
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
того что бы кинуть все силы на разработку против серьезных болезней.Кто такое сказал? Сейчас есть разработки в этом направлении. Так ИИ лучше ставит диагнозы, чем врачи. У бота множество данных о симптомах, их скармливают машине, а она просто мимикрирует и выдает результаты.
А вот это суровая правда, сейчас ИИ используется для того что бы получше впаривать людям не нужное им говноВот почему сразу ненужное? Вполне себе нужное.
А кто сказал, что оно должно быть умнее человека?
Вы можете обучить его быть глупым, средним…
Лично меня в этой демонстрации СтарКрафта больше всего впечатлило не то, что нейросеть размазала противников почти всухую (этого следовало ожидать рано или поздно), а то, что она легко и изящно проходит тест Тьюринга.Это в каком таком месте она тест Тьюринга проходит? В том самом, в котором ее более низкий средний апм становится супервысоким текущим апмом, и сетка за счет микроконтроля уровня СУПЕРБОТ9000 разбирает куда более сильную армию противника? Да и продула она именно в тот единственный раз, когда перед ней поставили задачу двигать камерой.
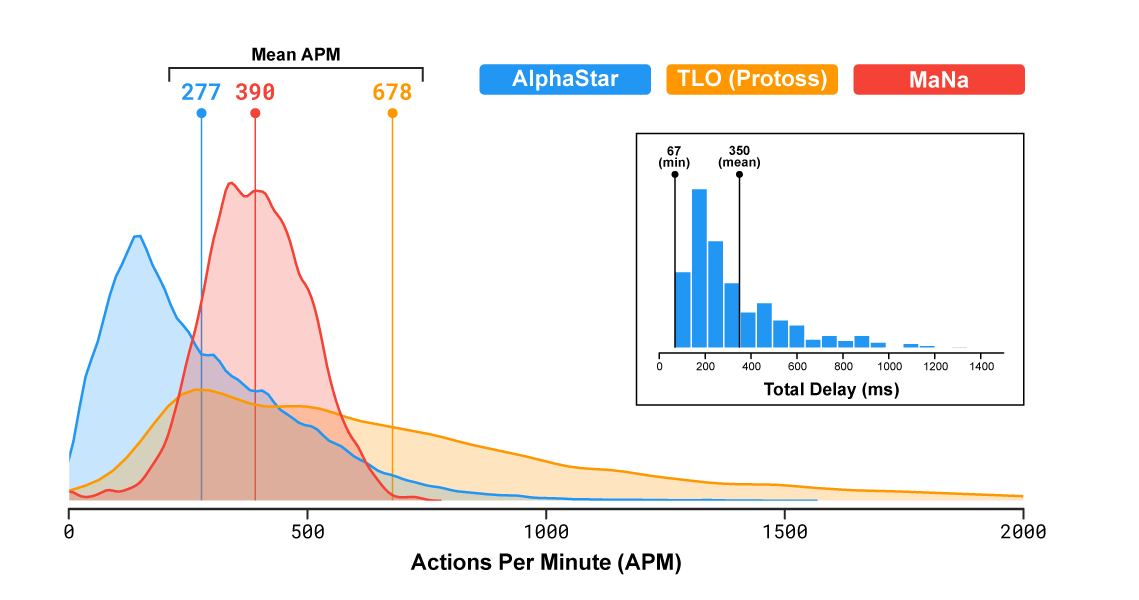
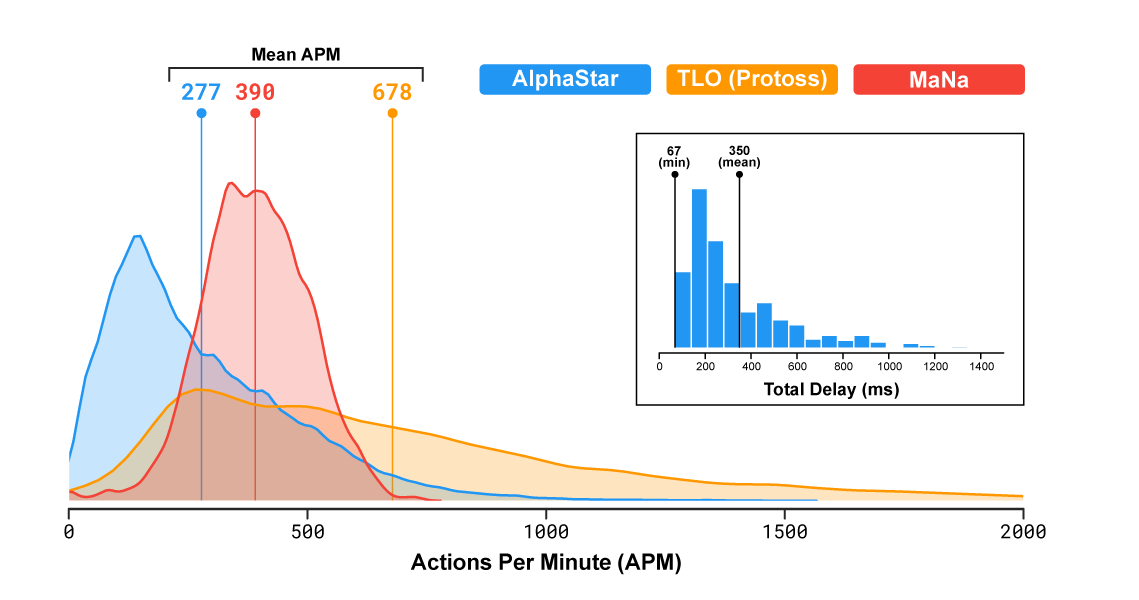
Самое революционное в этой сетке то, что она побеждает сильных игроков, при этом имея более низкий средний APM.
Ну стоит уточнить, что продул агент с камерой который учился 5 дней всего, другие же агенты без камеры учились по 200 лет каждый, а таких агентов было более 1000 и вот с ними уже было 0 шансов у человека. Я как любитель в старкрафт могу сказать, что тест Тюринга ИИ проходит он действует как человек но при этом почти не совершает ошибок. Самые значительные отклонения от человека заключаются в начальной разведке, да и в разведке в целом и видно, что разведка дроном это некий рудимент обучения на людях, бот пытается повторить эти действия но не до конца и не понимает зачем ему это.
На нем не только средний APM но и мгновенный и распределение по времени. Так вот — мгновенный, тоже не превышает человеческого уровня.
