
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
отчего же? Это же волшебно когда UI на клиенте это не статическая страничка а луп отрисовывающий стэйт! А если еще и выстроен как композиция реюзабельных компонентов, ух… А бэкэнд stateless и в целом не зависит от UI особо, крути верти как хочешь. Дикий простор для творчества. Для определенного процента проектов можно вообще без бэкэнда обходиться благодаря всяким там firebase-ам и похожим сервисам. Идеально для CRUD-like приложений, да и с кодогенерацией для UI и реюзом оного как-то получше дела обстоят.
Конечно же это не для всех проектов/команд подходит… И надо фронтэнды уметь, с чем сейчас тугова-то у людей. То есть свои жирные минусы несомненно есть...
{{#if author}}
<h1>{{firstName}} {{lastName}}</h1>
{{/if}}
Разумеется, бизнес-логику нельзя пихать в react-компонент, ни в коем случае.
Нельзя смешивать в одном компоненте бизнес-логику и логику отображения. Разделять вполне можно.
Когда вы в handlebars пишете
Так не пишите, оставьте шаблоны простыми.
Ну вот кстати именно поэтому на первый взгляд менее удобные mustache в итоге оказываются более поддерживаемым решением. Ибо вся логика оттуда искусственно вытеснена в контроллеры.
из-за смешивания логики (кода) и шаблона.
Twig/Nunjucks/Jinja2
<ul>
{% for item in list %}
<li>{{ item}}</li>
{% else %}
<li class="empty">List is empty :(</li>
{% endfor %}
</ul>Angular
<ul>
<li *ngFor="let item of list">{{item}}</li>
<li class="empty" *ngIf="!list.length">List is empty :(</li>
</ul>React JSX
render: function() {
return (
<ul>
{this.props.list.map(item => <li>{item}</li>)}
{this.props.list.length == 0 &&
<li class="empty">List is empty :(</li>
}
</ul>
)
}Knockout.js
<li data-bind="foreach: list">
<span data-bind="text: $data"></span>
</li>
<li class="empty" data-bind="if: pets().length == 0">List is empty :(</li>Я это к чему — логика отображения в шаблонах — от этого вы не уйдете. Разница лишь в способах которыми вы это дело разруливаете. JSX это лишь сахар чтобы удобнее было.
все работает на ES5 без какой-либо прекомпиляции.
Я уже не могу писать просто на es5 без всяких бабелев… к хорошему быстро привыкаешь.
SPA плохи двумя вещами — слабой индексацией в поисковиках и глюками старых браузеров.
На счет браузеров — согласен, хотя с каждым годом ситуация меняется в лучшую сторону. Ну а по поводу индексации — приведу пример. angular-universal. Server-side рендринг в пол пинка (ну как. относительно конечно).
Тем не менее в случае knockout / angular мы имеем самый минимум логики в шаблонах
присмотритесь. Количество логики ровно одинаковое. Разница лишь в синтаксисе. Причем в этом плане у jsx есть преимущество перед knockout — не надо изучать новый синтаксис — все работает на обычном js. Как и в underscore templates например и куче других шаблонизаторов.
es5 хорош тем что быстрее проект разворачивать
yoman, кучи скафолдингов, шаблоны проектов и т.д. решают эту проблему. А за счет es2015+ скорость разработки и удешевление поддержки быстро окупает эти вещи.
На react может конечно и надо переходить
В целом я фанат ангуляра так что… я не перейду)
render() {
let {list} = this.props;
return (
<ul>
{list.map(item => <li>{item}</li>)}
{!list.length && <li className="empty">List is empty :(</li>}
</ul>
)
}
$mol:
$my_pets $html_ul
Pet_row!index $html_li
sub /
<= pet_name!index \
No_pet $html_li
sub /
<= no_pet_messsage @ \Not pets :(sub() {
if( this.items().length === 0 ) return [ this.Empty() ]
return this.pets().map( ( name , index )=> this.Pet_row( index ) )
}
pet_name( index : number ) {
return this.pets()[ index ]
}На таком простом примере преимуществ не видно, но обычно каждая строка — это более сложная штука, так что разделение логики и композиции компонент (аналог шаблонов к компонентной архитектуре) не просто возможно, но и позволяет обуздать сложность, появляющуюся, когда логика идёт вперемешку с кусками html.
Не this.Empty(), а this.No_pet(), конечно же. И с наследованием тут всё хорошо (прям отлично). И нет, это не "самопиар", а объяснение, как та же проблематика может быть решена лучше.
На таком простом примере преимуществ не видно
А на каком будет видно и в чем заключается преимущество? Мы уже как-то дискутировали на эту тему — ваш вариант возможно и имеет свои плюсы, но не годится для большинства людей.
На любом более-менее реальном. Ну, банальная задача: в зависимости от флага заворачивать содержимое в дополнительную обёртку. И тут начинаются пляски с партиалами, хелперами, а то и вообще копипастой.
При разделении композиции и логики вы просто пишете, например:
$my_app $mol_view
as_card true
sub / <= Card $mol_card
sub / <= Info $mol_labeler
title <= info_title @ \Your salary
content / <= Salary $my_currency
value <= salary nullА потом добавляете отдельно любой сложности логику:
sub() {
return [ this.as_card() ? this.Card() : this.Info() ]
}На любом более-менее реальном.
То есть вывести список — не реальная задача?
Ну, банальная задача: в зависимости от флага заворачивать содержимое в дополнительную обёртку.
Как по мне это больше похоже на костыли нежели "реальную задачу". Мне дико не нравится сама идея что дети управляют родителем. Мне больше по душе в другую сторону, когда контейнер решает что у него внутри. Либо приведите менее абстрактное описание зачем это может понадобиться.
Вывести список строк в одиночном теге — не реальная. Более типично — вывести список из деревьев, причём каждый элемент списк должен иметь классы/аттрибуты. В том числе и динамические.
Так тут родитель (блок $my_app) и управляет всеми своими элементами (Card, Info, Salary).
Вывести список строк в одиночном теге — не реальная
Очень реальная. Пример — вывести табличку с заголовком строки в виде ФИО клиента и одним из столбцов через запятую номера заказов.
Только номера заказов должны быть ссылками на страницы этих заказов. Если заказов слишком много, то список должен заворачиваться в спойлер. Клик по имени должен открывать профиль клиента со всеми его заказами.
Сложно по бумаге кликать.
Версия для печати — очень частный случай.
Большинство отчётов не нуждаются в интерактивности, даже если формально не печатаются.
У нас ровно противоположная статистика.
У нас отчёты — это отчёты. Если отчёт подробный, то там всё и так есть. Если агрегированный, значит детали никого не интересуют. Были попытки получить интерактивность у отчётов, но и показали другой инструмент и сказал, что это то, что нужно.
Значит ваша выборка "реальных случаев" не может быть репрезентативной. Да и вывести ссылку — не сильно сложная проблема и я все еще не вижу "преимуществ" вашего подхода. "Мутация" контейнера детьми я расцениваю больше как какой-то костыль, хотя не отвергаю вероятности что вам это для чего-то нужно.
В целом же как по мне ваш варинт излишне сложен если сравнивать его с любым другим.
Значит ваша выборка "реальных случаев" не может быть репрезентативной.
А какая может? Будет чудесно, если вы приведёте ссылку на репрезентативную статистику.
Да и вывести ссылку — не сильно сложная проблема
Я говорил про не только ссылку.
"Мутация" контейнера детьми я расцениваю больше как какой-то костыль
Тут нет никакой мутации контейнера. Тут вывод либо одного компонента, либо другого. И это вполне штатная ситуация для нормального инструмента.
В целом же как по мне ваш варинт излишне сложен если сравнивать его с любым другим.
Реализуйте мой пример по проще :-)
Реализуйте мой пример по проще :-)
<my-card *ngIf="asCard()"></my-card>
<my-info *ngIf="asInfo()"></my-info>Если я правильно понимаю о чем ваш пример.
Нет, типичная реализация того же на Ангуляре будет выглядеть так:
<my-card *ngIf="asCard()">
<my-info>много тегов</my-info>
</my-card>
<my-info *ngElse>копипаста</my-info>типичная реализация того же на Ангуляре будет выглядеть так:
Эм...
ngElse. Это атрибут элемента, он ничего не знает о соседях.Ну то есть мэйнстрим подход, UI как композиция UI компонентов.
не то что бы повторить, у вас должен быть красивый и удобный метод во вью модел который проверяет это условие, и там где надо просто надо добавить отрицание. Логика провери же будет инкапсулирована.
Почему я считаю что такой подход "удобнее" — потому что, как вы заметили тут в комментариях, далеко не все разработчики компетенты. И их нужно ограничивать. А это значит надо делать компоненты максимально тупыми и выносить из них логику. Такие компоненты и тестить удобнее, и в целом приятно работать.
Суть от этого не меняется — нужно повторить вызов метода. А если надо будет привязаться к другому методу, то оба вызова надо будет поправить.
От того, что вы разобьёте один компонент на два сильносвязанных, вы никому жизнь не облегчите, а только усложните. Выносить в отдельный компонент имеет смысл лишь переиспользуемую логику.
А если надо будет привязаться к другому методу, то оба вызова надо будет поправить.
Как жаль что при построении логических выражений нет возможности делать отрицания....
Именно, поэтому в "шаблонах" вообще не должно быть логики
так ее и нет, вся логика в презентерах.
От того, что вы разобьёте один компонент на два сильносвязанных
компоненты не могут быть "сильносвязанными". Они либо имею связи/зависимости либо нет.
В одно месте вам нужно написать "asCard()", в другом "!asCard()". А если нужно первый блок показать при выполнении условий А и Б, второй — Б и В, а третий — А и С? Да, вы можете создать отдельные методы вида "isFirstBlockShowing", но:
Ангуляр не фосирует вынос логики, а наоборот поощряет её написание прямо в шаблоне. И даже если вы лично выносите всю логику, то большинство разработчиков заморачиваться не будут. А фреймворк должен поощрять хорошие практики и препятствовать плохим.
Могут. Выделяя как попало компоненты вы получаете такие вложенные компоненты, которым нужна половина свойств владельца. Ну или они реализуют эту половину свойств самостоятельно копипастой.
Выносить в отдельный компонент имеет смысл лишь переиспользуемую логику.
Очень спорное утверждение, противоречащее многим общепринятым принципам проектирования типа того же принципа единственной ответственности.
Компонент, созданный лишь для того, чтобы его можно было помещать в разные места, — не несёт какой-то уникальной ответственности.
не несёт какой-то уникальной ответственности.
на абстрактных "компонентах" — возможно, как никак что бы определить зону ответственности компонента надо знать что за компонент и за что он отвечает. Потому приведите пример подобной ситуации когда то что мы выноситм не сможет являться полноценным самодостаточным компонентом.
На моей памяти подобного небыло. Были компоненты занимающиеся отображением, весьма тупые, и компоненты-контейнеры, которые максимум разруливали какие компоненты показывать, но не занимались отображением непосредственно.
Ангуляр не фосирует вынос логики, а наоборот поощряет её написание прямо в шаблоне.
в целом — да, но можно во вью модели логику подублировать всегда. У разработчиков всегда будет возможность сломать инкапсуляцию и продублировать логику. С этим надо бороться другими способами.
Могут. Выделяя как попало компоненты вы получаете такие вложенные
Есть такая проблема. Нужна нормальная декомпозиция, а многие разработчики почему-то этого не умеют.
Ок, пусть это будет карточка товара: Фотка, название, описание, цена, список тегов. На всех страницах товары показываются такими карточками, но на некоторых страницах карточка должна быть ссылкой, а на некоторых — нет.
Решение в лоб
ProductCard = (product) =>
<div>
<ProductImage value={product.image}/>
<ProductName value={product.name}/>
<ProductDescription value={product.description}/>
<ProductPrice value={product.price}/>
<ProductTags value={product.tags}/>
</div>;
LinkableProductCard = ({product}) => <a href={product.link}><ProductCard product={product}></a>;Замечательно, тольво вы забыли прокинуть alt в картинку, title в ссылку, завернули теги в ссылку (они ведь тоже должны быть ссылками), в стоимость не прокинули валюту (которую надо оформлять другим цветом), плюс у вас появился совершенно лишний див. А уж про прокидывание правильных классов для навешивания стилей я вообще молчу. Ну и, конечно, создали пяток совершенно лишних компонент, которые нигде не будут использоваться кроме как тут.
