
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
За что минусят то?
(Пожимая плечами) Общая безблагодатность?
Не. Наличие ключевых триггеров, таких как "Сколково", "Вопрос на понимание".
По теме статьи... FIFO, LIFO - это довольно известныве и распространенные схемотехнические примитивы. Их изучали не то что в институтах - в техникумах. И на дискретке. Правда уже более 20 лет назад дело было. Сейчас не знаю. В целом повтор азбучных истин это не плохо. Впрочем, если уж говорить об азбуке, то и понятия типа "кредитный счетчик" или "skid buffer" и им подобные надо пояснять. Как минимум ссылками, а лучше текстом.
Правда остается нераскрытыми несколько важных моментов. Первые из которых это вопрос про то, когда FIFO лишний элемент. Да, я поимаю, про это сложнее писать. В подавляющем большинстве случаев это будет "Application specific". Т.е. типовая рекомендация "ставь FIFO" в определнных случаях оказывается бесполезной (вредной, правда, сильно реже). Ну, и безусловно - вы упоминули насколько типов реализации FIFO (триггеры, память) но как-то совсем легонько. Сказав А, надо говорить и Б. Т.е. упомянуть почему в одних случаях надо так, а в других эдак.
Как результат общее впечатление от статьи как от лекции в плохом ВУЗе. Вроде что-то такое где-то слышали, вроде даже по делу. И местами понятно. Но звонок прозвенел и... Это что сейчас было? В итоге "азбучную" статью поняли только те, кто и без нее "в теме". Сомневаюсь что цель была именно в этом. А публика здесь... Любит минусть мимоходом. Как раз за ключевые триггеры.
*** . Их изучали не то что в институтах - в техникумах. И на дискретке ***
Но тут же вся соль, что это на верилоге. Вы дискретку поставите вовнутрь 3-нанометрового чипа в телефоне?
*** понятия типа "кредитный счетчик" или "skid buffer" ***
Ну я же написал, что это не полноценная лекция, а:
приквел к завтрашнему занятию в Сколково (где будет и кредитный счетчик и skid buffer) и
минимальный набор комментариев к трем упражнениям, которые я хочу чтобы участники сделали перед этим занятием
Надеюсь я посмотрю. Правда абсолютной уверенности нет. Про приквел - да, действительно. В статье есть. И даже прочитано было. И даже по ссылке сходил. Но почему-то ожидалось несколько большего.
Впрочем, мне кажется что предлагаемый вами формат больше подходит для современной молодежи. Страннно, но обучающие видео почему-то им заходят лучше. Культ книги, карандаша и бумаги, видимо остается исключительно за старшим поколением. Впрочем "доклады у доски"в живую все равно работают лучше. В первую очередь потому, что вопросы с места разрешаются.
В целом ваши статьи интересны. Особенно когда они похожи на эту. Я бы очень хотел почитать про задержки для моделирования. Вот эта тема на сегодня мне не очень понятна. В том смысле, что я знаю откуда они берутся, догадываюсь почему моделировщик их игноририет (во всяком случае в "быстром" режиме), но не понимаю как их правильно расставлять в своем проекте.
Хотя, если уж совсем честно, то главную прикладную задачу я сделал. Да, понадобился Lattice с его семейством Crosslink как независимый приемник и анализатор MIPI, но это прошли. Когда я в следующий раз "потянусь" к ПЛИСам - это вопрос... Уж больно задачи у меня не того уровня...
