Введение
Новый набор SIMD инструкций для x86-процессоров Intel AVX был представлен публике ещё в марте 2008 года. И хотя реализации этих инструкций в железе ждать ещё полгода, спецификацию AVX уже можно считать устоявшейся, а поддержка набора инструкций AVX добавлена в новые версии компиляторов и ассемблеров. В данной статье рассмотрены практические вопросы оптимизации для Intel AVX подпрограмм на языках C/C++ и ассемблер.
Набор команд AVX
Все команды AVX, а также некоторые другие команды, описаны в справочнике, который можно найти на сайте Intel, посвященному AVX. В некотором смысле, набор команд AVX представляет собой расширение наборов команд SSE, которые уже поддерживаются всеми современными процессорами. В частности, AVX расширяет изначально 128-битные регистры SSE до 256 бит. Новые 256-битные регистры обозначаются как ymm0-ymm15 (для 32-битной программы доступны только ymm0-ymm7); при этом 128-битные SSE регистры xmm0-xmm15 ссылаются на младшие 128 бит соответствующего AVX регистра.
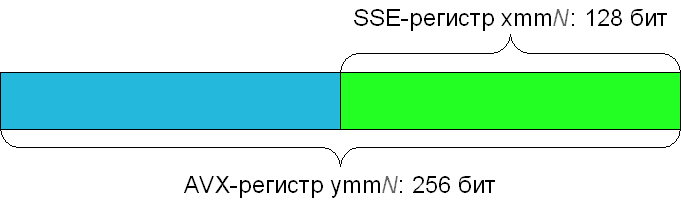
Чтобы эффективно работать с новыми 256-битными регистрами, в AVX было добавлено несметное количество инструкций. Однако, большинство из них представляет собой лишь немного изменённые версии уже знакомых нам инструкций SSE.
Так, каждая инструкция из SSE (а также SSE2, SSE3, SSSE3, SSE4.1, SSE4.2 и AES-NI) имеет в AVX свой аналог с префиксом v. Кроме префикса, такие AVX-инстукции отличаются от своих SSE-собратьев тем, что могут иметь три операнда: первый операнд указывает, куда писать результат, а остальные два — откуда брать данные. Трёхоперандные инструкции хороши тем, что во-первых позволяют избавиться от лишних операций копирования регистров в коде, а во-вторых упрощают написание хороших оптимизирующих компиляторов. SSE2-код
movdqa xmm2, xmm0
punpcklbw xmm0, xmm1
punpckhbw xmm2, xmm1может быть переписан с AVX как
vpunpckhbw xmm2, xmm0, xmm1
vpunpcklbw xmm0, xmm0, xmm1.При этом команды с префиксом v зануляют старшие 128 бит того AVX регистра, в который они пишут. Например, инструкция vpaddw xmm0, xmm1, xmm2 занулит старшие 128-бит регистра ymm0.
Кроме того, некоторые SSE-инструкции были расширены в AVX для работы с 256-битными регистрами. К таким инструкциям относятся все команды, работающие с числами с плавающей точкой (как одинарной, так и двойной точности). Например следующий AVX код
vmovapd ymm0, [esi]
vmulpd ymm0, ymm0, [edx]
vmovapd [edi], ymm0обрабатывает сразу 4 double.
Вдобавок, AVX включает в себя некоторые новые инструкции
- vbroadcastss/vbroadcastsd/vbroadcastf128 — заполнение всего AVX регистра одним и тем же загруженным значением
- vmaskmovps/vmaskmovpd — условная загрузка/сохранение float/double чисел в AVX регистр в зависимости от знака чисел в другом AVX регистре
- vzeroupper — обнуление старших 128 бит всех AVX регистров
- vzeroall — полное обнуление всех AVX регистров
- vinsertf128/vextractf128 — вставка/получение любой 128-битной части 256-битного AVX регистра
- vperm2f128 — перестановка 128-битных частей 256-битного AVX регистра. Параметр перестановки задаётся статически.
- vpermilps/vpermilpd — перестановка float/double чисел внутри 128-битных частей 256-битного AVX регистра. При этом параметры перестановки берутся из другого AVX регистра.