Всё строго по ТЗ :) Единственное замечание которое принимаю сходу — title в ссылку, но только как фичереквест. О всём остальном вы не можете судить по этому фрагменту, не зная схемы объекта product. А div не лишний, а несёт семантическую нагрузку — отделяет карточку продукта от остального документа, делает её самостоятельным элементов, на который, в числе прочего, можно ссылаться в файлах стилей. И компоненты лишними не считаю, даже если они не будут переиспользоваться — они улучшают поддерживаемость кода. Вот захотели вы валюту указывать — я джуну скажу "там есть элемент ProductPrice — добавь наименование валюты", а без компонентов придется "там есть семиэтажный Product, поройся в нём, найди часть, где цена выводится и добавь наименование валюты"
ТЗ изменилось. Сколько вам времени потребуется на рефакторинг всего проекта под новые требования, описанные в предыдущем сообщении?
Вы на имя тега будете ссылаться в файлах стилей?
Для отображения валют в разных местах имеет смыл создать компонент CurrencyValue. Отображать ProductPrice вне ProductCard было бы странно.
title для ссылки откуда брать? product.name или product.link.title? Если первое, то до десяти минут, включая деплой на стейдж- сервер. Если второе — ждём бэкенедеров и плюс 10 минут.
Пока в проекте только одно место, где нужно отображать. Появится второе — будем смотреть что в них общего.
Боюсь вы не замечаете масштаб трагедии. Тэги должны являться ссылками, поэтому вы не можете взять и снаружи завернуть всю карточку в ссылку. Ссылка должна быть внутри карточки и при этом опциональной.
карточка должна быть ссылкой
Согласно ТЗ и реализовано. Никаких "внутри" в ТЗ нет. Ели опять ТЗ меняется, то уточните, что значит "внутри". И почему не могу завернуть ссылку в ссылку?

Работает?
Нет, работать оно будет либо в режиме XHTML, либо если вы создаёте DOM скриптом. О каком-либо изоморфном рендеринге HTML в таком случае придётся забыть.
В ТЗ что-то было про изоморфный рендеринг? По умолчанию у нас обеспечивается только функциональность в актуальной стабильной версии Chrome, что фиксируется в коммерческом предложении на внедрение и SLA, ну в Firefox потестим чтобы вёрстка не плыла глобально, а практически весь body генерируется скриптами, клиенту отдаётся минимальная статическая страница.
Прятаться за вами же написанным кривым тз — верх непрофессионализма. Не удивляйтесь потом, что ваши клиенты уйдут к конкурентам, которые продумывают последствия принятых технических решений и обсуждают их с заказчиком заранее, а не когда заказчик понимает, что вы сделали какашку, а он даже не может потребовать исправления. Тактически вы выиграли тысячу рублей, стратегически потеряли сотни тысяч.
Вы когда к стоматологу приходите — тоже выкатываете ему подробное тз или всё же рассчитываете на его профессионализм и понимание что и для чего он делает и к каким последствиям это приведёт?
В ТЗ что-то было про изоморфный рендеринг?
Справедливости ради, вот эти "в тз небыло" немного напрягают. А как же protected variations?
Небольшие (с точки зрения заказчика) могут полностью перевернуть подход к разработке. Навскидку, для изоморфного рендеринга React-"шаблонов" я вообще никаких оценок дать не могу — знаю, что некоторые люди это как-то делают, вероятно с помощью http-сервера на NodeJS. Всё. Есть ли у React различия между рендерингом в DOM и в http-ответ я не знаю, в этом направлении в компании вообще ничего не делалось никогда. И вообще, может из-за требования изморфного рендеринга нужно будет полностью пересмотреть бэкенд часть. Ну или оставить PostgreSQL, но выпилить из проекта PHP и меня вместе с ним.
Обеспечивать во фронтенд коде совместимость с каким-то сервером, которого разработчик в глаза не видел — это не мелочь, которую можно опустить в ТЗ по принципу "это же очевидно, вы же профессионалы"
Ну, там разные тезисы: генерация html-писем, индексирование поисковиками и прочими роботами, поддержка отключённых скриптов и браузеров не поддерживающих скрипты, экспорт в хтмл, быстрый показ страницы, экономия батарейки клиентского девайса.
Ну например "хотите чтобы ваш круто интернет-магазин вообще поисковиками индексировался" или "хотите чтобы конверсия не падала от того что апа загружается у пользователей 5 секунд".
Продать изоморфность весьма просто. И в целом это не требует каких-то больших эфортов если делать нормально.
@vintage я вот только ваш кейс с "а тепер весь блок продукта стал ссылкой" немного не понял. Мне всегда казалось что делать блоки ссылками — не хорошо, и как правило была бы ссылка где-то внутри блока а какой-то декоратор над контейнером уже бы превращал весь блок в ссылку. Это как бы и кейс изоморфности покрывает, и делать легко и просто, и нет конфликтов со спецификациями.
Ну например «хотите чтобы ваш круто интернет-магазин вообще поисковиками индексировался»
А он индексируется только при изоморфном рендеринге? :)
Быстрее и надёжнее индексируется, если рендерится на сервере. Но для этого не обязательно делать изоморфный рендеринг, есть способы попроще, типа prerender.io.
Или других способов отдавать выдачу не за 5 секунд нет?
Тут проблема не в отдаче, а в рендеринге. Сложная страница — долгий рендеринг. Мобильный девайс медленный, батарейка хилая, а серваков мы можем понаставить реактивных пачку. К сожалению редко какой современный фреймворк умеет в ленивый рендеринг, чтобы рендерилось не всё, что есть на странице, а только лишь то, что попало в видимую область.
Я не очень понял, чем то, что вы описали отличается от реализации VolCh.
ListItemsOrNoItems = ({items}) => items.length !== 0 ? <ListItems items={items}/> : <NoItems/>;
ListItems ({items}) => <ul>{items.map((item) => <ListItem item={item}/>)}</ul>;
ListItem = ({item}) => <li>{item}</li>;
EmptyList = () => <p>No items</p>;
У каждого компонента ровно одна собственная уникальная ответственность. Будет она переиспользоваться где-то, может будет дублироваться — дело десятое. Главное — декомпозиция ответственностей и обязанностей.
Замечательно. А если мне нужен ListItemsOrNoItems, но с другими ListItems и NoItems?
Что-то вроде
ListItemsOrNoItems = (items, AbstractListItems, AbstractNoItems) => items.length !== 0 ? <AbstarctListItems items={items}/> : <AbstarctNoItems/>;
и вызов codehtml
<ListItems items={items} AbstractListItems={ListItems} AbstractNoItems={NoItems/} />P.S. что-то разметка глючит
Очень наглядно, спасибо.
Естественно в компоненте могут быть определены значения по умолчанию для дочерних элементов — если не указано, то берем стандартный.
Чудесно, особенно когда таких опциональных компонентов больше 2.
Это же XML по сути.
ListItemsOrNoItems = (items, AbstractListItems, AbstractNoItems) => items.length !== 0 ? <AbstarctListItems items={items}/> : <AbstarctNoItems/>;Это лапша. И в жизни это так не работает, так как вы не прокидываете параметры в в создаваемые тут компоненты.
Присмотритесь — прокидываю. И в чем лапша?
Вы прокидываете один единственный параметр — items.
От количества параметров что-то зависит? Тем более их можно группировать в объекты типа options
Конечно, апи усложняется, апи меняется, вы решили очень частную задачу, и это решение не переиспользуемо.
Наговнокодить-то на реакте легко и просто, я с этим не спорю. Но вот сделать гибкое, легко поддерживаемое, понятное решение — это нужно попариться.
Чем оно не переиспользуемо? Вывод списка элементов или элемента, замещающего пустой список — типовая задача и данный сниппет её решает. Передачу дополнительных параметров (что обычно для таких задач не требуется, стили или инлайнятся/импортятся в конкретных элементах, или через контекст передается тема) для дочерних элементов можно реализовать разными способами, например через…
Договаривайте уж. Через контекст? Глобальную переменную? Урл?
Это не многоточие русского языка, а рест оператор джаваскрипта/джейэсикс :)
что ж вы сразу-то этого не сделли? Давайте посмотрим какой код у вас получится.
Для сравнения, у меня получился такой.
Рендерит списки любых компонент, а если список пустой — рендерит опять же произвольный компонент переданный владельцем. При этом не трубется никаких прокидываний параметров через...
Не видел необходимости. KISS
Теперь она появилась, не заставляйте иеня упрашивать вас написать полноценное переиспользуемое решение, которое можно применять в реальных ситуациях, а не только в комментариях на Хабре :-)
Не заставляйте меня делать продакшен решение в комментариях на хабре по неясным для меня критериями переиспользуемости.
Ну, я же не поленился, и сделал продакшен решение по максимальным критериям переиспользуемости. Потратил на это (включая написание демонстрационного примера) не более 5 минут. Неужели на реакте это потребует сильно больше времени? Как же так?
SPA
слабой индексацией в поисковиках
Как правило, приложение, в отличии от сайтов и порталов, не нуждается в индексации.
тысячами разработчиками писались одни и те же вещи, часто с одними и теми же ошибками. Попробуйте написать такое же (желательно так же с объектом Greeting, получаемым из базы, а не массивом или stdClass) приложение на голом PHP и количество кода вас неприятно удивит. Или в коде будут грубые ошибки.
Это смотря какое приложение. Да и фреймворки разные есть. Тут больше важно что нужно знать современные концепции и стандарты современного веб приложения. Вот composer — да; PSR'ы; Неймспейсы; Автолоадинг; Система контроля версий; Единая точка входа; Паблик директория; Роутинг; Шаблонизация; Query builder. Остальное имхо опционально.
И если уж говорить о самой статье, то замените symfony на laravel и react на vue. И статья выйдет короче)
голого php хватит для реального приложения
Его то хватит, вопрос в стоимости решения и покрываемых кейсах.
Как минимум, нужно ещё подумать как задача будет изменяться в обозримом будущем.
Почему-то при разработке сайта визитки никто не желает вкладывать туда потенциал соц.сети или интернет магазина, а пилят именно визитку. И если клиент хочет из этой визитки интернет-магазин получить, то ему, собственно, выкатывается отдельный ценник.
Да ладно не желают. Желают, но узнав сколько оно стоит (или в случае внутреннего заказчика — сроки), то свои аппетиты умеряют. Но возможность развития закладывать нужно практически всегда, особенно если заказчик уже рассказал о своих будущих хотелках.
Да ладно не желают. Желают, но узнав сколько оно стоит (или в случае внутреннего заказчика — сроки), то свои аппетиты умеряют.
потом попробовать написать свой фреймворк
Тут можно напороться на проблему "а что писать то". Ну то есть мы хотим на практике поучиться — это похвально. Но как новичку определить что он делает что-то дельное? Мы же таким образом можем вредные привычки сформировать у человека.
Может выложить свое творчество на Хабр — тут очень доброжелательно ему объяснят, что он делает не так.
В целом есть еще чатики всякие, тостеры и подобное. Ну то есть получать фидбэк сейчас есть где. Другой вопрос что… то о чем я писал немного о другом.
Допустим вы решили написать свой фреймворк но понятия не имеете что в нем должно быть… У вас еще нет конкретных задач которые решает фреймворк, и делать мы его будем в отрыве от реальности. И пихать туда будем кучу всего просто посмотрев на других, не разобравшись почему там так и зачем. И скорее всего ближайшее код ревью будет не через неделю а через месяц минимум. А на таких масштабах "конструктивно" уже сложно.
Так что вместо написания своих фреймворков нужно прикладные задачи решать. Если воображение не хватает придумать себе задачу — можно опять же во всяких этих чатиках поспрашивать, или просто погуглить и попробовать повторить проект который нравится. Еще неплохо если будут генерить "изменения требований", причем желательно что бы это делал не тот же человек который реализует проект.
Ну и под "прикладными задачами" я подразумеваю не бложики, а что-то интереснее. Например — клоны инстаграммов, твиттеров. Какие-то утилитки. Хороший пример в чатиках проскакивал — человек отрабатывал навыки на примере тулы для генерации чейджлогов из git log.
Мне кажется более логично изучить голый PHP.
