Продолжаем рассказ о создании мульти-парадигменного языка программирования, поддерживающего декларативный логический стиль для описания модели предметной области. Прошлые публикации находятся здесь и здесь. Теперь пришло время для описания основных особенностей и требований к языку описания модели предметной области. Но для начала сделаем небольшой обзор наиболее популярных языков представления знаний. Это довольно обширная область, имеющая давнюю историю и включающая ряд направлений — логическое программирование, реляционное исчисление, технологии семантической паутины, фреймовые языки. Я хочу сравнить такие языки как Prolog, SQL, RDF, SPARQL, OWL и Flora, выделить те их особенности, которые были бы полезны в проектируемом мульти-парадигменном языке программирования.
Начнем с логического программирования и языка Prolog. Знания о предметной области представляются в нем в виде набора фактов и правил. Факты описывают непосредственные знания. Факты о клиентах (идентификатор, имя и адрес электронной почты) и счетах (идентификатор счета, клиента, дата, сумма к оплате и оплаченная сумма) из примера из прошлой публикации будут выглядеть следующим образом
Правила описывают абстрактные знания, которые можно вывести из других правил и фактов. Правило состоит из головы и тела. В голове правила нужно задать его имя и список аргументов. Тело правила представляет собой список предикатов, соединенных логическими операциями AND (задается запятой) и OR (задается точкой с запятой). Предикатами могут служить факты, правила или встроенные предикаты, такие как операции сравнения, арифметические операции и др. Связь между аргументами головы правила и аргументами предикатов в его теле задается с помощью логических переменных — если одна и та же переменная стоит на позициях двух разных аргументов, то значит, что эти аргументы идентичны. Правило считается истинным тогда, когда истинно логическое выражение тела правила. Модель предметной области можно задать в виде набора ссылающихся друг на друга правил:
Мы задали два правила. В первом мы утверждаем, что все счета, у которых сумма к оплате меньше оплаченной суммы, являются неоплаченными счетами. Во втором, что должником является клиент, у которого есть хотя бы один неоплаченный счет.
Синтаксис Prolog очень простой: основной элемент программы — правило, основные элементы правила — это предикаты, логические операции и переменные. В правиле внимание сфокусированно на переменных — они играют роль объекта моделируемого мира, а предикаты описывают их свойства и отношения между ними. В определении правила debtor мы утверждаем, что если объекты ClientId, Name и Email связанны отношениями client и unpaidBill, то они также будут связаны и отношением debtor. Prolog удобен в тех случаях, когда задача сформулирована в виде набора правил, утверждений или логических высказываний. Например, при работе с грамматикой естественного языка, компиляторами, в экспертных системах, при анализе сложных систем, таких как вычислительная техника, компьютерные сети, объекты инфраструктуры. Сложные, запутанные системы правил лучше описать в явном виде и предоставить среде исполнения Prolog разбираться с ними автоматически.
Prolog основан на логике первого порядка (с включением некоторых элементов логики высшего порядка). Логический вывод выполняется с помощью процедуры, называемой SLD резолюция (Selective Linear Definite clause resolution). Упрощенно ее алгоритм представляет собой обход дерева всех возможных решений. Процедура вывода находит все решения для первого предиката тела правила. Если текущий предикат в базе знаний представлен только фактами, то решениями являются те из них, которые соответствуют текущим привязкам переменных к значениям. Если правилами — то потребуется рекурсивная проверка их вложенных предикатов. Если решений не найдено, то текущая ветвь поиска завершается неудачей. Затем для каждого найденного частичного решения создается новая ветвь. В каждой ветви процедура логического вывода выполняет привязку найденных значений к переменным, входящим в состав текущего предиката, и рекурсивно выполняет поиск решения для оставшегося списка предикатов. Работа завершается, если достигнут конец списка предикатов. Поиск решения может войти в бесконечный цикл в случае рекурсивного определения правил. Результатом работы процедуры поиска является список всех возможных привязок значений к логическим переменным.
В примере выше для правила debtor правило резолюции сначала найдет одно решение для предиката client и свяжет его с логическими переменными: ClientId = 1, Name = «John», Email = «john@somewhere.net». Затем для этого варианта значений переменных будет выполнен поиск решения для следующего предиката unpaidBill. Для этого потребуется сначала найти решения для предиката bill при условии, что ClientId = 1. Результатом будут привязки для переменных BillId = 1, Date = «2020-01», AmoutToPay = 100, AmountPaid = 50. В конце будет выполнена проверка AmoutToPay < AmountPaid во встроенном предикате сравнения.
Одним из наиболее популярных способов представления знаний являются семантические сети. Семантическая сеть представляет собой информационную модель предметной области в виде ориентированного графа. Вершины графа соответствуют понятиям предметной области, а дуги задают отношения между ними.
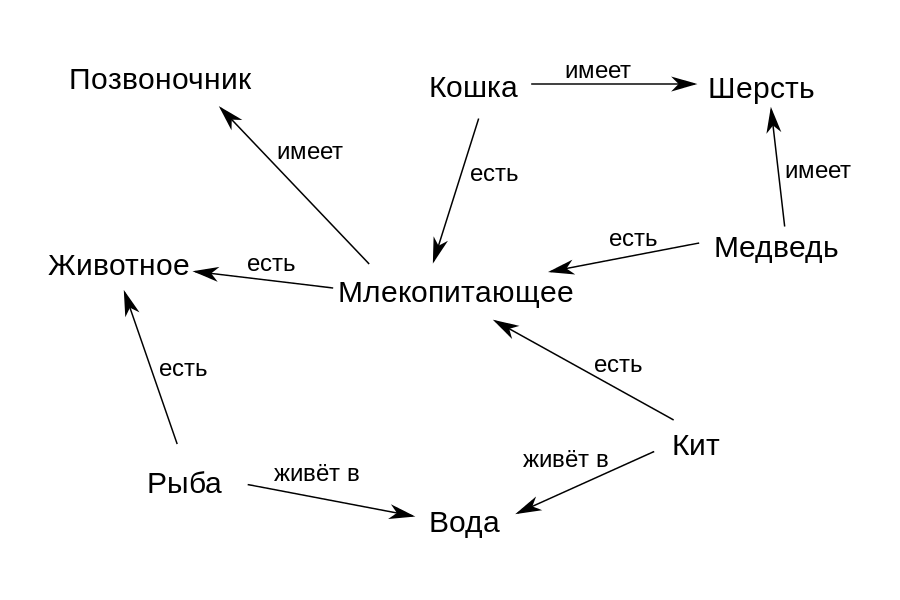
Например, согласно графу на рисунке выше понятие «Кит» связано отношением «есть» («является») с понятием «Млекопитающее» и «живет в» с понятием «Вода». Таким образом мы можем формальным образом задать структуру предметной области — какие понятия она включает и как они между собой связаны. А дальше такой граф можно использовать для поиска ответов на вопросы и вывода из него новых знаний. Например, мы можем вывести знание о том, что «Кит» «имеет» «Позвоночник», если решим, что отношение «есть» обозначает отношение класс-подкласс, и подкласс «Кит» должен наследовать все свойства своего класса «Млекопитающее».
