
Привет, Хабр! Меня зовут Артур Темиров, я delivery‑менеджер в одном из продуктов X5 (о нём дальше в тексте). Над его созданием у нас трудятся 5 технических команд — в общей сложности это более 60 человек. В статье рассказываю о том, как визуализация является отправной точкой для эволюционного развития процессов, а также об ошибках, которые могут допускаться на этом пути.
Я не ставлю перед собой цели рассказать про успешное внедрение чего бы то ни было, про лучшие практики, которые всем подойдут и надо использовать именно их. Я вообще буду стараться не давать какие‑либо советы и, скорее, даже настаиваю на том, что это мой личный опыт и любое его повторение может (и будет) развиваться по другому сценарию. Заваривайте чай, наливайте свежесваренный кофе, готовьте смузи, устраивайтесь поудобнее, мы начинаем.
Контекст

Контекст очень важен, потому что он помогает понять, что может для вас сработать, а что — нет.
Мы создаём сложный IT‑продукт, под капотом которого находится достаточно большой пласт логики и данных. С помощью него бизнес‑пользователи могут сегментировать клиентскую базу, формировать и отправлять персональные предложения покупателям торговой сети «Пятёрочка», а также реализовывать различные механики по этим предложениям. На выходе благодаря нашему продукту покупатель получает наиболее интересное и выгодное предложение, а торговая сеть и поставщики — свои финансовые и маркетинговые эффекты. Команда продукта географически распределена и люди практически не пересекаются в оффлайне.
Для понимания привёл список ролей, задействованных в разработке продукта:
Роль | Количество сотрудников |
|---|---|
Бизнес-анализ | 5 |
Разработка front-end | 4 |
DevOps | 1 |
Системный анализ | 3 |
Тестирование | 6 |
Разработка back-end | 8 |
Delivery Manager | 3 |
Архитектор | 1 |
UX/UI | 2 |
Data Quality | 4 |
Data Engineering | 3 |
Data Science | 11 |
Data Analytics | 10 |
С чего всё начиналось

Ко мне обратилось руководство продукта, описав несколько проблем, с которыми они столкнулись на тот момент. Процитирую их:
У нас уходит единая точка входа в IT, нам нужна замена.
Одна из команд берёт в спринт задачи, но спустя две недели завершает 10-20% из взятых.
В целом нам не понятно, что происходит в части IT-разработки.
У бизнес-команд некому проводить ретроспективу.

Погрузившись в работу коллег, стало понятно, что между командами практически отсутствовала синхронизация. Все существовали только в рамках своих функциональных задач и не видели общую картину происходящего. Визуализация потока создания ценности отсутствовала как таковая.
Отсюда вытекало множество проблем:
Не было прозрачности взаимодействия между разными командами — визуализация заканчивалась задачами в Jira‑проектах команд, а что происходило у других команд...
Невозможно было ответить бизнесу на вопрос: «Когда будет готово?», т. к. оценка давалась каждой командой отдельно и не учитывала «передачу работы» из команды в команду.
Задачи брались в работу одной командой, после чего «вставали на холд», т. к. оказывалось, что для дальнейшей работы была нужна другая команда, которая не планировала эти работы.
Периодически происходили ситуации, когда одна команда что‑то разработала, выпустила в прод, а остальные узнавали об этом, когда от новой фичи ломался другой функционал.
Для бизнеса отсутствовала прозрачность взятия в работу новых задач.

Первые шаги

Я поставил перед собой главную цель – выстроить такую модель работы, когда общая визуализация процесса является не только единым местом правды и местом для синхронизации команд, но и источником данных, которые будут драйвером дальнейших изменений.


