Добрый день!
Как вы поняли из названия, вас ждет очередная статья про NetFlow, но на этот раз с необычной стороны — со стороны реализации NetFlow сенсора на FPGA.
Введение
Да, на хабре много статей по теме NetFlow: начиная с подробного разбора и HOWTO по настройке, до прикладного применения в отлове вирусной атаки и учете трафика.
Но это статья не о том, как NetFlow пользоваться, она о том, как его реализовать.
Задача создания NetFlow сенсора интересна в том плане, что вам одновременно необходима гибкость, чтобы поддерживать изменяемые в реальном времени шаблоны NetFlow и в то-же время очень высокая производительность, чтобы эффективно обрабатывать трафик и работать с памятью.
Там, где я работаю (я FPGA программист в НТЦ Метротек), мы используем платформы, которые позволяют делать выбор между программными и аппаратными реализациями.
Но в большей части наших задач, программная часть занимается в основном управлением, а основную работу принимает на себя FPGA. Именно поэтому создание NetFlow сенсора, как чего-то более интересного в плане Software Hardware Co-design, показалось нам подходящим поводом поделиться нашей работой с Вами, написав эту статью.
О NetFlow
Чтобы не терять нить повествования и определиться с терминами, расскажу про NetFlow, пусть и очень кратко, потому что эта информация есть везде.
NetFlow это протокол, который придумали Cisco Systems.

Зачем? Чтобы можно было удаленно следить за трафиком в сети.
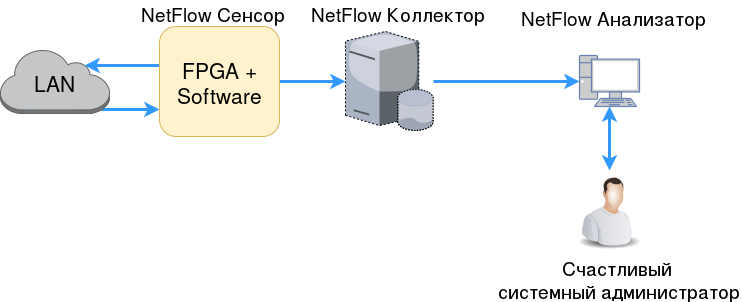
То есть в локальной сети есть некоторый L3-свитч с функцией NetFlow сенсора и где-то в другом месте коллектор, который знает все о том, что в сети происходит.
При этом не должно создаваться лишней нагрузки на сеть данными, которые мы пересылаем в коллектор, то есть простое зеркалирование трафика на анализатор не подходит.
Элементы в NetFlow:
Сенсор (он же Exporter) — устройство, которое собирает информацию о потоках в сети.
Обычно это L3-коммутатор или маршрутизатор, который достаточно редко (обычно раз в секунду) отправляет информацию о потоках в коллектор.
- Коллектор — (обычно) удаленный сервер, который собирает информацию, отправленную сенсором, и хранит её.
Что еще нужно знать про NetFlow:
Export пакеты — это те пакеты, которые отправляет сенсор на коллектор.
В них вся суть NetFlow. Вы, наверное, слышали про то, что NetFlow бывает разных версий — так вот, формат этих export пакетов — главное различие между версиями.
Версии NetFlow: v1, v5, v8, v9. v9 — самая распространённая, остальные или дают ограниченную функциональность (v1, v5), или излишне сложные (v8).
В версии v9 сенсором определяется, какую информацию он может отдать, а коллектор под это подстраивается. Сенсор вместе с данными отправляет шаблон, по которому понятно, как с этими данными работать. Шаблоны очень гибкие. Подробнее можно почитать рекомендацию по NetFlow v9 в RFC 3954.
Есть еще IPFIX — на данный момент функционально тот же NetFlow v9.
Только NetFlow курируется Cisco, а IPFIX стандартизован RFC.
- Поток — как говориться в RFC 3917 п.2.1, это когда у пакетов есть что-то общее.
Для NetFlow v9 принято использовать более строгое определение:
К одному потоку относятся пакеты, со следующими одинаковыми характеристиками:
- IP адрес источника;
- IP адрес получателя;
- TCP/UDP порт источника;
- TCP/UDP порт получателя;
- ICMP код;
- ICMP тип;
- Протокол L4 (поле IP Protocol Number);
- IP ToS;
- Входной интерфейс.
