Исходники: https://github.com/huggingface/transformers
Документация: https://huggingface.co/docs/transformers/main/en/index
Платформа Hugging Face это коллекция готовых современных предварительно обученных Deep Learning моделей. А библиотека Transformers предоставляет инструменты и интерфейсы для их простой загрузки и использования. Это позволяет вам экономить время и ресурсы, необходимые для обучения моделей с нуля.
Модели решают весьма разнообразный спектр задач:
NLP: classification, NER, question answering, language modeling, summarization, translation, multiple choice, text generation.
CV: classification, object detection,segmentation.
Audio: classification, automatic speech recognition.
Multimodal: table question answering, optical character recognition, information extraction from scanned documents, video classification, visual question answering.
Reinforcement Learning
Time Series
Одна и та же задача может решаться различными архитектурами и их список впечатляет - более 150 на текущий момент. Из наиболее известных: Vision Transformer (ViT), T5, ResNet, BERT, GPT2. На этих архитектурах обучены более 60 000 моделей.
Модели Transformers поддерживают три фреймворках: PyTorch, TensorFlow и JAX. Для На PyTorch’а доступны почти все архитектуры. А вот для остальных надо смотреть совместимость: https://huggingface.co/docs/transformers/main/en/index#supported-frameworks
Также модели можно экспортировать в форматы ONNX и TorchScript.
Transformers не является набором модулей, из которых составляется нейронная сеть, как например PyTorch. Вместо это Transformers предоставляет несколько высокоуровневых абстракций, которые позволяют работать с моделями в несколько строк кода.
Начнем с установки…
Установка
Нам понадобится сами трансформеры:
pip install transformers
И т.к. мы будем писать на торче, то:
pip install torch
Еще нам понадобится библиотека evaluate, которая предоставляет различные ML метрики:
pip install evaluate
Поиск моделей
Прежде чем приступать к коду нам нужно формализовать нашу задачу до одного из общепринятых классов и найти подходящую для нее модель на хабе Hugging Face: https://huggingface.co/models

Слева вы можете увидеть ряд фильтров:
Класс задачи
Поддерживаемый фреймворк глубокого обучения
На каком датасете происходило обучение
Язык, на котором училась модель (если это NLP задача).
Также вы сможете поискать модель по названию — часто название модели содержит ее предназначение или архитектуру. Например, NLP-модели для классификации токсичности текста могут содержать “toxic” в названии. А берто-подобные архитектуры содержат слово “bert”.
На ваш поиск может вывалится множество моделей, поскольку для одной и той же задачи имеется множество предобученных моделей на разных архитектурах. И вам нужно выбрать подходящую. Что значит “подходящую”? Тут на вкус и цвет фломастеры разные: кому-то важнее точность, кому-то универсальность, а кому-то размер модели — выбирайте :)
Провалившись в конкретную модель вы сможете найти:
Более подробное описание модели
Кол-во классов, которые предсказывает модель
Примеры кода
Бенчмарки
И возможность поэкспериментировать
Более подробно про различные классы задач и как они решаются можете почитать здесь: https://huggingface.co/tasks

После того как вы нашли нужную модель скопируйте ее полное название, далее оно нам понадобится…
Использование моделей
Для доступа к моделям есть два способа:
Прямое использование моделей на исходном фреймворке — больше кода, но и больше гибкости.
Класс Pipeline — самый простой способ воспользоваться моделями из transformers. С него и начнем.
Pipeline
Использование любой модели включает в себя минимум два шага: соответствующим образом подготовить данные и непосредственное использование модели. Класс Pipeline объединяет в себе эти два шага.
Посмотрим как его задействовать на примере задачи классификации (токсичности) текста:
from transformers import pipeline clf = pipeline( task = 'sentiment-analysis', model = 'SkolkovoInstitute/russian_toxicity_classifier') text = ['У нас в есть убунты и текникал превью.', 'Как минимум два малолетних дегенерата в треде, мда.'] clf(text) #вывод [{'label': 'neutral', 'score': 0.9872767329216003}, {'label': 'toxic', 'score': 0.985331654548645}]
Здесь мы:
В конструкторе pipeline указали задачу, которую хотим решить, а также название конкретной модели из хаба Hugging Face (https://huggingface.co/models).
