Как мы используем цепи Маркова в оценке решений и поиске багов. Со скриптом на Python
Нам важно понимать, что происходит с нашими студентами во время обучения, и как эти события влияют на результат, поэтому мы выстраиваем Customer Journey Map — карту клиентского опыта. Ведь процесс обучения — не нечто непрерывное и цельное, это цепочка взаимосвязанных событий и действий студента, причем эти действия могут сильно отличаться у разных учеников. Вот он прошел урок: что он сделает дальше? Пойдет в домашнее задание? Запустит мобильное приложение? Изменит курс, попросит сменить учителя? Сразу зайдет в следующий урок? Или просто уйдет разочарованным? Можно ли, проанализировав эту карту, выявить закономерности, приводящие к успешному окончанию курса или наоборот, «отваливанию» студента?
Обычно для выстраивания CJM используют специализированные, весьма дорогие инструменты с закрытым кодом. Но нам хотелось придумать что-то простое, требующее минимальных усилий и по возможности опенсорсное. Так появилась идея воспользоваться цепями Маркова — и у нас получилось. Мы построили карту, интерпретировали данные о поведении студентов в виде графа, увидели совершенно неочевидные ответы на глобальные вопросы бизнеса и даже нашли глубоко спрятанные баги. Все это мы сделали с помощью опенсорсных решений Python-скрипта. В этой статье я расскажу про два кейса с теми самыми неочевидными результатами и поделюсь скриптом со всеми желающими.
Итак, цепи Маркова показывают вероятность переходов между событиями. Вот примитивный пример из Википедии:
Здесь «E» и «A» — события, стрелочки — переходы между ними (в том числе и переход из события в него же), а веса стрелочек — вероятность перехода («взвешенный ориентированный граф»).
Что использовали
Цепь обучалась стандартным функционалом Python, которому скармливались логи активности студентов. Граф на полученной матрице строился библиотекой NetworkX.
Лог выглядит так:
Это csv-файл, содержащий таблицу из трех столбцов: id студента, наименование события, время, когда оно произошло. Этих трех полей достаточно, чтобы проследить движения клиента, построить карту и в итоге получить цепь Маркова.
Библиотека возвращает построенные графы в формате .dot или .gexf. Для визуализации первых можно воспользоваться бесплатным пакетом Graphviz (инструмент gvedit), мы работали с .gexf и Gephi, тоже бесплатной.
Дальше хочу привести два примера использования цепей Маркова, которые позволили нам по-новому взглянуть на наши цели, учебные процессы и саму экосистему Skyeng. Ну и подправить баги.
Первый кейс: мобильное приложение
Для начала мы исследовали путь студента по нашему самому популярному продукту — курсу General. В тот момент я работал в детском департаменте Skyeng и мы хотели посмотреть, насколько эффективно работает мобильное приложение с нашей детской аудиторией.