Семантическая паутина (semantic web) — это попытка построить глобальную семантическую сеть на базе ресурсов Всемирной паутины путём стандартизации представления информации в виде, пригодном для машинной обработки. Для этого в HTML-страницы дополнительно закладывается информация в виде специальных атрибутов HTML тэгов, которая позволяет описать смысл их содержимого в виде онтологии — набора фактов, абстрактных понятий и отношений между ними.
Стандартным подходом для описания семантической модели WEB ресурсов является RDF (Resource Description Framework или Среда Описания Ресурсов). Согласно ней все утверждения должны иметь форму триплета «субъект — предикат — объект». Например, знания о понятии «Кит» будут представлены следующим образом: «Кит» является субъектом, «живет в» — предикатом, «Вода» — объектом. Весь набор таких утверждений можно описать с помощью ориентированного графа, субъекты и объекты являются его вершинами, а предикаты — дугами, дуги предикатов направлены от объектов к субъектам. Например, онтологию из примера с животными можно описать в следующем виде:
Такая форма записи называется Turtle, она предназначена для чтения человеком. Но то же самое можно записать и в XML, JSON форматах или с помощью тэгов и атрибутов HTML документа. Хоть в Turtle нотации предикаты и объекты можно сгруппировать вместе по субъектам для удобства чтения, но на семантическом уровне каждый триплет независим.
RDF удобен в тех случаях, когда модель данных сложна и содержит большое количество типов объектов и связей между ними. Например, Wikipedia предоставляет доступ к содержимому своих статей в RDF формате. Факты, описанные в статьях структурированы, описаны их свойства и взаимные отношения, включая факты из других статей.
RDF модель представляет собой граф, по умолчанию никакой дополнительной семантики в нем не заложено. Каждый может интерпретировать заложенные в графе связи как посчитает нужным. Добавить в него некоторые стандартные связи можно с помощью RDF Schema — набора классов и свойств для построения онтологий поверх RDF. RDFS позволяет описать стандартные отношения между понятиями, такие как принадлежность ресурса некоторому классу, иерархию между классами, иерархию свойств, ограничить возможные типы субъекта и объекта.
Например, утверждение
задает, что «Млекопитающее» является подклассом понятия «Животное» и наследует все его свойства. Соответственно, понятие «Кит» также можно отнести к классу «Животное». Но для этого нужно указать, что понятия «Млекопитающее» и «Животное» являются классами:
Так же предикату можно задать ограничения на возможные значения его субъекта и объекта.
Утверждение
указывает, что объектом отношения «живет в» всегда должен быть ресурс, относящийся к классу «Окружающая среда». Поэтому мы должны добавить утверждение о том, что понятие «Вода» является подклассом понятия «Окружающая среда»:
RDFS позволяет описать схему данных — перечислить классы, свойства, задать их иерархию и ограничения их значений. А RDF – наполнить эту схему конкретными фактами и задать отношения между ними. Теперь мы можем задать вопрос к этому графу. Сделать это можно на специальном языке запросов SPARQL, напоминающем SQL:
Этот запрос вернет нам 2 значения: «Whale» и «Fish».
Пример из предыдущих публикаций со счетами и клиентами можно реализовать приблизительно следующим образом. С помощью RDF можно описать схему данных и наполнить ее значениями:
Но вот абстрактные понятия, такие как «Должник» и «Неоплаченные счета» из первой статьи этого цикла, включают в себя арифметические операции и сравнение. Они не вписываются в статичную структуру семантической сети понятий. Эти понятия можно выразить с помощью SPARQL запросов:
Секция WHERE представляет собой список шаблонов триплетов и условий фильтрации. В триплеты можно подставлять логические переменные, имя которых начинается с символа "?". Задача исполнителя запроса — найти все возможные значения переменных, при которых все шаблоны триплетов содержались бы в графе и выполнялись условия фильтрации.
В отличии от Prolog, где на основе правил можно конструировать другие правила, в RDF запрос не является частью семантической сети. На запрос нельзя ссылаться как на источник данных для другого запроса. Правда у SPARQL есть возможность представить результаты запроса в виде графа. Так что можно попробовать объединить результаты запроса с исходным графом и новый запрос выполнить на объединенном графе. Но такое решение будет явно выходить за рамки идеологии RDF.
Важным компонентом технологий семантической паутины является OWL (Web Ontology Language) – язык описания онтологий. С помощью словаря RDFS можно выразить только самые базовые отношения между понятиями — иерархию классов и отношений. OWL предлагает гораздо более богатый словарь. Например, можно задать, что два класса (или две сущности) являются эквивалентными (или различными). Такая задача часто встречается при объединении онтологий.
Можно создавать составные классы на основе пересечения, объединения или дополнения других классов:
Такие выражения, позволяющие связать понятия между собой, называются конструкторами.
OWL также позволяет задавать многие важные свойства отношений:
Так же можно задать ограничения на значения аргументов отношений. Например, указать, что аргументы должны всегда принадлежать определенному классу, или что у класса должно быть как минимум одно отношение заданного типа, или ограничить для него количество отношений такого типа. Или указать, что к определенному классу относятся все экземпляры, которые связаны заданным отношением с заданным значением.