- vldmxcsr/vstmxcsr — загрузка/сохранение управляющих параметров AVX (куда ж без этого!)
- xsaveopt — получение подсказки о том, какие AVX-регистры содержат данные. Эта команда сделана для разработчиков ОС и помогает им ускорить переключение контекста.
Использование AVX в ассемблерном коде
На сегодня AVX поддерживается всеми популярными ассемблерами для x86:
- GAS (GNU Assembler) — начиная с версии binutils 2.19.50.0.1, но лучше использовать 2.19.51.0.1, которая поддерживает более позднюю спецификацию AVX
- MASM — начиная с версии 10 (входит в Visual Studio 2010)
- NASM — начиная с версии 2.03, но лучше использовать последнюю версию
- YASM — начиная с версии 0.70, но лучше использовать последнюю версию
Определение поддержки AVX системой
Первое, что нужно сделать перед использованием AVX — убедиться, что система его поддерживает. В отличие от разных версий SSE, для использования AVX требуется его поддержка не только процессором, но и операционной системой (ведь она должна теперь сохранять верхние 128-бит AVX регистров при переключении контекста). К счастью, разработчики AVX предусмотрели способ узнать о поддержке этого набора инструкций операционной системой. ОС сохраняет/восстанавливает контекст AVX с помощью специальных инструкций XSAVE/XRSTOR, а конфигурируются эти команды с помощью расширенных контрольных регистров (extended control register). На сегодня есть только один такой регистр — XCR0, он же XFEATURE_ENABLED_MASK. Получить его значение можно, записав в ecx номер регистра (для XCR0 это, естественно, 0) и вызвав команду XGETBV. 64-битное значение регистра будет сохранено в паре регистров edx:eax. Выставленный нулевой бит регистра XFEATURE_ENABLED_MASK означает, что команда XSAVE сохраняет состояние FPU-регистров (впрочем, этот бит всегда выставлен), выставленный первый бит — сохранение SSE-регистров (младшие 128 бит AVX регистра), а выставленный второй бит — сохранение старших 128 бит AVX регистра. Т.о. чтобы быть уверенным, что система сохраняет состояние AVX регистров при переключении контекстов, нужно убедиться, что в регистре XFEATURE_ENABLED_MASK выставлены биты 1 и 2. Однако, это ещё не всё: прежде, чем вызывать команду XGETBV, нужно убедиться, что ОС действительно использует инструкции XSAVE/XRSTOR для управления контекстами. Делается это с помощью вызова инструкции CPUID с параметром eax = 1: если ОС включила управление сохранением/восстановлением контекста с помощью инструкций XSAVE/XRSTOR, то после выполениния CPUID в 27-ом бите регистра ecx будет единица. Вдобавок, неплохо бы проверить, что сам процессор поддерживает набор инструкций AVX. Делается это аналогично: вызвать CPUID с eax = 1 и убедиться, что после этого в 28-ом бите регистра ecx находится единица. Всё вышесказанное можно выразить следующим кодом (скопированном, с небольшими изменениями, из Intel AVX Reference):
; extern "C" int isAvxSupported()
_isAvxSupported:
xor eax, eax
cpuid
cmp eax, 1 ; Поддерживает ли CPUID параметр eax = 1?
jb not_supported
mov eax, 1
cpuid
and ecx, 018000000h ; Проверяем, что установлены биты 27 (ОС использует XSAVE/XRSTOR)
cmp ecx, 018000000h ; и 28 (поддержка AVX процессором)
jne not_supported
xor ecx, ecx ; Номер регистра XFEATURE_ENABLED_MASK/XCR0 есть 0
xgetbv ; Регистр XFEATURE_ENABLED_MASK теперь в edx:eax
and eax, 110b
cmp eax, 110b ; Убеждаемся, что ОС сохраняет AVX регистры при переключении контекста
jne not_supported
mov eax, 1
ret
not_supported:
xor eax, eax
ret
Использование AVX-инструкций
Теперь, когда вы знаете, когда можно использовать AVX-инструкции, самое время перейти к их использованию. Программирование под AVX мало отличается от программирования под другие наборы инструкций, но нужно учесть следующие особенности:
- Крайне нежелательно смешивать SSE- и AVX-инструкции (в том числе AVX-аналоги SSE-инструкций). Чтобы перейти от выполнения AVX-инструкций к SSE-инструкциям процессор сохраняет в специальном кэше верхние 128 бит AVX регистров, на что может уйти полсотни тактов. Когда после SSE-инструкций процессор снова вернётся к выполнению AVX-инструкций, он восстановит верхние 128 бит AVX регистров, на что уйдёт ещё полсотни тактов. Поэтому смешивание SSE и AVX инструкций приведёт к заметному снижению производительности. Если вам нужна какая-то команда из SSE в AVX-коде, воспользуйтесь её AVX-аналогом с префиксом v.