Задали набор документов, в которых нужно найти токсичный текст.
На выходе модель для каждого примера вывела наиболее вероятный класс и его скор.
С полным списком наименований задач, которые поддерживаются Pipeline вы можете ознакомится здесь: https://huggingface.co/docs/transformers/main/en/main_classes/pipelines
При первом обращении к какой-либо модели произойдет ее загрузка. При повторном обращении к этой модели загрузка будет производится из кэша.
Что тут можно улучшить:
Помимо конкретной модели в pipeline можно передать tokenizer. Токенайзер используется в NLP задачах и отвечает за предварительную обработку текста и конвертирует их в массив чисел, которые затем поступают на вход модели (об этом подробнее ниже).
Обычно для модели используется точно такой же tokenizer, который использовался при обучении (только так можно гарантировать корректность ее работы). Но если по каким-либо причинам вам потребовался другой, то его можно задать примерно так:
pipeline( task = 'question-answering', model = 'distilbert-base-cased-distilled-squad', tokenizer = 'bert-base-cased')
По умолчанию классификатор возвращает наиболее вероятный класс, но вы можете вернуть и все значения:
clf(text, top_k=None) #вывод [[{'label': 'neutral', 'score': 0.9872767329216003}, {'label': 'toxic', 'score': 0.012723307125270367}], [{'label': 'neutral', 'score': 0.01466838177293539}, {'label': 'toxic', 'score': 0.985331654548645}]]
Если все данные, которые нужно обработать, не влазят в память, то можно задействовать генератор, который будет поштучно загружать данные в память и подавать их в модель:
from transformers import pipeline clf = pipeline( task = 'sentiment-analysis', model = 'SkolkovoInstitute/russian_toxicity_classifier') text = ['У нас в есть убунты и текникал превью.', 'Как минимум два малолетних дегенерата в треде, мда.'] def data(text): for row in text: yield row for out in clf(data(text)): print(out) #вывод {'label': 'neutral', 'score': 0.9872767329216003} {'label': 'toxic', 'score': 0.985331654548645}
PyTorch
А теперь посмотрим как использовать модель на нативном Торче. Будем классифицировать котиков :)
import torch import requests from PIL import Image from io import BytesIO from transformers import AutoImageProcessor, AutoModelForImageClassification response = requests.get( 'https://github.com/laxmimerit/dog-cat-full-dataset/blob/master/data/train/cats/cat.10055.jpg?raw=true') img = Image.open(BytesIO(response.content)) img_proc = AutoImageProcessor.from_pretrained( 'google/vit-base-patch16-224') model = AutoModelForImageClassification.from_pretrained( 'google/vit-base-patch16-224') inputs = img_proc(img, return_tensors='pt') with torch.no_grad(): logits = model(**inputs).logits predicted_id = logits.argmax(-1).item() predicted_label = model.config.id2label[predicted_id] print(predicted_id, '-', predicted_label) #вывод 281 - tabby, tabby cat
Тут мы:
Импортируем два AutoClass’а: AutoImageProcessor и AutoModelForImageClassification.
AutoClass (начинается с Auto) это специальный класс, который автоматически извлекает архитектуру предварительно обученной модели по ее имени или пути.Загружаем картинку по URL.
Загружаем ImageProcessor. Это аналог токенайзера, но только для картинок — выравнивает размеры картинок, нормализует и т.д. (об ImageProcessor чуть подробнее ниже). В предыдущем варианте предобработкой занимался сам Pipeline где-то в своих недрах. Сейчас же нам придется заниматься этим самостоятельно.
Загружаем модель. Сама модель представляет собой PyTorch nn.Module, который вы можете использовать как обычно при работе с торчом.
Обрабатываем картинку посредством ImageProcessor. ImageProcessor возвращает словарь, который подаем на вход модели с оператором распаковки (**).