Сейчас OWL является фактически стандартным средством для построения онтологий. Этот язык лучше подходит для построения больших и сложных онтологий чем RDFS. Синтаксис OWL позволяет выразить больше разных свойств понятий и отношений между ними. Но и вводит ряд дополнительных ограничений, например, одно и то же понятие нельзя одновременно объявить и как класс и как экземпляр другого класса. Онтологии в OWL жестче, более стандартизированы и, соответственно, более читабельны. Если RDFS это всего лишь несколько дополнительных классов поверх RDF графа, то OWL имеет другую математическую основу — дескрипционную логику. Соответственно, становятся доступны и формальные процедуры логического вывода, позволяющие извлекать новую информацию из OWL онтологий, проверять их согласованность и отвечать на вопросы.
Дескрипционная или описательная логика (descriptive logic) является фрагментом логики первого порядка. В ней допустимы только одноместные (например, принадлежность понятия к классу), двухместные предикаты (наличие у понятия свойства и его значения), а также конструкторы классов и свойства отношений, перечисленные выше. Все остальные выражения логики первого порядка в дескрипционной логике отброшены. Например, допустимыми будут утверждения, что понятие «Неоплаченный счет» относится к классу «Счет», понятие «Счет» имеет свойства «Сумма к оплате» и «Оплаченная сумма». Но вот сделать утверждение, что у понятия «Неоплаченный счет» свойство «Сумма к оплате» должно быть больше свойства «Оплаченная сумма» уже не получится. Для этого понадобится правило, которое будет включать предикат сравнения этих свойств. К сожалению, конструкторы OWL не позволяют сделать это.
Таким образом, выразительность дискрипционной логики ниже, чем у логики первого порядка. Но, с другой стороны, алгоритмы логического вывода в дескрипционной логике гораздо быстрее. Кроме того, она обладает свойством разрешимости — решение гарантированно может быть найдено за конечное время. Считается, что на практике такого словаря вполне достаточно для построения сложных и объемных онтологий, и OWL – это хороший компромисс между выразительностью и эффективностью логического вывода.
Также стоит упомянуть SWRL (Semantic Web Rule Language), который сочетает возможность создания классов и свойств в OWL с написанием правил на ограниченной версии языка Datalog. Стиль таких правил такой же, как и в языке Prolog. SWRL поддерживает встроенные предикаты для сравнения, математических операций, работы со строками, датами и списками. Это как раз то, чего нам не хватало для того, чтобы с помощью одного простого выражения реализовать понятие «Неоплаченный счет».
В качестве альтернативы семантическим сетям рассмотрим также такую технологию как фреймы. Фрейм — это структура, описывающая сложный объект, абстрактный образ, модель чего-либо. Он состоит из названия, набора свойств (характеристик) и их значений. Значением свойства может быть другой фрейм. Также у свойства может быть значение по умолчанию. К свойству может быть привязана функция вычисления его значения. В состав фрейма также могут входить служебные процедуры, в том числе обработчики таких событий так создание, удаление фрейма, изменение значения свойств и др. Важным свойством фреймов является возможность наследования. Дочерний фрейм включает в себя все свойства родительских фреймов.
Система связанных фреймов формирует семантическую сеть, очень похожую на RDF граф. Но в задачах создания онтологий фреймы были вытеснены языком OWL, который сейчас является фактическим стандартом. OWL более выразителен, имеет более продвинутое теоретическое основание — формальную дискрипционную логику. В отличии от RDF и OWL, в которых свойства понятий описываются независимо друг от друга, в фреймовой модели понятие и его свойства рассматриваются как единой целое — фрейм. Если в моделях RDF и OWL в вершинах графа находятся имена понятий, а в ребрах — их свойства, то во фреймовой модели в вершинах графа расположены понятия со всеми их свойствами, а в ребрах — связи между их свойствами или отношения наследования между понятиями.
В этом фреймовая модель очень близка модели объектно-ориентированного программирования. Они во многом совпадают, но имеют разную сферу применения — фреймы направлены на моделирование сети понятий и отношений между ними, а ООП — на моделирование поведения объектов, их взаимодействия между собой. Поэтому в ООП доступны дополнительные механизмы скрытия деталей реализации одного компонента от других, ограничения доступа к методам и полям класса.
Современные фреймовые языки (такие как KL-ONE, PowerLoom, Flora-2) комбинируют составные типы данных объектной модели с логикой первого порядка. В этих языках можно не только описывать структуру объектов, но и оперировать этими объектами в правилах, создавать правила, описывающие условия принадлежности объекта заданному классу и т.д. Механизмы наследования и композиции классов получают логическую трактовку, которая становится доступна для использования процедурам логического вывода. Выразительность этих языков выше, чем у OWL, они не ограничены двухместными предикатами.
В качестве примера попробуем реализовать наш пример с должниками на языке Flora-2. Этот язык включает в себя 3 компонента: фреймовую логику F-logic, объединяющую фреймы и логику первого порядка, логику высших порядков HiLog, предоставляющую инструменты для формирования высказываний о структуре других высказываний и мета-программирования, и логику изменений Transactional Logic, позволяющую в логической форме описывать изменения в данных и побочные эффекты (side effects) вычислений. Сейчас нас интересует только фреймовая логика F-logic. Для начала с ее помощью объявим структуру фреймов, описывающих понятия (классы) клиентов и должников:
Теперь мы можем объявить экземпляры (объекты) этих понятий:
Символ '->' означает связь атрибута с конкретным значением у объекта и значение по умолчанию в объявлении класса. В нашем примере поле amountPaid класса bill имеет нулевое значение по умолчанию. Символ ':' означает создание сущности класса: client1 и client2 являются сущностями класса client.
Теперь мы можем объявить, что понятия «Неоплаченный счет» и «Должник» являются подклассами понятий «Счет» и «Клиент»:
Символ '::' объявляет отношение наследования между классами. Наследуется структура класса, методы и значения по умолчанию для всех его полей. Осталось объявить правила, задающие принадлежность к классам unpaidBill и debtor:
В первом высказывании утверждается, что переменная
Получить список должников можно с помощью запроса:
Мы просим найти все значения, относящиеся к классу debtor. Результатом будет список всех возможных значений переменной
Фреймовая логика сочетает в себе наглядность объектно-ориентированной модели с мощью логического программирования. Она будет удобна при работе с базами данных, моделировании сложных систем, интеграции разрозненных данных — в тех случаях, где нужно сделать акцент на структуре понятий.