- Сохранения верхней части AVX регистров при переходе к SSE-коду можно избежать, если занулить верхние 128 бит AVX регистров с помощью команды vzeroupper или vzeroall. Несмотря на то, что эти команды зануляют все AVX регистры, они работают очень быстро. Правилом хорошего тона будет использовать одну из этих команд перед выходом из подпрограммы, использующей AVX.
- Команды загрузки/сохранения выровненных данных vmovaps/vmovapd/vmovdqa требуют, чтобы данные были выровнены на 16 байт, даже если сама команда загружает 32 байта.
- На Windows x64 подпрограмма не должна изменять регистры xmm6-xmm15. Т.о., если вы используете эти регистры (или соответствующие им регистры ymm6-ymm15), вы должны сохранить их в стеке в начале подпрограммы и восстановить из стека перед выходом из подпрограммы.
- Ядро Sandy Bridge будет способно запускать на выполнение две 256-битные AVX-команды с плавающей точкой каждый такт (одно умножение и одно сложение) благодаря расширению исполнительных устройств до 256 бит. Ядро Bulldozer будет иметь два универсальных 128-битных исполнительных устройства для команд с плавающей точкой, что позволит ему выполнять одну 256-битную AVX-команду за такт (умножение, сложение либо совмещённое умножение и сложение (fused multiply-add); при использовании последней операции можно надеяться на такую же производительность, как и у Sandy Bridge).
Теперь вы знаете всё, чтобы писать код с использованием AVX. Например, такой:
; extern "C" double _vec4_dot_avx( double a[4], double b[4] )
_vec4_dot_avx:
%ifdef X86
mov eax, [esp + 8 + 0] ; eax = a
mov edx, [esp + 8 + 8] ; edx = b
vmovupd ymm0, [eax] ; ymm0 = *a
vmovupd ymm1, [edx] ; ymm1 = *b
%else
vmovupd ymm0, [rcx] ; ymm0 = *a
vmovupd ymm1, [rdx] ; ymm1 = *b
%endif
vmulpd ymm0, ymm0, ymm1 ; ymm0 = ( a3 * b3, a2 * b2, a1 * b1, a0 * b0 )
vperm2f128 ymm1, ymm0, ymm0, 010000001b ; ymm1 = ( +0.0, +0.0, a3 * b3, a2 * b2 )
vaddpd xmm0, xmm0, xmm1 ; ymm0 = ( +0.0, +0.0, a1 * b1 + a3 * b3, a0 * b0 + a2 * b2 )
vxorpd xmm1, xmm1, xmm1 ; ymm1 = ( +0.0, +0.0, +0.0, +0.0 )
vhaddpd xmm0, xmm0, xmm1 ; ymm0 = ( +0.0, +0.0, +0.0, a0 * b0 + a1 * b1 + a2 * b2 + a3 * b3 )
%ifdef X86 ; На 32-битной архитектуре возвращаемые числа с плавающей точкой должны быть в st(0)
sub esp, 8
vmovsd [esp], xmm0
vzeroall ; Содержимое SSE-регистров не важно: зануляем полностью
fld qword [esp]
add esp, 8
%else
vzeroupper ; В xmm0 содержится возвращаемое значение, поэтому зануляем только верхние 128 бит
%endif
ret
Тестирование AVX кода
Чтобы убедиться в работоспособности AVX кода лучше написать к нему Unit-тесты. Однако встаёт вопрос: как запустить эти Unit-тесты, если ни один ныне продаваемый процессор не поддерживает AVX? В этом вам поможет специальная утилита от Intel — Software Development Emulator (SDE). Всё, что умеет SDE — это запускать программы, на лету эмулируя новые наборы инструкций. Разумеется, производительность при этом будет далека от таковой на реальном железе, но проверить корректность работы программы таким образом можно. Использовать SDE проще простого: если у вас есть unit-тест для AVX кода в файле avx-unit-test.exe и его нужно запускать с параметром «Hello, AVX!», то вам просто нужно запустить SDE с параметрами