Взяв логи и прогнав их через скрипт, я получил что-то такое:
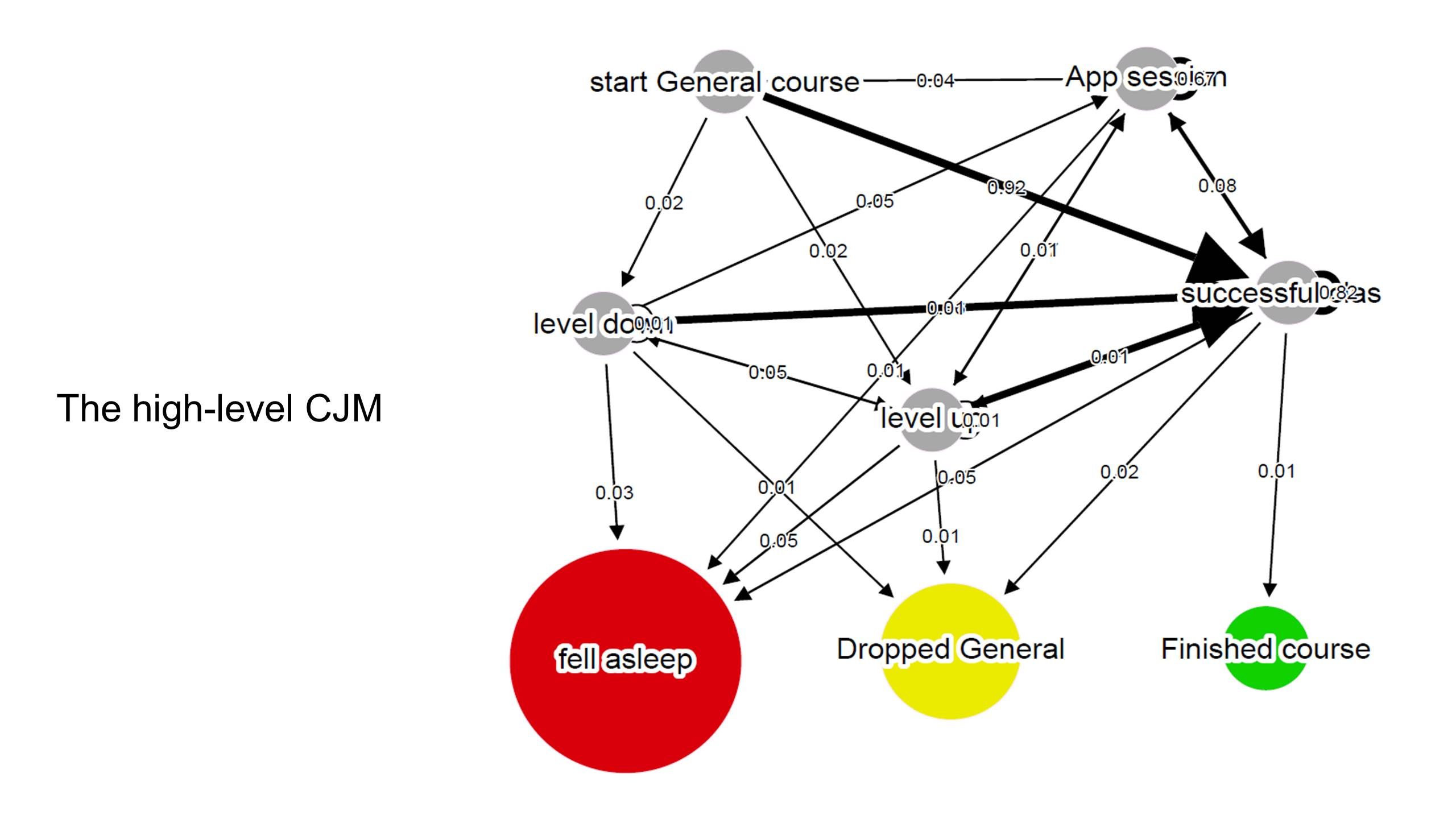{kind=link}
Стартовый узел — Start General, а внизу три выходные ноды: ученик «заснул», сменил курс, закончил курс.
- Fell asleep, «Заснул» — значит, больше не проходит занятия, скорее всего, он отвалился. Мы оптимистично называем это состояние «заснул», т.к. в теории у него сохраняется возможность продолжить обучение. Худший результат для нас.
- Dropped general, Сменил курс — перешел с General на что-то другое и потерялся для нашей цепи Маркова.
- Finished course, Закончил курс — идеальное состояние, человек прошел 80% уроков (не все уроки обязательны).
Попадание в ноду successfull class означает успешное прохождение урока на нашей платформе вместе с учителем. Она фиксирует продвижение по курсу и приближение к желаемому результату — «Закончил курс». Нам важно, чтобы студенты посещали ее как можно больше.
Чтобы получить более точные количественные выводы для мобильного приложения (нода app session), мы построили отдельные цепи для каждого из финальных узлов и далее сравнивали попарно веса ребер:
- из app session обратно в нее же;
- из app session в successful class;
- из successful class в app session.