А еще было бы неплохо поучиться тесты писать до момента когда надо фреймворк брать. Ну и не стоит на голом пыхе заниматься коммерческой разработкой (если у вас нет достаточно опыта).
А так да, знание фреймворка не убережет вас от незнания языка. Логику мы все ж на php пишем.
<?php
echo 'Hello, world!';
Hello, world!
не увидел обвеса статьи в "sarcasm"
Доставание объекта из репозитория не бизнес-логика. Здесь бизнес-логики по сути нет вообще, только бизнес-данные.
/**
* @Route("/greetings/{id}")
*/
public function greetingAction($id)
{
$greetingsManager = $this->get('greetings');
$greeting = $greetingsManager=>get($id);
return new JsonResponse(['greeting' => $greeting]);
}
class GreetingController{
private $greetingService;
public function __construct(GreetingService $greetingService){
$this->greetingService = $greetingService;
}
...
}
для контроллеров удобнее через дабл диспатч… ух жду symfony 3.3… смогу убрать свои кастыли для этого. В целом нет ничего зазорного не делать контроллеры сервисами.
для контроллеров удобнее через дабл диспатч
В целом нет ничего зазорного не делать контроллеры сервисами
Не знаю как это.
Это когда зависимости для метода прокидываются как аргументы этого метода:
// вместо такого
public function doSomething()
{
$this->someData = $this->dependency->someCalculations($this->someData);
}
// так
public function doSomethingCooler(MyDependency $dependency)
{
$this->someData = $dependency->someCalculations($this->someData);
}Хорошо подходит для экшенов контроллеров и если вы хотите какую-то логику опрокинуть в сущность чтобы не плодить геттеров и не ломать инкапсуляцию.
Откуда же им взять состояние, чтобы не быть сервисами?
Поясню свою мысль. Контроллер это такая штука, которая уж больно тесно интегрирована с фреймворком (она зависит от абстракции запросов как минимум, шаблонизаторов и подобного). Делать их "независимыми от фреймворка" банально не выгодно. В них не должно быть никакой логики что бы нас это парило.
А при помощи дабл диспатча мы можем полностью устранить необходимость в экшенах контроллера юзать сервис локаторы и тем самым получить практически тот же профит что и от controller-as-service но без гемороя.
А кто мешает сейчас писать в режиме 1 action = 1 controller?
Получается именно то самое поведение, которое вам хочется.
далеко не то же. Зачем мне ажно целый класс который выглядит так:
class RegisterUserAction
{
private $handler;
private $loginManager;
public function __construct(RegisterUserHandler $handler, LoginManager $loginManager, Flusher $flusher)
{
$this->handler = $handler;
$this->loginManager = $loginManager;
$this->flusher = $flusher;
}
/**
* @Route("/users", methods={"POST"})
*/
public function __invoke(Request $request)
{
$user = $this->handler->__invoke($this->mapRequestData($request));
$this->flusher->flushChanges();
return $this->loginManager->login($user);
}
}если я могу сделать так:
public function registerUserAction(Request $request, RegisterUserHandler $handler, LoginManager $loginManager)
{
$user = $handler($this->mapRequestData($request);
$this->flushChanges();
return $loginManager->login($user);
}Ну то есть кода меньше, делает одно и то же. Это же контроллеры, там нет логики, даже логики уровня приложения. Оно просто связывает HTTP и приложение. Вот если бы можно было полностью от HTTP отвязаться на уровне фронтконтроллера, у меня остались бы только хэнделеры и контроллеры бы юзались как адаптеры например для совместимости со старыми версиями API. Но увы я пока не придумал эффективного способа.
PSR-7 middleware фреймворки реализуют именно то, что вы хотите.
Не то же самое. Повторюсь — я пробовал, на 100% не выходит. Проблема обычно с http реквестом или с flush-ем доктрины. Все равно нужна какая-то одна штука на запрос которая будет связывать все вместе. Проблему частично решает graphql но это если он нам подходит.
Вот если бы можно было полностью от HTTP отвязаться на уровне фронтконтроллера, у меня остались бы только хэнделеры и контроллеры бы юзались как адаптеры например для совместимости со старыми версиями API. Но увы я пока не придумал эффективного способа.
Это хорошо подходит когда вы не любите фронтэндщиков.
CommandBus это хорошо, это прикольно, это весело. Но это не значит что HTTP запрос который дергает шину команд ничего не должен возвращать. А если вам надо что-то вернуть — надо знать что возвращать.
p.s. Практикую CQRS на проектах, так что вдохновиться увы не могу и думал над этим не один месяц. Отказаться от контроллеров является непрактичной затеей. Делать экшены контроллеров как классы практично только если у вас логика в контроллерах.
Зачем мне ажно целый класс который выглядит так
и будет по мидлвэру на действие. То есть адаптеры такие небольшие. То есть… контроллеры.
В моем понимании разные форматы это рендеринг в разные View
Или в самом контроллере анализируя пришедший из роутинга параметр формата буду подключать необходимые View.
Эдакий Context switch.
Как правило, для HTML нужно возвращать больше данных.
То есть мы можем воспринимать контроллеры как еще один адаптер, еще один мидлварь. И у нас будет адаптер (мидлварь) которая на основе правил маршрутизации будет выбирать нужный. Пока не вижу ни разницы в подходах ни профита. Я лишь выбираю способ с которым удобнее. В PHP удобнее класс-контроллер с несколькими экшенами и дабл диспатчем. В JS удобнее функции-адаптеры которые выступают как мидлвари.
И у нас будет адаптер (мидлварь) которая на основе правил маршрутизации будет выбирать нужный
Разница между обычным контроллером и пачкой Middleware
Я опять же не понимаю о чем спор. Мидлвари или просто слой адаптеров — это хорошо, но это совершенно отдельный вопрос. Он не решает необходимости иметь некий мидвар на конце цепочки который бы соответствовал одному http запросу. А наличие перед этим мидлварем цепочки, каждый элемент которой делает что-то одно — это просто логично.
и будет по мидлвэру на действие. То есть адаптеры такие небольшие. То есть… контроллеры
не обязательно дробить Middleware по штуке на действие.
Не обязательно. По факту мы можем реализовать:
То есть в общем и целом мы стоим перед выбором — либо у нас роуты будут разбросаны по всей системе (потому что тут можно без контроллера, а тут без контроллера будет сложно) либо у нас всегда будет тонкий слой адаптеров между HTTP и приложением, по экшену на юзкейс.
потому что тут можно без контроллера, а тут без контроллера будет сложно
[
'route' => '/article/update/:id',
'middleware' => [
SessionMiddleware::class,
AclMiddleware::class,
ControllerDelegatorMiddleware::class,
],
'controller' => ArticleController::class,
'action' => 'updateAction',
]
Ну да, можно разделить на мидлвари и всегда парсить куки/боди, проверять права, даже если они фактически не понадобятся. Вместо того, чтобы делать это лениво, в случае запроса к соответствующей сущности.
проверять права, даже если они фактически не понадобятся
Пользователь запрашивает текст статьи. Если статья опубликована — выдаём её без вопросов. Если в черновиках, то проверяем, что пользователь — автор или админ. Жонглирование мидлварями тут ничем не поможет. Удобно это делать на уровне модели, в момент обращения к которой, идёт автоматическая проверка по тем правилам, что соответствуют конкретной сущности.
Не очень удобно. Удобнее это делать между вью и моделью, то есть в контроллере. Правил доступа может быть множество, копить их всех в модели — она разрастется без всякого изменения бизнес-ценности.
Удобнее вообще не разделять серверную логику на M и V и C, ибо этот паттерн предназначен для интерактива с пользователем, а схема "запрос-ответ" не интерактивна, а строго последовательна.
Более продуктивный подход — организовывать все сущности в виде "ресурсов", к которым можно обратиться через любой протокол (http, udp, ws, ssh) через соответствующие адаптеры.
Зачем вам множество правил доступа?
Ограничения прав имеет чуть ли не наибольшую бизнес ценность.
Знаете, когда реализуешь изоморфную модель, то начинаешь смотреть на вещи по другому. Например, на сервере если нет прав, нужно давать отлуп.
А в клиентском приложении нужно деактивировать кнопки, если нет прав. То есть нужно иметь возможность заранее узнавать есть ли права делать определённые действия с определённой сущностью, до попытки выполнить эти действия. И знание это должно не в коде зашиваться, а приходить вместе с сущностью. Права доступа — такой же атрибут сущности, как и прочие её атрибуты.
На многих серверах система "запрос-ответ" уже не используется в чистом виде. Как минимум есть всякие пуш-технологии. Да и сам запрос можно рассматривать как событие UI, причём не важно пользователь его инициировал, кликнув ссылку или другой сервер.
А мне ресурсный подход мало нравится, больше сервисный, он универсальней — сервис может обеспечить CRUD-доступ к ресурсу, а может делать гораздо более сложные вещи. И, главное, бизнес обычно оперирует процессами, а не сущностями.
Не мне, бизнесу. Постоянно новые требования. Но эти требования обычно к основной бизнес-логике не относятся. И бизнес-ценности особой не имеет, в плане что не приносит прибыли, защищают от потерь, нужны как неизбежное зло, но прибыли не приносят. Мировая практика показывает, что неразрывное связывание объектов прав доступа (это не только сущности) и описания самих прав (особенно императивное) крайне редко приносит пользу. Различные ACL, хранимые и обрабатываемые отдельно более эффективны как в плане удобства их манипулированием, так и в плане улучшения основной логики — мухи отдельно, котлеты отдельно.
Что является атрибутом, а что нет, определяется не разработчиком приложения, а экспертами предметной области. И даже если эксперты настаивают на том, что право доступа неотъемлемый атрибут сущности или экземпляра процесса, то разработчик может их разбить и связать 1:1, чтобы облегчить свои задачи, например не хранить в базе данных код определения прав с последующим его интерпретацией.
На многих серверах система "запрос-ответ" уже не используется в чистом виде.
В рамках REST это в любом случае остаётся — запрос ответ. Даже в схеме "запрос от одного сервера, ответ другому". Нет сохраняющегося состояния вьюшки — нет MVC. Комбинацию клиент+сервер уже можно рассматривать как MVC, точнее на клиенте MVC, но модель синхронизируется с мастер-моделью на сервере.
И, главное, бизнес обычно оперирует процессами, а не сущностями.
Чем бизнес оперирует — то и есть сущность.
И бизнес-ценности особой не имеет, в плане что не приносит прибыли, защищают от потерь, нужны как неизбежное зло, но прибыли не приносят.
Всё же хотелось бы более конкретный пример. Если есть требование, например, что автор может редактировать статью, то проще, производительнее и надёжней просто проверить авторство (причём это можно делать даже на клиенте, без обращения к серверу), чем городить обращение к ACL и обеспечивать каждого автора правами на созданные ими статьи, а когда логика прав меняется — перетрясать ACL.
Даже когда надо выдавать произвольные права произвольным людям/группам — удобнее оказывается просто хранить в модели списки субъектов соответствующим ролям. Но опять же, это применимо лишь для графовой субд, а для реляционной проще вкрутить ACL табличку, да.
В рамках REST это в любом случае остаётся — запрос ответ. Даже в схеме "запрос от одного сервера, ответ другому". Нет сохраняющегося состояния вьюшки — нет MVC. Комбинацию клиент+сервер уже можно рассматривать как MVC, точнее на клиенте MVC, но модель синхронизируется с мастер-моделью на сервере.
Я рассматриваю клиент-сервер как MVC, в котором V и C размазаны между клиентом и сервером. Что между клиентом и сервером есть односторонний синхронный канал "запрос-ответ" — деталь реализации, обусловленная протоколом обмена. Что на клиенте может быть дублирование модели и свое MVC — деталь реализации.
Чем бизнес оперирует — то и есть сущность.
Очень отличается от классического определения сущности в моделировании предметных областей. Как минимум, бизнес оперирует сущностями и процессами, в которые сущности вовлечены. Например, сущности "клиент" и "договор" вовлечены в процесс "заключение договора".
Всё же хотелось бы более конкретный пример. Если есть требование, например, что автор может редактировать статью, то проще, производительнее и надёжней просто проверить авторство (причём это можно делать даже на клиенте, без обращения к серверу), чем городить обращение к ACL и обеспечивать каждого автора правами на созданные ими статьи, а когда логика прав меняется — перетрясать ACL.
