 Элементы на веб-страницах, в основном, располагаются бок о бок или друг под другом. Но иногда дизайн требует перекрытия элементов. Например, выпадающее меню навигации, панели предварительного просмотра при наведении курсора, бесполезные баннеры о куках и, конечно, бесчисленные всплывающие окна, требующие вашего немедленного внимания.
Элементы на веб-страницах, в основном, располагаются бок о бок или друг под другом. Но иногда дизайн требует перекрытия элементов. Например, выпадающее меню навигации, панели предварительного просмотра при наведении курсора, бесполезные баннеры о куках и, конечно, бесчисленные всплывающие окна, требующие вашего немедленного внимания.В этих ситуациях браузер должен как-то решить, какие элементы показывать «сверху», а какие элементы держать в фоновом режиме, полностью или частично закрытыми. Относительно сложный набор правил в стандарте CSS определяет порядок наложения по умолчанию для каждого элемента страницы (наверное, всё в мире можно назвать «относительно сложным», но сразу настораживает, что стандарт поставляется со специальным приложением, озаглавленным «Подробное описание контекстов наложения»).
Если дефолтный порядок не устраивает, то разработчики прибегают к свойству
z-index: оно даёт контроль над виртуальной осью z (глубиной), которая концептуально проходит «сквозь» страницу. Таким образом, элемент с более высоким z-index отображается «ближе» к пользователю, то есть рисуется поверх элементов с более низкими индексами.Интересное свойство оси
z заключается в том, что у неё нет естественных границ. Горизонтальная и вертикальная оси обычно ограничены ожидаемыми размерами дисплея. Мы не ожидаем, что какие-либо элементы будут рахмещаться на «1000000px слева» или «-3000em сверху»: они либо станут невидимы, либо вызовут неприятную прокрутку. (Если только вы не читаете эту статью в то время, когда повсюду дисплеи шириной в миллионы пикселей. Если это так, призываю вас прекратить чтение и запустить проект веб-страницы на триллион долларов).А вот значения
z-index являются безразмерными и имеют значение только в относительном выражении: страница с двумя элементами будет выглядеть одинаково, если индексы z равны 1 и 2 или −10 и 999. В сочетании с тем, что страницы часто собираются из компонентов, разработанных изолированно, это приводит к любопытному искусству выбора соответствующих z-индексов.Как гарантировать, что ваше раздражающее всплывающее окно точно отобразится поверх всех элементов на странице, если вы не знаете, сколько их, кто их написал, и насколько они хотели быть наверху? Вот тогда вы и поставите свой z-индекс на 100, или, может быть, 999, или, может быть, чисто на всякий случай, на 99999, чтобы гарантировать, что ваш точно выиграет.
По крайней мере, так я пишу свой CSS. В остальной части этого поста мы рассмотрим миллионы z-индексов и посмотрим, что делают остальные веб-разработчики.
Получение данных
Первым шагом стал сбор большого набора значений z-индексов из существующих веб-страниц. Для этого я обратился к Common Crawl, общедоступному, очень большому и замечательному хранилищу страниц из интернета. Данные размещаются на S3, так что можно достаточно эффективно запрашивать их из кластера AWS. К счастью, в интернете есть несколько учебных пособий, показывающих, как это сделать.
Мой сложный экстрактор z-индексов включает поиск на каждой странице всех совпадений следующего регулярного выражения:
re.compile(b'z-index *: *(-?[0-9]+|auto|inherit|initial|unset)')
Как только значения определены, остаётся стандартная задача map-reduce для количества вхождений. К счастью, я не первый, кто захотел подсчитать вхождения всяких вещей в выборке, и этого было достаточно, чтобы адаптировать один из многих примеров. (Почти весь мой личный код — это регулярное выражение вверху).
Благодаря очень подробной статье в блоге мне удалось развернуть код на кластере Elastic Map Reduce, и я приступил к сканированию архива страниц за март 2019 года. Этот конкретный архив разбит на 56 000 частей, из которых я наугад выбрал 2500, или около 4,4%. В этом числе нет ничего особенного, кроме того, что оно примерно переводится в цену, которую я был готов инвестировать в этот эксперимент. После ужасной ночи в надежде, что я неправильно сделал прогнозы, я получил результаты, извлечённые из 112,7 млн страниц. (Должен отметить, что всё это HTML-страницы. Я не слишком углублялся в этот вопрос, но похоже, что Common Crawl не индексирует внешние таблицы стилей, и в результате я извлекаю значения только из встроенных CSS. Оставлю в качестве упражнения для читателя определить, соответствует ли полученное распределение тому, что вы получите из внешних таблиц стилей).