Напоследок рассмотрим основные особенности синтаксиса SQL. В прошлой публикации мы говорили, что SQL имеет логическую теоретическую основу — реляционное исчисление, и рассмотрели реализацию примера с должниками на LINQ. В плане семантики SQL близок к фреймовым языкам и ООП модели — в реляционной модели данных основным элементом является таблица, которая воспринимается как единое целое, а не как набор отдельных свойств.
Синтаксис SQL прекрасно соответствует такой ориентации на таблицы. Запрос разбит на секции. Сущности модели, которые представлены таблицами, представлениями (view) и вложенными запросами, вынесены в секцию FROM. Связи между ними указываются с помощью операций JOIN. Зависимости между полями и другие условия находятся в секциях WHERE и HAVING. Вместо логических переменных, связывающих аргументы предикатов, в запросе мы оперируем полями таблиц напрямую. Такой синтаксис описывает структуру модели предметной области более наглядно по сравнению с «линейным» синтаксисом Prolog.
На примере со неоплаченными счетами мы можем сравнить такие подходы как логическое программирование (Prolog), фреймовую логику (Flora-2), технологии семантической паутины (RDFS, OWL и SWRL) и реляционное исчисление (SQL). Их основные характеристики я свел в таблицу:
Теперь нужно подобрать математическую основу и стиль синтаксиса для языка моделирования, предназначенного для работы со слабоструктурированными данными и интеграцией данных из разрозненных источников, который бы сочетался с объектно-ориентированными и функциональными языками программирования общего назначения.
Наиболее выразительными языками является Prolog и Flora-2 — они основаны на полной логике первого порядка с элементами логики высших порядков. Остальные подходы являются ее подмножествами. За исключением RDFS — он вообще не связан с формальной логикой. На данном этапе полноценная логика первого порядка мне видится предпочтительным вариантом. Для начала я планирую остановиться на нем. Но и ограниченный вариант в виде реляционного исчисления или логики дедуктивных баз данных тоже имеет свои преимущества. Он обеспечивает большую производительность при работе с большими объемами данных. В будущем его стоит рассмотреть отдельно. Дескрипционная логика выглядит слишком ограниченной и неспособной выразить динамические отношения между понятиями.
С моей точки зрения, для работы со слабоструктурированными данными и интеграции разрозненных источников данных фреймовая логика подходит больше, чем Prolog, ориентированный на правила, или OWL, ориентированный на связи и классы понятий. Фреймовая модель описывает структуры из объектов в явном виде, фокусирует на них внимание. В случае объектов с большим количеством свойств фреймовая форма гораздо более читабельна, чем правила или триплеты «субъект-свойство-объект». Наследование также является очень полезным механизмом, позволяющим значительно сократить объем повторяющегося кода. По сравнению с реляционной моделью фреймовая логика позволяет описать сложные структуры данных, такие как деревья и графы, более естественным образом. И, самое главное, близость фреймовой модели описания знаний к модели ООП позволит интегрировать их в одном языке естественным образом.
У SQL я хочу позаимствовать структуру запроса. Определение понятия может иметь сложную форму и его не помешает разбить на секции, чтобы подчеркнуть его составные части и облегчить восприятие. Кроме того, для большинства разработчиков синтаксис SQL довольно привычен.
Итак, за основу языка моделирования я хочу взять фреймовую логику. Но поскольку целью является описание структур данных и интеграция разрозненных источников данных я попробую отказаться от синтаксиса, ориентированного на правила, и заменить его на структурированный вариант, позаимствованный у SQL. Основным элементом модели предметной области будет «понятие» (concept). В его определение я хочу включить всю информацию, необходимую для извлечения его сущностей (entities) из исходных данных:
Определение понятия будет напоминать SQL запрос. А вся модель предметной области будет иметь форму взаимосвязанных понятий.
Получившийся синтаксис языка моделирования я планирую показать в следующей публикации. Для тех, кто хочет познакомиться с ним уже сейчас, есть полный текст в научном стиле на английском языке, доступный по ссылке:
Hybrid Ontology-Oriented Programming for Semi-Structured Data Processing
Ссылки на предыдущие публикации:
Проектируем мульти-парадигменный язык программирования. Часть 1 — Для чего он нужен?
Проектируем мульти-парадигменный язык программирования. Часть 2 — Сравнение построения моделей в PL/SQL, LINQ и GraphQL
Prolog
Начнем с логического программирования и языка Prolog. Знания о предметной области представляются в нем в виде набора фактов и правил. Факты описывают непосредственные знания. Факты о клиентах (идентификатор, имя и адрес электронной почты) и счетах (идентификатор счета, клиента, дата, сумма к оплате и оплаченная сумма) из примера из прошлой публикации будут выглядеть следующим образом
client(1, "John", "john@somewhere.net"). bill(1, 1,"2020-01", 100, 50).
Правила описывают абстрактные знания, которые можно вывести из других правил и фактов. Правило состоит из головы и тела. В голове правила нужно задать его имя и список аргументов. Тело правила представляет собой список предикатов, соединенных логическими операциями AND (задается запятой) и OR (задается точкой с запятой). Предикатами могут служить факты, правила или встроенные предикаты, такие как операции сравнения, арифметические операции и др. Связь между аргументами головы правила и аргументами предикатов в его теле задается с помощью логических переменных — если одна и та же переменная стоит на позициях двух разных аргументов, то значит, что эти аргументы идентичны. Правило считается истинным тогда, когда истинно логическое выражение тела правила. Модель предметной области можно задать в виде набора ссылающихся друг на друга правил:
unpaidBill(BillId, ClientId, Date, AmoutToPay, AmountPaid) :- bill(BillId, ClientId, Date, AmoutToPay, AmountPaid), AmoutToPay < AmountPaid. debtor(ClientId, Name, Email) :- client(ClientId, Name, Email), unpaidBill(BillId, ClientId, _, _, _).
Мы задали два правила. В первом мы утверждаем, что все счета, у которых сумма к оплате меньше оплаченной суммы, являются неоплаченными счетами. Во втором, что должником является клиент, у которого есть хотя бы один неоплаченный счет.