sde -- avx-unit-test.exe "Hello, AVX!"При запуске программы SDE сэмулирует не только AVX инструкции, но также и инструкции XGETBV и CPUID, так что если вы используете предложенный ранее метод для детектирования поддержки AVX, запущенная под SDE программа решит, что AVX действительно поддерживается. Кроме AVX, SDE (вернее, JIT-компилятор pin, на котором SDE построен) умеет эмулировать SSE3, SSSE3, SSE4.1, SSE4.2, SSE4a, AES-NI, XSAVE, POPCNT и PCLMULQDQ инструкции, так что даже очень старый процессор не помешает вам разрабатывать софт под новые наборы инструкций.
Оценка производительности AVX кода
Некоторое представление о производительности AVX кода можно получить с помощью другой утилиты от Intel — Intel Architecture Code Analyzer (IACA). IACA позволяет оценить время выполнения линейного участка кода (если встречаются команды условных переходов, IACA считает, что переход не происходит). Чтобы использовать IACA, нужно сначала пометить специальными маркерами участки кода, которые вы хотите проанализировать. Маркеры выглядят следующим образом:
; Начало участка кода, который надо проанализировать
%macro IACA_START 0
mov ebx, 111
db 0x64, 0x67, 0x90
%endmacro
; Конец участка кода, который надо проанализировать
%macro IACA_END 0
mov ebx, 222
db 0x64, 0x67, 0x90
%endmacroТеперь следует окружить этими макросами тот участок кода, который вы хотите проанализировать
IACA_START
vmovups ymm0, [ecx]
vbroadcastss ymm1, [edx]
vmulps ymm0, ymm0, ymm1
vmovups [ecx], ymm0
vzeroupper
IACA_ENDСкомпилированный с этими макросами объектный файл нужно скормить IACA:
iaca -32 -arch AVX -cp DATA_DEPENDENCY -mark 0 -o avx-sample.txt avx-sample.objПараметры для IACA нужно понимать так
- -32 — означает, что входной объектный файл (MS COFF) содержит 32-битный код. Для 64-битного кода нужно указывать -64. Если на вход IACA подаётся не объектный файл (.obj), а исполняемый модуль (.exe или .dll), то этот аргумент можно не указывать.
- -arch AVX — показывает IACA, что нужно анализировать производительность этого кода на будущем процессоре Intel с поддержкой AVX (т.е. Sandy Bridge). Другие возможные значения: -arch nehalem и -arch westmere.
- -cp DATA_DEPENDENCY просит IACA показать, какие инструкции находятся на критическом путе для данных (т.е. какие инструкции нужно соптимизировать, чтобы результат работы этого кода вычислялся быстрее). Другое возможное значение: -cp PERFORMANCE просит IACA показать, какие инструкции «затыкают» конвеер процессора.
- -mark 0 говорит IACA проанализировать все помеченные маркерами участки кода. Если задать -mark n, IACA будет анализировать только n-ый размеченный участок кода.
- -o avx-sample задаёт имя файла, в который будут записаны результаты анализа. Можно опустить этот параметр, тогда результаты анализа будут выведены в консоль.
