
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
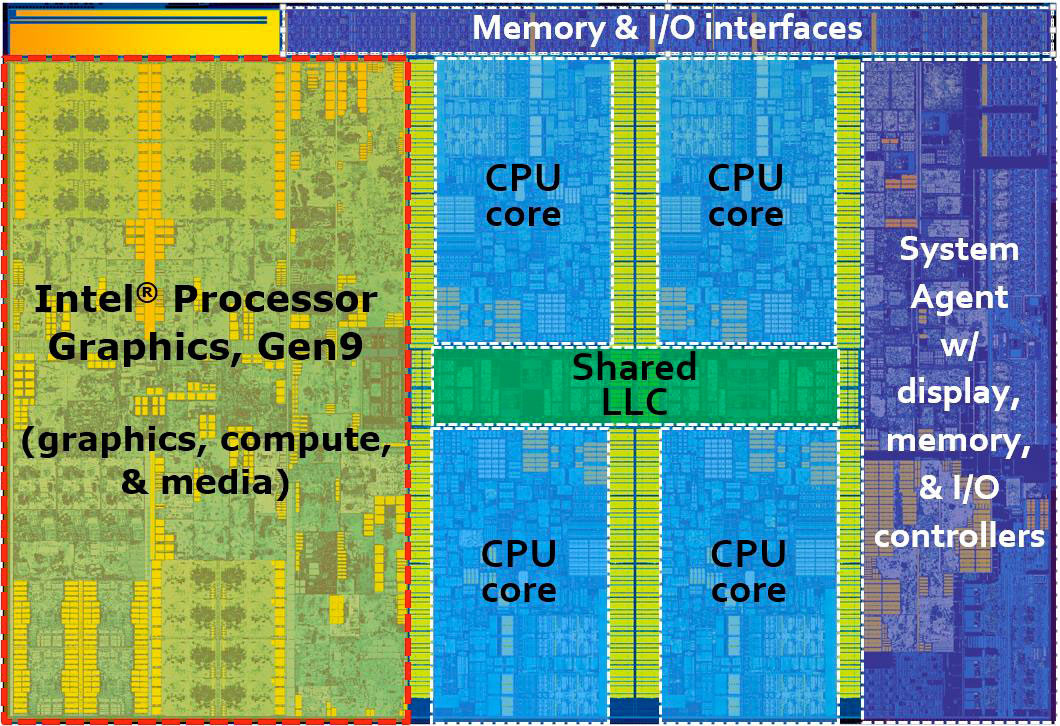
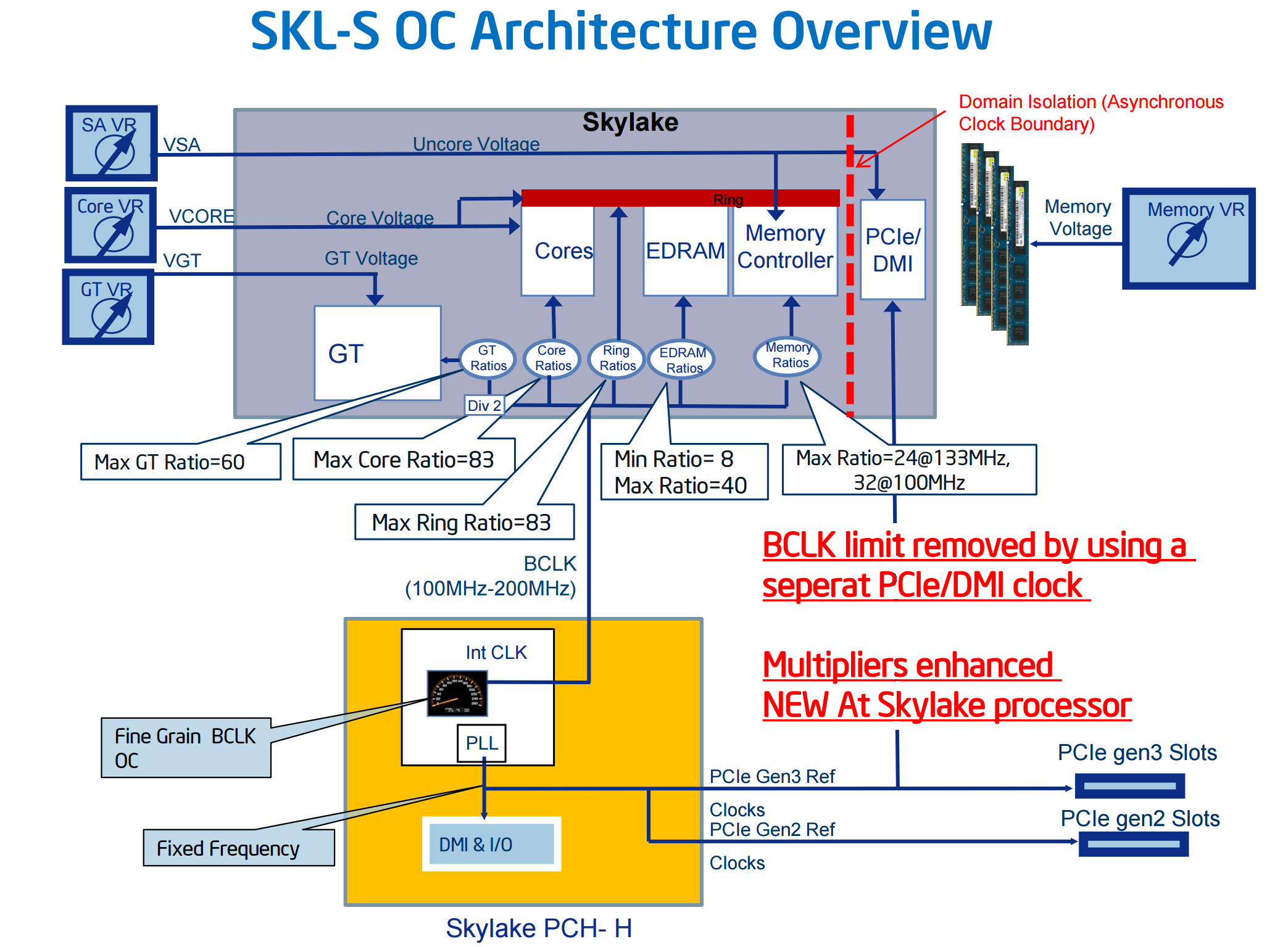
В 6м поколении (skylake) даже в i7 графическая часть занимает уже больше площади кристалла и транзисторного бюджета, чем собственно сам процессор.