Мгновенный апм TLO — это рапид фаер, то есть зажимается одна кнопка и набивается апм нонстопом (с-но, сами то не могли догадаться, что 2к апма для человека — физически невозможное значение?). Игнорируйте его график и сравнивайте хвосты с маной — там все сразу понятно, даже без учета того, что процент "бесполезных кликов" у маны, опять таки, сильно выше чем у альфы.
Вы можете обучить его быть глупым, средним… Лишь бы при этом оно выглядело человечно
она легко и изящно проходит тест Тьюринга.
при этом имея более низкий средний APM
APM — APM-ом, а точность кликов и скорость реакции совершенно нечеловеческие. И в 10 первых ихрах бот видел всю карту сразу (хоть и с туманом войны) и камеру никуда не двигал. Разработчкики, конечно, говорили, что, мол, он внимание фокусировал вроде как в одном месте, но там был момент, где бот контролировал одновременно 3 группы юнитов с разных сторон, когда окружал армию противника.
В последней игре, вроде как, ввели понятие камеры для бота и он ее проиграл.
И если от них там будет требоваться работа — большинство просто перестанет играть. «Долбанутые» геймеры останутся, конечно, но кассу они не делают.Это всё равно что говорить о профессиональном спорте. Чемпионы мире — еще те… «долбанутые».
А человек настолько легко это делает, что ему кажется, что этот процесс настолько прост, что его можно вообще не реализовывать в ИИ, что абсолютно неверноВ каком возрасте человек делает это легко? Нужны годы, чтобы научить говорить, а потом еще и понимать. Да, пока ИИ не может. Но, закликать человека — легко…
Как раз такого рода задачи ИИ уже относительно хорошо решает. См. например датасет bAbI. Там как раз такого рода примеры:
1 Mary moved to the bathroom.
2 John went to the hallway.
3 Where is Mary? bathroom
И более сложные запутанные ситуации. Но в целом верно, существующие системы обучения ИИ оторваны от реального мира и нет никаких гарантий, что из предоставляемых им датасетов можно извлечь эту информацию. О том что на самом деле происходит в описываемом тексте. Не говоря о практически отсутствующей у текущих слабых ИИ возможности делать последовательные рассуждения.
После обеда Юлия пошла в парк.
