
Реализации Flux, такие как Redux, мотивируют нас уделять больше внимания проектированию состояния приложения. Оказывается, это нетривиальная задача. Это похоже на классический пример из теории хаоса, когда, казалось бы, безобидный взмах крыльев бабочки ведёт к далеко идущим последствиям. Ниже приведены советы, которые помогут вам лучше организовать состояние приложения.
Что такое состояние приложения
Согласно Википедии, программа сохраняет данные в переменных, представленных в памяти компьютера. Значения этих переменных в определённый момент времени и являются состоянием приложения.
Важно добавить к определению слово «минимальное». Проектируя состояние приложения, нужно стараться работать с минимальным набором данных, и игнорировать те переменные, которые могут быть рассчитаны его основе.
В приложениях с однонаправленным потоком данных (Flux) состояние находится в хранилищах (stores). Выполнение действий (actions) приводит к изменению состояния, в результате чего представления (views), которые подписаны на его изменения, обновляются в соответствии с новыми данными.
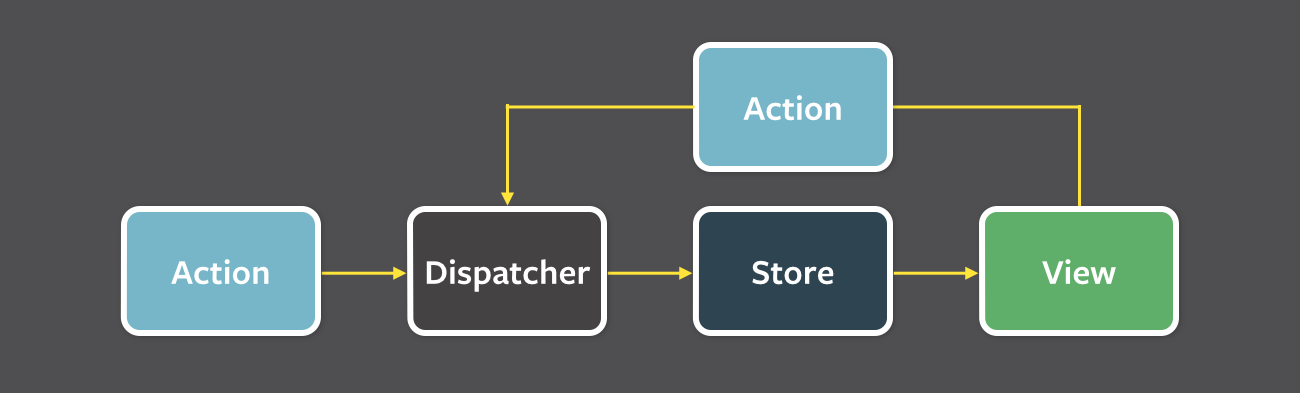
Redux, о котором пойдет речь дальше, добавляет несколько строгих ограничений. Прежде всего, состояние хранится в едином иммутабельном и сериализумемом хранилище.
Ниже представлены советы, которые будут полезны, даже если вы не используете Redux. Они могут пригодиться и тем, кто вообще не использует Flux.
1. Состояние не обязано повторять структуру ответа сервера
Локальное состояние приложения часто основывается на данных, полученных от сервера. Если приложение используется для отображения серверных данных, есть искушение использовать эту же структуру на клиенте.
В качестве примера возьмем приложение для управления интернет-магазином. Менеджер будет использовать его для управления товарами. Список товаров приходит с сервера и должен быть сохранен в локальном состоянии приложения, чтобы быть отрисованным в представлениях. Допустим, с сервера приходит такой JSON:
{ "total": 117, "offset": 0, "products": [ { "id": "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0", "title": "Blue Shirt", "price": 9.99 }, { "id": "aec17a8e-4793-4687-9be4-02a6cf305590", "title": "Red Hat", "price": 7.99 } ] }
Список товаров приходит как массив объектов, так почему бы не сохранить его в таком виде в локальном состоянии?
В данном случае, выбор сервером массива для передачи списка товаров может быть связан с разбиением на страницы, с дроблением списка на части для порционной загрузки, с избеганием повторной отправки данных для экономии траффика. Всё это – обоснованные соображения, но, в целом, они не связаны с теми соображениями, которыми руководствуемся мы при моделировании локального состояния приложения.
2. Объект предпочтительнее массива
В целом, массивы – не лучшая структура данных для использования в состоянии приложения. Представьте, что нужно получить или обновить конкретный товар из списка. Если мы хотим изменить цену, или нужно применить обновление от сервера, итерирование по массиву для поиска конкретного товара будет не таким удобным, как его получение по ID в объекте товаров.