Из этих полей делаем вывод:
- NetFlow учитывает только IP пакеты (в IPFIX это даже в название вынесено);
- ICMP пакеты тоже считаются (в случае ICMP поля портов L4 считаем равными 0);
- Поток — это только в одну сторону (то есть, если есть клиент и сервер, то от клиента к серверу это один поток, обратно — другой);
И не забываем — данное определение потока не задано жестко стандартом. По мере наших нужд можно изменять понятие потока, например сагрегировав потоки по направлениям.
Проектно-изыскательские работы
Теперь, когда про NetFlow все известно, сформулируем ТЗ:
Нужен NetFlow сенсор, такой, чтобы:
- Был готов к большому числу потоков (десятки, сотни тысяч);
- Был готов к большой нагрузке, в идеале line rate на своей платформе (2G/100G);
- Работал без семплинга (когда часть трафика не попадает в статистику).
- Основной платформой для разработки являются умные зонды, например M716, который можно поставить в разрыв сети и так собирать статистику. Но в процессе проектирования стоит учесть и возможность использования в нашем 100G свитче B100;
Целевые платформы обе гетерогенные: CPU + FPGA.
Зонды основаны на Altera SoC (Cyclone V) ARM процессор + небольшая FPGA. Все это на одном кристалле.
В B100 это мощный процессор (Intel Core I7) + большая FPGA (Stratix V). Между ними PCIe.
Поэтому свободы в плане Hardware/Software Co-design у нас много.
Но начнем с объяснения, почему очевидные варианты реализации не подходят.
SW Only
Мы не используем FPGA совсем. Используем программное решение для NetFlow.
Получаем очень большую гибкость, но что с производительностью?
- Прием и обработка входного пакета. Добиться обработки line rate трафика userspace утилитой будет очень тяжело. Даже если бы мы добились от FPGA функционала, соответствующего карточкам от Intel и использовали библиотеки DPDK, добиться скорости сетевого стека, который бы без потерь принимал пакеты на line rate 100G размером 64 байта — почти невозможно, по крайней мере в реальные сроки. Даже на 1G линке на ARM'е возникают очень серьезные вопросы в том, сколько времени уйдет на оптимизацию стека.
- Загрузка процессора. С платформой B100 можно предположить, что решив проблему сетевого стека нам хватит процессорного времени, чтобы еще что-то делать, кроме приема пакетов, но на маленьком ARM'е возникают опасения, вытянет ли система постоянную проверку потоков в памяти, даже без приема пакетов.
Таким образом можно сделать вывод — да, такая реализация возможна, но:
- Если мы говорим о реальных сроках разработки — семплинг входных пакетов неизбежен.
- На SoC платформе встает очень серьезный вопрос про максимальное число потоков, которое мы сможем хранить в памяти, ведь все эти потоки нужно будет постоянно проверять.
- Мы можем в FPGA. Даже если учесть, что программная реализация возможна, вполне очевидно что многие вещи на FPGA будут реализованы в разы эффективнее.
Но кое-что полезное из рассмотрения программной реализации мы все-таки вынесли — проекты в которых можно подсмотреть нюансы реализации NetFlow сенсора:
FPGA only
Теперь перейдем к другой крайности — все на FPGA:
- Прием и обработка входного пакета. Максимальная скорость, line rate и на B100 и на SoC'ах. Цена — время разработки, но мы будем писать это не с нуля — у нас уже много наработок в этой области.
- Загрузка процессора — не актуальна, а число потоков ограничено только размерами памяти. При адекватных числах (1-2 миллиона потоков) мы не упираемся в число чтений которые будут происходить при проверки потоков. Остается проблема интерфейса — пропускная способность которую мы будем делить между добавлением потоков и их проверкой, но мы всегда можем сказать, что проверка — менее приоритетная задача и делать её только тогда, когда не добавляем новый пакет.
Но встает очень важный вопрос насчет гибкости создания NetFlow пакетов.
Вариант 1 — мы отказываемся от возможности изменять шаблоны NetFlow v9. Мы пишем генератор на FPGA, который может отправлять данные только по одному шаблону.
Если мы захотим сменить шаблон — придется переписывать этот FPGA модуль. Такой подход нас не устраивает, потому что разные коллекторы могут по-разному работать с NetFlow и иногда не совсем хорошо воспринимают различные поля: например некоторые поля NetFlow v9 пакета имеют размер, который может быть переопределен шаблоном, но не все коллекторы к этому готовы, они ждут, что это поле будет константного размера.