зачастую интегрированная графика используется в том случае, если компьютер собирается постепенно, когда денег нет на сборку всего и сразу, интеграшка дает возможность использовать компьютер хоть как-то, не дожидаясь покупки нормальной видеокарты
с чего вы взяли, что skylake быстрее ryzen?
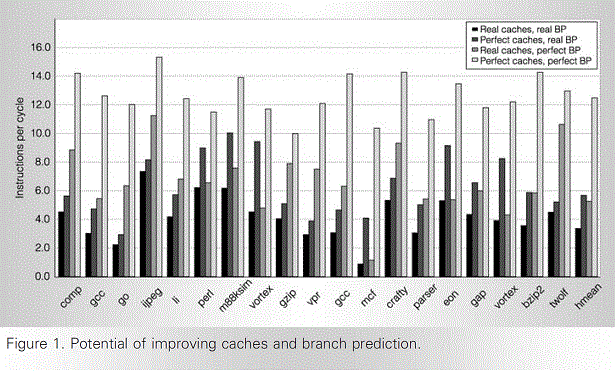
Его ядро можно представить как два, которые на однопоточной нагрузке объединяются.
Ну так вы только что описали HT.
При on/off HT количество доступных исполняющих устройств на поток не меняется
Это почему же? При включённом HT два потока, выполняющиеся на одном ядре, вынуждены пользоваться общими ресурсами ядра. Поэтому при включении HT количество доступных ресурсов уменьшается пропорционально загрузке.
Это и есть «HT наоборот», когда два ядра обрабатывают один поток для увеличения ОДНОПОТОЧНОЙ производительности.
Когда как HT делит часть ресурсов одного ядра, чтобы загрузить их по максимуму для увеличения МНОГОПОТОЧНОЙ производительности.
Принципиальной разницы между этими решениями нет. В обоих случаях имеем логические ядра с разделяемыми ресурсами.
А если ядер больше двух? И еще всякая дерготня через apic бегает? Опрашивать планировщиком, а не схлопнулись ли у нас ядра? А то некоторые процедуры бывают весьма time-critical, их нельзя вешать на "временно отсутствующее" ядро, чьи ФУ отданы другому.
Значит, надо сразу делать матрицы регистров, ИУ, декодеров, предсказателей, ВВ, программно конструировать цепочки ИУ и работать на архитектуре с условным выполнением инструкций. Итого вырисовывается какой-то arm-asic grid, причем сильно смахивающий на видеокарту.
Зато можно будет для множества нетребовательных задач расхлопнуться до decoders/2 логических процессоров, а для жесткой векторной арифметики хоть почти все узлы отдать одному логическому процу, оставив минимум под систему. Заработало ядро — затребовало из пула ресурсы, закончило обработку — отдало все ресурсы обратно в общий пул. Осталось еще beamVM портануть прямо на железо, и вот он — мега-SoC будущего, который захватит мир.
Правда, до того миру надо будет сильно упереться в пределы горизонтального масштабирования, которые пока что все еще удается отодвигать. Ну и схожего эффекта можно достичь и другими, не столь экстравагантными, способами.
AMD ZEN — отказ от узких 2/такт декодеров и разделяемых ФУ, полноценный декодер на 4 инструкции/такт как у iCore (+ до 2 иструкций из кэша уже декодированных). И сразу в один прыжок догнали Intel.
Но, к сожалению, не перегнали. Скорее, только достигли уровня Sandy Bridge.
Например, FPU: у AMD был один FPU на 2 ядра, стало два 128-битных FPU на ядро. У Intel же уже с Haswell имеется по два 256-битных FPU на ядро. То есть могут оказаться задачи, в которых Zen в 8 потоков будет работать со скоростью 4-ядерника Intel.

Было 2 128 битных FMAC на модуль (при этом делимых между 2 ядрами) работающих с плавающей запятой, стало 2 256-битных FMAC в каждом ядре.
Все как у самых современных Intel
Данная диаграмма датируется весной 2015 года и не соответствует действительности. В обзорах последнего месяца указывается, что блоки AVX в Zen будут 128-битные. Возможно, в Zen+ они станут полноценным.
То есть могут оказаться задачи, в которых Zen в 8 потоков будет работать со скоростью 4-ядерника Intel.
Я думаю, стоит дождаться выхода официальной документации на процессоры, а не гадать.