Мы можем обновить данные из примера таким образом:
{ "productsById": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "title": "Blue Shirt", "price": 9.99 }, "aec17a8e-4793-4687-9be4-02a6cf305590": { "title": "Red Hat", "price": 7.99 } } }
Но что если важен порядок элементов в списке? Например, если мы должны выводить товары именно в том порядке, который указан в массиве из ответа сервера? В таком случае, мы можем сохранить дополнительный массив идентификаторов:
{ "productsById": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "title": "Blue Shirt", "price": 9.99 }, "aec17a8e-4793-4687-9be4-02a6cf305590": { "title": "Red Hat", "price": 7.99 } }, "productIds": [ "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0", "aec17a8e-4793-4687-9be4-02a6cf305590" ] }
Примечание: эта структура отлично работает с компонентом React Native ListView. Рекомендуемая версия cloneWithRows ожидает именно такой формат.
3. Состояние не обязано иметь тот формат, в котором представления принимают данные
В конце концов, представления рисуются на основе состояния. Возможность избежать дополнительных преобразований, сохраняя данные состояния в нужном для представлений виде, кажется привлекательной.
Вернемся к нашему примеру с системой управления интернет-магазином. Предположим, что каждый товар может либо быть в наличии, либо отсутствовать. Для этого мы можем добавить поле outOfStock в объект товара:
{ "id": "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0", "title": "Blue Shirt", "price": 9.99, "outOfStock": false }
Наше приложение должно отобразить список всех отсутствующих товаров. Как вы помните, компонент React Native ListView ожидает два аргумента для метода cloneWithRows: объект со строками и массив из ID этих строк. Хочется подготовить такую структуру заранее и хранить её в состоянии приложения, чтобы не преобразовывать данные при передаче в компонент. Структура состояния будет выглядеть так:
{ "productsById": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "title": "Blue Shirt", "price": 9.99, "outOfStock": false }, "aec17a8e-4793-4687-9be4-02a6cf305590": { "title": "Red Hat", "price": 7.99, "outOfStock": true } }, "outOfStockProductIds": ["aec17a8e-4793-4687-9be4-02a6cf305590"] }
Хорошая идея, не так ли? На самом деле, нет.
Причина, как и ранее, в том, что представления руководствуются другими соображениями. Их основная задача – отобразить данные в максимально удобном для пользователя виде, а это может противоречить нашему стремлению хранить в состоянии приложения лишь необходимый минимум данных. Более того, разные представления могут показывать один набор данных в разном виде, а это может приводить к дублированию данных в состоянии.
Это подводит нас к следующему пункту.
4. Никогда не дублируйте данные в состоянии
Если при обновлении данных требуются одновременные изменения в двух местах для сохранения целостности, значит данные в состоянии дублируются. Предположим, что в примере выше, один товар получает статус «нет в наличии». Чтобы учесть это обновление, нам нужно изменить поле outOfStock в объекте товара и добавить его ID в массив outOfStockProductIds – два обновления.
Проблема решается просто – удаляется лишняя сущность. Обновляя данные только в одном месте, мы исключаем риск нарушить целостность.
Если мы отказываемся от массива outOfStockProductIds, нам нужно найти способ подготовки данных для представлений. Распространенной в Redux практикой является использование селекторов:
{ "productsById": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "title": "Blue Shirt", "price": 9.99, "outOfStock": false }, "aec17a8e-4793-4687-9be4-02a6cf305590": { "title": "Red Hat", "price": 7.99, "outOfStock": true } } } // selector function outOfStockProductIds(state) { return _.keys(_.pickBy(state.productsById, (product) => product.outOfStock)); }
Селектор – это чистая функция, которая получает на вход состояние приложения и возвращает преобразованную часть для дальнейшего использования. Дэн Абрамов рекомендует располагать селектор вместе с reducer'ом, поскольку они, как правило, тесно связаны. Использовать селектор мы будем внутри представления в mapStateToProps.
Жизнеспособной альтернативой удалению массива является удаление свойства outOfStock в каждом объекте товара. В этом случае, единым источником информации о наличии товара является массив с ID. Правда, в соответствии с пунктом 2, возможно, будет лучше превратить этот массив в объект:
{ "productsById": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "title": "Blue Shirt", "price": 9.99 }, "aec17a8e-4793-4687-9be4-02a6cf305590": { "title": "Red Hat", "price": 7.99 } }, "outOfStockProductMap": { "aec17a8e-4793-4687-9be4-02a6cf305590": true } } // selector function outOfStockProductIds(state) { return _.keys(state.outOfStockProductMap); }
5. Никогда не сохраняйте вторичные данные в состоянии
Хранение в состоянии данных, которые получены в результате вычислений на основе других данных из состояния, нарушает принцип SSOT (Single source of truth), поскольку обновление данных требует изменений в нескольких местах для сохранения целостности.
Добавим в наше приложение возможность указать скидку на товар. Нужно вывести пользователю отфильтрованный список товаров, в котором представлены либо все товары, либо товары со скидкой, либо без.
