда есть ложка дегтя, поэтому несмотря на все удобство метода эго-кластеризации, мы также понимали, что у этого метода есть ряд особенностей, которые следует учитывать.
Нужно заранее понимать свой граф. Не важно какой граф используется, и какой набор пользователей собран — без знания графа применять эго-кластеризацию не получится. И да, к выбору графа надо подходить творчески, не ограничивая себя только стандартными вещами типа графа дружб или графа сообщений — для разных продуктов могут быть разные графы, в том числе и варианты, которые не лежат на поверхности.
Не подходит для экспериментов на расширение графа. Например, мы не можем измерять эксперименты, которые направлены на увеличение дружб, поскольку граф фиксированный — мы не увидим, завел ли пользователь новых друзей после запуска теста.
Оценивается эффект только на первый круг графа. Модель позволяет считать только эго-вершину и альтер-вершины. При этом у каждой альтер-вершины на более низком уровне есть свои альтер-вершины, которые игнорируются, что иногда усложняет оценку теста. Например, с этим мы столкнулись при запуске «Моментов» (нового сервиса внутри ОК для публикации вертикальных фото и видео, которые исчезают через 24 часа) — поскольку на начальных этапах пользователи и из альтер- и из эго-групп мало использовали «Моменты», эффект от запуска было оценить сложно.
Низкий уровень MDE или необходимость большой аудитории. Чтобы видеть интересующий нас уровень эффекта, нужна внушительная аудитория для формирования кластеров. Но даже это в нашем случае спасает не всегда — по некоторым метрикам мы предпочитаем отслеживать изменение на 0,1% и меньше, но этого не всегда можно добиться на том количестве графов, которые мы можем у себя сформировать.
Не подходит для долгосрочных экспериментов. Граф со временем может размываться, поэтому эго-кластеризация не подходит, если эксперимент надо держать несколько месяцев.
Чтобы хотя бы частично преодолеть эти ограничения, мы применяем несколько параметров запуска.
Loss rate. Это доля от общего числа альтер-вершин, которую допустимо не использовать в эксперименте. Как правило, мы задаем этот параметр в диапазоне 20-40%. То есть, если у эго-вершины 100 потенциальных альтер-вершин, мы допускаем, что в кластер войдет от 60 до 80 альтер-вершин.
Ignored vertices degree. Это параметр, который позволяет выявить и отсеять эго-вершины, у которых число альтер-вершин превышает допустимый лимит. Например, проигнорировать эго-вершину, если у нее 2000 потенциальных альтер-вершин. Это нужно, потому использование таких эго-вершин повышает алгоритмическую нагрузку, а также задействует слишком много альтер-вершин, делая их недоступными для включения в другие кластера.
Bins count. Это технический параметр, который останавливает алгоритм, когда в одной из нод заканчиваются пользователи. Это позволяет получить равномерную кластеризацию и снизить дисперсию между кластерами.
От теории к практике: примеры запусков по эго-кластерам
Эго-кластеризация стала одним из основных подходов, позволяющим нам проводить эксперименты без искажения результатов из-за сетевых эффектов. Приведу несколько примеров.
Запуск акции «Верни друга»
Мы запускали акцию «Верни друга», в рамках которой активные пользователи ОК могли отправить неактивным пользователям уведомление с приглашением вернуться в ОК и бесплатно получить доступ к сервису «Всё включено», который позволяет дарить подарки и пользоваться другими внутренними услугами.
Эго-кластеризация помогла нам собрать непересекающиеся наборы «Активный юзер — неактивные друзья» и, как результат, оценить чистый результат от проведения акции.