Все модели Transformers возвращают логиты, которые идут перед последней функцией активации (например, softmax). Соответственно, нам самим необходимо их обработать, чтобы получить на выходе вероятность или класс.
Автоматическое определение архитектуры
Для каждой архитектуры и каждой задачи под нее есть свой специальный именной класс. Например: BertForSequenceClassification, GPT2ForSequenceClassification, RobertaForSequenceClassification и т.д. Также и для их предобработчиков: BertTokenizer, .GPT2Tokenizer и т.д.
Чтобы каждый раз не заморачиваться с определением точного названия класса в Transformers завезли так называемый AutoClass. AutoClass позволяет автоматически считывать всю метаинформацию (архитектуру и пр.) из предварительно обученной модели при ее загрузке:
img_proc = AutoImageProcessor.from_pretrained( 'google/vit-base-patch16-224') model = AutoModelForImageClassification.from_pretrained( 'google/vit-base-patch16-224') tokenizer = AutoTokenizer.from_pretrained( 'SkolkovoInstitute/russian_toxicity_classifier') model = AutoModelForSequenceClassification.from_pretrained( 'SkolkovoInstitute/russian_toxicity_classifier')
Каждый автокласс привязан к определенной задаче. С полным списком автоклассов можете ознакомится здесь: https://huggingface.co/docs/transformers/main/en/model_doc/auto
Если вы обучаете модель с нуля, то вам нужно импортировать точный конечный класс.
Дообучение
Не часто вам потребуются модели как есть. В соревнованиях, а тем более в работе вам скорее всего придется дообучить модель на своем датасете. И тут вас есть несколько вариантов…
Trainer
Самый простой способ - воспользоваться классом Trainer. Это аналог Pipeline’а. Только он предназначен для организации упрощенного процесса обучения.
import datasets import evaluate import pandas as pd import numpy as np from datasets import Dataset from sklearn.model_selection import train_test_split from transformers import (AutoTokenizer, AutoModelForSequenceClassification, TrainingArguments, Trainer) # Загружаем данные df = pd.read_csv('toxic.csv') df.columns = ['text','label'] df['label'] = df['label'].astype(int) # Конвертируем датафрейм в Dataset train, test = train_test_split(df, test_size=0.3) train = Dataset.from_pandas(train) test = Dataset.from_pandas(test) # Выполняем предобработку текста tokenizer = AutoTokenizer.from_pretrained( 'SkolkovoInstitute/russian_toxicity_classifier') def tokenize_function(examples): return tokenizer(examples['text'], padding='max_length', truncation=True) tokenized_train = train.map(tokenize_function) tokenized_test = test.map(tokenize_function) # Загружаем предобученную модель model = AutoModelForSequenceClassification.from_pretrained( 'SkolkovoInstitute/russian_toxicity_classifier', num_labels=2) # Задаем параметры обучения training_args = TrainingArguments( output_dir = 'test_trainer_log', evaluation_strategy = 'epoch', per_device_train_batch_size = 6, per_device_eval_batch_size = 6, num_train_epochs = 5, report_to='none') # Определяем как считать метрику metric = evaluate.load('f1') def compute_metrics(eval_pred): logits, labels = eval_pred predictions = np.argmax(logits, axis=-1) return metric.compute(predictions=predictions, references=labels) # Выполняем обучение trainer = Trainer( model = model, args = training_args, train_dataset = tokenized_train, eval_dataset = tokenized_test, compute_metrics = compute_metrics) trainer.train() # Сохраняем модель save_directory = './pt_save_pretrained' #tokenizer.save_pretrained(save_directory) model.save_pretrained(save_directory) #alternatively save the trainer #trainer.save_model('CustomModels/CustomHamSpam')
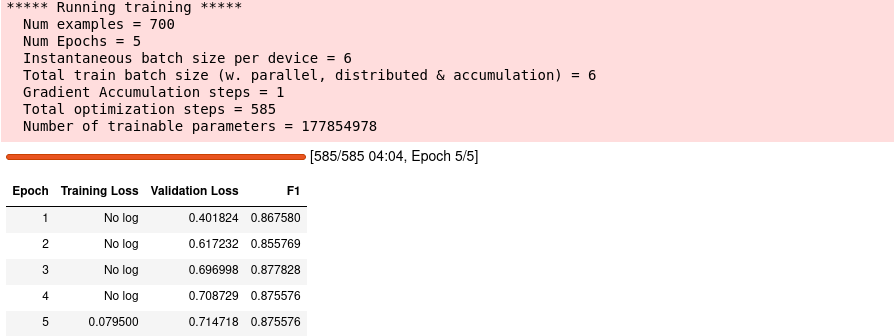
Что мы тут делаем:
Загружаем данные в пандас.