Вариант 2 — мы реализуем динамическое изменение шаблонов в FPGA. Это возможно, но такой модуль будет занимать очень много ресурсов. Помимо этого его разработка займет очень много времени как на сам модуль, так и на его отладку.
И еще один минус такой реализации: в стандарте говорится, что для транспорта NetFlow export пакетов может быть использован не только UDP, но SCTP. А это значит, что если мы захотим поддержку такой функциональности — мы должны будем реализовать половину сетевого стека на FPGA.
SW + HW
Теперь, когда мы убедились, что только FPGA или только програмные реализации для данной задачи не подходят, перейдем к совместному решению.
Функциональные блоки
Чтобы было удобнее искать решение, сделаем следующее:
- Разбиваем предполагаемую функциональность на функциональные блоки;
- Формируем требования к этим блокам;
- Распределяем, в зависимости от требований, эти блоки на hardware и software реализации.
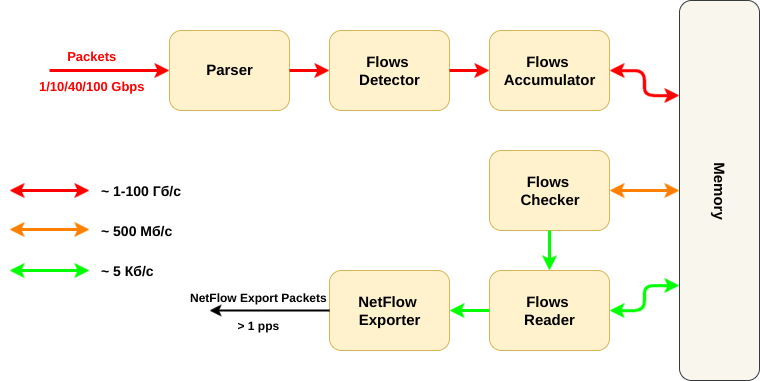
На этой схеме представлены основные функциональные блоки NetFlow сенсора:
- Сначала пакет нужно принять и распарсить (вытащить нужные поля заголовков) (Parser);
- Потом нужно понять, к какому потоку принадлежал пакет (Flow Detector);
- Далее нужно достать из память информацию по этому потоку, обновить её и записать обратно (Flow Accumulator);
- В памяти при этом хранятся поля заголовков пакетов + дополнительная информация (счетчики байт и пакетов потока, таймеры начала и конца потока);
- Вместе с этим работает вторя часть NetFlow — та, которая проверяет, что поток в памяти лежит достаточно долго и его пора вычитывать. То есть потоки из памяти регулярно вычитываются и проверяются (Flow Checker);
- Если поток пора экспортировать — его нужно удалять из памяти и подготовить к отправке (Flow Reader);
- Напоследок нужно сформировать NetFlow Export пакет для коллектор;
Что нам дало такое разбиение:
- Во всей схеме NetFlow сенсора за само "NetFlow" отвечает один блок — формирование пакета.
То есть если этот блок будет гибким, мы можем использовать любые версии NetFlow или даже IPFIX; - Цветом на схеме указана ориентировочная нагрузка на интерфейсы — наш главный критерий выбора SW vs HW;
Теперь, имея в виду эту схемку, перейдем к вариантам:
Вариант 1
Пока мы точно знаем следующее:
- Принимать пакеты, парсить их и добавлять в память мы хотим на FPGA;
- Формировать export пакеты мы хотим программно.
Вся часть аккумуляции от приема пакета до записи в память должна происходить на FPGA.
Предположим, на этом вся работа FPGA заканчивается: память, где хранятся потоки — общая. К ней имеет доступ soft и он сам производит проверку потоков в памяти и их вычитывание.
В этом случае у нас остается проблема большой нагрузки на CPU при большом числе потоков, но и вдобавок к этому, появляется новая проблема — коллизии доступа к памяти: FPGA может захотеть обновить информацию о потоке, который soft собрался вычитывать, в этом случае будет очень просто потерять часть сведений о потоке.
У данной проблемы есть решения, но они потребуют дополнительного усложнения архитектуры.
Вариант 2
Тогда идем чуть дальше — память остается общей, но проверкой потоков занимается FPGA (регулярно вычитывает и проверяет таймеры потоков). Как только поток необходимо экспортировать — FPGA сообщает в soft указатель на этот поток. Нагрузку с CPU мы сняли, но проблема коллизий не решилась.
Вариант 3
Идем еще дальше — когда FPGA вычитало поток из памяти и поняло, что это поток на экспорт — оно само удаляет поток из памяти и отправляет его в soft (используя любой доступный интерфейс).