ACL просто как пример. Проверять авторство — да, но в слое проверке прав доступа писать
$userCanEdit = ($article->author === $user) || $user->hasGroup('admin', 'moderator') || $user->hasPermission('edit_any_article') || ($user->birthDate == new \DateTime('1975-05-03')); а не в методе Article::isEditableBy(User $user) то же самое — слишко сильная связанность с User получается.
И способ хранения и сущности, и прав особого значения не имеет для бизнеса, как правило.
Как минимум, бизнес оперирует сущностями и процессами, в которые сущности вовлечены. Например, сущности "клиент" и "договор" вовлечены в процесс "заключение договора".
От того, что некоторые сущности назвали процессами, они сущностями быть не перестали. Процесс "заключение договора" сам по себе вовлечён в процесс "продажа товара", который агрегирован в сущность "продажи".
не в методе Article::isEditableBy(User $user) то же самое — слишком сильная связанность с User получается.
И что в этом плохого?
И способ хранения и сущности, и прав особого значения не имеет для бизнеса, как правило.
От того, что некоторые сущности назвали процессами, они сущностями быть не перестали. Процесс "заключение договора" сам по себе вовлечён в процесс "продажа товара", который агрегирован в сущность "продажи".
Сущность — вещь, процесс — действие.
И что в этом плохого?
На любой чих службы безопасности и т. п. нужно менять бизнес-логику. На любое изменение сущности пользователя нужно менять бизнес-логику.
Формат хранения определяет мышление
Я вообще стараюсь не думать о хранении пока не определюсь с объектной моделью. Выбор из SQL, noSQL или вообще в какого-то веб-хранилища последний этап.
Сущность — вещь, процесс — действие.
А что толку от этого переименовывания? Суть остаётся та же. Действие, как и любая вещь, обладает состоянием, связями с другими вещами. Как и любые вещи, действия складываются в различные коллекции. Даже процессорные потоки — это не более чем особые структуры. Что уж говорить про собственно процессы.
На любой чих службы безопасности и т. п. нужно менять бизнес-логику. На любое изменение сущности пользователя нужно менять бизнес-логику.
И? Если вы перенесёте эту функцию из файла А в файл Б, связанный с первым как 1-к-1, что-то сильно изменится?
Выбор из SQL, noSQL или вообще в какого-то веб-хранилища последний этап.
А с какими типами СУБД вы работали? Ну, помимо реляционных и словарных.
Действие не обладает состоянием. Оно либо есть, либо его нет. Можно условно считать, что состоянием действия является супепозицией состояний всех вовлеченных сущностей, но это только условность.
С большой вероятностью у нас будет не два файла, связанных 1-1, а множество, связанных с Б (пользователем) многие-к-одному. И при размещении логики проверки прав преимущественно в сущностях (все их там разместить скорее всего не получится, если молотком не вбивать), при изменении сущности пользователя нужно будет менять все сущности модели.
dBase к каким относится? ) А так из экзотики xBase и Db4o немного крутил.
Действие не обладает состоянием. Оно либо есть, либо его нет.
Процесс обладает состоянием. Например, текущая стадия.
при изменении сущности пользователя нужно будет менять все сущности модели.
Зачем? Реализуйте тот же интерфейс.
dBase к каким относится? ) А так из экзотики xBase и Db4o немного крутил.
Первая — реляционная. Остальные — хз. Попробуйте поиграться с какой-нибудь графовой. Даже если не будете использовать в дальнейшем, это заставляет взглянуть по другому на привычные вещи.
Сложно представить процесс, в котором есть бизнес-необходимость хранить текущую стадию отдельно от сущностей в него вовлеченных.
Речь об изменении интерфейса сущности пользователя.
Я приверженец подхода по которому система хранения должна минимально влиять на объектную модель. Посмотрю, может быть некоторые мои модели удобнее будет хранить в ней, чем в реляционных или документных.
Сложно представить процесс, в котором есть бизнес-необходимость хранить текущую стадию отдельно от сущностей в него вовлеченных.
Процесс "списание товара". Подчинённый подготавливает список товаров, руководитель подтверждает или нет, бухгалтер оформляет списание официально, только если списание подтверждено.
Речь об изменении интерфейса сущности пользователя.
Значит всю логику работы с пользователями нужно будет перетрясти. И будет проще, если эта логика лежит рядом с соответствующими сущностями, а не где-то в сторонке.
Этап процесса однозначно определяется состоянием сущности "список товаров на списание" и наличием связанной с ней проводки. Причём связь может быть односторонней — только проводка ссылается на список. А собственного состояния у процесса и нет. Каждый этап должен иметь результат в виде создания, изменения или удаления каких-то сущностей.
Причём связь может быть односторонней — только проводка ссылается на список.
Ссылка — это тоже состояние. Вам не кажется странным, что у вас тут две сущности, связанные 1-к-1 и которые всегда существуют в паре? Что вы выиграли от такого условного разделения "процесса списания", на "проводку" и "список товаров" (который на самом деле не список, а полноценный документ с подписантами, количеством, ценами и прочей требухой — почему бы не назвать этот документ "проводкой"?)?
Не всегда. Проводка формируется только если список утвержден руководителем (представим, что бухгалтерия права голоса не имеет). Более того, руководитель может утвердить список лишь частично (для простоты в комментарии) и проводка не будет соответствовать списку.
В целом, исходя из своих знаний и опыта в областях оперативного и бухгалтерского учёта, как в теории так и на практике, а также контекста топика и треда решил, что первичный документ на списание должен быть отделён от проводки по многим причинам, одна из которых стоимость лицензий на бухгалтерскую программу для подчиненного и руководителя.
Представим что мы реализуем полный жизненный цикл. Какой смысл разделять эти сущности? Предлагаете дублировать сущность и "закрывать" предыдущую после каждого пройденного шага процесса? А если надо будет вернуться на шаг назад не потеряв при этом привязанные к сущности обсуждения в почте?
Простой — это разные выделенные контексты. Оперативный документооборот и бухгалтерский учёт. Нет смысла создавать бухгалтерские проводки "в планах" на каждый чих, особенно если 90% из них руководством не утверждается. Ну а если в требованиях априори есть, что в процессе утверждения список товаров может измениться и необходимо хранить первоначальную заявку, то мы очень сильно усложним систему, не разделив эти слаюосвязанные и в реальной жизни сущности.
В рамках REST это в любом случае остаётся — запрос ответ.
Вот только есть мнение что подход в чистом виде устарел немного, требования сейчас чуть-чуть другие.
В целом подход запрос-ответ хорошо ложится на MVA.
Я проспал statefull революцию?
graphql + subscribe пиарят, все чаще вэбсокеты для мобилок юзаются с доставкой ивентов на сервер вместо стэйта… Не уверен что это "революция" но тенденция есть.
Ну и в целом есть нюансы, можно сделать stateless сервер (легко скейлить) с подпиской на изменения данных используя websockets.
Вебсокеты батарейку кушают, поэтому лучше всё же централизованные пуши.
Полноценный subscribe я мало где видел. Но подписки — это очень уж ограниченное состояние. Я бы сказал statefew.
Вебсокеты батарейку кушают, поэтому лучше всё же централизованные пуши.
Батарейку они кушать могут только за счет проверки соединения (ping/pong). В библиотеках типа socket-io вы можете сами выставлять "частоту" проверок. Ну а в бэкграунде на всяких там iOS у вас всеравно нет выбора — надо юзать пуши.
Ну и в целом у пушей тоже есть ограничения, вроде отсутствия гарантированной доставки (иногда важно знать что было доставлено на клиент а что нет). Так же у эпл есть небольшие ограничения по частоте отправления пушей. Ну и иногда нужно организовывать весьма интенсивное взаимодействие между клиентом и сервером.
Но подписки — это очень уж ограниченное состояние. Я бы сказал statefew.
Ну так это же хорошо :)
Да, и "Админы" — это тоже модель.
Доменная модель естественным образом представляется в виде графа, где все узлы друг с другом перелинкованы. Пользователь логически "знает" о всех своих статьях точно также как и статья "знает" о своём авторе. Да, это не вписывается в реляционную модель, где связь многие-ко-многим эмулируется через поиск по индексу. Если же вы попробуете использовать графовую субд, то перестанете удивляться тому, что многие сущности знают друг о друге. Статья знает об авторе, пользователь о своих группах, группа о ролях, роли… о статьях :-)
Конечно, все эти связи есть смысл хранить, если не требуется их быстрый поиск, но многие можно вычислять динамически разворачиванием графа.
Почему это незачем, если ей, чтобы рассказать о правах, надо знать о ролях?
Затем, чтобы её правильно визуализировать.
У статьи вполне конкретные уникальные правила проверки прав. Зачем их уносить далеко от реализации собственно этой модели?
Это не у статьи проверки, это у пользователей. :) Посмотрите на реальность — у документов нет систем проверки прав, есть комплекс мер, которые мешают не авторизованному пользователю получить доступ к совсекретному документу, но сам документ лишь чистая информация.
Более того, Статье вообще незачем «знать» о ACL-Ролях.
Сильно зависит от задачи. Частенько именно "статья" сможет сказать кто ее может редактировать. Например только ее автор. Эта информация доступна только ей.
Но не надо пытаться "обобщить" все на счете.
Например только ее автор
Не так уж частенько, на самом деле. Скорее это исключение, что статья знает кто её может редактировать, а не правило. Статья может сообщить системе проверки прав доступа, кто её автор, если системе это нужно, но держать в сущности статьи список всех пользователей и(или) пускай групп, которые могут её редактировать — перебор.
Судя по первому взгляду там не запись знает, кто её может редактировать, а система проверки прав доступа решает по метаданным, сохраненной в одной записи с основными данными. И я сильно удивлюсь, если в этой СУБД нет суперпользователя, который может отредактировать запись, даже если его нет в метаданных записи. В любом случае не похоже, что там хранится полноценный объект, а не, максимум, его данные и метаданные.
Пользователь там — это просто запись типа OUser в БД. Если входишь под таким пользователем и обращаешься к restricted записям, то срабатывает повешенный на них хук, проверяющий права. Хук наследуется от суперкласса ORestricted и к неунаследованным от него записям не применяется. Так что фактически это объект со своим состояним и поведением.
Ну, и да, всегда можно войти администратором кластера и воротить что угодно, но это к бизнес-модели уже не относится :-)
Так что фактически это объект со своим состояним и поведением.
Не согласен. Поведение (проверка прав) не принадлежит записи, из записи только иногда (например если юзер не суперюзер) берутся данные для выбора той или иной стратегии поведения для системы проверки прав доступа. Не называем же мы объектом сишную структуру, которую читает какая-то функция. Смысл объекта — поведение вместе с данными, а не снаружи.
Покажите мне хоть один компилируемый ООП язык, где методы принадлежат объектам :-D Везде методы — это отдельно лежащие функции, которым в качестве контекста передаётся ссылка на структуру. Обычно в самом объекте максимум, что хранится — это ссылка на таблицу виртуальных методов.
В случае ORestricted — у записи есть ссылка на её класс, у класса — на супер класс, на суперклассе навешан хук. Та же таблица виртуальных методов, только в профиль.
Покажите мне хоть один компилируемый ООП язык, где методы принадлежат объектам
покажите мне хоть один пример чистой функции, при компиляции которой не изменяются значения регистра переходов процессора.
Это я пытаюсь донести что вы предлагаете снять один из уровней абстракций. В ООП важным является поведение объекта. Да, само по себе поведение это просто функции которые лежат отдельно и есть некая таблица вызовов. При вызове в рантайме подставляется контекст.
Вот только ООП оно не про объекты. "Все есть объект". Это не значит что у всего должен быть класс, это буквально означает что "любая штука есть объект". Скаляры — объекты, просто в некоторых языках у них нет поведения. Даже в языках вроде Erlang мы можем под объектом со своим стэйтом и поведением понимать тред. И треды между собой будут обмениваться сообщениями. И можно подменять треды в рантайме (late binding).
То есть совершенно не важно что вы называете объектом. Важно то, что статически, на уровне исходников, у вас стэйт и обработка этого стэйта будут максимально рядом. Инкапсуляция и data-abstraction. А как оно там в рантайме — нам не особо интересно с практической точки зрения. Семантический разрыв и все такое.