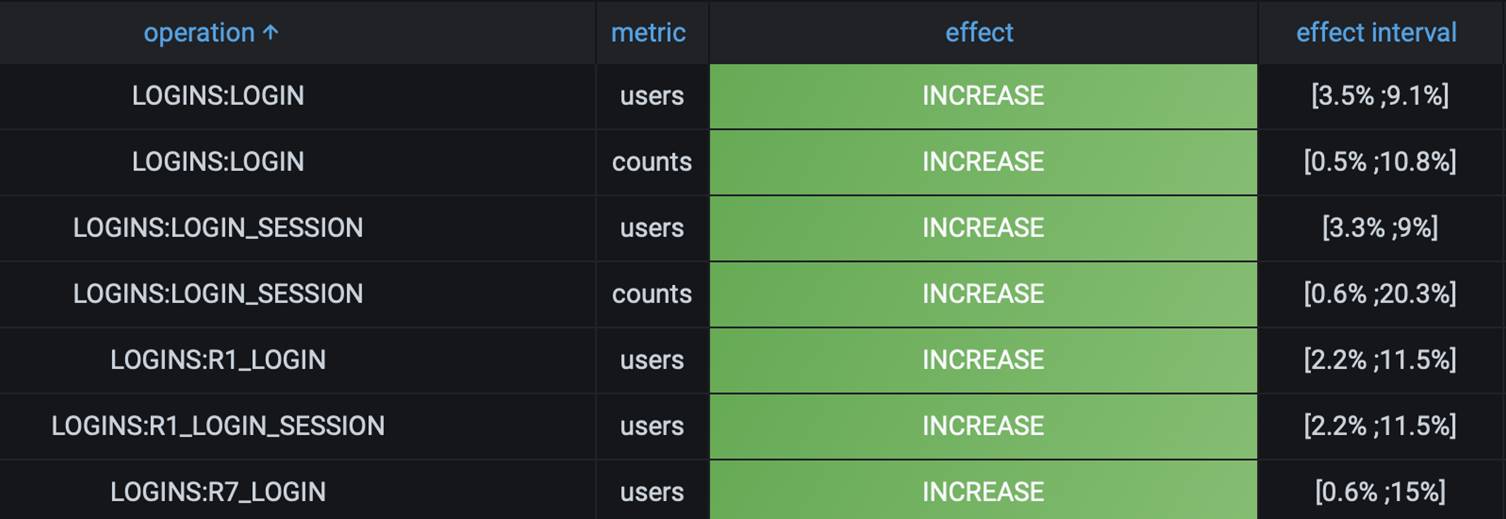
Благодаря корректному формированию кластеров, мы смогли увидеть хороший прирост по возвратам на первый и седьмой день. Все показатели отслеживали через нашу A/B-платформу. Почитать о ней подробнее можно в материале моей коллеги.
«Всё включено» и дни рождения
Мы проводили эксперимент, в рамках которого хотели оценить, как меняются метрики подарков в зависимости от доступности сервиса «Всё включено» именинникам и их друзьям. Для этого нам нужно было сформировать независимые кластеры из именинников и их друзей, чтобы проверить разные варианты выдачи доступа к сервису «Всё включено» — только именинникам, только друзьям, всем сразу.
Эго-кластеризация помогла нам сформировать непересекающиеся наборы «Именинник — близкие друзья» и оценить разные конфигурации, не задевая одних и тех же именинников по несколько раз.
В результате теста мы обнаружили, что в одной из конфигураций первые покупки подарков выросли на 300% в день.
Примечательно, что для этого эксперимента мы считали динамический граф, поскольку именинники меняются каждый день. Соответственно, граф с эго-кластерами пересчитывался каждый день.
Борьба с токсичностью
Мы активно боремся с токсичностью внутри ОК. Один из способов такой борьбы — выдача mute пользователям, которые используют нецензурную лексику. Это сложная задача, поскольку в рамках одного обсуждения в комментариях использовать мат могут несколько пользователей и важно исключить ситуацию, при которой один собеседник получает mute, а другой — нет.
Эго-кластеризация позволила нам сформировать изолированные друг от друга группы любителей ругаться — это нужно, чтобы отделить пользователей из разных групп и работать с ними независимо.
Как результат, при тестировании методов борьбы с токсичностью мы исключаем искажения эффекта на метрики из-за ощущения несправедливости.
Эксперименты с ранжированием ленты
Эго-кластеризацию мы также применяем во время экспериментов с ранжированием ленты. Наша внутренняя статистика показывает, что в случае хорошей работы модели в сравнении с оценкой посредством классического А/B-теста:
метрики времени при оценке по эго-кластерам могут показывать разницу в 30% или более;
метрика просмотров вырастает на ~50% или более.

Более того, в некоторых кейсах эго-кластеризация позволяет отслеживать дополнительные метрики, которые не видно в обычных экспериментах.
Итоги и рекомендации
Эго-кластеризация — универсальный метод, который можно применять под задачи разного типа и проводить эксперименты разной направленности, не сталкиваясь с сетевыми эффектами. Достоинство эго-кластеров в том, что они логически просты, легко масштабируются и позволяют оценивать эксперименты, которые иначе не оценить — в нашем случае каждое из этих преимуществ стало ключевым.
При этом начать работать с эго-кластерами довольно просто — надо оценить наличие сетевого эффекта (в том числе, если кажется, что его нет), выбрать граф для запуска, собрать кластера и получить профит.
Так что, если хотите попробовать эго-кластеризацию в своем проекте — дерзайте прямо сейчас.