В таком случае память больше не должна быть общей, коллизии мы можем решать внутри FPGA на этапе разрешения доступа к памяти.
А формированием export пакетов NetFlow занимается программная часть, которая может быть изменена на работу с любым протоколом.
Последний вариант нас нас устроил. Можно переходить к созданию proof of concept на базе SoC платформы.
Реализация
Перед реализацией предъявим к ней некоторые требования:
- Это должна быть IP-core (стандартные интерфейсы, реюзабилити через параметры и т.д.);
- Функциональность должна быть расширяемая — сейчас это PoC, но не хочется тратить много времени на то, что потом не будет использовано.
Все это привело нас к следующей реализации:
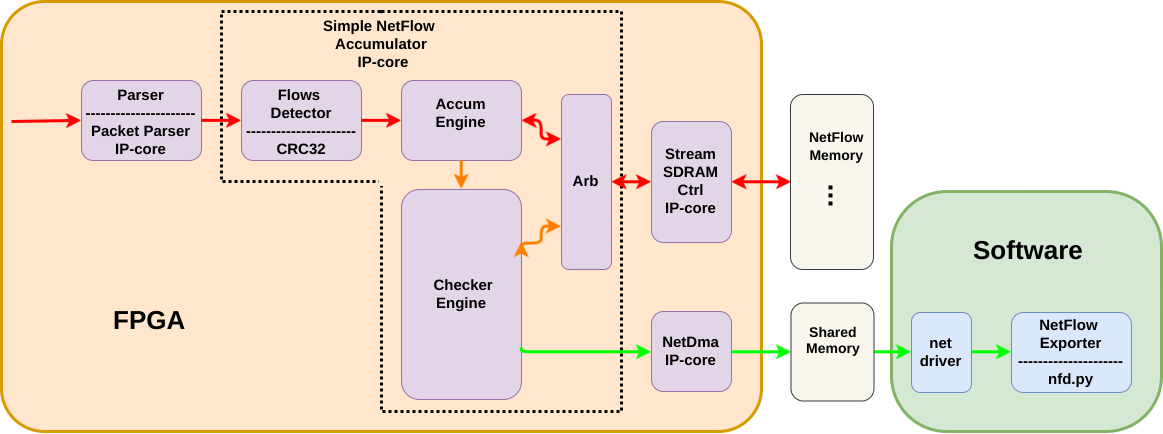
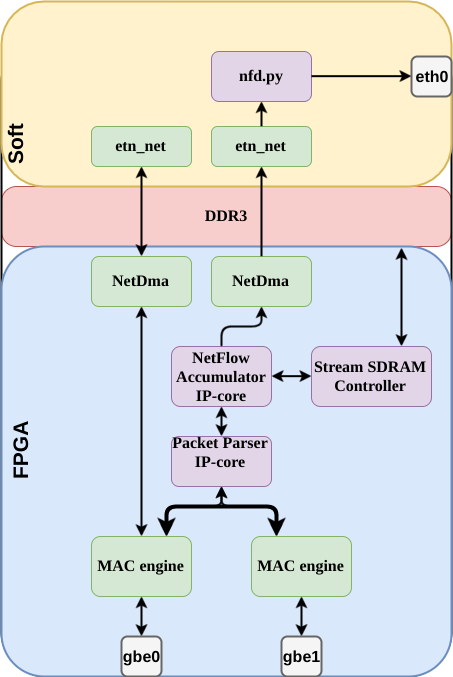
- Parser — наша IP-core, взятая из другого проекта. Она принимает пакетный интерфейс Avalon-ST и достает из пакета нужные поля заголовков.
Avalon Streaming Interface — интерфейс для передачи потоков данных внутри FPGA. Используется в IP-core от Altera. Может быть использован в варианте непрерывного потока данных или пакетной передачи данных (используются сигналы начала/конца пакета). Подробнее можно почитать тут: Avalon Interface Specifications.pdf
NetDMA — тоже наша IP-core — DMA контроллер, который принимает Avalon-ST пакеты и пишет их в память по дескрипторам. Для того, чтобы снабжать этот DMA дескрипторами, у нас уже есть драйвер. Сейчас этот DMA и драйвер используются в нашем сетевом стеке.
Simple NetFlow Accumulator — та самая IP-core NetFlow сенсора. Она занимается детектированием потока. Чтением и обновлением информации в памяти по каждому принятому пакету, постоянной проверкой памяти на наличие потоков на экспорт и арбитражем запросов к памяти при добавлении и проверки.