Переводим датафрейм в класс Dataset, которые можно подавать на вход модели при обучении.
Применяем к каждой строке датасета (тексту) токенизатор, чтобы перевести его в массив чисел.
Подгружаем предварительно обученную модель.
Определяем экземпляр класса TrainingArguments. В нем задаются гиперпараметры, которые будут использоваться при обучении модели, а также специальные флаги, которые активируют различные варианты обучения.
Т.к. класс универсальный и предназначен для обучения разных архитектур и задач, то параметров у него довольно много. Подробнее ознакомится с ними можете здесь: https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArgumentsСейчас зададим только: куда сохранять промежуточные результаты во время обучения, стратегию обучения (в данном случае — по эпохам), кол-во эпох и размер батча.
Посредством модуля Evaluate определяем интересующую нас метрику и задаем функцию, которая будет выполнять расчет в процессе обучения.
З.Ы. Не забываем что все модели возвращают логиты, которые необходимо соответствующим образом преобразовать.
Использовать библиотеку Evaluate не обязательно. Можно хоть из скалерна брать метрики. Главно определить функцию, которая будет производить расчеты.
Список доступных метрик: https://huggingface.co/evaluate-metric
тут же вы можете с ними поэкспериментировать.Создаем объект Trainer и подгружаем в него все ранее определенные компоненты: модель, аргументы, датасеты, функцию оценки. И запускаем обучение.
После обучения сохраняем результат на диск.
В последующем мы можем загрузить нашу модель так:
model = AutoModelForSequenceClassification.from_pretrained( './pt_save_pretrained')
Trainer поддерживает поиск гиперпараметров посредством специализированных пакетов: optuna, sigopt, raytune и wandb. Более подрбно: https://huggingface.co/docs/transformers/hpo_train
PyTorch
Теперь задействуем классический алгоритм обучения на торче:
import torch import evaluate import pandas as pd from tqdm.auto import tqdm from datasets import Dataset from torch.optim import AdamW from torch.utils.data import DataLoader from sklearn.model_selection import train_test_split from transformers import (AutoTokenizer, AutoModelForSequenceClassification, get_scheduler) # Загружаем данные df = pd.read_csv('toxic.csv') df.columns = ['text','label'] df['label'] = df['label'].astype(int) # Конвертируем датафрейм в Dataset train, test = train_test_split(df, test_size=0.2) train = Dataset.from_pandas(train) test = Dataset.from_pandas(test) # Выполняем предобработку текста tokenizer = AutoTokenizer.from_pretrained( 'SkolkovoInstitute/russian_toxicity_classifier') def tokenize_function(examples): return tokenizer(examples['text'], padding='max_length', truncation=True) def ds_preproc(ds): ds = ds.map(tokenize_function) ds = ds.remove_columns(['text', 'index_level_0']) ds = ds.rename_column('label', 'labels') ds.set_format('torch') return ds tokenized_train = ds_preproc(train) tokenized_test = ds_preproc(test) # Создаем даталоадер train_dataloader = DataLoader(tokenized_train, shuffle=True, batch_size=8) test_dataloader = DataLoader(tokenized_test, batch_size=8) # Загружаем модель и указываем кол-во классов model = AutoModelForSequenceClassification.from_pretrained( 'SkolkovoInstitute/russian_toxicity_classifier', num_labels=2) # Задаем оптимайзер и шедулер optimizer = AdamW(model.parameters(), lr=5e-6) num_epochs = 5 num_training_steps = num_epochs * len(train_dataloader) lr_scheduler = get_scheduler( name = 'linear', optimizer = optimizer, num_warmup_steps = 0, num_training_steps = num_training_steps) device = 