Таблица виртуальных методов — техническая деталь реализации, логически же метод принадлежит объекту.
Вы делаете что-то вроде Record::findById(1)->read(): record, когда получаете отлуп от системы управления правами или делаете Record::findById(1): record? Если второе, то проверкой права на чтение данных записи занимается не запись. Если первое, то как ограничить право, чтобы клиент не узнал о существовании записи в одних случаях, и узнал но не мог прочитать — в других.
Логически и в OrientDB хук принадлежит записи :-)
Если нет права на чтение, то запись просто не будет найдена в поисковых запросах. Если у вас есть её идентификатор, то будет отлуп при попытке чтения её данных.
Каждая запись знает, что есть суперюзер и его надо пускать всегда?
Кем не будет найдена, если проверка прав осуществляется в записи? Сначала найдётся для движка, а потом сама удалится при попытке движка отдать её? Или, всё таки, движок её найдёт, увидит, что пользователь не в ACL записи и не суперадмин и исключит из результатов? А если надо различать ситуации "не найдена" и "нет прав доступа" при общем запросе типа "вывести список всех сотрудников, а также их оклады если пользователь является начальником сотрудника"?
Хук скорее всего знает, да.
Скорее всего движок попытается прочитать, сработает хук, который проверит права и даст отлуп, а движок пропустит эту запись. Но я не особо знаком со внутренностями. Да это и не важно — для пользователя "объект сам знает кто как может с ним работать".
Очевидно, оклады должны лежать в отдельных записях с отдельными правами. В OrientDB минимальная гранулярность прав — объект. Я на уровне приложения реализовывал уже гранулярность до конкретных свойств.
для пользователя "объект сам знает кто как может с ним работать".
Если движок пропускает записи, с которым пользователь не может работать, а не даёт отлуп на всю выборку, то не объект, а движок знает.
В OrientDB минимальная гранулярность прав — объект.
Тогда для очень многих схем управления доступом он не подойдёт. Очень часто права ограничиваются к полям объектов и нередко в зависимости от состояния этой, а то и других сущностей.
А чем вас не устраивает класс из нескольких экшенов? У вас лимит на количество методов в классе? :)
Ну человек же борется с километровыми конструкторами путем внедрения необходимых каждому методу зависимостей прямо в екшен.
не совсем. Я борюсь с lack of cohesion. У меня есть по классу на экшен приложения, по классу на юзкейс. А контроллеры лишь являются адаптером между HTTP и этим "юзкейсом". Мне проще сделать один класс с 5-ю экшенами связанными по смыслу, а поскольку всем 5-ти экшенам нужны разные зависимости инъектить их через конструктор как-то не очень выгодно.
так как в аргументах смешиваются зависимости и непосредсвтенно аргументы.
А что, аргументы уже не являются зависимостями? Да, это зависимость по данным, но смысл примерно тот же. Грубо говоря у вас будет "запрос" + 1-2 зависимости для обработки этого запроса. Почти всегда. Крайне редко вам понадобится что-то сложнее.
Но дабл диспатч привязывает вас к контейнеру который умеет в дабл диспатч.
Нет, дабл диспатч привязывает меня к мидлвари которая достаточно умная что бы сделать $container->get(Foo::class) и заполнить аргументы метода. А делать свои имена сервисов умеют все.
Если что — контейнер симфони этого не умеет из коробки. У меня есть ~80 строк кода которые добавляют эту функциональность + кэширование.
один класс с 5-ю экшенами связанными по смыслу,
Я только не совсем понимаю почему они связаны между собой, а зависимости при этом у всех разные…
Я только не совсем понимаю почему они связаны между собой, а зависимости при этом у всех разные…
Потому что слегка разные операции + у меня есть отдельные классы которые реализуют одно конкретное действие.
есть у меня например ресурс /accounts/{id}. Он содержит в себе операции над этими ресурсами:
/accounts/{id} — создание аккаунта/accounts/{id} — детали аккаунта/accounts/{id}/withdrawn — вывод средствС точки зрения группирования операций мне удобнее держать их в одном классе как 3 экшена. Просто с точки зрения структурирования кода.
Причем для всех трех операций у меня свои зависимости. Для создания аккаунта я хочу сервис который умеет их делать, записывать в базу и т.д. Для второго мне нужен сервис, который достанет нужную информацию об аккаунте. Это не может быть тот же сервис что и для создания аккаунта ибо они могут даже с разными базами данных работать. И для вывода средства у меня есть третий сервис, поскольку он работает больше с пеймент гейтвеем и с точки зрения бизнеса это совершенно отдельный процесс. Но с точки зрения пользователя — оно все рядом.

App\Action\User\Register::class => function (ContainerInterface $container) {
return new \App\Action\User\Register(
$container->get(RouterInterface::class),
$container->get(TemplateInterface::class),
// прочие зависимости
);
},
App\Action\User\Login::class => function (ContainerInterface $container) {
return new \App\Action\User\Login(
$container->get(RouterInterface::class),
$container->get(TemplateInterface::class),
// прочие зависимости
);
},
- Invoices
- Handler
- PurchaseProductHandler
- TransferMoneyHandler
- PayTheInvoiceHandler
- Model
- Infrastructure
- Http
- Orders
- Handler
- AskForRefundHandler
- ...У меня примерно так. Но все равно нужны контроллеры, а "хэндлеры" это просто application-level сервисы, реализация отдельных юзкейсов. Директории верхнего уровня описывают ограниченные контексты (Bounded Context).
У вас лимит на количество классов? оО
У меня лимит на количество кода не приносящего пользы. Чем меньше — тем лучше. У меня лимит на количество кода в экшене контроллера.
Увы в реальности так красиво выходит только на очень простых задачах. В остальных случаев хоть какой-то адаптер нужен для каждого конкретного UI. То что мы потом сверху можем через контент негошиейшен разруливать делать json или html — это мелочи.
А флаш где делать? Мне его надо сделать между "сделал дело" и "сделал выборку для респонса".
Более того, я и так это делаю в мидлварях. Просто у меня всеравно есть необходимость юзать контроллер как точку, которая уже разделяет операции чтения и записи.
Если есть слой сервисов, то думаю в нем,
а я думаю в том месте, которое регламентирует границы бизнес транзакции. То есть если у нас есть сервис уровня приложения, который описывает какой-то юзкейс, или бизнес транзакцию, то флаш должен быть сразу после вызова этого сервиса.
Через такие штуки как AOP мы можем это разрулить (декорация или ивенты неудобно).
можно реализовать специальный Middleware для этих целей. Вариантов куча.
В этом случае для каждой бизнес транзакции нам нужна мидлваря а при таком раскладе у вас разница между контроллером и мидлварем невилируется. Я вообще не понимаю о чем спор. Покажите мне код который не требует наличия контроллеров, а я скажу что это либо "тоже самое" либо "вот вам причины почему это неудобно".
а я думаю в том месте, которое регламентирует границы бизнес транзакции
Покажите мне код который не требует наличия контроллеров
повторю еще раз — мидвари это просто цепочка адаптеров. контроллер = адаптер на границе приложения и UI layer. Вы можете делать все так что бы "контроллер" был лишь одним из элементов цепочки мидварей.
p.s. я использую мидлвари, у меня туда вынесены кеширования, аутентификация, jwt авторизация, есть еще кое какие мои мидлвари которые занимаются раграничением прав, но у меня все еще есть контроллеры и за пол года размышлений я не смог от них отказаться. Из вариантов которые пока не пробовал и которые могут подойти — использование graphql или подобных подходов, где вот этот вопрос "что делать после изменения данных" регламентируется на уровне запроса клиентом. В этом случае всем этим может заниматься одна единственная мидлваря.
Ну то есть кода меньше, делает одно и то же.
Проблема обычно с http реквестом или с flush-ем доктрины. Все равно нужна какая-то одна штука на запрос которая будет связывать все вместе.
Это когда зависимости для метода прокидываются как аргументы этого метода:
а представьте пример с 5-ю зависимостями
у меня есть правило — у любой штуки не должно быть более 3-х зависимостей. Если у вас их больше — вам нужно подумать больше над декомпозицией.
Хорошо подходит для экшенов контроллеров
public function *Action(Request, Response, [$next]){
...
}
Поясню свою мысль
в 2017-ом году сервисы менеджеры сущностей являются моветоном. Хотя и в нулевых так было...
/**
* @Route("/greetings/{id}", requirements={"id": "\d+"}, methods={"GET"})
*/
public function greatingAction(int $id, Greater $greater)
{
return $this->json([
'greating' => $greater->greet(),
]);
}Полагаю, что требования к Hello world звучат примерно так «нужно уметь выводить надпись Hello world». Точка.
Незаслуженно забыли о микросервисах. Очевидно же, что вывод Hello нужно реализовать в сервисе приветствий (Greeting), а вывод World нужно делегировать сервису геолокации.
Крайне спорное утверждение
выглядит красиво
весьма субъективная метрика.
работает стабильно
А насколько хорошо расширяется? Есть ли статистика регрессий в коде?
нет скрытой логики.
Неужели нет ни одной глобальной переменной?
Расширять бизнес-логику приложения, которое не меняется годами — не нужно.
Даже не знаю сочувствовать или завидовать. Что программист-то делать должен с этим приложением? Многолетние баги фиксить? Микрооптимизациями заниматься? На новые версии PHP переводить?
Автор, В 2017 держать под гитом .idea моветон)
Есть мнение что помещать в .gitignore тоже моветон) Нужно в .git/info/exclude. Но это конечно спорно
[core]
excludesfile = ~/.gitexclude
.idea/
являются уровнем инфраструктуры разработки, а не частью проекта.
Принятая/согласованная/утвержденная инфраструктура разработки неотъемлемая часть проекта. Пускай лучше вы лишний раз скачаете не нужные вам файлы, чем 90% команды будут "переводить" стайл-гайд на "язык" настроек продуктов джетбрэйнс, а то и вычислять стайл-гайд по реджектам от хуков.
Принятая/согласованная/утвержденная инфраструктура разработки
90% команды будут «переводить» стайл-гайд на «язык» настроек продуктов джетбрэйнс, а то и вычислять стайл-гайд по реджектам от хуков
./idea в репе — часть этого окружения.
Это если в команде договор использовать продукт от jetbrains. Смысла так сильно ограничивать команду я лично не вижу. А если же у вас не проект а библиотека, то .idea уж точно быть не должно не в репозитории не в .gitignore
Есть мнение, что развёртывание проекта должно производиться одной командой и не должно никак затрагивать другие проекты. Поэтому всякие node_modules и .DS_Store помещают в .gitignore, чтобы ни у кого не было с ними проблем. Всего строчка в .gitignore, а одной головной болью меньше. Будьте прагматичными, а не фанатичными.
.DS_Store лучше в глобальный гитигнор.
К сожалению, не всегда с вашим кодом работают достаточно компетентные разработчики с хорошо настроенной системой и не ленящиеся читать маны. Так что чем меньше будет инструкция по развёртыванию окружения, тем больше вероятность, что она будет исполнена как следует.
Так что чем меньше будет инструкция по развёртыванию окружения
Ну так я и не буду просить разработчика на arch добавлять .DS_Store в глобальный гитигнор. Это его дело. Так что мануал как раз уменьшится, а добавить вообще все что может закоммитить недостаточно компетентный разработчик, это у вас сил не хватит.
А вот когда на ревью придет реквест с закоммиченным .DS_Store разработчику придет вот эта ссылка.
Вы будете писать по мануалу для каждой оси? А на собственно код-то время останется? :-)
Уже есть бойлерплейты для гитигнора со всякой ерундой, которую обычно не надо версионировать.
А для IDEA и ко есть плагинчик, который генерирует гитигнор для всякой ерунды в пару кликов, только выбрать используемую ерунду, начиная с самой IDE :)
Чтобы не тратить каждый раз по 10 минут на объяснение почему и как нужно делать, а потом напоминать, когда у них меняется система.
Лучше делать так, чтобы работа с вашим кодом вызывала как можно меньше трудностей у других людей.
Больше прагматизма, меньше идеологии — рекомендую.
И нет ничего плохого в том, чтобы быть ленивым. Если бы не лень, мы бы до сих пор на ассемблере писали.
Вы будете страдать от лишней строчки в gitignore?
Это был риторический вопрос. И так понятно, то ни у кого никаких страданий по этому поводу не будет. Тоже мне камень преткновения.