- Stream SDRAM Ctrl — маленькая IP-core, которая служит для более простого доступа к памяти. Она может читать и писать в память по произвольному сдвигу. Для чтения — принимает сдвиг и число байт и через какое-то время по Avalon-ST отправит поток с данными. Для записи — указываем сдвиг и число байт, a по Avalon-ST шлём данные, которые будут записаны.
Структура хранения данных потоков
Для хранения данных используется самая простая структура — хеш-таблица без механизма решения коллизий.
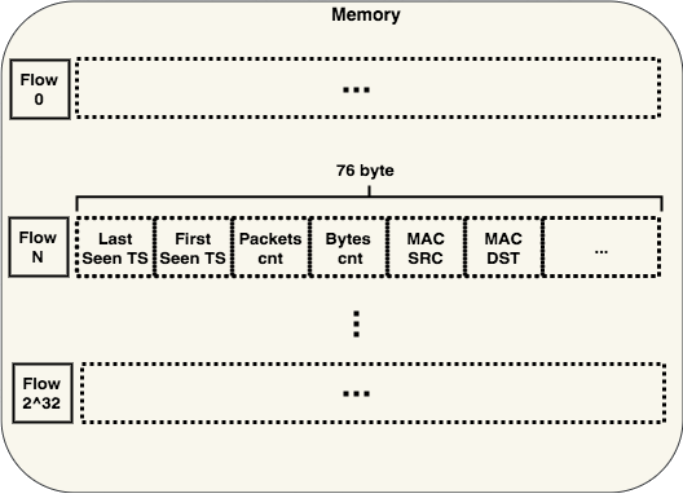
Результат вычисления хэш-функции потока мы рассматриваем как сдвиг в памяти, по которому надо расположить соответственные сведения.
При добавлении нового потока мы считаем от него хеш, вычитываем из памяти по нужному индексу и проверяем, что это действительно он. Если мы ошиблись (случилась коллизия хеш-функции), то заставляем ядро проверки NetFlow вычитать этот поток из памяти. Да, его таймеры еще не истекли и он еще должен бы храниться в памяти, но таков наш самый простой метод борьбы с коллизиями. Минусы такого подхода:
- Мы генерируем бОльшую нагрузку на интерфейс между NetFlow и CPU;
- Мы немного нечестно поступаем относительно того, что ждет от нас коллектор.
Первая проблема решаемая: чем ниже вероятность коллизий, тем меньше возможный всплеск нагрузки.
Вторая проблема может быть решена в программной части, если там будет реализован свой небольшой буфер для хранения таких преждевременных отправок.
Выбираем хеш
В качестве хеш-функции в данный момент используется CRC32 от полинома 0x04C11DB7 (это тот, который используется в Ethernet). Конечно у нас была идея подобрать более интересную хеш-функцию, которая давала бы меньше коллизий. Но моделирование показало, что с CRC32 все в порядке.
Для моделирования мы сделали простейшую хеш таблицу на python, которая содержит  позиций (такой размер показался нам наиболее подходящим для первой реализации, потому на нем и тестируем хеш-функции). То есть от полученного значения хеш-функции используется только 20 бит, чтобы определить позицию в таблице.
позиций (такой размер показался нам наиболее подходящим для первой реализации, потому на нем и тестируем хеш-функции). То есть от полученного значения хеш-функции используется только 20 бит, чтобы определить позицию в таблице.
Мы также написали скрипт-генератор, который создает уникальных слова по 17 байт (именно столько получается данных из полей, уникальных для потока).
Эти данные мы добавляем в нашу таблицу, с разными хеш-функциями:
- CRC32 с полиномом 0x04C11DB7
- CRC32 с полиномом 0xEDB88321
- CRC32 с полиномом 0x82608EDB
- LookUp3
- MurMurHash3
Полиномы CRC32 0xEDB88321 и 0x82608EDB — это преобразования полинома 0x04C11DB7. В одном из прошлых проектов мы использовали такие CRC функции для быстрой генерации большого числа разных хешей. Решили их проверить заодно и здесь.
LookUp3 была выбрана потому, что это функция специально создана для хеш-таблиц и содержит в себе она вполне терпимые для FPGA опрерации — сложение и сдвиг.
MurMurHash3 была выбрана не только из-за классного названия, но и как пример мультипликативной функции, которую будет достаточно дорого реализовывать в FPGA, но которая должна, в теории, дать лучшее заполнение таблицы.