Более-менее полное понимание задержек можно получить с помощью чтения двух текстов:
Приложения вот к этой книжке на русском языке Дональда Томаса - https://dmkpress.com/catalog/electronics/cad/978-5-97060-619-3/
Статьи Клифа Каммингса http://www.sunburst-design.com/papers/CummingsHDLCON1999_BehavioralDelays_Rev1_1.pdf
В книжке Дональда Томаса есть объяснение как работает симулятор, а статья Клифа Каммингса дополняет это. Вот выдержки из книги Дональда Томаса:
https://habr.com/ru/post/465969/
В начале книги Дональд Томас показывает упрощенную картинку симулятора, а в конце книги ее уточняет и дополняет:
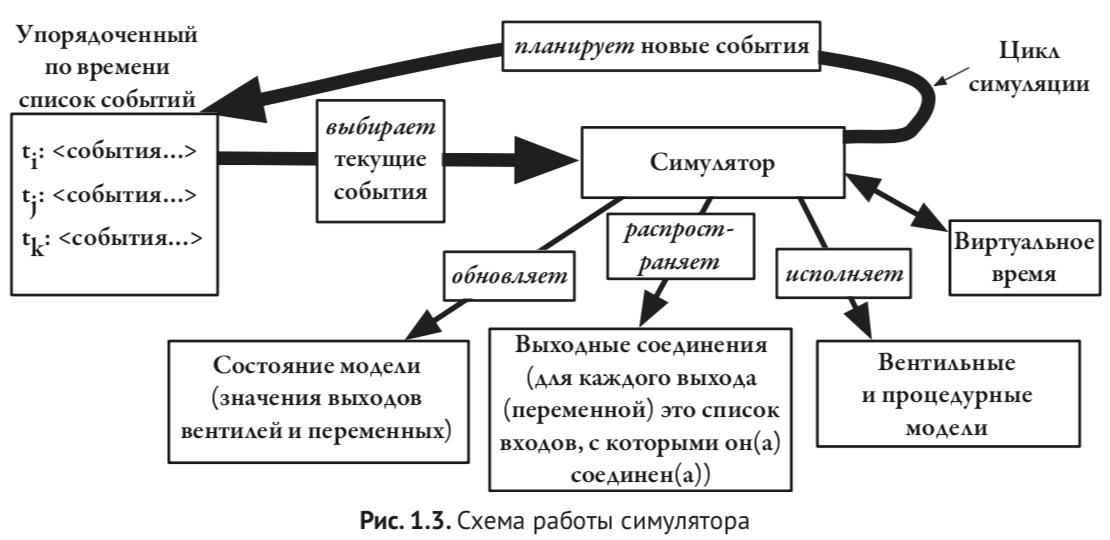
В симуляторе есть очереди событий и симулируемое время:
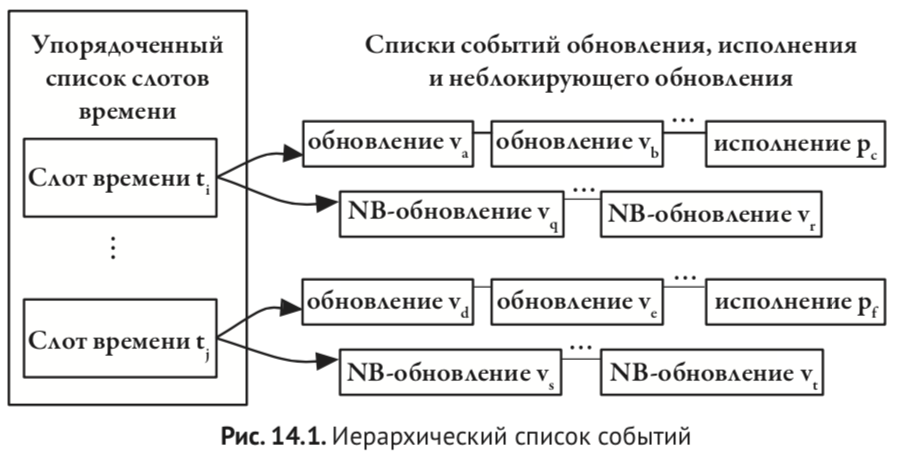
Событие может породить новое событие, как в текущий момент симуляции (в текущем дельта-цикле), так и в будущем времени. В текущем дельта-цикле сначала обрабатываются все события, порождаемые так называемыми блокирующими присваиваниями, а потом — события, порождаемые неблокирующими присваиваниями. Это необходимо для корректного моделирования параллельной семантики распостранения электрических сигналов в железе:
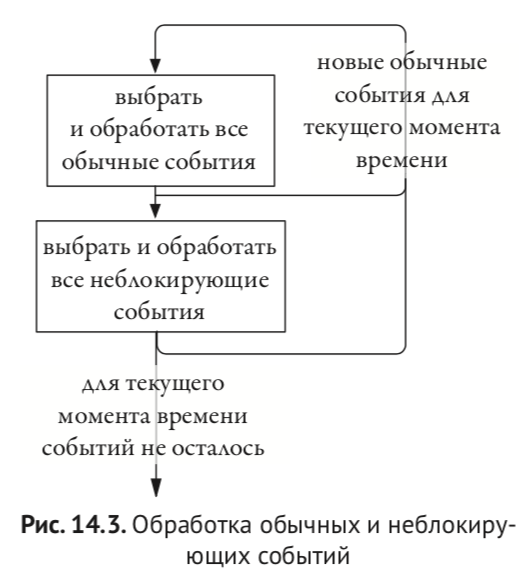
Кроме синтезируемого подмножества верилога есть еще несинтезируемое подмножество. Оно предназначено для описания тестового окружения и тестов, и вот его можно рассматривать как своего рода язык программирования. Для событий тестового окружения и мониторов вводятся дополнительные шаги симулятора:

Точное знание алгоритма работы симулятора очень полезно, чтобы избежать разнообразных багов, связанных с так называемыми гонками (race condition).
От вас ни одного изображения не загружается в этом сообщении, увы.
Сбой на Хабре. Эти изображения есть по ссылке https://habr.com/ru/post/465969/
Я извиняюсь за задержки в ответах. Дела не поволяют оперативнее.
Вопрос, собственно, был несколько не в этом. Позвольте я его переформулирую (только сделайте скидку - я не ПЛИСовод совсем - в данном контекстре скорее схемотехник).