Самые распространённые значения
Моё сканирование дало в общей сложности около 176,5 млн значений z-индекса, из них 36,2 тыс. уникальных.
Итак, каковы самые распространённые?
На рисунке показан топ-50. Обратите внимание, что ось y логарифмическая и показывает относительные частоты. Например, наиболее распространённое значение 1 составляет 14,6% всех вхождений, найденных в выборке. В целом топ-50 составляет около всех 80% собранных значений.

Первое наблюдение состоит в том, что доминируют положительные значения. Единственный отрицательный элемент в топ-50 — это
−1 (второй по распространённости −2 занимает 70-е место). Возможно, это говорит нам, что люди обычно более заинтересованы в том, чтобы вывести вещи наверх, чем спрятать их в фоне.Как правило, у большинства топовых значений есть одно из следующих свойств:
- Они малы: например, все числа от 0 до 12 находятся в топ-50.
- Это степени десяти или кратные числа: 10, 100, 1000, 2000, …
- Они «близки» к степени десяти: 1001, 999, 10001, …
Эти закономерности согласуются с тем, что люди выбирают большие «знакомые» значения (степени десяти), а затем, возможно, для регулировки относительной глубины внутри компонента — значения немного выше или ниже.
Также интересно посмотреть на самые распространённые значения, которые не вписываются ни в один из этих шаблонов:
На 36-м месте мы видим 2147483647. Это число многие программисты сразу распознают как
INT_MAX, то есть 231−1. Наверное, люди рассуждают так: поскольку это самое большое значение для (знакового) целого, никакой z-индекс не окажется выше, поэтому мой элемент с индексом INT_MAX всегда будет наверху. Однако, MDN говорит следующее о целых числах в CSS:Не существует официального диапазона значений типа <integer>. Opera 12.1 поддерживает значения до 215-1, IE — до 220-1, а остальные браузеры даже выше. На протяжении существования значений CSS3 было проведено несколько обсуждений об установлении минимально поддерживаемого диапазона: последнее решение приняли в апреле 2012 на время фазы LC, тогда был принят диапазон [-227-1; 227-1], но были предложены и другие значения, такие как 224-1 и 230-1. Однако, самая свежая на данный момент спецификация более не указывает на область определения этого типа данных.Таким образом, не только нет согласованного максимального значения, но и в каждой документированной спецификации или стандартном предложении
INT_MAX фактически находится вне диапазона.На 39-м месте у нас 8675309, в котором лично я не увидел ничего примечательного. Но для более полумиллиона разработчиков, очевидно, оно имеет смысл. Я подозреваю, что вы либо мгновенно узнаете это число, либо совершенно не поймёте его смысл, в зависимости от того, где и когда вы выросли. Не буду выдавать спойлеров, ответ скрывается всего за одним поиском.