После добавления каждого нового слова в каждую из таблиц мы сохраняли уровень заполненности таблицы, чтобы построить такой график:

Как видно из графика — на наших данных никаких значимых различия нет.
Так что CRC32 вполне подходит нам, пока мы не решим изменить размер данных, от которых считаем хеш, или пока не захотим защититься от умышленной атаки на заполенение нашей таблицы.
Для тестовой платформы была выбран одина из платформ с SoC'ом на борту и двумя сетевыми интерфейсами, смотрящими в FPGA.
Пакеты, которые попадут в NetFlow, берутся из транзита — когда пакет отправляется с одного порта на другой через FPGA. Включение и выключение траниза уже реализовано на этой платформе.
Таким образом, можно создавать нагрузку до 2 Гб/c и при этом контролировать число отправленных на NetFlow пакетов.
На выбранной платформе у FPGA и CPU общая память. Чтобы отделить ту память, с которой будет работать только FPGA (для хранения пакетов), ядру Linux при загрузке ограничивается видимая область памяти, так, чтобы нам хватило оставшейся для хранения 1 миллиона потоков ~ 150 МБ.
Для создания самих export пакетов написали свою простую python утилиту, которая с помощью библиотеки scapy слушает сетевой интерфейс, по которому приходят данные о потоках. С помощью этой же библиотеки она формирует NetFlow Export пакеты и отправляет их.
Заключение
Производительность
Данная реализация NetFlow, в теории, "упирается" только в пропускную способность памяти (в одной из статей мой коллега Des333 производил практический расчет этой пропускной способности на SoC платформе и получил цифры в 20 Гб/c, подробнее можно почитать в его статье тут)
Хватит ли нам 20 Гб/c?
Добавление каждого пакета для нас — это чтение 45 байт из памяти и запись 76.
В худшем случае Ethernet трафик на 1G интерфейсе может создавать нагрузку в 1488095 пакетов в секунду (пакеты по 64 байта на line rate).
Таким образом, мы создадим нагрузку на память в 1.44 Гб/c. Остальную пропускную способность можем отдать на проверку потоков.
Но в текущей реализации производительность намного меньше: на практике мы не справляемся с худшим случаем line rate (пакеты по 64 байта) и часть пакетов не попадает в статистику. Оценить проблему в цифрах можно в симуляции, где придельная, при текущих настройках памяти, нагрузка без потерь ~ 1420000 пакетов в секунду. Это соответствует line rate в случае пакетов размером 69 байт.
Связано это с тем, что аккумулятор работает последовательно — он сначала полностью обрабатывает каждый пакет, а только потом берется за следующий.
Помимо этого, задержка DDR3-памяти получилась достаточно большой (интерконнект, автоматически сгенерированный средой разработки + использование IP-core Stream SDRAM Ctrl дало ~15 тактов задержки
между запросом на чтение и получением данных на частоте 62.5 МГц).
Решением данной проблемы является использование конвейера при добавлении данных в память. То есть мы запрашиваем данные на чтение, и, пока ждем ответа, запрашиваем чтение для следующего потока (и так до 15 раз).
Также можно увеличить частоту, на которой работает Simple NetFlow IP-core и весь доступ к памяти.
Known Issues
Это только PoC и в связи с этим имеется ряд ограничений, таких как:
Мы не следим за концом потока по IP флагам (только по таймерам), хотя NetFlow подразумевает, что это наша задача;
- Производительность очень сильно проседает при большом числе коллизий хеш-таблицы: мы упираемся в производительность сетевого стека между FPGA и CPU, потому что обработка нового пакета блокируется, если у нас нет места, чтобы вычитать пакет из памяти и отправить его в CPU. Возможное решение — реализовать корзины для хранения потоков в памяти (по одному индексу будет лежать несколько потоков);
- Уже упомянутая ранее проблема с производительностью, требующая реализации конвейера при добавлении новых данных в память;
На этом, в общем-то и все. Спасибо, что дочитали до конца.
Буду рад ответить на возникшие вопросы в комментариях.
P.S.
Кстати, мои коллеги из системной группы успели преобразовать те наброски из python утилиты для тестирования в приличный драйвер для Linux и демон на Rust'е, который занимается формированием пакетов для NetFlow.
Возможно когда-нибдуь они об этом что-нибудь напишут. Но пока они отдыхают после статьи про другую нашу совместную работу — ускорение AES шифрования. Если интересно, можно почитать тут.