Вопрос вот в чем. Что бы я не роектировал хоть комбинаторную схему, хоть цифровой автомат - все оно в конечном итоге будет декомбиноировано до самых примитиыных единиц. Т.е. до вентилей. А каждый из вентилей имеет задержку распространения сигнала. Т.е. даже в обычных комбинароных схемах сигналы до выходных вентилей могут доходить за разное время и это может (и обязательно будет) приводить к совершенно неожиданному поведению выходного сигнала. Это хорошо известный "разработчикам на дискретных элементах" факт. Он же имеет место и в ПЛИС (хотя, безусловно, задержка на вентиль там меньше в силу конструктивных особенностей самой ПЛИС).
Языки Verilog или VHDL - это языки опсания схемы. Грамотный разработчик до какого-то момента может предполагать в какую именно вентильную схемотехнику транслируется написанное (и проверить свои догадки посмотрев в RTL). Ровно так же, как грамотный разработчик на С может предполагать в какой именно код на ассемблере транслируются его программа и может это проверить в промежуточном коде, отладчике или дизассемлере. И вроде все хорошо - мы примерно представляем себе результат, пути распространения сигнала, можем примерно расставить задержки распространения для симулятора (особенно на сигалах, проходящих через множество вентилей).
Но... А разве есть гарантия того, что оптимизатор не переделает компонент в процессе его интеграции в схему? Что следующая версия компилятора будет производить такой же компонент? Т.е. проблематика ровно такая же как в низкоуровневом программировании. В лучшем случае мы получаем равный с точностью до поведения результат. Более того, поправьте, pls, если навру в терминологии, но "временное" и "функциональное" симулирование вроде как должно решать. Одно из них игнорирует "задержки на вентиль" и концентрируется на быстром получении результата в части "соответствия задуманному", второе сильно более медленнное, но пытается учитывать и эти задержки. Опять же - без гарантии. Ибо идеи по трансляцци языка в вентили у компилятора и симулятора могут (и наверняка будут) различаться. А теперь опять возвращаюсь к своему вопросу. Понимая все это я не понимаю как правильно расставлять руками задержки в своем проекте. Чем я могу помочь симуляторам с помощью этих задержек?
Понимая все это я не понимаю как правильно расставлять руками задержки в своем проекте. Чем я могу помочь симуляторам с помощью этих задержек?