Оранжевые стикеры визуализировали ту самую ценность, которая была понятна бизнесу, а жёлтые стикеры показывали задачи, которые надо сделать в команде или командах для реализации этой ценности.
Визуализировав таким образом нашу работу, мы поставили еженедельные встречи, в ходе которых мы синхронизировались по задачам, находящимся в работе.
Дополнительно руками начали собирать «сырые» данные по задачам с целью дальнейшего построения метрик производства, а именно: накопительную диаграмму потока, спектральную диаграмму, контрольную диаграмму и пропускную способность. В конце статьи поделюсь шаблоном в Google Sheets — возможно, кому‑нибудь пригодится.
Про ошибки

Однако, всё было не так радужно, как может показаться. Поэтому считаю правильным поделиться и ошибками, которые допускались в процессе достижения цели. Основной ошибкой было то, как именно создавалась доска. Часть этапов на визуализации — мои галлюцинации. В продукте не было таких процессов, но на тот момент они казались такими нужными, и я не смог удержаться от искушения и не «запихнуть» их — ведь всем от этого будет лучше, да? НЕТ! Именно поэтому достаточно длительное время к доске не было эмпатии, у неё даже было имя «доска Артура» — думаю, это о многом говорит:‑) Да и в целом у людей не было понимания, для чего всё это делается.
Чтобы такого не возникло, правильным решением, я считаю, нужно проводить STATIK. Подробнее о нём написано: тут и тут. В нашем случае понимание ценности от такого решения пришло спустя примерно три месяца.
Следующий шаг
Дальше в нашей жизни появился Kaiten (не реклама, но если мне заплатят, я не против), в который мы перенесли все наши задачи.

Какое‑то время мы работали над улучшением визуализации нашего рабочего процесса:
Улучшали визуализацию карточек рабочих элементов. Цель улучшений — прозрачность всего пути создания ценности. В карточке хранятся: связи с дочерними элементами (те самые задачи в командах), бриф с этапа дискавери, бизнес‑требования, User Story (пишутся после БТ в некоторых командах), плановый и фактический срок реализации, метки, показывающие как системы, в которых идёт разработка, так и другую полезную для участников процесса информацию.
Убирали лишние этапы. Сделали процесс больше похожим на то, как он выглядит в реальности — без галлюцинаций.
Появилась встреча по пополнению системы. На этой встрече в присутствии всех заинтересованных принимается решение о том, какие задачи будут взяты в производство следующими. Деливери‑менеджер в начале встречи говорит, сколько задач можем взять в работу, а далее всеми заинтересованными принимается решение, что брать следующим. Это даёт прозрачность как бизнесу, так и представителям технических команд — можно лучше планировать свою работу.
Что дальше

Появившаяся визуализация послужила драйвером для дальнейших улучшений самого процесса.
Встречи по пополнению сначала проходили в формате «берём в работу задачи тех, кто громче кричит». Думаю, не стоит говорить о том, чем плох такой подход. Поэтому у нас появился скоринг задач по RICE и задачи на встрече по пополнению стали брать в работу, ориентируясь, в первую очередь, на скоринг.
Бизнесом регулярно стал подниматься вопрос: «Когда будет готово?». На тот момент мы не понимали реальных возможностей нашей системы, и давать сроки, ориентируясь на статистику, ещё не могли. В итоге мы решили в качестве эксперимента давать экспертные сроки. Результат: большая часть задач была просрочена, что подтвердило озвученное ранее — экспертные сроки не работают, т. к. не учитываются риски.
Пока шёл эксперимент с экспертной оценкой, у нас накопилось достаточно статистики и появилась новая встреча «Обзор сервиса поставки» — встреча, на которой мы все вместе смотрим на метрики производства, чтобы понять текущие возможности нашей системы и обсудить изменения в процессах или правилах. После серии таких встреч мы договорились перейти от экспертной оценки сроков к статистической, ориентируясь на 85-й процентиль.
Ответ на извечный вопрос был дан, но вот люди восприняли его по‑своему. С первого раза (да и со второго тоже) не удалось объяснить, что есть определённая вероятность времени выполнения задач и мы даём оценку, ориентируясь на эту вероятность. В нашем случае 85-й процентиль составлял 130 дней, которые трактовались так, что все задачи будут сделаны за 130 дней — не больше и не меньше. И это вносило свои сложности в коммуникацию.
Не могу сказать, что сейчас все одинаково понимают, что означает 85-й процентиль, но мы регулярно на «Обзорах сервиса поставки» проводим просветительскую работу. Хочется верить, что тот нарратив, который создаётся на встречах, сможет нам помочь прийти к одинаковому пониманию подхода к статистической оценке сроков.
Читателю готов предложить погрузиться в мир статистической оценки сроков, посмотрев эти видео:
Улучшение процесса за счёт работы с блокерами
Отдельно хочется рассказать про то, как мы выстроили процесс работы с блокерами. К сожалению, тут нас Kaiten подвёл: его функционал отчётности не смог предоставить нужные разрезы данных, поэтому мы самостоятельно руками готовим отчёт по блокерам в Google Sheets, а потом отдаём файл в BI.