Распространенной ошибкой является хранение данных в виде трёх массивов, каждый из которых будет содержать набор ID для конкретного фильтра. Поскольку эти наборы могут быть рассчитаны на основе списка товаров и информации о текущем фильтре, правильнее будет сгенерировать их с помощью селектора как и ранее:
{ "productsById": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "title": "Blue Shirt", "price": 9.99, "discount": 1.99 }, "aec17a8e-4793-4687-9be4-02a6cf305590": { "title": "Red Hat", "price": 7.99, "discount": 0 } } } // selector function filteredProductIds(state, filter) { return _.keys(_.pickBy(state.productsById, (product) => { if (filter == "ALL_PRODUCTS") return true; if (filter == "NO_DISCOUNTS" && product.discount == 0) return true; if (filter == "ONLY_DISCOUNTS" && product.discount > 0) return true; return false; })); }
Селекторы исполняются при каждом обновлении состояния приложения перед перерисовкой представления. Если у вас сложные селекторы и вы заботитесь о производительности, используйте мемоизацию для кэширования результатов расчетов. В библиотеке Reselect это уже реализовано.
6. Нормализуйте связанные объекты
Наша задача – сделать так, чтобы развивать и поддерживать приложения было комфортно. При этом работать с его состоянием должно быть удобно. Простоту состояния удобнее поддерживать, когда объекты с данными независимы, но что происходит, если объекты связаны друг с другом?
Представьте, что в нашем примере нужно добавить систему управления заказами, с помощью которой покупатель может выбрать несколько товаров и оформить заказ. Допустим, мы получаем от сервера такой JSON со списком заказов:
{ "total": 1, "offset": 0, "orders": [ { "id": "14e743f8-8fa5-4520-be62-4339551383b5", "customer": "John Smith", "products": [ { "id": "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0", "title": "Blue Shirt", "price": 9.99, "giftWrap": true, "notes": "It's a gift, please remove price tag" } ], "totalPrice": 9.99 } ] }
В заказе содержится несколько товаров. Получается, что у нас есть две сущности, которые нужно связать между собой. Мы уже знаем, что нам не обязательно хранить данные один в один с предоставленной сервером структурой. Она, в данном случае, приведет к дублированию данных о товарах.
Хороший подход в данном случае – нормализовать данные и работать с двумя объектами: один для товаров, а другой для заказов. Поскольку объекты обоих типов имеют ID, мы можем использовать это свойство для их взаимосвязи. Таким образом, состояние приложения принимает следующий вид:
{ "productsById": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "title": "Blue Shirt", "price": 9.99 }, "aec17a8e-4793-4687-9be4-02a6cf305590": { "title": "Red Hat", "price": 7.99 } }, "ordersById": { "14e743f8-8fa5-4520-be62-4339551383b5": { "customer": "John Smith", "products": { "88cd7621-d3e1-42b7-b2b8-8ca82cdac2f0": { "giftWrap": true, "notes": "It's a gift, please remove price tag" } }, "totalPrice": 9.99 } } }
Если мы хотим найти все товары определенного заказа, мы проходим по ключам объекта products в заказе. Каждый ключ — это ID, к которому мы можем обратиться в объекте productsById, чтобы получить более подробную информацию о товаре. Специфичную для заказа информацию о товаре, такую как giftWrap, мы можем найти в объекте заказа products.
Для нормализации данных есть готовая библиотека – normalizr.
7. К состоянию приложения можно относиться как к базе данных, хранящейся в памяти
Большинство советов выше, наверняка, вам уже знакомы. Мы принимаем подобные решения при проектировании традиционных баз данных.
При проектировании структуры традиционной базы данных, мы стараемся избегать дублирования и хранения вторичных данных, индексируем данные в подобных объектам таблицах, используя первичные ключи (ID) и нормализуем отношения между несколькими таблицами. Всё то, что мы обсуждали выше.
Отношение к состоянию приложения как к базе данных, хранящейся в памяти, помогает сформировать правильную установку для принятия более взвешенных решений по поводу структуры данных.
Относитесь к состоянию приложения подобающим образом
Если выделить основную мысль статьи, то это она.
В императивном программировании мы склонны ставить на первое место код и уделять меньше внимания построению «корректных» моделей для внутренних структур данных, таких как состояние. Состояния наших приложений часто могут быть разбросаны среди различных менеджеров/контроллеров как совокупность внутренних переменных.
В декларативной парадигме дела обстоят иначе. В React и в подобных окружениях наша система реагирует на изменения в состоянии, поэтому оно становится таким же значимым, как и код, который управляет поведением приложения. С ним работают и действия (actions) и представления, для которых оно является источником данных. Redux и другие реализации Flux отталкиваются от этой идеи и добавляют новые возможности и ограничения для большей предсказуемости приложения.
Проектирование структуры состояния приложения требует времени. Мы должны быть внимательны к тому, насколько сложным оно становится и сколько усилий уходит на его поддержку и развитие. И, конечно, как и в случае с кодом, состоянию приложения, которое перестает эффективно справляться со своими задачами, время от времени необходим рефакторинг.
От переводчика:
Автор статьи: Tal Kol. Оригинал доступен по ссылке.
Спасибо bniwredyc за замечания и советы по переводу.