Вообще преимущество будет только на хорошо оптимизированном коде использующим сплошной поток из AVX-256 или FMA3 инструкций(что достижимо в основном в систетике, а не реальных приложениях).
Обычная свёртка в обработке изображений или линейная алгебра — это и есть сплошной поток FMA. Другое дело, когда код написан без использования векторных операций, тогда преимущество Intel в виде большего количества вычислительных блоков действительно теряется.
На подобном хорошо оптимизированном коде из чистого AVX-256, которые полностью загружают 2 FMA256 блока ядра Haswell, тот начинает включать «анти буст/анти турбо» — не просто вырубает любой буст по частоте, но начинает сбрасывать частоты ниже базовой и троттлить из-за того что эти блоки в нем жрут слишком много энергии и слишком сильно греются.
Неужели всё настолько ужасно? Мой Sandy Bridge (32 нм, 4 ядра, по одному AVX256 блоку на сложение и умножение) с довольно сильным разгоном не уходит в тротлинг под максимальной вычислительной нагрузкой. Неужели снижение техпроцесса с 32 нм до 14 нм так и не привело к значительному снижению тепловыделения?
Сейчас у меня 3770К, 4 ядра на 4.1 ГГЦ и без ECC, аргументов купить комп на новой линейке интела нет ни каких.
у меня в памяти лежит кусок данных относительно подряд
Все эти новости о поддержке ECC начались с того, что в спецификациях материнской платы нашли "совместимость" с модулем памяти ECC, про реальную реализацию ECC в процессоре данных нет. В обсуждении https://community.amd.com/thread/210870 заметили спецификации сходных плат, в которых честно указано, что модуль с 9 чипами памяти поставить можно (ECC и неECC DIMMы pin-совместимы), память заработает, но суммы ECC никто ни считать, ни исправлять не будет — http://www.gigabyte.us/Motherboard/GA-AX370-GAMING-5-rev-10#sp (AMD X370)
"Support for ECC Un-buffered DIMM 1Rx8/2Rx8 memory modules (operate in non-ECC mode)"
Работающий ECC увеличивает задержки примерно на такт (для каждого запроса требуется подсчитать код и, в случае чтения, может потребоваться инверсия одного из битов при получении признака ошибки), хотя и слабо влияет на реальную производительность.
Ранее корпорация AMD включала обычный SECDED ECC в некоторые десктопные продукты, но оставляла для серверных платформ более продвинутые варианты кодов, например:
Athlon 64, 2004 "2.4.2 Memory Controller… ECC checking with single-bit correction and double-bit detection • Chip Kill ECC allows single symbol correction and double symbol detection (Server/Workstation products only)";
16h G-Series SOC 2012, FT3 "Integrated Memory Controller… FT3 package… Supports ECC";
16h AMD Sempron, 2014 "FS1b package… Supports ECC"
16h A-Series Mobile "FT3 package… Supports ECC"
10h AMD Phenom II, 2010 "Integrated Memory Controller .."
В то же время ECC не включался в ряд встраиваемых APU, например 15h… Embedded R-Series, 2012 "Integrated Memory Controller", 15h A-Series APU 2012 "Integrated Memory Controller" — без ECC.
Точная информация будет через несколько недель с публикацией спецификаций на процессоры и чипсеты (поиск site:support.amd.com "family 17h"). Сейчас есть только предположения, хотя определенный код для F17 уже добавлен в ядро Linux: http://lxr.free-electrons.com/source/drivers/edac/amd64_edac.c?v=4.10#L2192, есть некоторая информация в истории этого файла: https://github.com/torvalds/linux/commits/master/drivers/edac/amd64_edac.c, например отказ включать ECC если он выключен (или не поддерживается) в BIOS "Forcing ECC on is not recommended on newer systems. Please enable ECC in BIOS".
Одно из изданий (STH) спросило на AMD Tech Day in San Francisco представителей AMD, ожидается ли анонс односокетных Zen/Ryzen с поддержкой ECC и получило ответ, что AMD не анонсирует таких продуктов при запуске Ryzen.
https://www.reddit.com/r/Amd/comments/5vpp40/no_ecc_support_in_any_of_the_currently_announced/ — https://www.servethehome.com/amd-ryzen-7-parts-available-for-pre-order-now/ "AMD RYZEN 7 PARTS AVAILABLE FOR PRE-ORDER NOW!" — PATRICK KENNEDY FEBRUARY 22, 2017
We did ask about a potential single socket Ryzen/ Zen part with ECC memory support and were told that AMD was not announcing such a product at this time alongside the Ryzen/ Zen launch.
http://www.anandtech.com/print/11170/the-amd-zen-and-ryzen-7-review-a-deep-dive-on-1800x-1700x-and-1700 The AMD Zen and Ryzen 7 Review: A Deep Dive on 1800X, 1700X and 1700 — March 2, 2017 9:00 AM EST
At this time AMD is not announcing any Pro parts, although it was confirmed to be that there are plans to continue the Pro line of CPUs with Ryzen to be launched at a later time.… A side note on ECC: given the design of Naples and the fact that it should be supporting ECC, this means that the base memory controller in the silicon should be able to support ECC. We know that it is disabled for the consumer parts, but nothing has been said regarding the Pro parts.… For our testing… 1800X, 1700X and 1700… At present, ECC is not supported.