В отчёте можно увидеть топ по количеству блокеров. Но, помимо количества, мы смотрим на сумму потраченного времени по этим кластерам, чтобы иметь более взвешенную картину.
Что мы получили от работы с блокерами
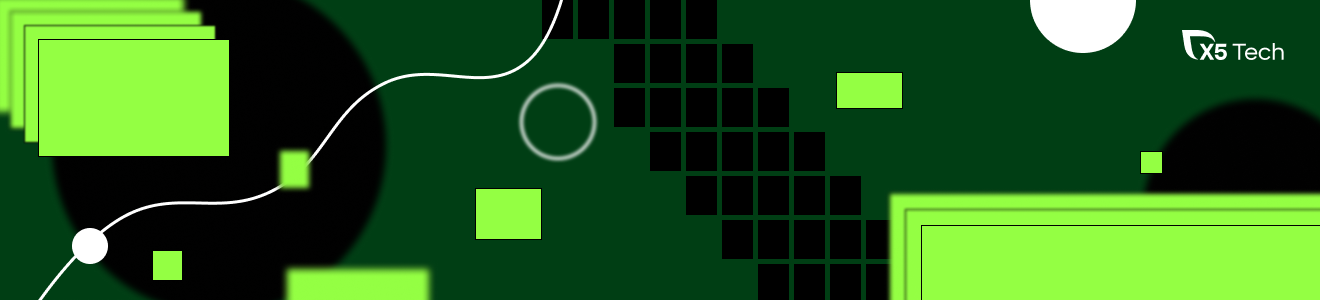
На примере блокера «Нет рук» мы договорились о внедрении WIP-лимитов (ранее их не было).
Узнать, что такое WIP-лимиты можно из этого видео:
Обоснование необходимости ограничить производство послужило два графика: количество блокеров «Нет рук» и сумма потраченного на него времени.
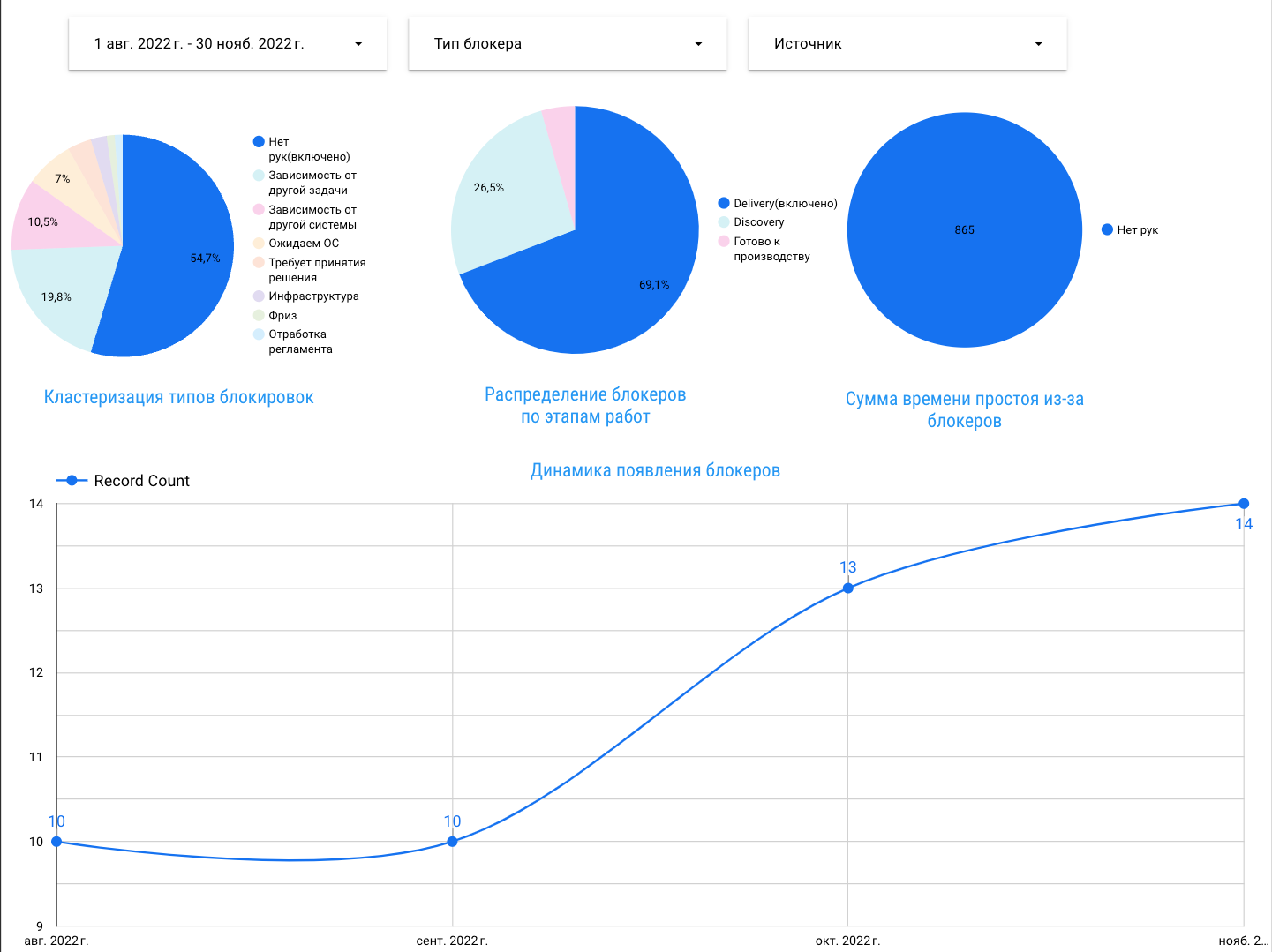
Можно проследить зависимость роста WIP и увеличения количества блокеров до ноября, с дальнейшим сокращением WIP после введения WIP-лимита:
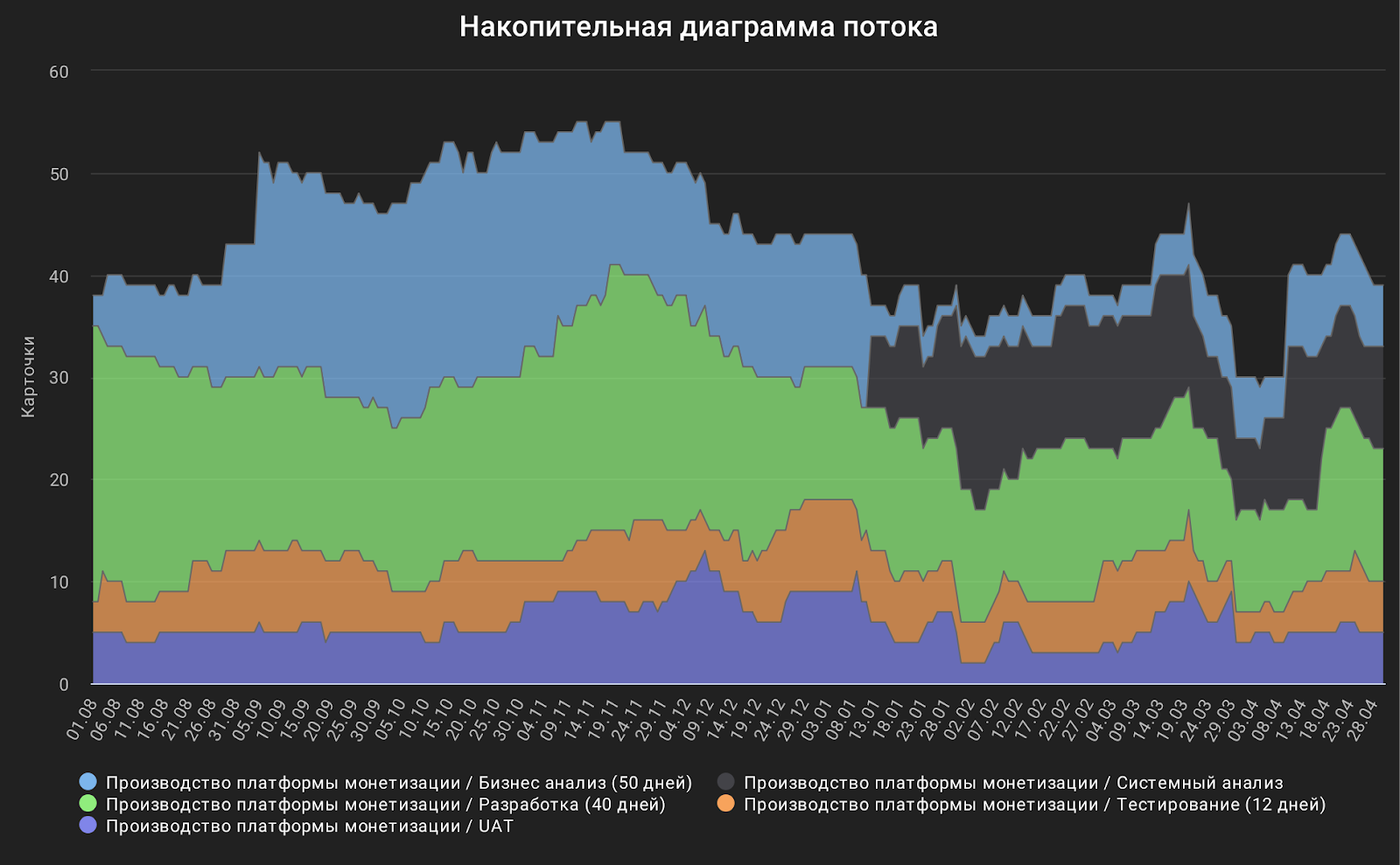
Приведу отчётность по блокерам после ноября. Тут достаточно интересная ситуация. Видно, что картина по блокерам у нас ухудшилась и кажется, что принятые меры не помогли. Но реальность оказалась другой. Увидев пользу от блокеров и возможность обсудить возникающие проблемы, началась более ответственная фиксация блокеров, т. е. качество собираемых нами данными тоже начало расти со всеми вытекающими.