В самом проекте для ПЛИС не нужно расставлять ручками задержки и помогать симулятору. Фишка в том, что на ПЛИС вы оперируете синхронным проектом. Т.е. всегда имеется некий тактовый сигнал и некоторая комбинационная логика, которая должна отработать за время такта и сохранить результаты в регистры. САПР гарантирует корректность функционирования схемы в железе, если комбинационная логика на любом пути в самом худшем случае успевает выполниться за время соответствующего такта.
Обычно большую часть времени вы отлаживаете корректность логики в поведенческой симуляции (быстрой) в предположении, что она укладывается в соответствующий такт, а затем прогоняете итерацию синтеза-имплементейшна и смотрите тайминги. Если не сошлись, дербаните конкретные комбинационные пути и/или колдуете с опциями. САПР выдаёт всю инфу по времянкам несошедшегося пути и симулировать там нечего. "Долгая" симуляция нужна в очень редких случаях.
Задержки могут понадобиться, если пилите свою библиотеку вентилей/примитивов (но для ПЛИС это делает вендор, так что всё украдено до нас). Также задержки обязательно понадобятся на границе с внешним миром: для внешних стимулов в тестбенчах или в качестве констрейнтов на входах/выходах ПЛИС.
Спасибо. Принято.
Ваш ответ примерно соответствует моему теперешнему пониманию ситуации. Но я слишком начинающий разработчик (в части ПЛИС) чтобы считать его безусловно верным. А тут такой повод уточнить. Грех не воспользоваться.
Задержки на уровне языка верилога (# n) иногда бывают нужны в тестбенче, как в случае выше. Также важно различать абстрактные задержки в симуляторе (дельта-циклы, о которых написал я) от реальных задержек в static timing analysis о которых пишете вы. Я написал ниже мое дополнение к вашему ответу
Я почему-то думал, что запостил вам ответ, но теперь его не вижу - наверное случился какой-то сбой (постил ответ с телефона).
Так вот, важно различать искусственные задержки в симуляторе (дельта-циклы) и реальные физические задержки в кремнии. Выше я писал об искуственных задержках, сейчас напишу о физических.
Моделировать на верилоге реальные физические задержки пробовали в 1980е, но потом пришли к выводу, что это работает плохо, после чего стали использовать static timing analysis во время сначала логического синтеза, а потом физического синтеза (размещения и трассировки, с более точным учетом задержек соединений).
Теперь работа выглядит так: архитектор всего чипа задает бюджет тайминга для разных блоков, тактовую частоту, в которую должна вписываться схема. Я, как проектировщик блока, периодически просматриваю результаты синтеза для своего блока, и если он не вписывается немного (скажем на 50 пикосекунд из 500 при 2 GHz тактовой частоты), то пробую оптимизировать локальную комбинационную логику. А если не вписывается сильно, скажем на 200 пикосекунд, то меняю микроархитектуру, добавляю стадии конвейера или ставлю регистр после вычисления ECC для статической памяти.
*** Ну, и безусловно - вы упоминули насколько типов реализации FIFO (триггеры, память) но как-то совсем легонько. Сказав А, надо говорить и Б. Т.е. упомянуть почему в одних случаях надо так, а в других эдак. ***
Это кстати да. Стоит добавить, что для FIFO размером больше пары-тройки тысяч бит (глубина * ширина) внутри ASIC-ов стоит использовать FIFO на основе SRAM блоков (такие есть от MediaTek, IBM итд).
Но тогда прийдется писать и про разницу между однопортовой и псевдо-двухпортовой памятями, и про ее латентность и способы компенсации латентности (присоединить сзади к FIFO на SRAM FIFO на D-триггерах), и про другие вещи (ECC, построение логической памяти из блоков физической итд). Это потребовало бы отдельного объемного поста, даже только для ASIC. А если писать про FPGA, а если писать про внешние памяти...
В данном случае у меня более скромная цель - приквел для занятия начального уровня на http://www.chipexpo.ru/shkola-sinteza-cifrovyh-shem-na-verilog
Читаю книги встреченные в статьях. К примеру, цифровая схемотехника и архитектура компьютера. С первой до пятой, открылся дивный мир. В шестой были знакомые части. Могли бы вы посоветовать практические книги/материалы для областей ee и cs?