'cuda' model.to(device) # Выполняем цикл... for epoch in tqdm(range(num_epochs)): #... обучения model.train() for batch in tqdm(train_dataloader, leave=False): batch = {k: v.to(device) for k, v in batch.items()} outputs = model(**batch) loss = outputs.loss loss.backward() optimizer.step() lr_scheduler.step() optimizer.zero_grad() #... оценки metric = evaluate.load('f1') model.eval() for batch in tqdm(test_dataloader, leave=False): batch = {k: v.to(device) for k, v in batch.items()} with torch.no_grad(): outputs = model(**batch) logits = outputs.logits predictions = torch.argmax(logits, dim=-1) metric.add_batch(predictions=predictions, references=batch['labels']) print(f'epoch {epoch} -', metric.compute()) # Сохраняем модель save_directory = './pt_save_pretrained' model.save_pretrained(save_directory)
Этот пайплайн не сильно отличается от других процессов обучения нейронных сетей:
Загружаем датасет в пандас, разбиваем на трейн/тест.
Конвертируем датафрейм в класс Dataset, который принимает на вход модель.
Переводим текст в токены, токены в массив чисел. Также очищаем датасет от лишних полей (иначе модель будет ругаться).
Формируем DataLoader для тренировочных и тестовых данных, чтобы мы могли
Определяем оптимизатор и шедулер.
Загружаем модель и указываем кол-во классов, которые должна выучить модель.
Задаем оптимизатор и планировщик. Причем оптимизатор родной для торча, а планировщик из библиотеки трансформеров.
Итерируемся по эпохам. На каждой выполняем цикл обучения и цикл оценки.
Сохраняем модель на диске.
Эмбединги
Третий способ дообучить модель — вытащить из нее эмбеддинги (актуально для NLP задач) и обучить какую-либо классическую модель, используя эти эмбединги как фичи.
Вытащить эмбединги можно двумя способами.
Первый - ручной:
import torch import pandas as pd from transformers import AutoTokenizer, AutoModel #Mean Pooling - Take attention mask into account for correct averaging def mean_pooling(model_output, attention_mask): token_embeddings = model_output[0] #First element of model_output contains all token embeddings input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float() sum_embeddings = torch.sum(token_embeddings * input_mask_expanded, 1) sum_mask = torch.clamp(input_mask_expanded.sum(1), min=1e-9) return sum_embeddings / sum_mask #Sentences we want sentence embeddings for sentences = ['This framework generates embeddings for each input sentence', 'Sentences are passed as a list of string.', 'The quick brown fox jumps over the lazy dog.'] #Load AutoModel from huggingface model repository tokenizer = AutoTokenizer.from_pretrained( 'sentence-transformers/all-MiniLM-L6-v2') model = AutoModel.from_pretrained( 'sentence-transformers/all-MiniLM-L6-v2') #Tokenize sentences encoded_input = tokenizer( sentences, padding=True, truncation=True, max_length=128, return_tensors='pt') #Compute token embeddings with torch.no_grad(): model_output = model(encoded_input) #Perform pooling. In this case, mean pooling sentence_embeddings = mean_pooling( model_output, encoded_input['attention_mask']) df = pd.DataFrame(sentence_embeddings).astype('float')
Альтернативно можно задействовать отдельную библиотеку — SentenceTransformers (ставится через пип):
from sentence_transformers import SentenceTransformer model = SentenceTransformer('SkolkovoInstitute/russian_toxicity_classifier') text = ['У нас в есть убунты и текникал превью.', 'Как минимум два малолетних дегенерата в треде, мда.'] embeddings = model.encode(text) df = pd.DataFrame(embeddings)

Как видите, SentenceTransformers может подгружать нужные модели с хаба Hugging Face.