Результат запуска IACA приведён ниже:
Intel(R) Architecture Code Analyzer Version - 1.1.3
Analyzed File - avx-sample.obj
Binary Format - 32Bit
Architecture - Intel(R) AVX
*******************************************************************
Intel(R) Architecture Code Analyzer Mark Number 1
*******************************************************************
Analysis Report
---------------
Total Throughput: 2 Cycles; Throughput Bottleneck: FrontEnd, Port2_ALU, Port2_DATA, Port4
Total number of Uops bound to ports: 6
Data Dependency Latency: 14 Cycles; Performance Latency: 15 Cycles
Port Binding in cycles:
-------------------------------------------------------
| Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 |
-------------------------------------------------------
| Cycles | 1 | 0 | 0 | 2 | 2 | 1 | 1 | 2 | 1 |
-------------------------------------------------------
N - port number, DV - Divider pipe (on port 0), D - Data fetch pipe (on ports 2 and 3)
CP - on a critical Data Dependency Path
N - number of cycles port was bound
X - other ports that can be used by this instructions
F - Macro Fusion with the previous instruction occurred
^ - Micro Fusion happened
* - instruction micro-ops not bound to a port
@ - Intel(R) AVX to Intel(R) SSE code switch, dozens of cycles penalty is expected
! - instruction not supported, was not accounted in Analysis
| Num of | Ports pressure in cycles | |
| Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | |
------------------------------------------------------------
| 1 | | | | 1 | 2 | X | X | | | CP | vmovups ymm0, ymmword ptr [ecx]
| 2^ | | | | X | X | 1 | 1 | | 1 | | vbroadcastss ymm1, dword ptr [edx]
| 1 | 1 | | | | | | | | | CP | vmulps ymm0, ymm0, ymm1
| 2^ | | | | 1 | | X | | 2 | | CP | vmovups ymmword ptr [ecx], ymm0
| 0* | | | | | | | | | | | vzeroupper
Самыми важными метриками здесь являются Total Throughput и Data Dependency Latency. Если код, который вы оптимизируете, это небольшая подпрограмма, и в программе есть зависимость по данным от её результата, то вам нужно стараться сделать Data Dependency Latency как можно меньше. В качестве примера может служить приведённый выше листинг подпрограммы vec4_dot_avx. Если же оптимизируемый код — это часть цикла, обрабатывающего большой массив элементов, то ваша задача — уменьшать Total Throughput (вообще-то эта метрика должна была бы называться Reciprocal Throughput, ну да ладно).
Использование AVX в коде на C/C++
Поддержка AVX реализована в следующих популярных компиляторах:
- Microsoft C/C++ Compiler начиная с версии 16 (входит в Visual Studio 2010)
- Intel C++ Compiler начиная с версии 11.1
- GCC начиная с версии 4.4
Для использования 256-битных инструкций AVX в дистрибутив этих компиляторов включен новый заголовочный файл immintrin.h с описанием соответствующих intrinsic-функций. Включение этого заголовочного файла автоматически влечёт за собой включение заголовочных файлов всех SSE-intrinsic'ов. Что касается 128-битных инструкций AVX, то для них нет ни только отдельных хидеров, но и отдельных intrinsics-функций. Вместо этого для них используются intrinsic-функции для SSEx-инструкций, а тип инструкций (SSE или AVX), в которые будут компилироваться вызовы этих intrinsic-функций задаётся в параметрах компилятора. Это означает, что смешать SSE и AVX формы 128-битных инструкций в одном компилируемом файле не получится, и если вы хотите иметь и SSE, и AVX версии функций, то вам придётся писать их в разных компилируемых файлах (и компилировать эти файлы с разными параметрами). Параметры компиляции, которые включают компиляцию SSEx intrinsic-функций в AVX инструкции следующие:
- /arch:AVX — для Microsoft C/C++ Compiler и Intel C++ Compiler под Windows
- -mavx — для GCC и Intel C++ Compiler под Linux
- /QxAVX — для Intel C++ Compiler
- /QaxAVX — для Intel C++ Compiler
Следует иметь в виду, что данные команды не только изменяют поведение SSEx intrinsic-функций, но и разрешают компилятору генерировать AVX инструкции при компиляции обычного C/C++ кода (/QaxAVX говорит Интеловскому компилятору сгенерировать две версии кода — с AVX инструкциями и с базовыми x86 инструкциями).