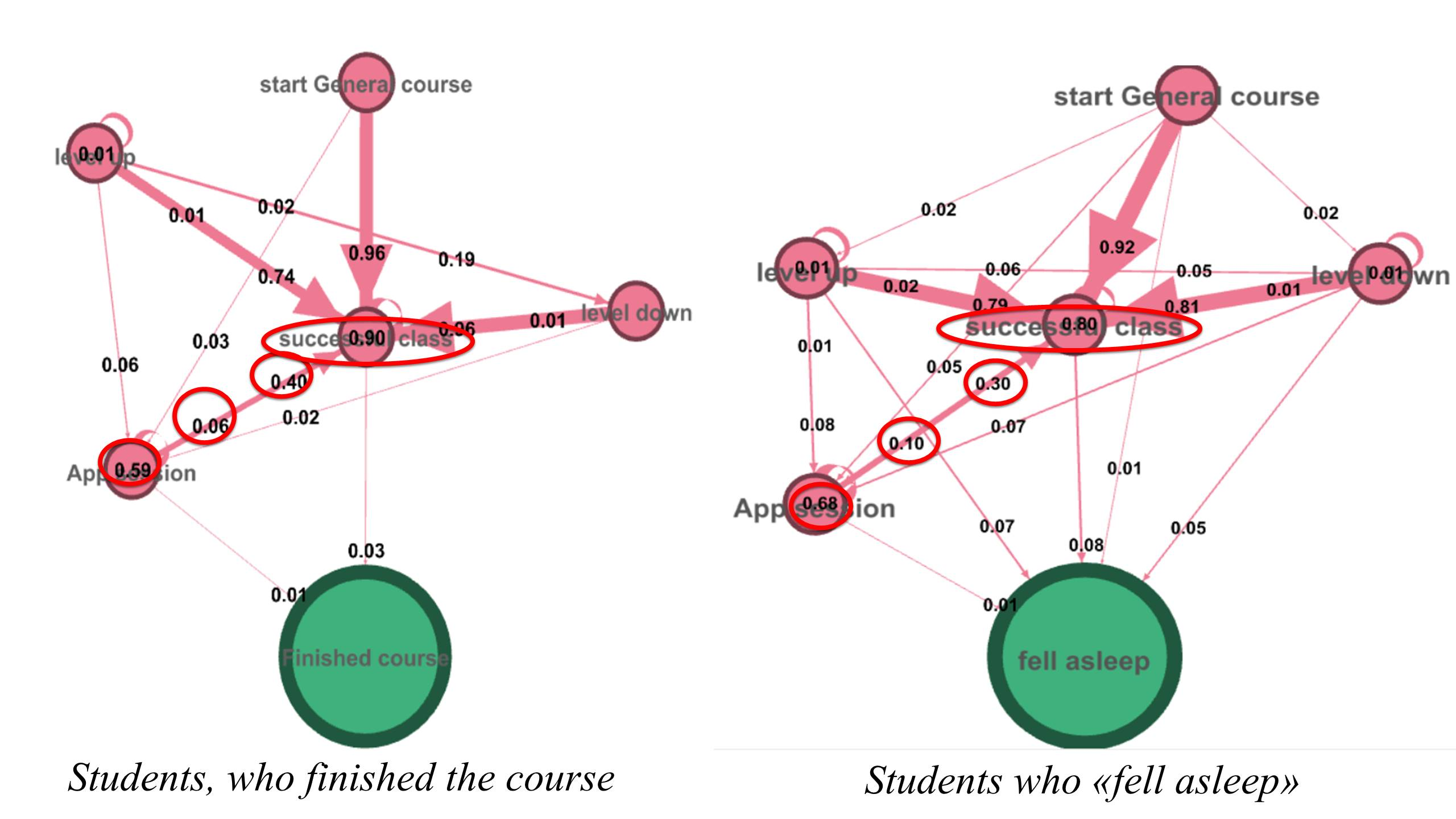{kind=link}
Слева — студенты, завершившие курс, справа — «заснувшие»
Эти три ребра показывают связь между успешностью студента и использованием им мобильного приложения. Мы ожидали увидеть, что у закончивших курс студентов связь с приложением будет сильнее, чем у «заснувших». Однако на деле получили ровно противоположные результаты:
- мы убедились, что разные группы пользователей по-разному взаимодействуют с мобильным приложением;
- успешные студенты менее интенсивно используют мобильное приложение;
- засыпающие студенты активнее используют мобильное приложение.