Последние два числа, которые казались немного неуместными, — это 1030 и 1050, на 42-м и 45-м местах, соответственно. Ещё один беглый поиск показал, что это значения z-индекса по умолчанию для классов
navbar-fixed и modal в Bootstrap.Распределение значений
Хотя подавляющее большинство всех значений
z-index приходится на небольшое количество вариантов, может быть интересно взглянуть на более широкое распределение собранного набора. Например, на рисунке 2 показана частота всех значений между -120 и 260.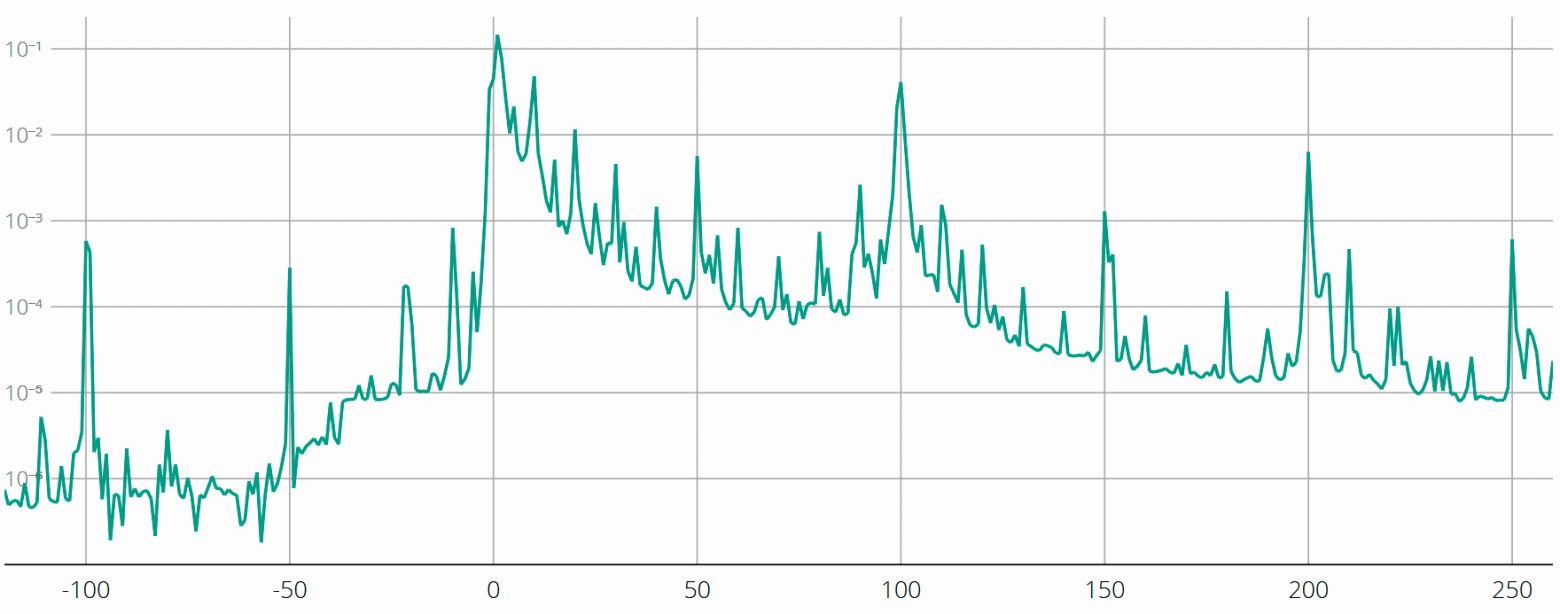
Кроме доминирования круглых чисел, мы видим почти фрактальное качество узоров на нескольких уровнях. Например, середина между двумя локальными максимумами часто сама является (меньшим) локальным максимумом: это 5 между 1 и 10, 15 между 10 и 20, 50 между 1 и 100, и т. д.
Мы можем подтвердить этот эффект и на более широком диапазоне: на следующем рисунке показаны частоты всех значений от -1200 до 2600, с округлением к меньшему по модулю до десяти, то есть числа вроде 356 и 359 засчитывались как 350. График очень похож на предыдущий. Как видим, структура в основном сохраняется при рассмотрении значений на порядок больше.

Наконец, на последней иллюстрации все положительные значения
z-index от 1 до 9999999999 сгруппированы по первой цифре (горизонтальная ось) и количеству цифр (вертикальная ось).
Положительные значения
z-index, сгруппированные по первой цифре и количеству цифр. Размеры пропорциональны общей частоте группы. Нажмите на группу для получения дополнительной информацииМы можем интуитивно представить каждую группу как шаблон значений, например,
3xxx для всех четырёхзначных значений, начинающихся с 3. Каждая группа отображается в виде прямоугольника, размер которого пропорционален частоте паттерна. На рисунке показано, например, что для каждого порядка величины, т. е. ряда групп, частоты следуют аналогичной тенденции, причём значения, начиная с 1, являются наиболее распространёнными, затем 9, затем 5.Оттенок каждой группы устанавливается на основе её энтропии. У жёлтых групп самая высокая энтропия, а у синих — самая низкая. Это помогает выделить шаблоны, где разработчики, как правило, выбирают одни и те же значения, или те, где значения распределяются более равномерно (обратите внимание, что энтропия всего нашего набора данных составляет 6,51 бит).
Заключение
Хотя было определённо интересно собирать и исследовать этот набор данных, я уверен, что есть лучшая статистика, визуализации и объяснения, ожидающие добычи и представления. Если хотите попробовать, не стесняйтесь загружать и распространять файл z-index-data.csv.
Возможно, вы преуспеете там, где я потерпел неудачу, и найдёте способ включить в график наибольшее значение
z-index, которое я нашёл, а именно 101242-1.Да, то число 9 повторяется 1242 раза. Очень надеюсь, что они, наконец, смогли показать свой <div> наверху.