ни у кого никаких страданий по этому поводу не будет
Могу лишь позавидовать тому, как удалась ваша жизнь, раз страдаете от такой ерунды :-)
Я немного не понимаю вашу позицию… Попробую просумировать
То есть… я пока не понимаю что именно вы предлагаете в контексте этого вопроса.
Мой же вариант — не делать ни того ни того. У всех моих разработчиков настроен глобальный гитигнор. Если мне приходят PR в github и там закоммичено что-то что не должно коммититься — он получит ссылку на доку про глобальный гитигнор и настроит его себе либо удалит файлы из коммитов.
Эффортов — ноль (ну или почти ноль), гитигнор чистый и там только то что относится к проекту, не надо писать километровые доки (они уже написаны).
Цели в проекте .gitignore и git в целом определяет руководство проекта, а не разработчики git. Есть хороша известная возможность у инструмента "из коробки", хорошо подходящая к задачам проекта. Почему бы её не использовать, а не искать другие инструменты или другие возможности у имеющихся? Вот вы страдаете от .idea в игноре, а я страдаю от неё в проекте. Какой ещё способ можете предложить, чтобы новый разработчик случайно не закоммитил каталог .idea? Крайне желательное требование — способ должен быть неотрывно связан с репозиторием.
Цели в проекте .gitignore и git в целом определяет руководство проекта, а не разработчики git
Почему бы её не использовать, а не искать другие инструменты или другие возможности у имеющихся? Вот вы страдаете от .idea в игноре, а я страдаю от неё в проекте. Какой ещё способ можете предложить, чтобы новый разработчик случайно не закоммитил каталог .idea?
Крайне желательное требование — способ должен быть неотрывно связан с репозиторием
Уже есть бойлерплейты для гитигнора со всякой ерундой, которую обычно не надо версионировать.
А вы предлагаете сразу для всех осей и IDE запихнуть в gitignore?
я указал ссылку где есть ссылки на бойлерплейты и описание что зачем и куда) Как по мне ссылки на этот док достаточно.
Всё, что актуально для проекта.
По вашей ссылке много чего предлагают в игнор засунуть, не всё это в конкретном проекте должно игнорироваться. Например, в каком-нибудь проекте *.sql могут быть необходимы. Человек скопипастит этот бойлерплейт и огребёт проблем на ровном месте. Всё же мейнтейнеру виднее какие файлы в проекте нужны, а какие — нет.
workspace.xml точно моветон, остальное — дело вкуса и соглашений в команде
Простите за оффтоп, но как же раздражают многочисленные "в 2017 году". Т.е. в 2016 можно было говнокодить по страшному и резко, меньше чем за 2 месяца все прозрели и стали писать абсолютно по другому?
Я надеюсь, вы не используете готовые высокоуровневые языки, которые сводят на нет суть программирования? Только машинный код?
А я верю Falseclock, приходилось несколько лет назад искать 1С-программиста… у них от словосочетания "HTTP-запрос" нервный тик начинается… и про то, что данные можно передавать не только через расшаренные XML-файлы, они даже слышать не хотят. Возможно есть исключения, но вживую не приходилось встречать.
Если брать в пример использование PHP как основного языка для веб приложений, то за последние годы мы пришли к тому, что это программисты это те
[...]
приходилось несколько лет назад искать 1С-программиста
Хм.
Вы невнимательно прочитали комментарий Falseclock… Цитирую:
Типичный пример. Мне надо было сделать интеграцию самописной CRM системой с 1С по REST\OData через HTTP-сервис, который появился недавно в платформе 1С.
…
Две недели упорного труда и сам реализовал то что мне нужно не имея никакого опыта программирования в 1С.
Я понял его мысль так, что бездумное использование CMS/CMF может довести уровень среднестатистического PHP-шника до уровня среднестатистического 1C-ника. Типа делай как в туториале и ни шагу в сторону.
Ну так, хотя бы помните, что это можно сделать… значит доку нагуглите за пару минут )
fetch('/api/endpont')
.then(response => response.json())
.then(json => console.log(json))This is an experimental technology
И эти люди говорят нам про фреймворки.
Читаем дальше
Because this technology's specification has not stabilized, check the compatibility table for usage in various browsers.
Поддерживается везде, кроме IE (в Edge уже есть). Достаточно, для того чтобы хотя бы попробовать
Понятно, намек на XHR прошел мимо.
Ага, а потом нам требуется прогресс download/upload и fetch отправляется мусорку.
… полифилл самому написать или готовый взять?
Не надо, как и уже устаревшие "обещания". Сейчас в тренде реактивное программирование.
мне казалось async/await, frp это весело и прикольно и в большинстве случаев не нужно.
Да и как вы там говорили, не всегда компетентные разработчики достаются которые знают что такое frp и как его готовить.
Я ничего не говорил про FRP. OORP готовить настолько просто, что с этим справится даже джуниор. А вот async/await, frp — лишние сложности на ровном месте.
async/await сложности? Их умеет любой джуниор дотнетчик
По сравнению с их отсутствием — да, сложности.
колбэк хелл проще?
Нет, проще — синхронный код.
Писать проще, да, особенно однопоточный без всякой конкурентности за ресурсы. Но вот нефункциональным требованиям такой код часто не соответствует. А то и функциональным.
async/await как раз способ сочетать простоту написания синхронного кода с реальной асинхронностью.
Реально синхронный, но неблокирующий код с автоматическим распараллеливанием.
async-await всё же не обеспечивает распараллеливание — нужно позаботиться об этом самостоятельно.
const responses = await multipleRequests
.map(request => this.preformRequest(request));Вы забыли завернуть это в Promise.all. О чём и речь.
Другой момент — вам нужно собрать все промисы в одну точку, иначе распараллеливания сделать не получится.
Вы забыли завернуть это в Promise.all. О чём и речь.
признаю, есть такой момент.
Другой момент — вам нужно собрать все промисы в одну точку, иначе распараллеливания сделать не получится.
А в вашем случае разве не происходит примерно такого же? Ну то есть вам же как-то надо приостановить выполнение кода, как это у вас происходит?
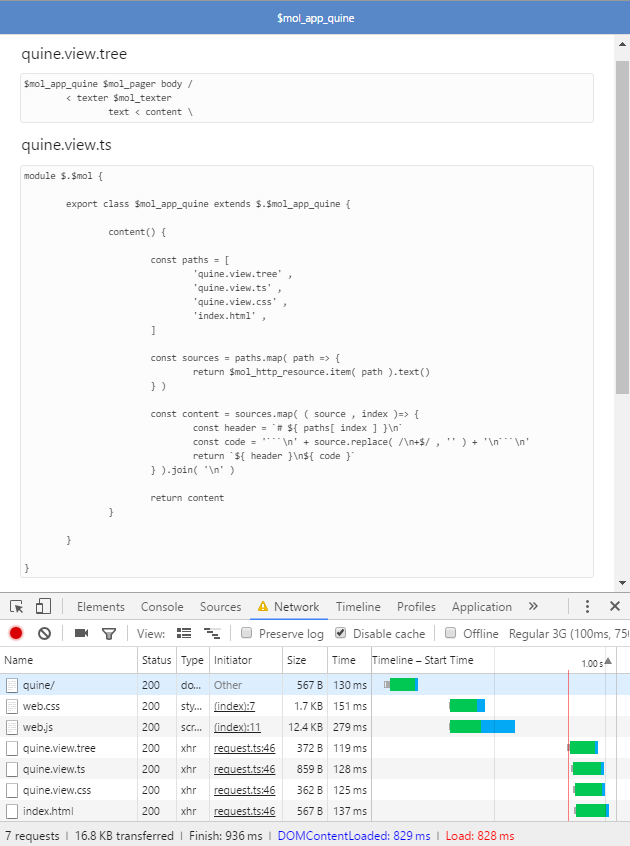
В том-то и дело, что нет. То же самое можно было бы переписать так:
@ $mol_mem()
header() {
return $mol_locale.text( this.toString() + '.header()' )
// там где-то в глубине дёргается файл с локализованными текстами на нужном языке.
}
@ $mol_mem()
sources() {
const treeContent = $mol_file.relative( 'quine.view.tree' ).content()
const tsContent = $mol_file.relative( 'quine.view.ts' ).content()
return `${ treeContent }\n\n${ tsContent }`
}
@ $mol_mem()
content() {
const header = this.header()
const sources = this.sources()
return `# ${ header }\n\n${ sources }`
}И все 3 файла будут загружены параллельно.
Приостановка делается просто — кидается исключение. $mol_mem() заворачивает метод в атом, который это исключение ловит, а наружу светит Proxy, который кидает это исключение лишь при попытке доступа к содержимому результата. Таким образом исполнение продолжается, но в момент, когда мы начинаем работать с результатом, исполнение метода прерывается, если результат ещё не получен.
Где вы находили эти сотни программистов которые не умеют работать с REST
Вот у меня специфика работы — апишки. И я на собеседованиях обычно не особо спрашиваю про rest просто по одной простой причине — 9/10 обычно начинают про http рассказывать. И для меня разработчик уже неплохо шарит в теме если говорит что оба POST и PUT могут быть использованы как для создания ресурсов так и для их обновления. Да что там, уже хорошо если аббревиатуру REST смогут расшифровать и рассказать как они это все дело понимают (не важно правильно или нет).
То что люди не знают про OData например это меня ничуть не удивляет.
Если брать в пример использование PHP как основного языка для веб приложений, то за последние годы мы пришли к тому, что это программисты это те, кто умеет настраивать CMS и сайт готов, позиционируя себя опытным разработчиком.
Программист — это тот, кто решает задачу заказчика с необходимым качеством (и прочими критериями выполнения). CMS, фреймворк — это не имеет значения.
А уж кто как себя позиционирует — так это личное дело каждого.
решать задачи не прибегая к готовым решениям — другое. Это и есть путь нормального эволюционного процесса хорошего программиста.
Так зачем же вы используете "готовое решение" PHP и "готовое решение" OData? Это совсем не путь нормального эволюционного процесса. Пишите свой язык, делайте свой протокол.
Вы уже разобрались, как работает интерпретатор PHP? До какого уровня вниз?
А вы когда новичком были, у вас не возникало вопросов, ответы на которые сейчас показались бы очевидными?
Приведу интересное наблюдение, суть которого заключается в том что отладчики плохо влияют на код.
Когда мы пишем код и что-то работает не так, у нас есть два варианта:
Второй подход машинальный, он зачастую не подразумевает глубокого анализа происходящего. Мы концентрируемся на одной строчке кода и состоянии в рантайме, не особо понимая как так вышло что оно такое как есть. Это не требует больших умственных усилий и устранив проблему мы просто идем дальше.
С другой стороны первый подход будет позволять разработчику думать над тем что он написал, а если так делать часто, то можно быстро приучить себя писать относительно читабельный код, проникнуться важностью изоляции состояния и минимизации сайд эффектов. Не говоря о том что мы будем вынуждены делать более качественную декомпозицию чтобы не сойти с ума.
То есть, с одной стороны дебагер штука полезная, и без нее никуда, с другой стороны в любой непонятной ситуации сразу ставить бряку приводит нас к менее читабельному/поддерживаемому коду.
Это же наблюдение можно спроецировать и на фокусировку внимания на фреймворках а не на принципах лежащих в их основе, и на то что сегодня разработчики чаще сразу лезут на тостеры вместо того чтобы попытаться разобраться в проблеме самостоятельно.
Можно, и более того — так оно и есть. Есть даже шутка — автокомплит это замечательная вещь которая позволяет создавать вещи вроде AbstractSomethingFactoryFactory. То есть возможность пользоваться оной плохо сказывается на необходимости думать над именованием и интерфейсами.
Но это не является причиной НЕ использовать IDE или автокомплит. Просто надо думать что делаешь.
Как без дебаггера вы найдете ошибку в написании алгоритма?
решать задачи не прибегая к готовым решениям — другое
composer create-project github.com/tiny-skeleton /var/www/prototype
Немного некорректный пример. Фреймворки для PHP написаны на PHP. Высокоуровневые языки написаны по большей части на низкоуровневых.
И что? Почему фреймворки сводят на нет всю суть программирования, а высокоуровневые языки — нет?