В мегатреде AMA (3 марта 2017)
https://www.reddit.com/r/Amd/comments/5x4hxu/we_are_amd_creators_of_athlon_radeon_and_other/
ответили на вопрос о ECC в Ryzen (поддержка есть, включается в BIOS если было реализовано поставщиком материнской платы, работоспособность ECC не гарантируется — не валидировалась в продуктах для "геймеров"):
https://www.reddit.com/r/Amd/comments/5x4hxu/we_are_amd_creators_of_athlon_radeon_and_other/def5ayl/
whatever0601: Could you speak to ECC being disabled in these CPUs?
AMD_Robert Technical Marketing[S]: ECC is not disabled. It works, but not validated for our consumer client platform.
nagvx: What does "validated" mean in this context? What sort of stumbling-block does that represent to those who want ECC? Will it still be possible to build ECC-enabled servers with consumer-grade (and consumer-price-range) hardware on the Ryzen platform? There are a significant portion of users who want ECC for their NAS/Homelab setups.
AMD_james Product Manager: Validated means run it through server/workstation grade testing. For the first Ryzen processors, focused on the prosumer / gaming market, this feature is enabled and working but not validated by AMD. You should not have issues creating a whitebox homelab or NAS with ECC memory enabled.
ShermanLiu: So the Ryzen has full ECC support, if I install a ECC memory, it would work in ECC mode, not non-ECC mode?
AMD_james Product Manager: yes, if you enable ECC support in the BIOS so check with the MB feature list before you buy.
tolga9009: Thank you for the answer! So, the AM4 platform / socket theoretically has everything to fully support ECC and it's only up to mainboard manufacturers. Is that correct?
AMD_Robert Technical Marketing[S]: Bingo.…
AMD_james Product Manager: RDIMM will likely not be supported. UDIMM ECC will work.…
TheRealHellBENder: I asked Asrock per mail and they answered that their B350 boards would operate in non-ECC mode
AMD_james Product Manager: Thanks for letting me know. I'll check with the MB makers and see if we can get consistent.
ParticleCannon: Speaking of prosumer features, is AMD-VI/IOMMU in?
AMD_james Product Manager: yes
tolga9009: I've seen IOMMU entries in ASRock and ASUS BIOSes. It's disabled by default, but you can enable it. So, it's in there. But I haven't seen any hands-on tests so far.
https://www.reddit.com/r/Amd/comments/5x4hxu/we_are_amd_creators_of_athlon_radeon_and_other/def58sv/
Minkipunk: Hello AMD! This question is a very short one. Do Ryzen CPUs support ECC Memory, yes or no? ;)
AMD_LisaSu CEO of AMD: Yes they do!
drchoi212x: do they support ECC-REG memory as well?
AMD_james Product Manager: ECC-REG — No, registered or buffered memory is not supported.
Этот патч также несколько интересен своей историей. Принят патч с сообщением: http://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/commit/?id=044e7a414be9ba20826e5fd482214686193fe7b6
EDAC, amd64: Don't force-enable ECC checking on newer systems
It's not recommended for the OS to try and force-enable ECC checking.
This is considered a firmware task since it includes memory training,
etc, so don't change ECC settings on Fam17h or newer systems and inform
the user.
- amd64_warn("Forcing ECC on!\n"); + if (boot_cpu_data.x86 >= 0x17) { + amd64_warn("Forcing ECC on is not recommended on newer systems. Please enable ECC in BIOS."); + goto err_enable; + } else + amd64_warn("Forcing ECC on!\n");
В предыдущей версии патча https://www.spinics.net/lists/linux-edac/msg06912.html "[PATCH 07/17] EDAC/amd64: Don't try to force ECC settings on newer systems" просто не включали ECC даже по ecc_enable_override=1 и не выдавали каких-либо сообщений:
+ /* Don't try to enable DRAM ECC from Linux on newer systems. */
+ if (boot_cpu_data.x86 >= 0x17)
+ return;На что было указано: https://www.spinics.net/lists/linux-edac/msg06931.html "Add… along with a pr_info()
explaining to the user why we're not going to force-enable ECC."
Вся серия патчей AMD Fam17h EDAC — https://www.spinics.net/lists/linux-edac/msg06905.html
Поиск патчей в ядре по строке "17h" http://git.kernel.org/cgit/linux/kernel/git/torvalds/linux.git/log/?qt=grep&q=17h (в частности, год назад там заметили раннее кодовое обозначение "AMD Zeppelin (Family 17h, Model 00h)")
В реальной задаче по кодированию видео в тесте Handbrake процессор Ryzen 7 1700 справился с задачей за 61,8 с, а Core i7 7700K — за 71,8 с. И это несмотря на то, что скорость кодирования видео с аппаратной поддержкой всегда считалась сильной стороной процессоров Intel.