Предварительная обработка
Чуть поподробнее разберем в чем заключается предварительная обработка текста и картинок…
Токенайзер
Токенайзер используется в моделях, которые так или иначе работают с текстом. Компьютер не умеет напрямую работать с текстом - только с числами. И тут в дело вступает токенайзер: он преобразует текст в массив чисел, которые затем поступают на вход модели.
По сути каждый токенайзер состоит из набора правил и глобально эти правила решают две задачи:
Как поделить предложение на токены. В самом простом случае поделить можно на слова, а критерий разделения - пробел. Но в действительности способов гораздо больше и они довольно сложные.
Как привести разнородные предложения к одной длине. Очевидно что тексты бывают разной длины. Но все последовательности, подаваемые на вход модели должны иметь одинаковую длину.
Сначала посмотрим как токенайзер разбивает предложение на токены:
from transformers import AutoTokenizer tokenizer = AutoTokenizer.from_pretrained( 'SkolkovoInstitute/russian_toxicity_classifier') tokenizer.tokenize('У нас в есть убунты и текникал превью.') #вывод ['У','нас','в','есть','убу','##нты','и','тек','##ника','##л','превью','.']
Обратите внимание на значки # в токенах. Так токенайзер выделяет подслова в словах. Это сделано, чтобы не запоминать кучу редких слов и уменьшить хранимый словарный запас. Также это позволяет модели обрабатывать слова, которые она никогда раньше не видела.
Это один из видов токенизации. Всего в трансформерах используются три основных вида токенизации: Byte-Pair Encoding (BPE), WordPiece, SentencePiece.
Теперь посмотрим, что подается на вход модели:
text = 'У нас в есть убунты и текникал превью.' encoding = tokenizer(text) print(encoding) #вывод 'input_ids': [101, 486, 1159, 340, 999, 63692, 10285, 322, 3100, 1352, 343, 85379, 132, 102] 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
Токенайзер возвращает словарь, содержащий:
input_ids — массив чисел, каждое из которых соответствует одному токену.
attention_mask — указывает модели, какие токены следует учитывать, а какие игнорировать.
token_type_ids — используется в специальных моделях, в которые подаются пары последовательностей. Например, вопрос-ответ. Тогда в token_type_ids эти две последовательности будут обозначены разными метками.
Данный словарь подается на вход модели с оператором распаковки (**).
Теперь посмотрим как токенайзер выравнивает длину предложений. За это отвечают три параметра:
padding — тензоры подаваемые в модель должны иметь одинаковую длину. Если этот параметр = True, то коротки последовательности дополняются служебными токенами до длины самой длинной последовательности.
truncation — очень длинные последовательности тоже плохо. Если параметр = True, то все последовательности усекаются до максимальной длины.
max_length — указываем до скольки токенов усекать последовательность.
text = ['У нас в есть убунты', 'Как минимум два малолетних дегенерата в треде, мда.'] encoding = tokenizer( text, padding=True, truncation=True, max_length=512) print(encoding) #вывод {'input_ids': [ [101, 486, 1159, 340, 999, 63692, 10285, 102, 0, 0, 0, 0, 0], [101, 1235, 3932, 1617, 53502, 97527, 303, 340, 39685, 128, 48557, 132, 102]], 'token_type_ids': [ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]], 'attention_mask': [ [1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}
Обратите внимание, что каждая последовательность представлена одинаковым количеством чисел (выровнены по самому длинному предложению). При этом короткие предложения дополнены нулями. А чтобы модель не обращала на них внимания, соответствующие токены в attention_mask обозначены нулями.