Вчера Юлия была в школе.
Юлия ходила в кино этим вечером.
Q: Куда Юлия пошла после парка? A: В кино.
Q: Где Юлия была перед парком? A: В школе.
1. Катя долго собиралась.
2. Катя опоздала.
3. Катя обнаружила, что торт съеден.
А ИИ этого не делает, ИИ лишь выдаёт результат, который по сути функция от вводных данных.


Строго говоря, «вообразить» что-то – это тоже функция от входных данных.
Нет. Если вы слышите, как кошка лазит за шкафом, у вас в воображении появляется и кошка и шкаф и примерное расположение кошки. А входные данные это шум. А в другой ситуации, например в гостях у друга, у которого собака, или если у вас нет кошки, такой же шум даст другую картинку в воображении.
То есть это функция не только от входных данных, а еще и от предыдущих запомненных. Их тоже можно считать входными, но вопрос в том, как они появляются в воображении из входных данных на тот момент.
Когда подросток читает «Таинственный возраст» он создаёт мир, в котором есть всё, что описано в книге по тексту книги.
Когда нейросеть «читает» этот же текст, то она ничего подобного не делает.
Неверное утверждение. Нейросеть как раз делает то, что и подросток — создает, воображает модель мира.
Нейросеть решает конкретную задачу, на которую вы ее обучите. Это совсем другое.
Человеческий мозг, в конечном счете, тоже решает одну единственную задачу. Победить в эволюционной гонке.
Вообще-то нет. Не решает он такой задачи.
Если не решает, то человек не оставляет потомства. Или его потомство голодает/живет под мостом/умирают от болезней (вставьте свой вариант).
Ну так на практике это весьма часто происходит, ergo, не решает.
Укажите мне, пожалуйста, на любую деятельность человека, которую нельзя было бы вписать в модель эволюции.
Натянуть сову на глобус, безусловно, можно всегда, ведь если привести пример людей, которые не ставят целью классические "жена-дети", то вы бодро отрапортуете, что это компенсация.
Но вы забываете одну простую вещь — у эволюции нет никакой цели. Эволюция (как и природа в общем) не обладает разумом и не способна к целеполаганию.
По-этому никакой задачи, вообще говоря, перед мозгом (и вообще любыми органами) не стоит. Все органы работают совершенно случайным образом, сформировавшимся исторически, в качестве казуса (те, у кого органы работали плохо, очевидно умерли). Вот и все.
если привести пример людей, которые не ставят целью классические «жена-дети», то вы бодро отрапортуете, что это компенсация...
Я имею в виду, что мозг потребляет энергию, которую существо вынуждено добывать прилагая серьезные усилия. И чтобы оправдать свое существование в теле, он должен что-то производить.
Нет, он никому ничего не должен. Потому что, еще раз — у природы нет целеполагания.
Мозг производит интеллектуальные усилия — с целью улучшить условия жизни как отдельной особи, так и общества в целом.
Мозг производит интеллектуальные усилия просто потому, что он так устроен. Точно так же у Солнца нет цели вставать на востоке и заходить на западе. Просто так устроена солнечная система. Никак по-другому Солнце действовать просто не может. Как и мозг.
у природы нет целеполагания.
Всегда очень интересно, зачем в споре апеллировать к тщетности бытия
Чет непонятно, как вы от отсутствия целей у природы пришли к тщетности бытия.
Я сказал «цель — выживание»,
Цель чего?
Моя основная аксиома: смысл жизни состоит в сохранении жизни. Не данной конкретной особи, а жизни как таковой, как явления.
Ваша аксиома ложна. У жизни (как таковой, не конкретной особи) нет никакой цели. Потому что у жизни нету сознания. А без сознания цели быть не может.
Отсутствие у самой природы как таковой смыслов и целей не мешает нам ей эти смыслы придавать и цели обозначать. Просто для того, чтобы наши с вами мыслительные действия можно было вести.
Попытка основывать рассуждения на базе заведомо ложного утверждения уж точно не прощает мыслительные действия. Наоборот.
А без цели мысль бесполезна. Она просто не работает.
Моя мысль — замечательно работает.
Мне куда интереснее проанализировать, какие цели я бы задал природе, если бы находился на месте разумного творца.
Но это же совершенно другой вопрос :)
Можно отвечать на него совершенно независимо по сравнению с: "какая у природы цель?"