Высокоуровневые языки избавляют нас от необходимости прямой манипуляции низкоуровневыми абстракциями типа адресов и ячеек памяти, фреймворки избавляют нас от необходимости манипулировать высокоуровневыми абстракциями типа текстов HTTP или SQL запросов, сводя их к абстракциями ещё более высокого уровня.
Высокоуровневые языки избавляют нас от необходимости писать на асм. Симфони и Ларавел вас от PHP не избавят.
И как это связано с "сутью программирования"?
del
«Hello, (real) world!» на php в 2017 году
JavaScript и его многочисленные друзья
плохой при этом PHP
Если бы докер сделал легкий доступ из контейнера к локалхосту
А зачем и чем он сложен? Если надо по быстрому например поднять базу данных на локалхосте (например тесты погонять)
docker run --rm -d -p 5432:5432 --name tests-db postgresИ вуаля. У нас поднята база на локалхосте.
psql -h localhost -u postgreДругого вида доступов и не нужно особо. В этом же смысл изоляции.
Обычному разработчику изоляция как таковая от докера не нужна, а вот доступы нужны.
/**
* @Route("/greetings/{id}")
* @ToJsonResponse()
*/
public function greetings($id)
{
$greeting = $this->getDoctrine()->getRepository("AppBundle:Greeting")->find($id);
return ['greeting' => $greeting->getGreeting()];
}
{
message : 'Exception message'
}
Php-программист в 2017 году не может обойтись без js и верстки
Почти 20 лет пишу на PHP и редко когда было что JS и вёрстка меня вообще не касалась. Даже когда в команде есть отдельные фронтендеры, то "почему-то" меня ставят лидом команды и я принимаю их задачи.
Это не смежные области?
нет, это все бэкэнд и чуть-чуть ops. Очень тесно переплетенные темы.
Ну неинтересен мне JS и фронт, не люблю я их — что же делать-то?
Не могу сказать что фронтэнд это интересно. В подавляющем большинстве случаев это просто верстка и компоновка элементов UI. Да, случается когда надо нетривиальную логику на клиент тянуть но на сервере этого добра больше обычно (покрайнемере сейчас).
С другой стороны как по мне любой уважающий себя бэкэндер должен хорошо представлять как пользуются бэкэндом клиенты и взглянуть на свои проблемы с этой стороны. К примеру… пишем мы микросервисы, пафосные такие, тыкаем в людей пальцами если у них хотя бы два микросервиса шарят между собой одну базу данных или имеют огрехи в изоляции… и при этом всем этим раем бэкэндщика пользуется монолитное мобильное приложение… которому еще и по 10 запросов надо сделать что бы данные из всех микросервисов достать… грустно наверное...
Anton Merge branch 'master' of github.com:anton-okolelov/helloworldphp
Далее не читал, но осуждаю.
Вот более правильные версии хеловорлда ))
https://github.com/DQNEO/php-HelloWorldEnterpriseEdition
https://gist.github.com/lolzballs/2152bc0f31ee0286b722
Речь идет о слепленной из говна и палок поддержке несуществующих в PHP аннотаций?
Ваше дело использовать их или нет. У нас частичный запрет — нельзя использовать в модели, можно в контроллерах и сервисах приложения.
Или о маниакальном фетише DI, благодаря которому чужой код превращается в нечитаемое месиво настолько, что приходится обвешиваться анализаторами XML и YAML барахла в многочисленных васяно-бандлах.
Ваше дело ставить васяно-бандлы или нет.
Starting a basic website in 2014:
1. Install Node
2. Install Bower
3. Pick CSS framework
4. Pick responsive approach
…
47. Write some HTML
— I Am Devloper (@iamdevloper) October 2, 2014
Я вообще ставлю Node.js между фронтендом на React и Symfony.
backend/
config/
vendor/
templates/
Как хотите так и складываете. Не нравится стандартное размещение файлов в Symfony — переопределяется лёгким движением руки.
Зачем на это тратить время ?
Что-нибудь слышали про KISS?
function if_foo takes string returns boolean
проверка
endfunction
function then_foo takes function returns nothing
тогда
endfunction
function else_foo takes function returns nothing
иначе
endfunction
То есть вы берете симфони (далеко не самый простой и дружелюбный фреймворк), в довесок к нему берете реакт (тоже не самый очевидный и дружелюбный фреймворк), обмазываетесь тайпскриптом, делаете на этом всем hello world и удивляетесь, что у вас куча оверхеда?
Конечно, если вам нужно что-то маленькое, то можно либо взять маленький фреймворк, либо быстро состряпать из готовых компонентов свой, взять тот же fastroute и вот приложенька с API готова.
А если приложение ваше будет большим, то и симфони не будет таким монстром на его фоне, а скорее всего упростит жизнь.
Тут как всегда просится уже набившая оскомину фраза "для каждой задачи свой инструмент".
Причём для реакта берётся далеко не самая стандартная обвязка, да и для симфони многое пишется руками из того, что автоматизировано либо в symfony, либо в bin/console, а про create-react-app не слышали.
А на самом деле при должном опыте подобный (не такой же) скелет разворачивается за полчаса максимум.
Вот тут вы не правы на 100500%. Typescript в мире javascript — это как бриллиант в куче г. Строгая типизация, interface и т.д. Особенно для реакта помогает. Когда задаешь interface для props, то тебе IDE не дает ошибиться
при использовании этого react-компонента. Без интерфейсов вообще сложно строить ООП.
При этом никакого особого оверхеда по сути нет, так как все равно обмазываться webpack-ом приходится и его конфигами.
Вы описываете плюсы статической типизации, но для JS она не ограничивается Typescript, притом что Typescript требует именно полноценного компилятора, а другие типа Flow требуют, максимум, простого плагина к babel, а то и просто типі в комментариях указіваются.
Обвязка — это redux, вы имеете в виду? Тут да, возможно надо было бы что-то попроще взять. Без чистых функций и т.д. Но redux интересен лично мне, кроме того, я знаю пару крупных контор, котрые его используют в продакшене и радуются. Поэтому решил взять его.
Не только, но и его тоже. Но поскольку мы говорим прежде всего о пхп-разработчике, то редакс для него библиотека с соверешнно чуждой парадигмой. Хранить стейт в умных компонентах или использовать ООП-"сторы" типа MobX куда ближе к PHP и Symfony.
Создание сущности по таблице? Ну да, но там сущность на несколько строк, разницы особо нет
Создание таблицы по сущности
не слышал, посмотрю
обязательно посмотрите
Typescript требует именно полноценного компилятора, а другие типа Flow требуют, максимум, простого плагина к babel
Вы так говорите будто полноценное хуже неполноценного.
Вы так говорите будто полноценное хуже неполноценного.
вы извращаете слова, никто не говорил про "неполноценные" компиляторы.
В целом если вы завязали проект на TypeScript вы от него никуда не денетесь. Это своего рода вендор-лок, пусть я и не думаю что это очень плохо в данном случае. С Flow все намного более демократично.
С точки зрения управления проектом, компилятор — новый тип сущности, вводимый в процесс сборки, а плагин к бабел — ещё один экземпляр существующего типа. И вообще можно обойтись без него, описывая типы в комментариях на манер jsdoc
Сам babel — лишняя сущность при использовании ts.
jsdoc крайне скупо описывает семантику и её крайне плохо понимают ide.
Почему лишняя? Тайпскрипт умеет импортировать в Джс например цсс-файлы? тайскрипт умеет компилировать в ES5+/ES2015-, то есть для браузеров, которые, скажем, 80% фич ES2015 умеют, а 20 нет? Когда в последний раз крутил, то выбор таргетов был строго ограничен и пришлось выбрать ES2015 и оставшиеся 20% компилить бабелем. Альтернатива — таргет ES5 совсем не радовала.
Я про флоу типы в комментариях, а не в коде на манер тс.
Тайпскрипт умеет импортировать в Джс например цсс-файлы?
И зачем заниматься такими извращениями?
тайскрипт умеет компилировать в ES5+/ES2015-, то есть для браузеров, которые, скажем, 80% фич ES2015 умеют, а 20 нет?
Конечно. Если вы про генераторы, то нет, такой говнокод он не генерирует.
Про модульность не слышали? Про изоляцию CSS компонента от окружения?
Specify ECMAScript target version: "ES3" (default), "ES5", "ES6"/"ES2015", "ES2016", "ES2017" or "ESNext".
Переходных вариантов нет, ориентирован на стандарты, а не реальную жизнь. Или отсекай больше пользователей, чем рассчитывал, или грузи большинству кучу ненужного ему кода.
Про модульность не слышали? Про изоляцию CSS компонента от окружения?
Для этого не нужно вкомпиливать стили в скрипты. Впрочем, я сторонник более наглядного БЭМ. Фанатичная изоляция особой пользы не приносит.
Или отсекай больше пользователей, чем рассчитывал, или грузи большинству кучу ненужного ему кода.
Или не используй модные фичи сомнительной ценности.
Не нужно, но это удобно. Сразу видно какие стили применяются к компоненту, а сами файлы стилей не загромождаются бесконечными конструкциями во избежание конфликтов.
"модные фичи сомнительной ценности" как-то слабо применимо к фичам, включенным в стандарт языка и уже поддерживаемым последними стабильными версиями сколь-нибудь популярных браузеров. Просто не все обновляются.
Не нужно, но это удобно
Совершенно не удобно. Сорсмапы — штуки до сих пор не надёжные. А для уникальности генерируются имена с хешами. БЭМ же нужен не только для решения конфликтов, но и для понимания что к чему относится.
"модные фичи сомнительной ценности" как-то слабо применимо к фичам, включенным в стандарт языка
То, что они включены в стандарт языка — лишь дань моде. Префиксы в css, Object.observe, application cache — тоже были стандартами и где они теперь?
Если вы пишете вручную «echo 'hello, world'», то обрекаете проект на говнокод на веки вечные (кто потом этот велосипед за вас переписывать будет?).
Тут не нужен даже php)
echo "Hello, World!" > /web/server/static/path/index.htmlИ все)
Я конечно понимаю, что болт забитый молотком держится лучше чем гвоздь завернутый гаечным ключом…
Да ладно? Для визиток и интернет-магазинов как раз фреймворк не нужен, нужна CMS, а то и вообще генератор статики.
А вот для сервисов и нестандартных проектов фреймворки очень помогают работать именно над нестандартной частью, не тратя время на всякие роутинги и маппинги базы данных (из поста именно они использованы).
Если же приходится писать сервис или нестандартный проект какой
то сразу находится миллион стандартных задач:
Ну то есть вся инфраструктура проекта. Можно брать full-stack фреймворки или микрофреймворки и дополнять компонентами по вкусу… Порой приходится дописывать что-то свое когда "жмет". Бизнес логика же обычно не должна зависеть от подобных вещей. Кучи принципов и правил не просто так понапридумывали.
Было решено взять фалкон
Так что пишут сейчас без фреймворков.
Простите, но я вижу тут несоответствие. То что у вас выходит некий микрофреймворк — это не значит что его нет. Более того, вы на основе готовых компонентов выстроили свой фреймворк. Вот и все. Ну то есть все как у всех. Просто у вас более узкоспециализированный и вы знаете что делаете.
Если вы действительно настолько индокринированы и реально подходите к проектированию и работе так, как описано в статье, мой вам совет: оставьте это ремесло, программирование не для вас.
Процентов 80 новых проектов я начинаю с подобных шагов: поднять базу постгрес, развернуть симфони с доктриной для бэка и вебпак с реактом для фронта. Полчаса максимум. И начинаю проектировать и программировать бизнес-логику и интерфейсы, не отвлекаясь на алгоритмы Кнута для валидации формочек, роутинга и маппинга объектной модели на базу данных.
Получилась статья о том, что современные инструменты веб-разработки не заточены для написания хелловорлдов.
Замечательно! Продолжайте в том же духе. Ждем разоблачений про использование современных Java IDE для ведения заметок, или про видеоконференции по электронной почте.
Изучение пхп следует начать с:
В современных фреймворках куча всего лишнего, всевозможные хелперы, обработчики, орм. Кому они нужны, если отдача простой статической страницы на таком фреймворках занимает 70мс? (тестил на локалке, Yii2).
Doctrine бесполезен в 95% случаях. Куча предобработки в запросах и ради чего? Потому что, возможно, в будущем я перенесу проект на другую SQL бд. Этого не случится в 95%ах случаев. А если и перейдете то далеко не факт что это будет sql поддерживающая бд.