Это значит, что «засыпающие» студенты начинают все больше времени проводить в мобильном приложени и в конце концов остаются в нем навсегда.
Сперва мы удивились, но, подумав, поняли, что это вполне закономерный эффект. В свое время я самостоятельно изучал французский, используя два инструмента: мобильное приложение и лекции по грамматике в YouTube. Поначалу я делил время между ними в пропорции 50 на 50. Но приложение веселее, там геймификация, там все просто, быстро и понятно, а в лекции надо вникать, что-то записывать, практиковаться в тетрадке. Постепенно я стал больше времени проводить в смартфоне, пока его доля не доросла до 100%: если провисеть в нем три часа, создается ложное ощущение выполненной работы, из-за которого идти и что-то слушать нет никакого желания.
Но как же так? Ведь мы специально создавали мобильное приложение, встраивали в него кривую Эббингауза, геймифицировали, делали его привлекательным, чтобы люди проводили в нем время, а оказывается, оно их только отвлекает? На самом деле причина в том, что команда мобильного приложения слишком хорошо справилась со своими задачами, в результате чего оно стало классным самодостаточным продуктом и начало вываливаться из нашей экосистемы.
В итоге исследования пришло понимание, что мобильное приложение надо как-то менять, чтобы оно меньше оттягивало от основного курса обучения. Причем и детское, и взрослое. Сейчас эта работа ведется.
Второй кейс: баги онбординга