По каким правилам происходит усечение и дополнение токенов читайте здесь: https://huggingface.co/docs/transformers/main/en/pad_truncation
ImageProcessor
ImageProcessor отвечает за подготовку данных CV задач. Его работа несколько проще. По сути он переводит все пиксели в числа и при необходимости выравнивает изображения до одинаковой длины/ширины.
from transformers import AutoImageProcessor from PIL import Image from io import BytesIO import requests response = requests.get( 'https://github.com/laxmimerit/dog-cat-full-dataset/blob/master/data/train/cats/cat.10055.jpg?raw=true') img = Image.open(BytesIO(response.content)) image_processor = AutoImageProcessor.from_pretrained( 'google/vit-base-patch16-224') inputs = image_processor(img, return_tensors='pt') #вывод {'pixel_values': tensor([[[[ 0.4275, 0.4275, 0.4196, ..., 0.0902, 0.1216, 0.0667], [ 0.4431, 0.4353, 0.4118, ..., 0.0902, 0.0588, 0.0118], [ 0.4431, 0.4353, 0.4039, ..., 0.1686, 0.1059, 0.0431], ..., [-0.1373, -0.0745, -0.0431, ..., 0.2941, 0.2863, 0.2627], [-0.1529, -0.1137, -0.0588, ..., 0.2784, 0.2627, 0.2627], [-0.1529, -0.1294, -0.0745, ..., 0.2706, 0.2392, 0.2392]], [[ 0.4275, 0.4431, 0.4588, ..., 0.0275, 0.0667, 0.0588], [ 0.4431, 0.4510, 0.4510, ..., 0.0275, 0.0039, 0.0039], [ 0.4431, 0.4431, 0.4431, ..., 0.1059, 0.0510, 0.0275], ..., [-0.2392, -0.1765, -0.1451, ..., 0.1922, 0.1922, 0.1765], [-0.2549, -0.2157, -0.1608, ..., 0.1765, 0.1765, 0.1922], [-0.2549, -0.2314, -0.1765, ..., 0.1686, 0.1529, 0.1765]], [[ 0.4431, 0.4510, 0.4275, ..., -0.0902, -0.0824, -0.0980], [ 0.4588, 0.4588, 0.4275, ..., -0.0980, -0.1451, -0.1529], [ 0.4588, 0.4510, 0.4118, ..., -0.0196, -0.0980, -0.1294], ..., [-0.3647, -0.3020, -0.2706, ..., 0.0667, 0.0667, 0.0510], [-0.3804, -0.3490, -0.2941, ..., 0.0431, 0.0353, 0.0431], [-0.3882, -0.3647, -0.3098, ..., 0.0353, 0.0118, 0.0275]]]])}
Для некоторых моделей ImageProcessor выполняет еще и постобработку. Например, преобразует логиты в маски сегментации.
Прочее
Шаринг
Если вы обучили/дообучили хорошую модель, то можете поделиться ею с сообществом. Подробная инструкция как это сделать: https://huggingface.co/docs/transformers/model_sharing
Также вы можете создать и загрузить в хаб Hugging Face свой кастомный Pipeline: https://huggingface.co/docs/transformers/main/en/add_new_pipeline#how-to-create-a-custom-pipeline
Датасеты
Платформа Hugging Face предоставляет много готовых датасетов для аудио, CV и NLP задач, которые вы можете использовать для своих целей. Найти нужный датасет вы сможете в специальном хабе. По аналогии с моделями воспользуйтесь фильтрами, чтобы отыскать нужный вам датасет:
https://huggingface.co/datasets
Загружать примерно так:
from datasets import load_dataset dataset = load_dataset('rotten_tomatoes')
Более подробно изучить функционал датасетов сможете здесь: https://huggingface.co/docs/datasets/index
Что дальше?
А дальше изучаем и воспроизводим кучу готовых примеров:
https://huggingface.co/docs/transformers/community#community-notebooks
https://github.com/huggingface/transformers/tree/main/examples
Отдельно стоит отметить целый курс, посвященный трансформерам: https://huggingface.co/course/chapter1/1

Код из статьи: https://github.com/slivka83/article/blob/main/transformers/Transformers.ipynb
Мои курсы: Разработка LLM с нуля | Алгоритмы Машинного обучения с нуля