Потому что из этих рассуждений можно почерпнуть много инженерных идей. Или сюжет для фантастического романа.
Но тогда ответ следует брать какой-то менее тривиальный, чем "сохранение жизни" :)
И, да, если бы вы находились на месте разумного творца — то зачем бы вы сделали миллионы "лишних" галактик? :)
На них тоже есть жизнь. Много разных вариантов жизни.
Ок. Давайте вместо "лишних галактик" будет "лишних систем". Или там тоже жизнь есть по-вашему? :)
Смысл воображения не в том, чтобы получить видео, а чтобы там были отдельные наблюдаемые объекты. Если там один объект "двигающееся изображение", такое воображение ничего не дает.
Например, здесь правильно будет если нейросеть будет распознавать понятия "столбик", "стена", "пространство", характеристики цвет, высота, их различие, сможет представить столбик отдельно от всего остального с разных сторон.
Чтобы у нейросети были информационные элементы, с которыми можно связать все эти слова, поданные на вход текстом. Или в отладчике их выделить каким-нибудь анализатором. Видео здесь скорее дальше чем ближе к тому что требуется.
Эта задача называется object detection
При чем тут object detection вообще?
Насколько я понимаю, object detection это определение классов, причем на конкретном изображении. Я говорю про определение конкретных объектов, и возможность манипулировать ими в дальнейшем без изображения. И самое главное, нейросеть сама должна определять список значимых фич, а не по специальному набору изображений с заранее известным результатом.
«представить себе столбик» означает смоделировать его в сознании как часть некоторого процесса.
Нет. Это означает отдельный объект. Например, вы можете представить этот столбик отдельно на черном фоне, хотя никогда такую картинку не видели. Взаимодействие с другими объектами это отдельное понятие, они выражаются другими словами (обычно глаголами). Неважно, с целью или нет, важно что отдельно. Это и позволяет использовать понятия отдельно от ситуаций, в которых они появились, применять в других, комбинировать, давать названия. На картинке выше сеть объекты не выделяет, она помнит всю картинку целиком.
На картинке выше сеть объекты не выделяет, она помнит всю картинку целиком.
А вы, кстати, в курсе, что «стоять» — это тоже глагол, который тоже выражает действие?
А я не сказал "стоять") Я вообще ни про какое действие не думал. Если подумать, то скорее будет "висеть". Но суть в том, что у меня не было ассоциации ни с каким действием, но при этом я могу представить его в любом действии — стоит, лежит, и т.д.
Неважно, насколько столбик детальный. Тут я например говорю про конкретный зеленый столбик. Нейросеть не может его выделить в памяти отдельно (то есть представить).
А скажите на милость, с чего вы это взяли?
Там это видео приводится как пример воображения, я говорил конкретно о нем.
Это произошло где-то в глубине сети.
В этом и суть. Если это размазано по сети и переплетено с другими параметрами, этим нельзя оперировать, нельзя использовать в другой ситуации, любое изменение окружения может повлиять на распознавание. Отсюда же и adversarial attacks всякие.
В этом и суть. Если это размазано по сети и переплетено с другими параметрами, этим нельзя оперировать, нельзя использовать в другой ситуации
Но когда он залез к нему в мозг
Я же не говорил ничего про отладку, только про поведение самой сети.
Никто не понимает до конца, как устроены нейросети
Так они не до конца и работают как человек.
но и экстраполировать ответ, проявлять ту самую «фантазию»
Я бы не назвал это фантазией, именно потому что сеть не может представить конкретный объект.
А это значит, что она — умеет отделять объекты друг от друга
Или что там ассоциативный массив jpg -> avi.
Смысл воображения не в том, чтобы получить видео, а чтобы там были отдельные наблюдаемые объекты. Если там один объект «двигающееся изображение», такое воображение ничего не дает.
То что мы называем воображением — представляя столбики или сопутствующие обстоятельства — в нейросетях называется вектором контекста.
Подождите, какой такой контекст. Я могу вообразить этот столбик отдельно, поместить его мысленно в другую ситуацию, представить 10 штук в ряд. Это наоборот отделение объекта от контекста, в котором он появился.
После чего простой регрессией из этого общего вектора она может рендерить картинку, выделять отдельные столбики на фото, да что угодно.
Так надо не всю картинку рендерить, как на анимации, а отдельные объекты. Тогда это будет похоже на воображение. Иначе это просто видеокодек, который работает с пикселями.