Онбординг — необязательная дополнительная процедура при регистрации нового ученика, избавляющая от потенциальных технических проблем в будущем. Базовый сценарий подразумевает, что человек зарегистрировался на лендинге, получил доступ в личный кабинет, с ним связываются и проводят вводный урок. При этом мы отмечаем большой процент технических трудностей во время вводного урока: не та версия браузера, не работает микрофон или звук, учитель не может сразу подсказать решение, и все это особенно сложно, если речь идет о детях. Поэтому мы разработали дополнительное приложение в личном кабинете, где можно выполнить четыре простых шага: проверить браузер, камеру, микрофон и подтвердить, что родители будут рядом во время вводного урока (ведь именно они платят за обучение детей).
Эти несколько страниц онбординга демонстрировали такую воронку:
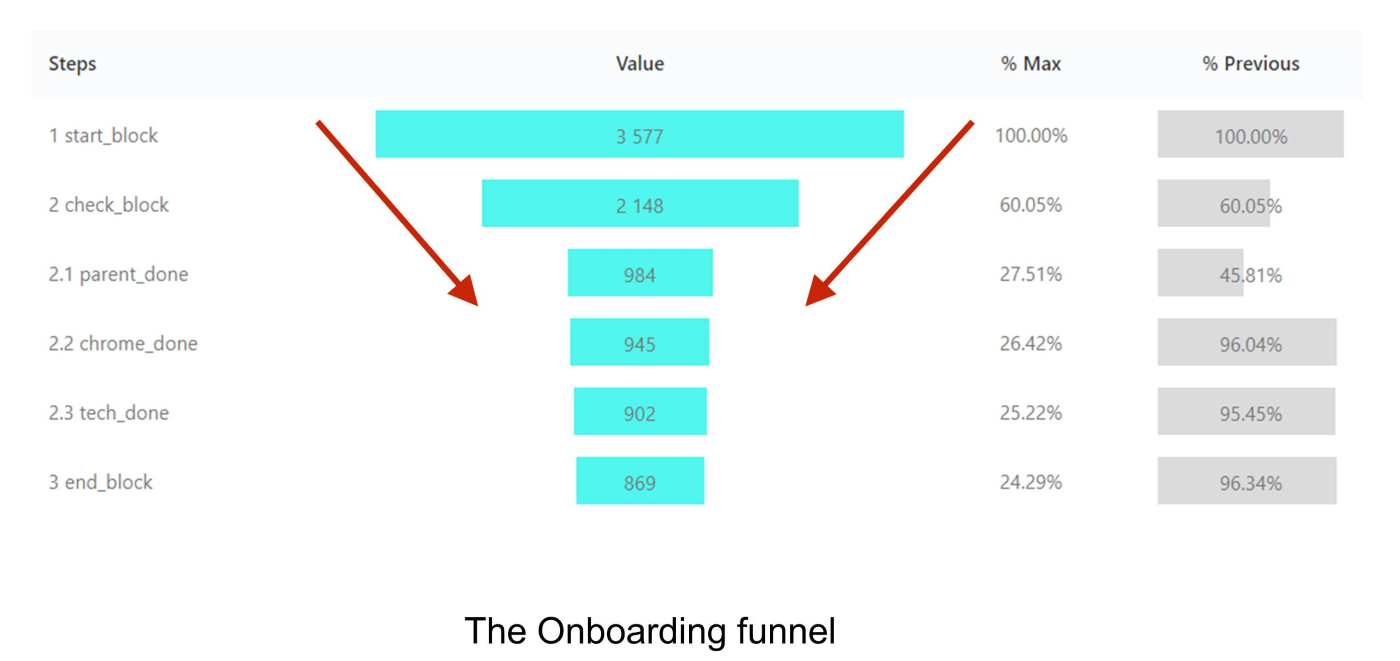{kind=link}
1: стартовый блок с тремя немного различающимися (в зависимости от клиента) формами ввода логина-пароля.
2: галка согласия на дополнительную процедуру онбординга.
2.1-2.3: проверка присутствия родителя, версии Chrome и звука.
3: финальный блок.
Выглядит она очень естественно: на первых двух шагах большая часть посетителей сливается, поняв, что тут надо что-то заполнять, проверять, а времени нет. Если клиент дошел до третьего шага — дальше он уже почти наверняка дойдет до финала. На воронке не видно ни одной причины, чтобы что-то заподозрить.
Все же мы решили проанализировать наш онбординг не на классической одномерной воронке, а с помощью цепи Маркова. Включили чуть больше событий, запустили скрипт и получили вот такое:
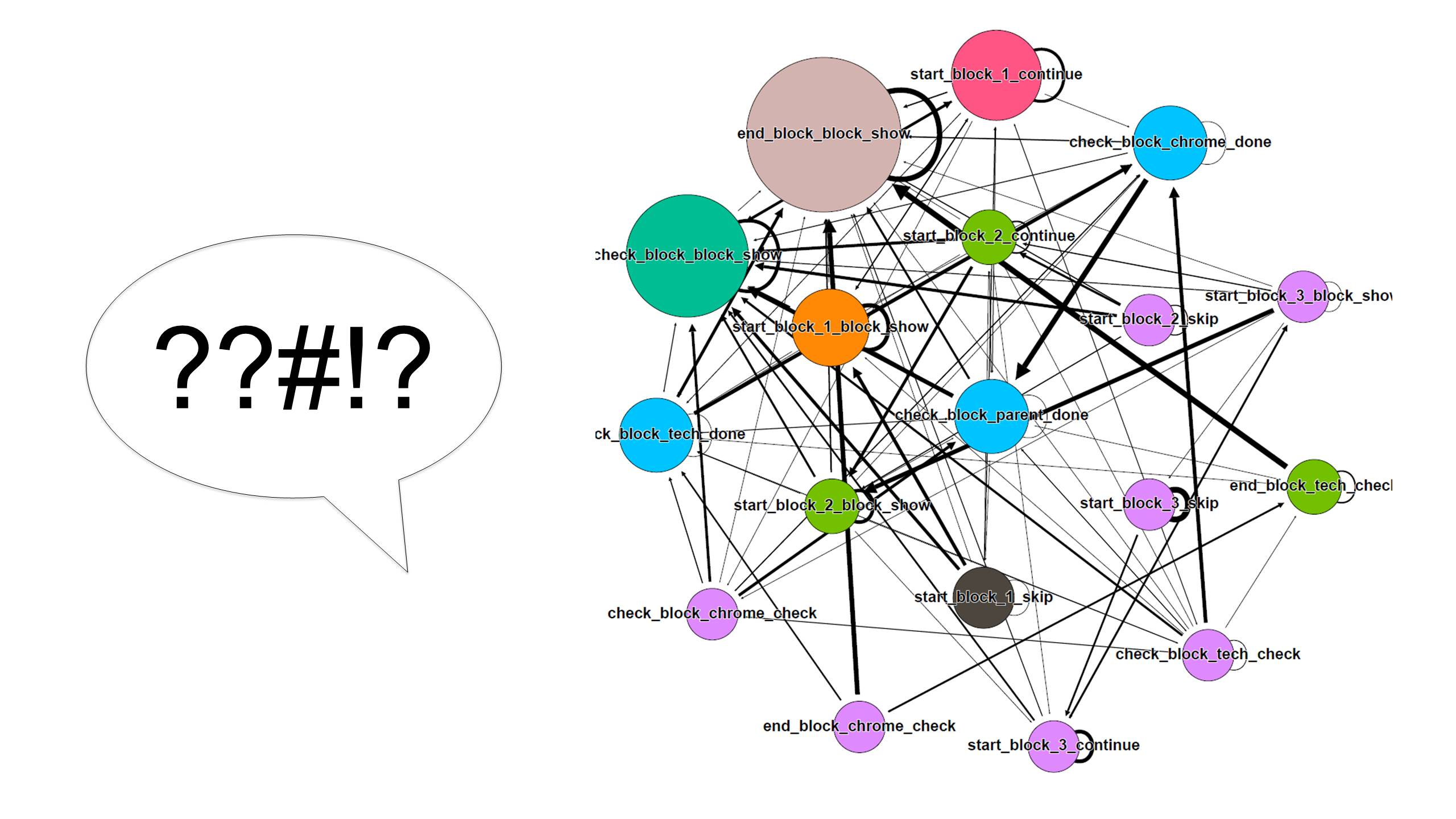{kind=link}