Чтобы со всеми этими intrinsic'ами было проще разобраться, Intel сделал интерактивный справочник — Intel Intrinsic Guide, который включает в себя описание всех intrinsic-функций, которые поддерживаются интеловскими процессорами. Для тех инструкций, которые уже реализованы в железе, указаны также latency и throughput. Скачать этот справочник можно с сайта Intel AVX (есть версии для Windows, Linux и Mac OS X).
Определение поддержки AVX системой
В принципе, для распознавания поддержки AVX системой можно использовать приведённый ранее ассемблерный код, переписав его на inline-ассемблере, либо просто прилинковав собранный ассемблером объектный файл. Однако, если использование inline-ассемблера невозможно (например, из-за coding guidelines, либо потому, что компилятор его не поддерживает, как в случае Microsoft C/C++ Compiler'а для Windows x64), то you are in deep shit. Проблема в том, что intrinsic-функции для инструкции xgetbv не существует! Таким образом, задача разбивается на две части: проверить, что процессор поддерживает AVX (это можно сделать кроссплатформенно) и проверить, что ОС поддерживает AVX (тут уж придётся писать свой код для каждой ОС).
Проверить, что процессор поддерживает AVX можно используя всё ту же инструкцию CPUID, для которой есть intrinsic-функция void __cpuid( int cpuInfo[4], int infoType ). Параметр infoType задаёт значение регистра eax перед вызовом CPUID, а cpuInfo после выполнения функции будет содежать регистры eax, ebx, ecx, edx (именно в таком порядке). Т.о. получаем следующий код:
int isAvxSupportedByCpu() {
int cpuInfo[4];
__cpuid( cpuInfo, 0 );
if( cpuInfo[0] != 0 ) {
__cpuid( cpuInfo, 1 );
return cpuInfo[3] & 0x10000000; // Возвращаем ноль, если 28-ой бит в ecx сброшен
} else {
return 0; // Процессор не поддерживает получение информации о поддерживаемых наборах инструкций
}
}С поддержкой со стороны ОС сложнее. AVX на сегодня поддерживается следующими ОС:
- Windows 7
- Windows Server 2008 R2
- Linux с ядром 2.6.30 и выше
В Windows была добавлена возможность узнать о поддержке операционкой новых наборов инструкций в виде функции GetEnabledExtendedFeatures из kernel32.dll. К сожалению, эта функция документирована чуть менее, чем никак. Но кое-какую информацию о ней раздобыть всё же можно. Эта функция описана в файле WinBase.h из Platform SDK:
WINBASEAPI
DWORD64
WINAPI
GetEnabledExtendedFeatures(
__in DWORD64 FeatureMask
);Значения для параметра FeatureMask можно найти в хидере WinNT.h:
//
// Known extended CPU state feature IDs
//
#define XSTATE_LEGACY_FLOATING_POINT 0
#define XSTATE_LEGACY_SSE 1
#define XSTATE_GSSE 2
#define XSTATE_MASK_LEGACY_FLOATING_POINT (1i64 << (XSTATE_LEGACY_FLOATING_POINT))
#define XSTATE_MASK_LEGACY_SSE (1i64 << (XSTATE_LEGACY_SSE))
#define XSTATE_MASK_LEGACY (XSTATE_MASK_LEGACY_FLOATING_POINT | XSTATE_MASK_LEGACY_SSE)
#define XSTATE_MASK_GSSE (1i64 << (XSTATE_GSSE))
#define MAXIMUM_XSTATE_FEATURES 64Нетрудно заметить, что маски XSTATE_MASK_* соответствуют аналогичным битам регистра XFEATURE_ENABLED_MASK.
В дополнение к этому, в Windows DDK есть описание функции RtlGetEnabledExtendedFeatures и констант XSTATE_MASK_XXX, как две капли воды похожих на GetEnabledExtendedFeatures и XSTATE_MASK_* из WinNT.h. Т.о. для определения поддержки AVX со стороны Windows можно воспользоваться следующим кодом:
int isAvxSupportedByWindows() {
const DWORD64 avxFeatureMask = XSTATE_MASK_LEGACY_SSE | XSTATE_MASK_GSSE;
return GetEnabledExtendedFeatures( avxFeatureMask ) == avxFeatureMask;
}Если ваша программа должна работать не только в Windows 7 и Windows 2008 R2, то функцию GetEnabledExtendedFeatures нужно подгружать динамически из kernel32.dll, т.к. в других версиях Windows этой функции нет.