Если я правильно понимаю, конкретно у этой нейросети нельзя взять часть вектора контекста и отрендерить из него зеленый столбик на темном фоне с разных сторон, который не будет двигаться по экрану как он двигается на полном изображении? Ну, без низкоуровневых хаков типа брать из вывода нейросети ограничивающий прямоугольник.
Вопрос о возможности или невозможности сильного ИИ уже давно не стоит, теперь это лишь вопрос времени.
Согласен, я говорю лишь о технических различиях.
Подождите, какой такой контекст. Я могу вообразить этот столбик отдельно, поместить его мысленно в другую ситуацию, представить 10 штук в ряд.
Возможно, десять в ряд не видели, но видели три в ряд. А дальше — экстраполируете.
Ну и что? Это никак не противоречит моим словам, даже подтверждает. Именно представление объектов по отдельности и дает возможность экстраполировать и комбинировать.
Важно отметить, что скорость действия программы и её область видимости на поле боя были ограничены, чтобы AlphaStar не получила несправедливого преимущества над людьми.
Стоит отметить что все же небольшое преимущество у AlphaStar было — несмотря на то, что туман войны закрывал карту для нейросети так же, как и для человека, программа получала для обработки не частичное изображение известной области (условный экран), а видела сразу все, что позволяет увидеть игра. Благодаря этому нейросети не приходилось постоянно переключаться между разными зонами карты для контроля за происходящим. Когда же для еще одного демонстрационного матча с MaNa разработчики заставили AlphaStar играть с обычным ограничением масштаба видимой области, то нейросеть проиграла человеку. Правда, в DeepMind отмечают, что самостоятельно двигающая камеру версия программы обучалась в «лиге AlphaStar» всего семь дней.
Дезертиры, мораль, погода, это всего лишь дополнительны параметры которые можно оцифровать и работать с ними как с вероятностями. Проблема только в обучении, в реальной жизни обучить сложновато, не хватит людей и русурсов, а вот создать симуляцию боевых действий пусть даже не со всеми возможными параметрами уже даст многократное преимущество перед противником.
пусть даже не со всеми возможными параметрами
Дезертиры, мораль, погода, это всего лишь дополнительны параметры которые можно оцифровать и работать с ними как с вероятностями.
Если вы это сделаете, то сможете легко выиграть любую войну и без ИИ.
Танки сейчас тоже скорее для красоты, уничтожаются на счет раз с ПТРК
Для этого он поиграет еще недельку и будет на том же уровне, что и с картой.
У калькулятора тоже превосходство в вычислениях, это ничего не означает.
Вот что сам MaNa пишет на реддите, когда его спросили, чем бот был лучше/хуже человека:
I would say that clearly the best aspect of its game is the unit control. In all of the games when we had a similar unit count, AlphaStar came victorious. The worst aspect from the few games that we were able to play was its stubbornness to tech up. It was so convinced to win with basic units that it barely made anything else and eventually in the exhibition match that did not work out. There weren’t many crucial decision making moments so I would say its mechanics were the reason for victory.
То есть, бот тупо рашил базовыми юнитами не особо заботясь о стратегии, и это работало. В этом нет никакой особой интеллектуальности, тупо победа за счет лучшей механики микроконтроля.
Это как называть бота в Counter-Strike прорывом в ИИ и скачком вперёд, потому что он хедшоты делает со 100% точностью. "The goal is to create artificial intelligence, not artificial aiming"
Есть лишь один вопрос. Почему до вчерашеного дня никому и никогда не удавалось создать бота для Старкрафт который бы победил человека даже имея неорганиченыц АПМ и скрипты для микроконтроля?
Потому что со всем остальным (кроме бешеного APM) у тех ботов было совсем плохо, они были слишком «запрограммированные» и негибкие, что позволяло легко найти брешь в их алгоритме и нагнуть их.
Но при наличии минимального интеллекта у игрока (что DeepMind вполне себе демонстрирует), сверхчеловеческое микро уже не «контрится» — тонкий игровой баланс Старкрафта на такое просто не рассчитан.
Человек однозначно проиграет в этой борьбе, тут даже никаких вопросов нет.
Я удивляюсь комментаторам которые пытаются доказать, что ИИ в чём-то вёл себя «нечестно». Да ребят, ему не нужно нажимать на клавиши, смиритесь.