Однозначно понять в этом хаосе можно только одно: что-то пошло не так. Процесс онбординга — линейный, это заложено дизайном, в нем никак не должно быть такой паутины связей. А тут сразу видно, что пользователя кидает между шагами, между которыми вообще не должно быть переходов.
Причины такой странной картины может быть две:
- косяки закрались в базу логов;
- косяки присутствуют в самом продукте — онбординге.
Первая причина, скорее всего, имеет место, но проверить ее достаточно трудоемко, и исправление логов никак не поможет улучшить UX. А вот со второй, если она есть, надо было срочно что-то делать. Поэтому мы отправились рассматривать узлы, выявлять ребра, которых быть не должно, искать причины их возникновения. Увидели, что некоторые пользователи зацикливались и ходили по кругу, другие — вываливались из середины в начало, третьи в принципе не могли выбраться из первых двух шагов. Передали данные в QA — и да, выяснилось, что в онбординге хватало багов: это такой побочный, немного костыльный продукт, его не тестировали достаточно глубоко, т.к. не ожидали никаких проблем. Сейчас уже весь процесс записи поменялся.
Эта история показала нам неожиданное применение цепей Маркова в области QA.
Попробуйте сами!
Я выложил свой Python-скрипт для обучения цепей Маркова в открытый доступ — пользуйтесь на здоровье. Документация на GitHub, вопросы можно задавать здесь, постараюсь на все ответить.
Ну и полезные ссылки: библиотека NetworkX, визуализатор Graphviz. А вот тут на Хабре есть статья про цепи Маркова. Графы в статье сделаны с помощью Gephi.