В Linux, насколько мне известно, нет отдельной функции, чтобы узнать о поддержке AVX со стороны ОС. Но вы можете воспользоваться тем фактом, что поддержка AVX было добавлена в ядро 2.6.30. Тогда остаётся только проверить, что версия ядра не меньше этого значения. Узнать версию ядра можно с помощью функции uname.
Использование AVX-инструкций
Написание AVX-кода с использованием intrinsic-функций не вызовет у вас затруднений, если вы когда-либо использовали MMX или SSE посредством intrinsic'ов. Единственное, о чём нужно позаботиться дополнительно, это вызвать функцию _mm256_zeroupper() в конце подпрограммы (как нетрудно догадаться, эта intrinsic-функция генерирует инструкцию vzeroupper). Например, приведённая выше ассемблерная подпрограмма vec4_dot_avx может быть переписана на intrinsic'ах так:
double vec4_dot_avx( double a[4], double b[4] ) {
// mmA = a
const __m256d mmA = _mm256_loadu_pd( a );
// mmB = b
const __m256d mmB = _mm256_loadu_pd( b );
// mmAB = ( a3 * b3, a2 * b2, a1 * b1, a0 * b0 )
const __m256d mmAB = _mm256_mul_pd( mmA, mmB );
// mmABHigh = ( +0.0, +0.0, a3 * b3, a2 * b2 )
const __m256d mmABHigh = _mm256_permute2f128_pd( mmAB, mmAB, 0x81 );
// mmSubSum = ( +0.0, +0.0, a1 * b1 + a3 * b3, a0 * b0 + a2 * b2 )
const __m128d mmSubSum = _mm_add_pd(
_mm256_castpd256_pd128( mmAB ),
_mm256_castpd256_pd128( mmABHigh )
);
// mmSum = ( +0.0, +0.0, +0.0, a0 * b0 + a1 * b1 + a2 * b2 + a3 * b3 )
const __m128d mmSum = _mm_hadd_pd( mmSubSum, _mm_setzero_pd() );
const double result = _mm_cvtsd_f64( mmSum );
_mm256_zeroupper();
return result;
}Тестирование AVX кода
Если вы используете набор инструкций AVX посредством intrinsic-функций, то, кроме запуска этого кода под эмулятором SDE, у вас есть ещё одна возможность — использовать специальный заголовочный файл, эмулирующий 256-битные AVX intrinsic-функции через intrinsic-функции SSE1-SSE4.2. В этом случае у вас получится исполняемый файл, который можно запустить на процессорах Nehalem и Westmere, что, конечно, быстрее эмулятора. Однако учтите, что таким методом не получиться обнаружить ошибки генерации AVX-кода компилятором (а они вполне могут быть).
Оценка производительности AVX кода
Использование IACA для анализа производительности AVX кода, созданного C/C++ компилятором из intrinsic-функций почти ничем не отличается от анализа ассемблерного кода. В дистрибутиве IACA можно найти заголовочный файл iacaMarks.h, в котором описаны макросы-маркеры IACA_START и IACA_END. Ими нужно пометить анализируемые участки кода. В коде подпрограммы маркер IACA_END должен находиться до оператора return, иначе компилятор «соптимизирует», выкинув код маркера. Макросы IACA_START/IACA_END используют inline-ассемблер, который не поддерживается Microsoft C/C++ Compiler для Windows x64, поэтому если для него нужно использовать специальные варианты макросов — IACA_VC64_START и IACA_VC64_END.
Заключение
В этой статье было продемонстрировано, как разрабатывать программы с использованием набора инструкций AVX. Надеюсь, что это знание поможет вам радовать своих пользователей программами, которые используют возможности компьютера на все сто процентов!
Упражнение
Приведённый код подпрограммы vec4_dot_avx не является оптимальным с точки зрения производительности. Попробуйте переписать её более оптимально. Какая у вас получалась Data Dependency Latency?