Смотрите. Если вы на бнете будете микрить сталкерами как АльфаСтар, то вас забанят ;)
Мана входит в 10ку лучших игроков-протосов планеты, поверьте, на своё обучение он потратил гораздо больше времени чем этот ИИ.
А если в количестве игр посчитать?
Уточнение: ИИ не видел скрытые туманом войны области. Он просто видел карту разом. Как играть на растянутой миникарте.
Во многом согласен, но разные агенты это, объективно, плюс в копилку AlphaStar.
Пока мир не может сделать одного бота чтобы побороть прогеймеров, ребята одновременно сделали 5 разных, со стабильно хорошими результатами.
Адаптироваться на лету к разным противникам это как люди выигрывают на ладдере, турнирах и становятся прогеймерами.
Просто если бы они выставили адекватное ограничение APM (думаю они пытались), то игроки-люди разделали бы бота под орех, и никакой красивой презентации для инвесторов не вышло бы. А у них дедлайны, надо что-то показать.
Вот тут AMA на reddit с разработчиками, и там выясняется что лимитер APM был настроен так, что даже (теоретически) допускались кратковременные burst'ы под 2500 APM (на практике мы видели 1500 в боях), что конечно полный бред, ни один человек никогда так не сможет кликать — чисто физически эффективный APM не может быть выше 200-300, все что выше это бессмысленные «раскликивания», возможно даже с помощью макросов клавиатурных. Причем бот кликает с суперточностью, ему не надо рамкой выделять юнитов и елозить курсором, он может суперточно выбрать любой набор юнитов в любых местах карты одновременно — ему даже и камерой не нужно было елозить, он играл с «зумхаком» все игры кроме последней (где он позорно слился). Это профанация полная, рассчитанная то чтобы впечатлить и убедить тех, кто в SC никогда не играл. Манипулирование числами и статистикой (это я про их «средний APM даже ниже чем у игроков-людей» и красивые графики распределений, где сравниваются яблоки и апельсины).
У ИИ есть спам
Только в тех ситуациях, когда APM больше «не на что» было потратить эффективно, т.е. не в моментах интенсивных стычек. Этому AI научился у людей, так как первую версию обучали на реплеях, перед тем как она начала играть сама с собой. Но поскольку это не влияло на винрейт, ИИ «не смог забыть» эту привычку. А вот в критические моменты он тратил свой APM очень эффективно, так как это влияло на винрейт при обучении.
Этот график — профанация и притягивание за уши… Какой нафиг APM в 2000 у человека, и какая разница какой APM «средний» если важно то, какой он пиковый в критические моменты игры, и какой процент полезных действий в этом APM, ведь большая часть человеческого APM это спам-клики и перемещение камеры, при том что боту же даже камеру перемещать не надо было.
Вот очень хороший пост в /r/MachineLearning где все четко расставляют по полочкам:
> Поэтому возможно в 2-3 раза выше эффективный апм,
Но в Старкрафте это гигантское преимущество и полностью меняет игру, при в 2-3 раза большем APM чем у топовых прогеймеров, оптимальным стилем игры становится массить блинк сталкеров и давить ими c трех сторон одновременно. В Старкрафте в балансе многое рассчитано на то, что идеальный контроль у человека невозможен, и баланс старкрафта во многом про искусство эффективного менеджмента ограниченного количества действий в секунду. Если его не ограничивать, то игра просто теряет смысл.
"Он не учится в процессе игры, прилетел дроп, и AI продолжал гоняться за ним пока не проиграл."
Чисто технически это можно сделать, нет проблем. Проблема в необходимости огромного количества материала для обучения.
В десяти играх машина успешно предсказывала поведение игрока, делала контры
Действительно, общеизвестно же, что сталкеры — это контра имморталам!
В подтверждение моих слов уточню: если бы она в первых десяти играх не могла прогнозировать (а это ей приходилось делать ибо юниты противника она и там не видела), то что же тот же MaNa не размазал ее таким же (или сходным) очевидным способом?
Потому что нейронные сети не умеют прогнозировать. Альфазеро не прогнозирует, что будет строить противник, это не человек. Она не рассуждает. Она просто знает, что, статистически, если в момент Х строить юнита Y и потом отсылать его в Z — вероятность победы выше.
{kind=link}
{kind=link}
Нейросеть AlphaStar обыграла профессионалов StarCraft II со счётом 10−1