Второй по популярности блокер – «Зависимость от другой задачи». Это ситуация, когда задача взята в разработку, но конфликтует с другой задачей, т. к. в процессе разработки затрагивается один функционал и параллельная разработка невозможна.
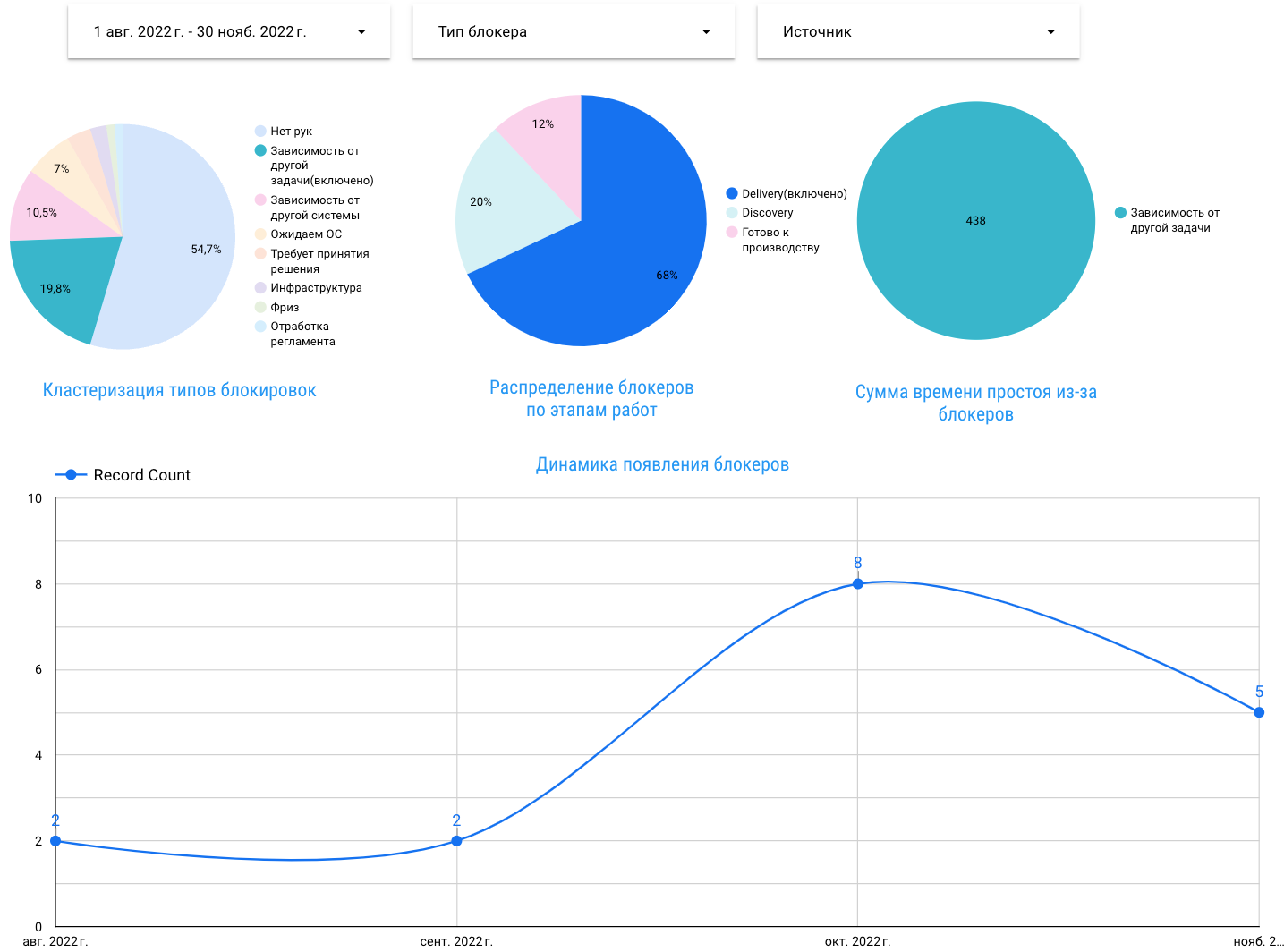
В данном случае мы договорились об улучшении этапа дискавери, где по результату мы понимаем возможное влияние на микросервисы и при пополнении delivery‑системы учитываем эти нюансы перед взятием задач в работу. Кстати, описанная проблема обозначила нам точки роста для оптимизации в архитектуре нашего приложения.
И опять статистика после изменений показывает, что цифры не сильно изменились. Тут уже двоякая ситуация. Во‑первых, это улучшение качества фиксации блокеров. Во‑вторых, мы ещё находимся в процессе выстраивания Discovery и нам явно есть куда расти.
В качестве заключения
В статье я умышленно не упоминал Kanban‑метод, практиками и принципами которого я руководствовался в своей работе. Но, наверное, в заключение можно сказать спасибо методу и процитировать @pimenaus: что Kanban‑доски — это не только доски и стикеры, а значительное большее. Kanban‑доски дают нам визуализацию процесса работы, которая начинает показывать проблемные места, благодаря чему можно строить системную работу по эволюционным изменениям наших процессов.
Как и обещал, прикладываю ссылку на шаблон в Google Sheets.