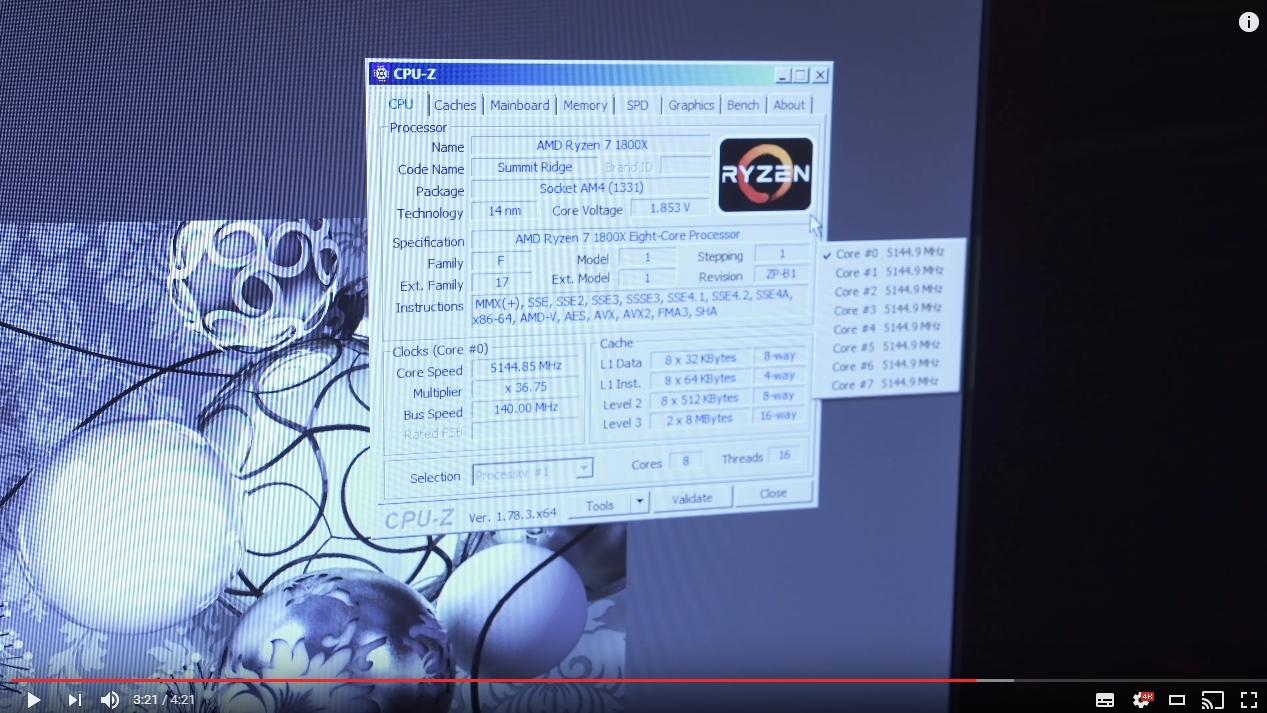
еще к свежим утечкам: "Ryzen 7 1800X, разогнанный до 5.2 Ghz, установил рекорд Cinebench R15 — 2449."
.
Вот 6, похоже, ника не получить…
5.1449.ceil
res0: Double = 6.0
Меня не покидает стойкое ощущение какого-то подвоха. Ведь если все так прекрасно, как описывают сами АМД, то зачем продлевать обзорщикам NDA до второго марта (старт продаж)?
Т.е. у компании АМД задача создать побольше шума, а не продать побольше процессоров? Интересно.
У Ryzen 7 1800X TDP = 95Вт, но это тоже неплохо)
Мягкий знак и латинская i. Возможно, у человека просто нет "ы" в раскладке.
если АМД быстро не выкатит что-то сравнимое
К тому же десктопы нужны мало кому,
Я часто решаю проблему розеток в аэропортах тройником и выдергиванием вендинговых автоматов из розетки.
По поводу расширяемости — я лично пердпочитаю ПроБук серию НР, ДЕЛЛЫй ентерпрайзных моделей, и верхний сегмент Лениво.
Обоснуйте, что понимаете под обслуживаемостью и расширяемостью. Конкретно в HP и Lenovo меня дико раздражает BIOS Whitelist — не могу ни проапгрейдить Wi-Fi карточку, ни поставить Mini PCI-E SSD. В отличие от десктопов, идеальных ноутбуков нет — приходится либо мириться с недостатками, либо сильно переплачивать.
ну manufacturer ACL-листы еще никто не отменял, увы. Никто в Лениво не хочет, чтоб вы купили ссд у Самсуя и вайфлю от ЛГ :)
Даже ещё хуже: я не могу в старый ноут HP воткнуть карточку от более нового ноутбука HP. Никто не хочет, чтобы вы сделали небольшой апгрейд вместо покупки нового ноутбука.
Обслуживаемость и расширяемость в моём понимании — легко открыть, достать до нужного компонента не снимая материнку, легко заменить комплектующую типа кулера\клавиатуры\тачпада\памяти итд.
Я бы тогда назвал надёжностью и ремонтопригодностью.
А расширяемостью в современных ноутбуках, увы, не пахнет: со времем становится только хуже.
про то и речь. SSD, блок питания, корпус — при апгрейде не требуют замены.Дешевые ноуты просто издевательство.
а для серьёзных игр нужна спокойная обстановка, много времени и стол для мышки.
Сервис, а в России им кто-то пользуется?
Да, крупные корпорации пользуются, особенно бюджетные.
Сервис, а в России им кто-то пользуется?
гейминг и еше раз гейминг
Если процессор действительно хорош — то как он получился?
третий процессор Ryzen 7 1700 с энергопотреблением до 65 Вт
Всегда считал, что 99% энергии, потреблённой процессором идёт в тепло (из-за паразитных ёмкостей/сопротивлений), разве это не так?
Это отличная новость для всех в мире, кроме сотрудников и акционеров компании Intel.
Думаю не совсем так, так как что то мне подсказывает, что антимонопольный комитет уже придерживает Intel за причинное место, по x86.