Синтаксис Prolog очень простой: основной элемент программы — правило, основные элементы правила — это предикаты, логические операции и переменные. В правиле внимание сфокусированно на переменных — они играют роль объекта моделируемого мира, а предикаты описывают их свойства и отношения между ними. В определении правила debtor мы утверждаем, что если объекты ClientId, Name и Email связанны отношениями client и unpaidBill, то они также будут связаны и отношением debtor. Prolog удобен в тех случаях, когда задача сформулирована в виде набора правил, утверждений или логических высказываний. Например, при работе с грамматикой естественного языка, компиляторами, в экспертных системах, при анализе сложных систем, таких как вычислительная техника, компьютерные сети, объекты инфраструктуры. Сложные, запутанные системы правил лучше описать в явном виде и предоставить среде исполнения Prolog разбираться с ними автоматически.
Prolog основан на логике первого порядка (с включением некоторых элементов логики высшего порядка). Логический вывод выполняется с помощью процедуры, называемой SLD резолюция (Selective Linear Definite clause resolution). Упрощенно ее алгоритм представляет собой обход дерева всех возможных решений. Процедура вывода находит все решения для первого предиката тела правила. Если текущий предикат в базе знаний представлен только фактами, то решениями являются те из них, которые соответствуют текущим привязкам переменных к значениям. Если правилами — то потребуется рекурсивная проверка их вложенных предикатов. Если решений не найдено, то текущая ветвь поиска завершается неудачей. Затем для каждого найденного частичного решения создается новая ветвь. В каждой ветви процедура логического вывода выполняет привязку найденных значений к переменным, входящим в состав текущего предиката, и рекурсивно выполняет поиск решения для оставшегося списка предикатов. Работа завершается, если достигнут конец списка предикатов. Поиск решения может войти в бесконечный цикл в случае рекурсивного определения правил. Результатом работы процедуры поиска является список всех возможных привязок значений к логическим переменным.
В примере выше для правила debtor правило резолюции сначала найдет одно решение для предиката client и свяжет его с логическими переменными: ClientId = 1, Name = «John», Email = «john@somewhere.net». Затем для этого варианта значений переменных будет выполнен поиск решения для следующего предиката unpaidBill. Для этого потребуется сначала найти решения для предиката bill при условии, что ClientId = 1. Результатом будут привязки для переменных BillId = 1, Date = «2020-01», AmoutToPay = 100, AmountPaid = 50. В конце будет выполнена проверка AmoutToPay < AmountPaid во встроенном предикате сравнения.
Семантические сети
Одним из наиболее популярных способов представления знаний являются семантические сети. Семантическая сеть представляет собой информационную модель предметной области в виде ориентированного графа. Вершины графа соответствуют понятиям предметной области, а дуги задают отношения между ними.
Например, согласно графу на рисунке выше понятие «Кит» связано отношением «есть» («является») с понятием «Млекопитающее» и «живет в» с понятием «Вода». Таким образом мы можем формальным образом задать структуру предметной области — какие понятия она включает и как они между собой связаны. А дальше такой граф можно использовать для поиска ответов на вопросы и вывода из него новых знаний. Например, мы можем вывести знание о том, что «Кит» «имеет» «Позвоночник», если решим, что отношение «есть» обозначает отношение класс-подкласс, и подкласс «Кит» должен наследовать все свойства своего класса «Млекопитающее».
RDF
Семантическая паутина (semantic web) — это попытка построить глобальную семантическую сеть на базе ресурсов Всемирной паутины путём стандартизации представления информации в виде, пригодном для машинной обработки. Для этого в HTML-страницы дополнительно закладывается информация в виде специальных атрибутов HTML тэгов, которая позволяет описать смысл их содержимого в виде онтологии — набора фактов, абстрактных понятий и отношений между ними.
Стандартным подходом для описания семантической модели WEB ресурсов является RDF (Resource Description Framework или Среда Описания Ресурсов). Согласно ней все утверждения должны иметь форму триплета «субъект — предикат — объект». Например, знания о понятии «Кит» будут представлены следующим образом: «Кит» является субъектом, «живет в» — предикатом, «Вода» — объектом. Весь набор таких утверждений можно описать с помощью ориентированного графа, субъекты и объекты являются его вершинами, а предикаты — дугами, дуги предикатов направлены от объектов к субъектам. Например, онтологию из примера с животными можно описать в следующем виде:
@prefix : <...some URL...> @prefix rdf: <http://www.w3.org/1999/02/rdf-schema#> @prefix rdfs: <http://www.w3.org/2000/01/22-rdf-syntax-ns#> :Whale rdf:type :Mammal; :livesIn :Water. :Fish rdf:type :Animal; :livesIn :Water.
Такая форма записи называется Turtle, она предназначена для чтения человеком. Но то же самое можно записать и в XML, JSON форматах или с помощью тэгов и атрибутов HTML документа. Хоть в Turtle нотации предикаты и объекты можно сгруппировать вместе по субъектам для удобства чтения, но на семантическом уровне каждый триплет независим.
RDF удобен в тех случаях, когда модель данных сложна и содержит большое количество типов объектов и связей между ними. Например, Wikipedia предоставляет доступ к содержимому своих статей в RDF формате. Факты, описанные в статьях структурированы, описаны их свойства и взаимные отношения, включая факты из других статей.
RDFS
RDF модель представляет собой граф, по умолчанию никакой дополнительной семантики в нем не заложено. Каждый может интерпретировать заложенные в графе связи как посчитает нужным. Добавить в него некоторые стандартные связи можно с помощью RDF Schema — набора классов и свойств для построения онтологий поверх RDF. RDFS позволяет описать стандартные отношения между понятиями, такие как принадлежность ресурса некоторому классу, иерархию между классами, иерархию свойств, ограничить возможные типы субъекта и объекта.
Например, утверждение
:Mammal rdfs:subClassOf :Animal.
задает, что «Млекопитающее» является подклассом понятия «Животное» и наследует все его свойства. Соответственно, понятие «Кит» также можно отнести к классу «Животное». Но для этого нужно указать, что понятия «Млекопитающее» и «Животное» являются классами:
:Animal rdf:type rdfs:Class. :Mammal rdf:type rdfs:Class.