Я поднял свой mvc движок, для своего маленького проекта. И страница отдается за 30мс без запросов к бд. При этом там есть нормальный роутинг, актив рекорд, автолоад классов и удобная подрубка сторонних библиотек.
Фреймворки в большинстве случаев слишком универсальны. За что вы платитесь производительностью
Изучение пхп следует начать с:
а как по мне когда люди начинают идти по такому пути, где-то упускаются следующие понятия:
В целом фреймворки или написание своего "движка" тут не помогут от слова совсем.
Куча предобработки в запросах и ради чего? Потому что, возможно, в будущем я перенесу проект на другую SQL бд. Этого не случится в 95%ах случаев.
Давайте немного поговорим о "смене БД". Это дурацкий пример, полностью согласен. Если у нас на проекте была выбрана MySQL то мы от нее вряд-ли сможем далеко убежать. Более того, делать совсем без SQL не выйдет в большинстве задач. Рано или поздно появляется native sql для того что бы максимально эффективно использовать выбранную СУБД.
НО! Вместо смены СУБД на всем проекте мы всегда можем добавить вторую! Просто потому что можем упереться в лимиты СУБД или просто потому что в другой СУБД что-то есть из коробки. Тут уже ORM или любые абстракции от хранилища (DAO вам должно понравится судя по всему) сильно экономят время.
В целом достаточно просто что бы SQL не был размазан по всему проекту и лежал изолированно где-то. А как вы это делаете — это уже детали. Например любители доктрины часто размазывают DQL по всему проекту или EntityManager юзают не только там где надо но вообще везде. Это тоже плохо и противоречит идеи Doctrine.
Я поднял свой mvc движок, для своего маленького проекта. И страница отдается за 30мс без запросов к бд.
Symfony3 + Doctrine 2.5 + выборка из базы = 20ms. Что я делаю не так? Скорость ответов важна, но это лишь значит что мы берем что-то медленное и стандартное а потом оптимизируем узкие места. То есть мы экономим 5x на времени разработки (чтобы вы понимали, во фреймворках покрыты многие кейсы о которых вы даже думать не будете, но если будете вам придется все это реализовать самостоятельно), и потом оптимизируем только то что медленно работает. Например в случае доктрины можно гидрацию данных оптимизировать или на SQL.
А вот уже когда у разработчика достаточно опыта, и он знает хотя бы парочку фреймворков и что там для чего, вот тогда можно лепить свои фреймворки оптимизированные исключительно под проекты которые он делает.
Проблема с фреймворками и разработчиками в основном заключается в том, что большинство даже не пытается разбираться "а зачем там что и как работает".
30мс — это тоже у меня на локалке. Я думал будет понятно, простите.
Если говорить о проектировании систем то лучше уж почитать Фаулера.
И мне кажется добавление еще одной бд входит в эти 5%. В Doctrine я и в правду не захотел разбираться, как и в симфони. Из коробки симфони у меня на локалке отдает страницу за 200мс, кажется это был второй симфони. После я естественно начал гуглить оптимизацию производительности. Понял что там предстоит нешуточная работа и бросил все это дело.
30мс — это тоже у меня на локалке.
ну и у меня на локалке. Просто я повыпиливал все что не нужно юзать. Ну и запускается это все в продакшен окружении с настроенными кэшами.
Если говорить о проектировании систем то лучше уж почитать Фаулера.
Фаулера почитать стоит конечно, а еще Роберта Мартина, Кента Бэка, Алестера Коберна и других хороших людей. Но их почему-то не читают. Ну и опять же на каком этапе читать то из тех что вы озвучили?
И мне кажется добавление еще одной бд входит в эти 5%.
Повторюсь — "абстракция от базы данных" это не для смены оной, а что бы игнорировать наличие оной когда вы бизнес логику описываете. Это не значит что вы не можете делать все через plain sql, просто все операции с базой должны быть изолированы в отдельных штуках. ORM аля Doctrine просто предоставляет вам один из способов делать это быстро и удобно. Ну то есть в большинстве случаев вы не будете проектировать схему базы данных, вы будете работать только с объектной моделью. То что этот инструмент несет в себе высокий уровень скрытой сложности — это да. И авторы к третьей версии собираются выпилить весь "сомнительный" функционал который позволял делать стремные вещи.
Повторюсь — «абстракция от базы данных» это не для смены оной, а что бы игнорировать наличие оной когда вы бизнес логику описываете
Ну ладно… у каждого свое видение одного и того же
Я пока плохо представляю ваш вижен. Давайте на каком-нибудь маломальски простом примере:
Есть например у нас необходимость давать пользователю скидку, если он накупил товаров за календарный месяц на >$100. Можете описать как бы вы делали, куда ложили бы sql, как выглядел бы код?
p.s. Специально выбирал примеры для которых ORM плохо подходит. Мне интересно именно как вы сделали бы подобное в вашем случае. Куда бы положили эту проверку, делили бы как-то и т.д. Где был бы SQL.
class User extends \app\system\model\ActiveRecord
{
public function haveDiscount()
{
return 100 < Util::getTransactionHistorySumByPeriod($this->id, strtotime('-1month'));
}
...
}
...
class Util
{
public static function getTransactionHistorySumByPeriod($iId, $iStart, $iEnd = null)
{
$sEnd = $iEnd === null ? date('d-m-Y H:i:s') : date('d-m-Y H:i:s', $iEnd);
$sStart = date('d-m-Y H:i:s', $iStart);
return \app\system\Registry::get('db')->add('SELECT SUM(value) AS total')
->add('FROM transactions')
->add('WHERE "id" = :id AND "created_at" > :start AND "created_at < :end')
->execute([':id' => $iId, ':start' => $sStart, ':end' => $sEnd])->fetch('total');
}
}
У вас всё таки есть слой, изолирующий бизнес-логику от хранилища, назвали вы его правда Util, но суть не меняется — даже если заменить SQL базу на NoSQL, а то и вообще на облачное хранилище с ptotobuf интерфейсом, то ничего в классе User не поменяется, только в слое Util нужно будет что-то менять.
Другое дело, что если нужно будет вывести список всех клиентов с пометкой есть ли у них право на скидку, то или получим ситуацию 1+N запросов, или нужно будет писать ещё один метод в слое изоляции.
Вот если вы переименуете Util в TransactionHistoryDao какой-нибудь, или просто TransactionHistory будет то же что и у меня в проектах с доктриной а не "еще одной реализацией AR". Ну и логику тогда можно было бы ложить в сущности.
Я не зря написал что описанная мной задача решается с ORM плохо, просто потому что задача выходит за пределы OLTP (Online-Transaction Processing).
Как по мне, то это самый нужный слой в сколь-нибудь серьёзном приложении. А так-то, да, можно SQL-запросы в PHP-шаблоны складывать.
Doctrine бесполезен в 95% случаях.
актив рекорд
То есть вам не понравилась Doctrine и вы изобрели свою ORM?
В современных фреймворках куча всего лишнего
автолоад классов и удобная подрубка сторонних библиотек
return json_encode(...) А статус ответа, а заголовки? Да банальный 'application/json', его как возвращать? Ну и унификация: JsonResponse — частный случай Response, какой-нибудь миддлваре всё равно какой из Response вернули, допишет свой заголовок, а какая-то только к JsonResponse что-то допишет или наоборот удалит что-то.
OOP — средство уменьшения сложности. Не бесплатное, да.
А зачем нужны 5 классов «встроенного autoload» если в конце он все равно вызывается spl_autoload_register?
Давайте рассуждать. У нас есть spl_autoload_register который позволяет нам сделать цепочки автозагрузчиков. Почему нам важны цепочки? Потому что разные модули нашего проекта, не важно наши они или third-party, могут иметь свои правила автозагрузки (например у вас есть старый модуль из эпохи php5.0 бэз нэймспейсов и новый красивый из эпохи 7.0). Это упрощает использование модулей. Мы просто подключаем автозагрузчик модуля и "едем дальше" вместо того что бы каждый раз вкручивать его в проект.
Далее, почему писать свой автозагрузчик плохая идея в большинстве случаев. Что мы можем написать сами за 1 минуту? Скорее всего это будет тупая функция которая тупо по имени класса будет импортировать какой-то файл.
Что мы можем сделать с composer за одну минуту. Описать PSR-4 автозагрузку или прописать инклуды, и вызвать команду composer dump --optimize --no-dev --classmap-authoritative. Что дает нам эта команда:
--optimize и --classmap-authoritative позволит нам составить классмэп (какой класс в каком файле искать), что бы не нужно было вычислять это каждый раз и трогать лишний раз файловую систему. Максимально эффективный способ.--no-dev выкинет все зависимости которые нам требуются для разработки (phpunit например или тэсты) из мэпы классов.И все это вы получаете… просто так из коробки. Подходит как для маленьких так и для больших проектов. Эфортов разработчика — минимум. Так почему бы не юзать?
Но в чем круть от писанины автора: «return new JsonResponse(...)», вместо return json_encode(...) ?!
скорее вместо:
header('Content-Type: application/json');
echo json_encode($data, JSON_HEX_TAG | JSON_HEX_APOS | JSON_HEX_AMP | JSON_HEX_QUOT);
fastcgi_finish_request();Раз уж вы о производительности заботитесь. Что будет быстрее, записать в поток 2 раза по 100 байт или 1 раз 200? И сколько это по времени если сравнивать с инстанцированием объектов?
ну и опять же, JsonResponse хэндлит еще и варианты для jsonp (вдруг кто-то тут еще под ie6 пишет), что руками делать уже ой как не удобно.
А если этот никчемный класс (JsonResponse) порождается 100 раз в секунду?
разница между простым вызовом json_encode будет ажно целый порядок, 10^-4 ms vs 10^-5 ms. Экономия на спичках.
ЗЫ. Давайте не забывать, что PHP — язык рожденный умирать! А OOP — это всегда медленно…
рожденный ползать летать не может? С тех пор как PHP родился его нутро пару раз переписывали уже. В данный момент он вполне себе может не умирать. Да, пока плохо с инфраструктурой, но если у нас например запросы на чтение (а их обычно большинство), выборки какие-нибудь, можно взять react или php-pm и радоваться жизни.
Некоторые для этих целей берут nodejs например (то есть запись происходит в php, там формируется набор событий. строится проекция на какую-нибудь монгу или эластику, а node через graphql отдает данные).
А OOP — это всегда медленно…
Не совсем так. Медленно — динамическая диспетчеризация, когда вам надо в рантайме соответствия искать кто кого вызывает. Эти вещи решаются различными инлайн кэшами на уровне интерпретатора (JIT, который обещают впилить в php8, вполне способен на подобные оптимизации). А все остальное — не отличается по производительности.
А хайлоад… это надо быть в top 100 по нагрузкам ресурсов что бы "ООП" стало узким местом. Намнооого чаще узким местом становится кривая архитектура.
рожденный ползать летать не может?
задумывался
Это вы правильно прошедшее время написали, сейчас PHP — язык общего назначения, на котором в том числе пишут и демонов и не только для веба. На уровне языка ничего принципиально отличного от других подобных языков нет. Про экосистему (фреймворки, библиотеки) можно поговорить, но вот язык сам уже не мешает.
А OOP — это всегда медленно…
Я боюсь, что StackOverflow с вами не согласится.
С другой стороны подобный стэк может быть корпстандартом, на котором по умолчанию начинаются новые проекты без особіх требований. Наш, например, не сильно отличается, из глобального только таблицы ручками не создаём и create-react-app используем для фронта.
SPA всё больше проникает в наш мир, и надо это уметь, хотя бы в общих чертах
То чувство, когда уже 5 лет время от времени пишешь SPA на JS+PHP без всей этой фигни :)
без какой фигни? Без хайпа?
Symfony для одностраничника разворачивать — это как собрать авиационный двигатель, чтоб пыль со шкафа сдуть.
Как минимум это может быть оправдано, если все остальные проекты в компании на Symfony и нет требований к одностраничнику, которые бы конфликтовали с Symfony, ради которых пришлось бы бороться с фреймворком. По вашей аналогии — на заводе авиадвигателей может быть проще собрать авиадвигатель для сдувания пыли, чем создавать отдельную линию для производства двигателей пылесосов :)
«Hello, (real) world!» на php в 2017 году