Надеюсь, что амд взлетят, ибо интел откровенно обнаглели без конкуренции, начиная после санди бриджа показывать 3-5℅ прироста.
Интересно, что там по разгону и производительности у 4с/8т
Интересно, какова причина остановки роста тактовой частоты? Почему уменьшение техпроцесса на порядок не дало возможности создавать процессоры с частотой 20 ГГц?
Как раз эта статья вызывает только ещё больше вопросов:
Один из таких способов – переход к более совершенному технологическому процессу.… Тем не менее, производители микропроцессоров постоянно совершенствуют технологический процесс, и частота за счет этого постепенно ползет вверх.
До 32 нм всё так и было: 45 нм — предел 3600 МГц (максимальное повышение частоты без значительного повышения напряжения), 32 нм — предел 4500 МГц, а затем всё встало. Сейчас уже 14 нм — предел всё те же 4500 МГц.
Я даже не уверен что 5 ГГц возьмем в ближайшем будущем в серийных образцах.
И не получится ли что i7 2го поколения на 7ггц будет быстрее чем i7-7700K на 4.5 ггц.
"единичного транзистора на частоте скажем в даже 100 ГГц… А вот даже имея такие транзисторы, создать из них очень сложную схему"
Частоты транзисторов уже выше 100 ГГц (хоть это и немного другие транзисторы, но порядок примерно такой) — Samsung 28nm "Ft (maximum unity gain frequency) of 280GHz and Fmax of 400GHz" — http://electronics360.globalspec.com/article/4078/samsung-foundry-adds-rf-to-28-nm-cmos
Собранная из транзисторов схема (любая — т.е. даже локальная типа сумматора или стадии ALU/FPU блока) для повышения своей полезности за такт переключает целые цепочки транзисторов. Традиционно задержку схемы (critical path) считали в т.н. Logical Effort в нормализованных (не зависящих от техпроцесса) единицах, например в τ, где одна τ = 3RC ("delay of an inverter driving an identical inverter with no parasitic capacitance") или в "FO4" (Fan-out of 4 — "one FO4 is the delay of an inverter, driven by an inverter 4x smaller than itself, and driving an inverter 4x larger than itself.… 5·τ = FO4"). В http://en.wikipedia.org/wiki/FO4 есть некоторые оценки длины такта в единицах FO4 для разных процессоров: "IBM Power6 has design with cycle delay of 13 FO4;3 clock period of Intel's Pentium 4 at 3.4 GHz is estimated as 16.3 FO4.4"; Еще примеры из http://www.realworldtech.com/fo4-metric/ — Revisiting the FO4 Metric, 2002:
Примеры схем и их FO4 http://www.realworldtech.com/fo4-metric/3/ — быстрый 64-битный однотактный сумматор — 7-5 FO4, разные варианты сдвига — http://www.realworldtech.com/fo4-metric/4/; часть FO4 требуется затратить на skew синхросигнала и slack/guard тригерров вокруг комбинационной логики.
К сожалению в оценках схем через FO4 не учитываются задержки проводов, а сейчас именно провода в большей степени ограничивают скорости (и кроме того, в длинных проводах частенько ставят усилители, которые также имеют задержку). Рекомендую материалы с https://inst.eecs.berkeley.edu/~cs250/sp16/ (осторожно, соавторы Risc-V) —
Существуют проекты технологий с пониженными задержками логического элемента (и резко пониженными температурами, жидкий азот для них слишком горяч; 4-7 K) и огромными проблемами каскадирования более 3-4 элементов друг за другом. Авторы вынуждены строить "процессоры" и "алу" с очень короткими (в единицах FO4) стадиями
https://pdfs.semanticscholar.org/015c/52e3ee213ae1d0eefe8815a0023bd48a4d99.pdf#page=4
"eight bit-stream arithmetic logic units (ALUs) interleaved with eight 8-bit general-purpose integer registers (R0-R7)" (АЛУ работает побитно, каждый однобитный кусочек АЛУ находится рядом с "битовой колонкой" регистрового файла), "A single-bit ALU (bALU) has a 3-stage execution pipeline" — один бит в АЛУ обрабатывается в 3-тактовом конвейере и это bit-sequential processor, т.е. для одной операции над 8 битным регистром требуется 12 тактов. Зато тактовая частота 17-20 ГГц.
Это (и подобные ему) изделия очень далеки от того, чтобы называться процессором. Это радиочастотный усилитель с очень простой схемой состоящий из считанных единиц транзисторов (в миллионы раз проще даже самых простых из современных процессоров типа встроенных в разную быт. технику и игрушки). Вот тут более безграмотно написано про него в отличии от ссылки выше и кучи ее копий растащенных по другим сайтам: https://xakep.ru/2014/11/02/terahertz-monolithic-integrated-circuit/
Ничего вычислять (обрабатывать данные) подобная микросхема не может, поэтому называться процессором тоже. Это как усилитель в радиоприемнике (радиопередатчике) процессором называть.
А как-же радеон r3/r5/r7?
Самый интересный вопрос о кодировании видео — использовали ли они ускорение встроенного видеоядра. 630 графика интела дает в 264 кодере х10 производительность. никакому процессору этот прирост и не снился — если нет то сравнение некоректно. Даже видео паскаль с кудой не достигает такой скорости как то что сделали в видеоядре интел!
Так то меня интел бесит. Начиная с термопасты под крышкой и заканчивая архитекторными нюансами. Но увы альтернатив по перегонке видео нет. Ежели интел работал с видеоядром то это нереально круто что райзен смог такое.
