
Low-precision inference в TensorRT сегодня - мастхэв, бест практис и прочие иностранные. Сконвертить из TensorFlow легко, запустить легко, использовать fp16 легко. Да и КПД выше, чем у pruning или distillation. На первый взгляд всё работает идеально. Но на самом деле всё ли так гладко? Рассказываем, как мы в TrafficData споткнулись об fp16, встали и написали статью.
Если ты читаешь эту статью ради подробного туториала о запуске TensorRT, то его тут нет. Он есть тут. Здесь же про опыт применения и несколько важных моментов, о которых не говорят в официальной документации.
Что за зверь ваш low-precision?
float16
И так, low-precision inference - запуск нейронных сетей в типе пониженной точности. Но зачем это нужно? По умолчанию все фреймворки учат и сохраняют модели в типе float32. Оказывается, что количество знаков во fp32 - часто избыточно. Ну а зачем нам эти сотни знаков после запятой? Можно просто скастовать fp32 веса во fp16, чтобы получить ускорение прямого прогона и уменьшение используемой памяти в 2 раза. При этом сохранив исходную точность модели. Единственное условие - наличие тензорных ядер в вашем GPU.
int8 и прочее
Кроме fp16 с простым кастованием есть много идей по более оптимальному использованию бит в 16-битном значении. Просто чтобы напомнить:

Но этого мало. Использование нейронных сетей в высоконагруженных системах и мобильных платформах заставляет еще сильнее ужимать сети и ускорять инференс. Добро пожаловать в мир int8 и int4. Да, в них квантуют. Да, в int8 всего 256 значений. Да, это работает. Со своими сложностями, конечно - здесь уже просто так не кастанёшь, как в случае с fp16. Нужно внимательно изучать распределения значений в слоях, чтобы эффективно использовать предоставленный небольшой диапазон значений.
Объясню, почему мы не смотрим на 8/4 битные квантизации. Дело в том, что здесь не обойтись без потери точности. Например, тут говорят как оптимально юзать int4 и радуются, что потеряли не 15%, а 8% точности. Или вот красноречивая табличка от Nvidia о западении точности при использовании int8:
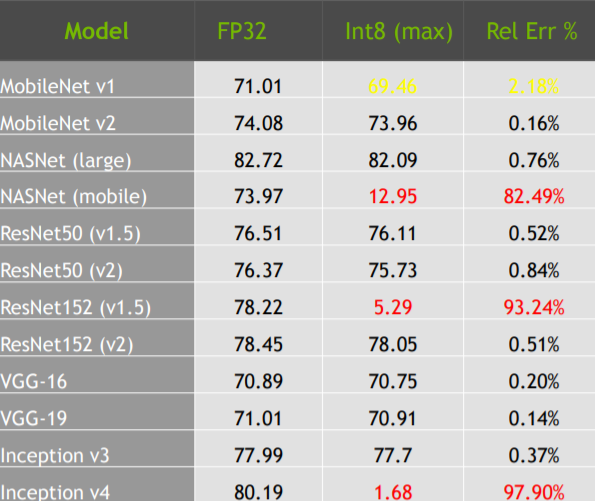
Я слышал на конференциях, что на такую потерю точности нормально смотрят в мобильных решениях. Особенно, если это какой-то развлекательный контент типа переноса стилей на GANax и тд. Ну изменился стиль немного - ничего страшного.
В нашем решении каждый процент точности - наше золотце. И пока мы не научились не терять их в int8.
TensorRT
Если у вас мобильные решения или просто инференс на CPU, то попробуйте TensorFlow Lite. Но в основном, говоря про low-precision inference в проде, сегодня имеют ввиду TensorRT - кроссплатформенный SDK для супер-быстрой работы на GPU от Nvidia. TensorRT легко превращает ваши модели в оптимизированные Engines. Сконвертить можно из любого нейросетевого фреймворка через ONNX. Engine - очень важная сущность в TensorRT. При билде происходит оптимизация под текущий GPU - на других GPU engine либо не запустится, либо будет работать неоптимально. Короче говоря, есть ряд параметров, которые нужно знать или задать заранее:
GPU. На чём собрали Engine, на том пусть он и работает. Но допустим общий билд для карточек одного семейства - Turing или Ampere. Например, мы билдили Engine для RTX 2060 и он замечательно работает на RTX 2080 Super. Создание отдельного Engine для RTX 2080 Super существенного ускорения не создает.
BatchSize. Нужно задать максимальный - для него и будет соптимизирован Engine. В рантайме можно подавать батчи размером меньше максимального, но это будет неоптимально.
InputSize. Мы работаем с изображениями. И размер входного изображения иногда может меняться во время рантайма. Но TRT требует его задавать жестко, что логично. Да, есть возможность задать минимальный и максимальный размеры, а TRT создаст несколько профилей оптимизации. Но всё же это не так гибко, как в TensorFlow, а иногда нужно.
Precision. Собственно мы можем задать fp32/fp16/int8. Первые два различаются лишь выбором флага. С int8 я мало экспериментировал. Но судя по документации, отличие лишь в необходимости калибровочного датасета - набора картинок, на основании которого TRT определит распределения значений на разных слоях.
Ну и под конец еще добавлю, что в рантайме эти движки отжирают лишь необходимый минимум GPU RAM и замечательно работают параллельно (если правильно работать с TensorRT Context в вашем коде рантайма).
Контекст задачи
Окей, чтобы было понятнее, какие проблемы возникли, пара слов о нашем продукте. Мы пилим TrafficData - ПО для оценки трафика c камер и дронов, в рилтайме и постфактум, в дождь и снег. Нам важно, чтобы ночью детектилось вот так:

И не хуже.
На opentalks.ai2020 мы рассказывали, как, используя Pruning и физичность данных, ускорили обработку в 4 раза и не потеряли в точности. Статью про Pruning я уже выкладывал. Но сегодня давайте поговорим конкретно про low-precision inference.
Как мы запустились и потеряли нежные фичи
Скачивая либы TensorRT, бонусом вы получаете набор примеров с кодом для самых разных архитектур и ситуаций. Для билда движков мы использовали пример SampleUffSSD (UFF - универсальный формат описания сети, через который мы конвертили наши .pb), cлегка его закастомив под входной тензор от YOLO. И хотя TensorRT очень много обновляется и всё больше новых интересных слоев поддерживает, тогда мы запускались на версии, где не было реализации ResizeBilinear операции для Upsample слоя. И мы накостылили Conv2DTranspose вместо него, чтобы не писать кастомный слой. Первая сконверченная модель была радостью, как и её скорость работы.
Даже если перейти с fp32 из TF в fp32 TRT, то уже получается неслабое ускорение - на 15-20%. В конце концов TRT использует и много других оптимизаций, например горизонтальные, вертикальные и любые другие LayerFusion.
Для инференса мы закастомили пример trtExec, обернув его для использования в .NET коде. На вход - байты изображения, на выходе - нераспарсенные байты выхода YOLO. Здесь аккуратно работайте с CudaStream и ExecutionContext. Тогда ни память не утечет, ни потоки обработки не закорраптятся.
И так, мы реализовали TensorRT fp16 inference. Сбилдили движки для разных карточек. Прогнали основные тесты - колебания точности в пределах погрешности. И всё замечательно работало несколько месяцев. А дальше - история.
10:00. Звонок клиента:
- У нас тут на одном ролике TrafficData плохо работает - машинки двоятся.
- Окей, скиньте ролик разберемся.
Смотрим ролик - да, проблема есть. Ролик с тенями и на нём тени отмечаются, как второе авто.
13:00. Добрали изображения в основной датасет. Поставили доучиться с низким LR.
16:00. Тестим на версии с инференсом в TensorFlow - всё замечательно. Билдим новый Engine. Тестим на версии с инференсом в TensorRT - опять машины двоятся:

17:00. Идём домой.
Следующее утро началось с мема:

Стало очевидно, что проблема в TensorRT, а конкретно - в преобразовании весов во fp16. Мы проверили еще несколько других роликов со сложными условиями и увидели, что после преобразования во fp16 проблемы появились и в других местах. Стали появляться пропуски детекции на ночных видео, некоторые билборды стали определяться как авто. Короче вот так мы потеряли нежные, но важные фичи, про которые оригинальная сеть во fp32 знала, а вот во fp16 успешно забыла. Что делать?
Quntization Aware Training. Учи на том, на чем будет работать
Подсознательно мы сразу понимали, что если мы обучаем на fp32, а потом инференсим на fp16, то выйдет неприятная вещь. Вот эти жалкие циферки далеко после запятой потеряны и так влияют. Тогда зачем мы их учили на каждом батче? Идея Quntization Aware Training крайне проста - учи и помни о том типе, в котором будешь инференсить. Т.е. в типе fp16 должны быть все веса сверток, активаций и градиентов. Не удивляйтесь, если первые запуски в TensorFlow окажутся с NaN-лоссом. Просто внимательно инспектируйте происходящее. Мы потратили пару недель, переписали всё обучение на fp16 и проблема была решена.
Как в Tensorflow 2.0?
Тут небольшое отступление о том, как мы были рады обновлению TF2.0. Работая под TF1.15 мы кусали локти, заставляя запуститься обучение во fp16, переписывая слои. Но это заработало. А потом пришел TF2.0 - используешь tf.train.experimental.enable_mixed_precision_graph_rewrite над оптимизатором и всё заводится, как моя Lada Granta. Но всё же стоит обратить внимание на whitelist - не все ноды по умолчанию будут работать во fp16. Часть стоит поправить руками. Ну и дополнительный бонус - огромная экономия памяти, которой не получалось в TF1.15. Батч-сайз для нашей кастомной YOLOv4.5 увеличился в 2 раза - с 4 до 8. Больше батч - лучше градиенты.
Выводы
Fp16 inference - это здорово. Только не стоит забывать про Quntization Aware Training, если вы хотите сохранить точность оригинальной модели. Это позволило нам сделать еще шаг в сторону оптимизации наших и клиентских мощностей:

Что особенно важно в годы дефицита чипов и дорогих GPU. Я всё же за использование GPU в тех местах, где они приносят пользу людям, автоматизируя что-то. А не там, где они приносят прибыль, делая деньги из подогретого воздуха.
А вообще вся тематика ускорения инференса сетей сегодня - очень интересное поле для экспериментов. Хочется попробовать десятки новых способов Pruning, Distillation или квантования в int4, но всех Баксов Банни не догонишь. Пробуйте новое, но не забывайте отдыхать.
UPD: Отвечая на вопрос DistortNeo про реальную максимальную производительность на практике.
В теории TensorRT, используя tensor cores, может дать реальное ускорение общей производительности до 6 раз. То есть важно говорить как ускорение для 1 потока в 2 раза за счет fp16 вычислений, так и про увеличение пропускной способности памяти и особенности вычислений в tensor cores. Что же на практике?
Наш опыт такой — при работе в 1 потоке мы получаем ускорение 2х. Однако, если говорить про многопоточную обработку, то ситуация интереснее. Во fp32 на TF мы можем обрабатывать параллельно 2.5 потока видео 30 fps, т.е. суммарно 75 кадров в секунду. При переходе на fp16 в TensorRT производительность вырастает до 8 потоков 30 fps = 240 кадров в секунду. Т.е. фактически при полной утилизации tensor cores мы получили увеличение производительности в 3.2 раза — несколько меньше теоретически максимальной. Скорее всего, это связано с тем, что мы обрабатываем потоки с батчем = 1, чтобы не увеличивать latency прихода данных по каждому кадру. Использование большего батча в инференсе может поднять итоговый буст производительности еще ближе к теоретическим 6х.
UPD2: Q&A к вопросам kremnik
1) Почему не решились писать кастомные слои под trt? Легче было написать свой слой на tf, чем на trt?
Мы использовали YOLO-подобную архитектуру и знали, что Upsample там легко заменяется на Conv2DTranspose. Хотя и известно, что Conv2DTranspose здесь менее предпочтителен из-за свойственных ему краевых эффектов. Мы посчитали это более оптимальным по скорости путём, чем создание кастомных слоёв.
2) Встретились ли проблемы с другими слоями при конвертации из tf в uff? Насколько я понимаю, поддержка uff заканчивается, он мало обновляется и все потихоньку переходят на onnx, который поддерживает гораздо больше слоёв.
Других проблем не было. Нормально заходят и Mish-активации, и Separable2DConv. Но да, раз uff становится deprecated, мы будем юзать onnx.
3) Если был BatchNorm, пробовали ли делать BatchNorm Folding или конвертировали напрямую? Насколько я знаю, у uff проблемы с BatchNorm-слоями.
BatchNormalization слои, конечно, были. Проблем при конвертации не возникло и вроде нигде не натыкался на такую информацию.
4) Картинки при инференсе отдаёте батчами или по одной? Есть ли относительное ускорение на одну картину при батче==1 и батче==N?
Как писал в UPD выше - подаём по одной, чтобы не было большого latency между обработанными кадрами, т.к. после каждого кадра работают еще многие другие алгоритмы. Помню, что мы тестировали батч = 8 и там ускорения на 1 изображение практически не было - около 5% в рамках погрешности. Могу предположить, что батчинг скорее увеличит общую пропускную способность, чем скорость инференса одного изображения.
5) Использовали ли Triton или используете что-то своё?
Исторически наш первый продукт - монолитное десктопное приложение. Учитывая особенности его архитектуры, было логичнее написать свою обёртку над С++ кодом. Т.е. мы сами создаём ExecutionContext, CudaStream и сами контролируем очереди на обработку. Затем у нас появилось облачное решение, где мог бы быть логичнее Triton. Но нам уже очень понравилось самим контролировать процессы в TRT и мы оставили нашу обёртку.