Так же предикату можно задать ограничения на возможные значения его субъекта и объекта.
Утверждение
:livesIn rdfs:range :Environment.
указывает, что объектом отношения «живет в» всегда должен быть ресурс, относящийся к классу «Окружающая среда». Поэтому мы должны добавить утверждение о том, что понятие «Вода» является подклассом понятия «Окружающая среда»:
:Water rdf:type :Environment. :Environment rdf:type rdfs:Class
RDFS позволяет описать схему данных — перечислить классы, свойства, задать их иерархию и ограничения их значений. А RDF – наполнить эту схему конкретными фактами и задать отношения между ними. Теперь мы можем задать вопрос к этому графу. Сделать это можно на специальном языке запросов SPARQL, напоминающем SQL:
SELECT ?creature WHERE { ?creature rdf:type :Animal; :livesIn :Water. }
Этот запрос вернет нам 2 значения: «Whale» и «Fish».
Пример из предыдущих публикаций со счетами и клиентами можно реализовать приблизительно следующим образом. С помощью RDF можно описать схему данных и наполнить ее значениями:
:Client1 :name "John"; :email "john@somewhere.net". :Client2 :name "Mary"; :email "mary@somewhere.net". :Bill_1 :client :Client1; :date "2020-01"; :amountToPay 100; :amountPaid 50. :Bill_2 :client :Client2; :date "2020-01"; :amountToPay 80; :amountPaid 80.
Но вот абстрактные понятия, такие как «Должник» и «Неоплаченные счета» из первой статьи этого цикла, включают в себя арифметические операции и сравнение. Они не вписываются в статичную структуру семантической сети понятий. Эти понятия можно выразить с помощью SPARQL запросов:
SELECT ?clientName ?clientEmail ?billDate ?amountToPay ?amountPaid WHERE { ?client :name ?clientName; :email ?clientEmail. ?bill :client ?client; :date ?billDate; :amountToPay ?amountToPay; :amountPaid ?amountPaid. FILTER(?amountToPay > ?amountPaid). }
Секция WHERE представляет собой список шаблонов триплетов и условий фильтрации. В триплеты можно подставлять логические переменные, имя которых начинается с символа "?". Задача исполнителя запроса — найти все возможные значения переменных, при которых все шаблоны триплетов содержались бы в графе и выполнялись условия фильтрации.
В отличии от Prolog, где на основе правил можно конструировать другие правила, в RDF запрос не является частью семантической сети. На запрос нельзя ссылаться как на источник данных для другого запроса. Правда у SPARQL есть возможность представить результаты запроса в виде графа. Так что можно попробовать объединить результаты запроса с исходным графом и новый запрос выполнить на объединенном графе. Но такое решение будет явно выходить за рамки идеологии RDF.
OWL
Важным компонентом технологий семантической паутины является OWL (Web Ontology Language) – язык описания онтологий. С помощью словаря RDFS можно выразить только самые базовые отношения между понятиями — иерархию классов и отношений. OWL предлагает гораздо более богатый словарь. Например, можно задать, что два класса (или две сущности) являются эквивалентными (или различными). Такая задача часто встречается при объединении онтологий.
Можно создавать составные классы на основе пересечения, объединения или дополнения других классов:
- При пересечении все экземпляры составного класса должны относиться и ко всем исходным классам. Например, «Морское млекопитающее» должно быть одновременно и «Млекопитающим» и «Морским жителем».
- При объединении составной класс включает в себя все экземпляры исходных классов. Например, можно задать, что класс «Животное» является объединением классов «Хищник», «Травоядное» и «Всеядное». Все экземпляры этих классов будут заодно и «Животными».
- При дополнении к составному классу относится все, что не относится к исходному. Например, класс «Хладнокровное» дополняет класс «Теплокровное».
- Так же можно создавать классы на основе перечислений. Можно указать, что экземпляр составного класса обязательно должен быть экземпляром только одного из исходных классов.
- Можно задавать наборы непересекающихся классов — если экземпляр относится к одному из них, то одновременно он не может относиться к остальным классам из набора.
Такие выражения, позволяющие связать понятия между собой, называются конструкторами.
OWL также позволяет задавать многие важные свойства отношений:
- Транзитивность. Если выполняются отношения P(x, y) и P(y, z), то обязательно выполняется и отношение P(x, z). Примерами таких отношений являются «Больше»-«Меньше», «Родитель»-«Потомок» и т.п.
- Симметричность. Если выполняется отношение P(x, y), то обязательно выполняется и отношение P(y, x). Например, отношение «Родственник».
- Функциональная зависимость. Если выполняются отношения P(x, y) и P(x, z), то значения y и z должны быть идентичными. Примером является отношение «Отец» — у человека не может быть два разных отца.
- Инверсия отношений. Можно задать, что если выполняется отношение P1(x, y), то обязательно должно выполняться еще одно отношение P2(y, x). Примером таких отношений являются отношения «Родитель» и «Потомок».
- Цепочки отношений. Можно задать, что если А связан неким свойством с В, а В — с С, то А (или С) относится к заданному классу. Например, если у А есть отец В, а у отца В — свой отец С, то А приходится внуком С.
Так же можно задать ограничения на значения аргументов отношений. Например, указать, что аргументы должны всегда принадлежать определенному классу, или что у класса должно быть как минимум одно отношение заданного типа, или ограничить для него количество отношений такого типа. Или указать, что к определенному классу относятся все экземпляры, которые связаны заданным отношением с заданным значением.
Сейчас OWL является фактически стандартным средством для построения онтологий. Этот язык лучше подходит для построения больших и сложных онтологий чем RDFS. Синтаксис OWL позволяет выразить больше разных свойств понятий и отношений между ними. Но и вводит ряд дополнительных ограничений, например, одно и то же понятие нельзя одновременно объявить и как класс и как экземпляр другого класса. Онтологии в OWL жестче, более стандартизированы и, соответственно, более читабельны. Если RDFS это всего лишь несколько дополнительных классов поверх RDF графа, то OWL имеет другую математическую основу — дескрипционную логику. Соответственно, становятся доступны и формальные процедуры логического вывода, позволяющие извлекать новую информацию из OWL онтологий, проверять их согласованность и отвечать на вопросы.