фанаты x264 говорят хардварщина отстой. Только софтварные кодаки если нужно качество.
Мне глубоко пофигу какой кодек. у меня с каждой поездки по 180 гиг несжатого видео с фотиков с потоком в 70к я его пересжимаю иногда в 10 где хочу оставить качество а иногда и в 3к когда надо оставить абы було.
Кроме того сильнейше выручает скорость одного потока ведь когда надо стабилизировать картинку то работает максимум полтора потока — один стабилизирует а второй распаковывает/запаковывает назад. и вот тут то амд сразу в пролете ибо даже в топе на один поток они слабее i7 а i7-7700 на один поток слабее i5-7600 который я и приобрел недавно. Вот таки дела малята. я свой проц не могу загрузить на 100% — максимум 75. Нет смысла в 16 потоках когда у тебя одна задача!
А нету в фотике выбора битрейта?
Вы правда считаете, что фотик будет жать лучше? Задача фотика — сохранить видео в реальном времени, а не максимально сильно сжать видео.
core i5-7600k есть встроенная графика hd630
легко конвертирует 4к в 5 раз быстрее чем реальное воспроизведение при этом загрузка проца 30%.
я говорю о том что мне всеравно чем они этого добились но если с фотика моего 1 час видео конвертируется 2 минуты то я офигеваю от скорости а если пол часа то я офигеваю от тупости. для примера могу привести время конвертации с использованием видеокарты hd630 — 2 минуты. и без видеокарты — только проц 4 ядра 4 потока — 20 минут. тот же ш7-7700 этот же видик конвертирует 13 минут без видеокарты и 8 минут в паре с 1080 нвидиевской. апаратное nvenc естественно задействовано. Мне побоку внешней или внутренней. кстати если вставить ко мне внешнюю видео в систему — внутренний кодек остается работать! тоесть как видеокарта она гуано может быть но как апаратный ускоритель h264 — отличная штука! и зачем мне 16 ядер если распаковка архива — один поток, проведение документов в 1с — один поток, 99% игр — 2 потока, фотошоп — 3 потока, лайтрум 4 потока. Даже 4 ядра я нереально редко вижу занятыми на 100%. зато регулярно вижу 25% загшрузку — тоесть уперлось в одно ядро и все… тупим…
Фотик может писать 20кбит но это такое порно что лучше писать в 80 а потом компом перегонять. тем более есть моменты которые надо покачественнее сохранить а есть такие что и удаляются до перегонки.
13 минут без видеокарты и 8 минут в паре с 1080 нвидиевской
Что-то здесь нечисто. Хотя, если почитать поподробнее, то окажется, что:
Видеокарты не очень подходят для кодирования видео из-за особенности их архитектуры. Терафлопсы у 1080 просто не получается эффективно использовать в конкретной задаче.
Тогда не удивительно, что полноценный аппаратный кодер будет выигрывать по скорости у неспециализированного инструмента. И это хорошо. Надеюсь, следующим этапом развития процессоров будет аппаратный FRC (frame rate conversion).
А основной недостаток встроенного кодера у Intel, судя по отзывам — это жертва качеством ради скорости и меньшая гибкость в настройке кодера. Но для большинства пользователей это не критично — ну будет файл больше размером в итоге, ну и ладно.
Видеокарты не очень подходят для кодирования видео из-за особенности их архитектуры.
Раз так то вам путь к серсверным ксеонам с 12 ядрами. Или к платам с 2-3 такими процами на борту. Или уже освойте Куду — там полторы тысячи процев +-.
Извольте мы говорим не о зионах серверных, которые и разрабатывались для 100500 потоковости а о обычных консьюмери процах где максимум что в 99.9999% задач это 1-2 потока игры видео и иногда — какие-то Click-to-convert приложения "уменьшить размер видео с фотика" и все. Не думаю что каждый пользователь дома брутфорсит хеши или майнит коины — для этого процы безнадежны — видеокарты намного лучше но тоже увы полный шлак уже — электричество не отрабатывают. Революции не будет… не произошло… увы. ЗА последние 6 лет скорость одного потока реально возросла всего лишь в два раза.
Если я знаю как и что считать то мне всеравно как и на чем это реализовывать. а если доверять всяким длибам неизвестно под что оптимизированным и под что писанным то конечно начинаются поиски того камня который и был у разработчика этого длиба когда он её писал.
Потому многие свои расчеты я по раз 20 переделываю в программе через разные функции разные способы выделения амяти и т.д. пока не получу наилучший по скорости результат с наименьшими затратами памяти. И зачастую готовые универсальные библиотеки проигрывают конечному результату сделанному под конкретное имеющееся железо(на котором оно и будет крутиться) и под конкретную задачу. Яркий тому пример — printf и вся его братия из STDLIB которая вместе с ним едет. в условиях микроконтролеров это иногда выливается в занятие половины флеша ненужными универсальными функциями которые на отображение примитивного 4значного числа могут зажрать под 8000 тактов. в то время как руками написанная функция -аналог без ничего лишнего укладывается в 2% флеши и 400 тактов. Что называется почувствуй разницу.
Потому возражение не защитано. Я могу привести ещё 100500 примеров когда стандарнтые либы не подошли а немного допиленные руками — взлетели/загудели. У каждого камня есть свои слабые и сильные стороны. Сила программистов ресурсоёмких приложений — эксплуатировать сильные стороны и обходить слабые.