На русском языке я бы порекомендовал:
Лабник "Цифровой синтез" - https://dmkpress.com/catalog/electronics/circuit_design/978-5-97060-850-0/
Книгу Дональда Томаса по верилогу https://dmkpress.com/catalog/electronics/cad/978-5-97060-619-3/ ревью https://habr.com/ru/post/465969/
Также вам может быть интересен мой пост что читать после Харрисов https://habr.com/ru/post/336116/
<quote>Плату Omdazz, которую держит в руках девушка Наташа, вам подарят бесплатно, если вы будете делать упражнения </unquote>
Я уже третий месяц делаю упражнения, а мне ничего не подарили. Что за подстава?
BTW:
Я, как мне кажется нашел неточность в Лабник "Цифровой синтез" в 7.7 Однопортовое ПЗУ.
Не синтезируется такой код на Циклон 4 во встроенные Мемори битс. Распознается как ROM, ошибок в логе нет, но в отчете о компиляции Total memory bits = 0. Все на Logic Elements.
Надо assign убрать. Вот так компилится.
Total memory bits = 16,384 / 276,480 ( 6 % )
module rom
#(parameter DATA_WIDTH=8, parameter ADDR_WIDTH=11)
( iшnput clk,
input [(ADDR_WIDTH-1):0] addr,
output reg [(DATA_WIDTH-1):0] data_out );
reg [DATA_WIDTH-1:0] rom [2**ADDR_WIDTH-1:0];
initial begin
$readmemb("font16x8rom.txt", rom);
end
always @ (posedge clk)
begin
data_out <= rom[addr];
end
endmoduleА ROM и не должен занимать memory bits. Это может быть чисто комбинационная логика - см. Харрис & Харрис.
Плату если вы участник Сколковской Школы Цифровойго Синтеза и сделали упражнения 1-24 со школы вы можете запросить у Михаила Коробкова fpga-systems@yandex.ru
Не обязан занимать их... согласен. Поэтому я написал неточность... не ошибка. Но смысла не вижу использовать такие дефицитные Logic Elements, если есть куча неиспользуемых memory bits.
Плюс к этому assign ломает синхронное ROM. А судя по мануалам компилятор может запихивать в memory bits только синхронную память. Так что, как я понимаю асинронную память при всем желании он не сделает на мемори битс.
Так что это, наверное даже не неточночть, а неоднозначность...
----------------------------
К сожалению я не участник... Просто делаю упражнения :) Пролетаю с платой. :(
В FPGA избыток memory bits, в ASIC дефицит, это да.
Если отвлечься от специфики использования ресурсов FPGA, то в комбинационной ROM нет ничего плохого. Просто вам нужно учесть в вашем дизайне, что внутри rom модуля после комбинационного облака нет регистра, И если он вам нужен, то самому его поставить после инстанциации модуля. Ну вы это наверное и сами понимаете, это я на всякий случай сказал.
Просто мы старались в примерах делать код, который идет и на ASIC, и на FPGA,
Поглядите атрибуты в квартусе. С альтерой не работал уже давно, последний год только на ксайлинксе. У того есть атрибуты, позволяющие в том числе выбирать тип памяти. Наверняка и в квартусе это есть, хотя на практике (когда работал с альтерой) пользоваться атрибутами мне не приходилось.
Юрий, прошу прощения за возможно глупый вопрос, но хочется спросить, у вас что-то в текстовом виде предполагается ??? Или так и будет в виде роликов на ютубе ??? Глянул сейчас вашу программу в школе синтеза, мне даже в мои 60+ это вполне интересно и полезно. Но увы, видео я не очень хорошо воспринимаю. Если бы было в текстовом виде, это куда лучше. С уважением, Евгений.
P.S. У меня DE-nano 0, и ice40-8HX-Breakout board (самая любимая зверюшка моего электронного зоопарка). Первая из них для занятий в школе подойдет (22К ячеек) ?
FIFO для самых маленьких (вместе с вопросами на интервью)