Дескрипционная или описательная логика (descriptive logic) является фрагментом логики первого порядка. В ней допустимы только одноместные (например, принадлежность понятия к классу), двухместные предикаты (наличие у понятия свойства и его значения), а также конструкторы классов и свойства отношений, перечисленные выше. Все остальные выражения логики первого порядка в дескрипционной логике отброшены. Например, допустимыми будут утверждения, что понятие «Неоплаченный счет» относится к классу «Счет», понятие «Счет» имеет свойства «Сумма к оплате» и «Оплаченная сумма». Но вот сделать утверждение, что у понятия «Неоплаченный счет» свойство «Сумма к оплате» должно быть больше свойства «Оплаченная сумма» уже не получится. Для этого понадобится правило, которое будет включать предикат сравнения этих свойств. К сожалению, конструкторы OWL не позволяют сделать это.
Таким образом, выразительность дискрипционной логики ниже, чем у логики первого порядка. Но, с другой стороны, алгоритмы логического вывода в дескрипционной логике гораздо быстрее. Кроме того, она обладает свойством разрешимости — решение гарантированно может быть найдено за конечное время. Считается, что на практике такого словаря вполне достаточно для построения сложных и объемных онтологий, и OWL – это хороший компромисс между выразительностью и эффективностью логического вывода.
Также стоит упомянуть SWRL (Semantic Web Rule Language), который сочетает возможность создания классов и свойств в OWL с написанием правил на ограниченной версии языка Datalog. Стиль таких правил такой же, как и в языке Prolog. SWRL поддерживает встроенные предикаты для сравнения, математических операций, работы со строками, датами и списками. Это как раз то, чего нам не хватало для того, чтобы с помощью одного простого выражения реализовать понятие «Неоплаченный счет».
Flora-2
В качестве альтернативы семантическим сетям рассмотрим также такую технологию как фреймы. Фрейм — это структура, описывающая сложный объект, абстрактный образ, модель чего-либо. Он состоит из названия, набора свойств (характеристик) и их значений. Значением свойства может быть другой фрейм. Также у свойства может быть значение по умолчанию. К свойству может быть привязана функция вычисления его значения. В состав фрейма также могут входить служебные процедуры, в том числе обработчики таких событий так создание, удаление фрейма, изменение значения свойств и др. Важным свойством фреймов является возможность наследования. Дочерний фрейм включает в себя все свойства родительских фреймов.
Система связанных фреймов формирует семантическую сеть, очень похожую на RDF граф. Но в задачах создания онтологий фреймы были вытеснены языком OWL, который сейчас является фактическим стандартом. OWL более выразителен, имеет более продвинутое теоретическое основание — формальную дискрипционную логику. В отличии от RDF и OWL, в которых свойства понятий описываются независимо друг от друга, в фреймовой модели понятие и его свойства рассматриваются как единой целое — фрейм. Если в моделях RDF и OWL в вершинах графа находятся имена понятий, а в ребрах — их свойства, то во фреймовой модели в вершинах графа расположены понятия со всеми их свойствами, а в ребрах — связи между их свойствами или отношения наследования между понятиями.
В этом фреймовая модель очень близка модели объектно-ориентированного программирования. Они во многом совпадают, но имеют разную сферу применения — фреймы направлены на моделирование сети понятий и отношений между ними, а ООП — на моделирование поведения объектов, их взаимодействия между собой. Поэтому в ООП доступны дополнительные механизмы скрытия деталей реализации одного компонента от других, ограничения доступа к методам и полям класса.
Современные фреймовые языки (такие как KL-ONE, PowerLoom, Flora-2) комбинируют составные типы данных объектной модели с логикой первого порядка. В этих языках можно не только описывать структуру объектов, но и оперировать этими объектами в правилах, создавать правила, описывающие условия принадлежности объекта заданному классу и т.д. Механизмы наследования и композиции классов получают логическую трактовку, которая становится доступна для использования процедурам логического вывода. Выразительность этих языков выше, чем у OWL, они не ограничены двухместными предикатами.
В качестве примера попробуем реализовать наш пример с должниками на языке Flora-2. Этот язык включает в себя 3 компонента: фреймовую логику F-logic, объединяющую фреймы и логику первого порядка, логику высших порядков HiLog, предоставляющую инструменты для формирования высказываний о структуре других высказываний и мета-программирования, и логику изменений Transactional Logic, позволяющую в логической форме описывать изменения в данных и побочные эффекты (side effects) вычислений. Сейчас нас интересует только фреймовая логика F-logic. Для начала с ее помощью объявим структуру фреймов, описывающих понятия (классы) клиентов и должников:
client[|name => \string, email => \string |]. bill[|client => client, date => \string, amountToPay => \number, amountPaid => \number, amountPaid -> 0 |].
Теперь мы можем объявить экземпляры (объекты) этих понятий:
client1 : client[name -> 'John', email -> 'john@somewhere.net']. client2 : client[name -> 'Mary', email -> 'mary@somewhere.net']. bill1 : bill[client -> client1, date -> '2020-01', amountToPay -> 100 ]. bill2 : bill[client -> client2, date -> '2020-01', amountToPay -> 80, amountPaid -> 80 ].
Символ '->' означает связь атрибута с конкретным значением у объекта и значение по умолчанию в объявлении класса. В нашем примере поле amountPaid класса bill имеет нулевое значение по умолчанию. Символ ':' означает создание сущности класса: client1 и client2 являются сущностями класса client.
Теперь мы можем объявить, что понятия «Неоплаченный счет» и «Должник» являются подклассами понятий «Счет» и «Клиент»:
unpaidBill :: bill. debtor :: client.
Символ '::' объявляет отношение наследования между классами. Наследуется структура класса, методы и значения по умолчанию для всех его полей. Осталось объявить правила, задающие принадлежность к классам unpaidBill и debtor:
?x : unpaidBill :- ?x : bill[amountToPay -> ?a, amountPaid -> ?b], ?a > ?b. ?x : debtor :- ?x : client, ?_ : unpaidBill[client -> ?x].