нелогично — кроме встроенного видео это же ядро дает просто термоядерное ускорение h264 как енкодинг так и декодинг. сидеть на нем понятное дело нет смысла но в некоторых задачах оно нереально полезное дело!
Зато аппаратный декодер очень полезен в мобильных устройствах. Десктопу пофигу: декодирование — процесс не очень затратный, а вот в случае ноутбука даже небольшая нагрузка может сильно повлиять на время автономной работы.
А причём здесь виндошрифты? Любой шрифт будет выглядеть лучше, если его рендерить с высоким DPI.
А проблема в том, что Linux до сих не умеет нормально работать с HighDPI: в нём это делается на уровне приложений. Если приложение не поддерживает переменный DPI, то оно будет отрисовываться очень мелко.
В Windows же приложение, не умеющее в HighDPI, система просто обманывает. Таким образом, в Windows масштабируется всё (ну кроме случаев, когда приложение заявляет, что оно DPI-aware, а на самом деле нет).
Всё просто: если устройство может снимать в 4К, то пусть снимает. Иногда лучше потом на этапе обработки пережать или убрать лишнее, чем потом сокрушаться, что качество исходника было низким.
ни в коем случае. Куча мониторов рабочих с одним VGA интерфейсом. VGA прекрасно работает до fullHD.
А DVI-I — только людей путать очередными переходниками и на бабки разводить.
Стоит заметить, что в процессорах Skylake поддержки аналогового сигнала встроенным видеоядром больше нет. Так что ни VGA, ни DVI-I там больше нет — Intel уже сделала шаг.
убил бы всех кто не ставит копеешные включенные в проц и чипсет интерфейсы на плату — нереально напрягает.
Прошлое поколение процессоров… во многом стало разочарованием и ограничилось преимущественно использованием в недорогих конфигурациях…
Через гугл уже можно выковырять обзоры :)
https://3dnews.ru/948466
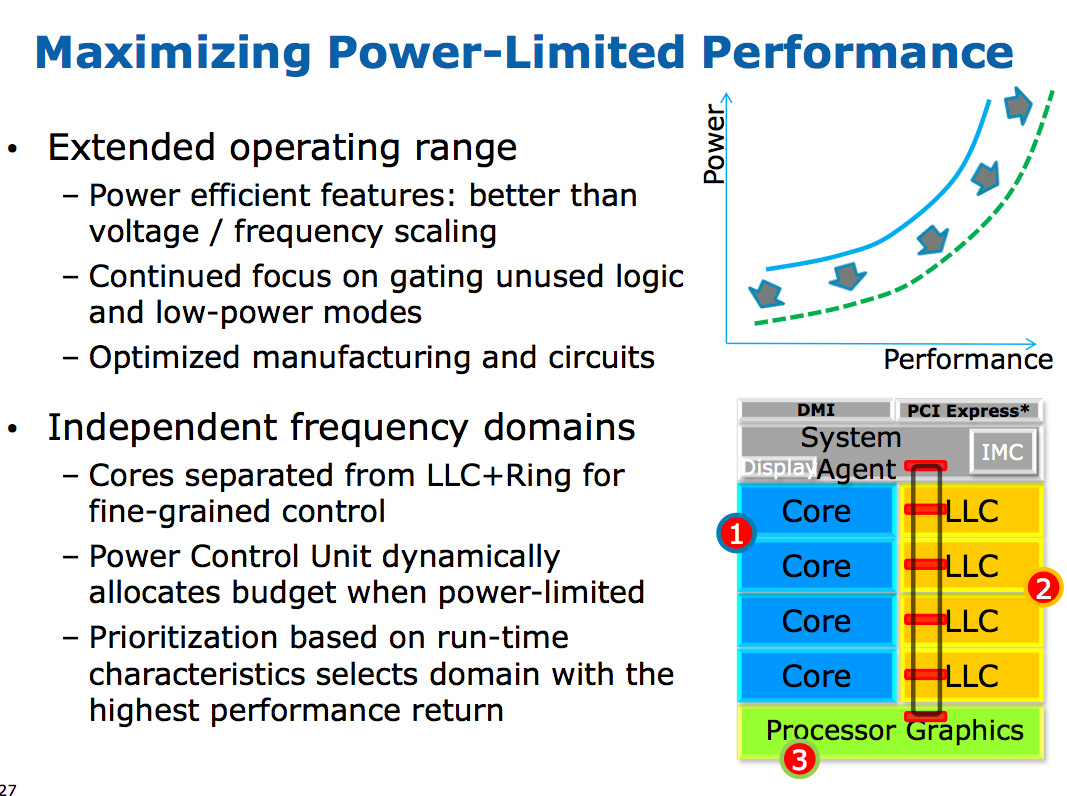
Спасибо. Очень неплохие результаты. Из этих тестов как раз и вылезает преимущество Intel при выполнении операций AVX за счёт большего числа блоков FPU (Intel: два 256-битных блока, AMD: два 128-битных). Причём это преимущество раскрывается только при использовании HT — один поток не способен загрузить все FPU-блоки одновременно.
Интересно, будет ли в Zen+ четырёхканальная память?
Update
Спасибо. Очень неплохие результаты. ...
Это относилось вот к этому:
Через гугл уже можно выковырять обзоры :)
https://3dnews.ru/948466

{kind=link}
{kind=link}
{kind=link}
AMD представила процессоры Ryzen 7