В первом высказывании утверждается, что переменная
?х является сущностью класса unpaidBill, если она является сущностью класса bill, и значение ее поля amountToPay больше значения amountPaid. Во втором, что ?х относится к классу unpaidBill, если она относится к классу client и существует хотя бы одна сущность класса unpaidBill, у которой значение поля client равно переменной ?х. Эта сущность класса unpaidBill будет связана с анонимной переменной ?_, значение которой в дальнейшем не используется.Получить список должников можно с помощью запроса:
?- ?x:debtor.
Мы просим найти все значения, относящиеся к классу debtor. Результатом будет список всех возможных значений переменной
?x:?x = client1
Фреймовая логика сочетает в себе наглядность объектно-ориентированной модели с мощью логического программирования. Она будет удобна при работе с базами данных, моделировании сложных систем, интеграции разрозненных данных — в тех случаях, где нужно сделать акцент на структуре понятий.
SQL
Напоследок рассмотрим основные особенности синтаксиса SQL. В прошлой публикации мы говорили, что SQL имеет логическую теоретическую основу — реляционное исчисление, и рассмотрели реализацию примера с должниками на LINQ. В плане семантики SQL близок к фреймовым языкам и ООП модели — в реляционной модели данных основным элементом является таблица, которая воспринимается как единое целое, а не как набор отдельных свойств.
Синтаксис SQL прекрасно соответствует такой ориентации на таблицы. Запрос разбит на секции. Сущности модели, которые представлены таблицами, представлениями (view) и вложенными запросами, вынесены в секцию FROM. Связи между ними указываются с помощью операций JOIN. Зависимости между полями и другие условия находятся в секциях WHERE и HAVING. Вместо логических переменных, связывающих аргументы предикатов, в запросе мы оперируем полями таблиц напрямую. Такой синтаксис описывает структуру модели предметной области более наглядно по сравнению с «линейным» синтаксисом Prolog.
Каким я вижу стиль синтаксиса языка моделирования
На примере со неоплаченными счетами мы можем сравнить такие подходы как логическое программирование (Prolog), фреймовую логику (Flora-2), технологии семантической паутины (RDFS, OWL и SWRL) и реляционное исчисление (SQL). Их основные характеристики я свел в таблицу:
| Язык | Математическая основа | Ориентация стиля | Сфера применения |
|---|---|---|---|
| Prolog | Логика первого порядка | На правила | Системы, основанные на правилах, сопоставление с образцом. |
| RDFS | Граф | На связи между понятиями | Схема данных WEB ресурса |
| OWL | Дескрипционная логика | На связи между понятиями | Онтологии |
| SWRL | Урезанная версия логики первого порядка как у Datalog | На правила поверх связей между понятиями | Онтологии |
| Flora-2 | Фреймы + логика первого порядка | На правила поверх структуры объектов | Базы данных, моделирование сложных систем, интеграция разрозненных данных |
| SQL | Реляционное исчисление | На структуры таблиц | Базы данных |
Теперь нужно подобрать математическую основу и стиль синтаксиса для языка моделирования, предназначенного для работы со слабоструктурированными данными и интеграцией данных из разрозненных источников, который бы сочетался с объектно-ориентированными и функциональными языками программирования общего назначения.
Наиболее выразительными языками является Prolog и Flora-2 — они основаны на полной логике первого порядка с элементами логики высших порядков. Остальные подходы являются ее подмножествами. За исключением RDFS — он вообще не связан с формальной логикой. На данном этапе полноценная логика первого порядка мне видится предпочтительным вариантом. Для начала я планирую остановиться на нем. Но и ограниченный вариант в виде реляционного исчисления или логики дедуктивных баз данных тоже имеет свои преимущества. Он обеспечивает большую производительность при работе с большими объемами данных. В будущем его стоит рассмотреть отдельно. Дескрипционная логика выглядит слишком ограниченной и неспособной выразить динамические отношения между понятиями.
С моей точки зрения, для работы со слабоструктурированными данными и интеграции разрозненных источников данных фреймовая логика подходит больше, чем Prolog, ориентированный на правила, или OWL, ориентированный на связи и классы понятий. Фреймовая модель описывает структуры из объектов в явном виде, фокусирует на них внимание. В случае объектов с большим количеством свойств фреймовая форма гораздо более читабельна, чем правила или триплеты «субъект-свойство-объект». Наследование также является очень полезным механизмом, позволяющим значительно сократить объем повторяющегося кода. По сравнению с реляционной моделью фреймовая логика позволяет описать сложные структуры данных, такие как деревья и графы, более естественным образом. И, самое главное, близость фреймовой модели описания знаний к модели ООП позволит интегрировать их в одном языке естественным образом.
У SQL я хочу позаимствовать структуру запроса. Определение понятия может иметь сложную форму и его не помешает разбить на секции, чтобы подчеркнуть его составные части и облегчить восприятие. Кроме того, для большинства разработчиков синтаксис SQL довольно привычен.
Итак, за основу языка моделирования я хочу взять фреймовую логику. Но поскольку целью является описание структур данных и интеграция разрозненных источников данных я попробую отказаться от синтаксиса, ориентированного на правила, и заменить его на структурированный вариант, позаимствованный у SQL. Основным элементом модели предметной области будет «понятие» (concept). В его определение я хочу включить всю информацию, необходимую для извлечения его сущностей (entities) из исходных данных:
- имя понятия;
- набор его атрибутов;
- набор исходных (родительских) понятий, служащих для него источниками данных;
- набор условий, связывающих между собой атрибуты производного и исходного понятий;
- набор условий, ограничивающих возможные значения атрибутов понятий.
Определение понятия будет напоминать SQL запрос. А вся модель предметной области будет иметь форму взаимосвязанных понятий.
Получившийся синтаксис языка моделирования я планирую показать в следующей публикации. Для тех, кто хочет познакомиться с ним уже сейчас, есть полный текст в научном стиле на английском языке, доступный по ссылке:
Hybrid Ontology-Oriented Programming for Semi-Structured Data Processing
Ссылки на предыдущие публикации:
Проектируем мульти-парадигменный язык программирования. Часть 1 — Для чего он нужен?
Проектируем мульти-парадигменный язык программирования. Часть 2 — Сравнение построения моделей в PL/SQL, LINQ и GraphQL

