
В настоящее время искусственный интеллект (ИИ) стремительно развивается. Мы являемся свидетелями интеллектуальной мощи таких нейросетей, как GPT-4 Turbo от OpenAI и Gemini Ultra от Google. В Интернете появляется огромное количество научных и популярных публикаций. Зачем же нужна еще одна статья про ИИ? Играя с ребенком в ChatGPT, я неожиданно осознал, что не понимаю значения аббревиатуры GPT. И, казалось бы, простая задача для айтишника, неожиданно превратилась в нетривиальное исследование архитектур современных нейросетей, которым я и хочу поделиться. Сгенерированная ИИ картинка будет еще долго напоминать мою задумчивость при взгляде на многообразие и сложность современных нейросетей.
План статьи
Виды нейросетей:
GPT - Generative Pre-trained Transformer
Generative Pre-trained Transformer:
Generative - понятный термин говорит о том, что нейросеть что-то генерирует. В случае ChatGPT генерируется текст, другие генеративные нейросети могут генерировать картинки, музыку, видео и т.д.
Pre-trained - тоже понятный термин, но, кажется, лишним уточнением, т.к. если модель ИИ предварительно не обучена, то она бессмысленна для практического применения.
Transformer - это архитектура нейросети, которая использует структуру encoder - decoder с механизмом внимания. Вот тут и произошла заминка в понимании, начинаем разбираться сначала!
Задачи ИИ и архитектуры нейросетей
За последние несколько лет нейросети научились хорошо решать несколько классов задач:
Задачи обработки естественного языка Natural Language Processing (NLP) такие как:
Понимание и генерация естественного языка (Natural-language understanding (NLU) и Natural-language generation (NLG))
Генерация изображений по текстовому описанию
Машинный перевод (Machine translation (MT)), и многие другие.
Распознавание изображений.
В настоящее время удачно сложилось несколько факторов, которые и способствовали качественным успехам в работе нейронных сетей в этих направлениях:
Современные компании и государства имеют доступ к мощным вычислительным ресурсам.
В Интернете накопилось большое количество данных, что позволило создать наборы данных для обучения нейросетей (датасеты).
Особенности архитектуры современных сетей:
Открытие новых способов представления и обработки информации.
Возможность ускорить исследования с помощью Transfer Learning. Это метод, который позволяет использовать предварительно обученные модели нейронных сетей для применения к другим задачам.
Возможность использовать для обучения нейросетей параллельные вычисления.
Для каждого класса задач обычно применяются свои типы нейросетей:
Для задач NLP - это рекуррентные нейросети (RNN) и трансформеры.
Для генерации визуальной информации - RNN, генеративные состязательные сети (GAN), Diffusion и трансформеры.
Для распознавания изображений - сверточные нейросети (CNN).
Видно, что некоторые архитектуры нейросетей универсальны и используются для решения нескольких классов задач. Рассмотрим подробнее основные современные архитектуры, но начнем с классических нейросетей, чтобы было легче понять их эволюцию.
Эволюция нейросетей
Нейроны
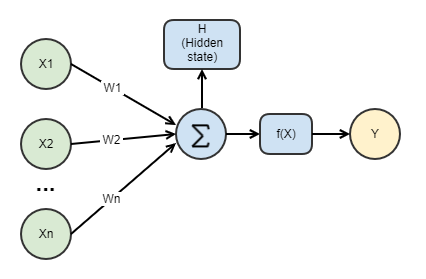
Традиционные нейросети состояли из персептронов. Персептрон - условная модель нейрона мозга человека. На схеме классический персептрон, у которого n входных параметров X, которые нейрон умножает на n весов W, суммирует и далее использует функцию активации f(X) для получения выходного значения Y:

Традиционные нейросети FFNN (Feed forward neural networks)
В любой нейронной сети есть входной слой нейронов, выходной слой и один или несколько скрытых слоев. Такие сети называют Multi-layer Perceptron (MLP). Они являются полносвязными, т.е. все нейроны в слое связаны со всеми нейронами следующего слоя, но нейроны в одном слое не связаны друг с другом. MLP обычно визуализируются подобными схемами:
")
При работе нейросети сигнал передается от входов к выходам, поэтому такие сети еще называют сетями прямого распространения Feed forward neural networks, (FFNN). Обучаются FFNN сети методом градиентного спуска и обратного распространения ошибки (backpropagation).
Теперь рассмотрим эволюцию методов решения задач с помощью нейросетей.
Традиционный подход в решении задач NLP
Традиционные решения задач обработки естественного языка опираются на следующие языковые модели построения представления текстов и предложений:
VSM (Vector Space Model)
n-граммы (n-gram)
В модели VSM языковой корпус - это набор документов, каждый из которых представляется неупорядоченным набором слов (мешок слов, Bag of Words, BoW). В результате получается матрица, которую называют документ - термин (document-term matrix). Это матрица, в которой каждая строка - это документ из корпуса, колонка - это слово из словаря корпуса, а в ячейку записывается вероятность, с которой слово встречается в документе. Получается, что каждая строка - это вектор в векторном пространстве. Для наглядности приведу пример для корпуса из трех предложений:
d1 = "the fat cat sat on the mat"
d2 = "the big cat slept"
d3 = "the dog chased a cat"
Матрица документ - термин будет следующая:

В модели n-грамм каждое слово представлено в виде набора n-грамм символов. Модель для каждой n-граммы задает постоянный вектор и представляет слова как суммы векторов их частей. Основной плюс традиционных моделей - это простота создания и использования, но минусов гораздо больше:
В моделях не учитывает порядок слов;
Стремительный рост размерности при росте словаря;
Разреженные векторы на больших словарях;
Медленно работают с большими словарями;
Нет решения для новых слов, которые отсутствуют в обучающем корпусе;
Модель Word2vec решила проблему размерности, создавая короткие и плотные представления слов, которые называются векторным представлением (word embedding). Это представление компактно и использует не тысячи, а сотни знаков. А главное, с его помощью кодируется смысл, т.е. вектора с похожими смыслами располагаются рядом в пространстве и с похожим направлением. На картинке показано, что при представлении слов в виде embeddings модель понимает, что смысл отношения слов мужчина - женщина похож на смысл отношения слов король - королева. К таким векторам можно применять стандартные математические операции. Например, можно выполнить операцию "король" минус "мужчина" плюс "женщина", и результат будет близок к слову "королева":
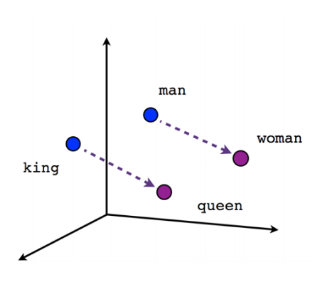
Общая концепция работы - модель смотрит на окружение слов, с помощью векторного представления слов кодирует предложения и решает проблему многозначности. В нейросетях для этих задач используются слои нейронов и применяются стандартные матричные операции. Первые сети, которые использовали данный подход были рекуррентные нейросети RNN.
Рекуррентные нейросети RNN (Recurrent neural networks)
Recurrent neural networks, RNN) — это те же сети прямого распространения, но со смещением во времени: нейроны получают информацию не только от предыдущего слоя, но и от самих себя в результате предыдущего прохода R:

Из этого свойства следует, что такие сети хорошо решают задачи, связанные с последовательностями:
Понимание и генерация текстов.
Чат боты и другие диалоговые системы.
Машинный перевод текстов.
Распознавание речи и музыки.
Описание содержимого картинок или видео.
Существует несколько архитектур, развивающих идею рекуррентных нейросетей:
LSTM (Long short-term memory)
Архитектура LSTM используют фильтры (gates) и блоки памяти (memory cells). Наличие фильтра забывания на первый взгляд кажется странным, но иногда забывать оказывается полезно: если нейросеть запоминает книгу, то в начале новой главы может быть необходимо забыть некоторых героев из предыдущей. Эти механизмы реализуются в скрытом состоянии нейрона H:
Управляемые рекуррентные нейроны (Gated Recurrent Units, GRU)
GRU - разновидность LSTM, которая быстрее и проще в эксплуатации. Вместо входного, выходного фильтров и фильтра забывания здесь используется фильтр обновления (update gate). Подробности работы GRU: “Text generation with an RNN”
Недостатки рекуррентных сетей:
Длительное время обучения и выполнения: Рекуррентные сети обрабатывают входные embeddings последовательно по шагам, что означает, что каждый шаг зависит от предыдущего.
Отсутствие параллелизма.
Рекуррентные сети могут столкнуться с проблемой исчезающего или взрывного градиента. Это означает, что информация о предыдущих шагах может постепенно исчезать или сильно увеличиваться, приводя к проблемам в обучении модели.
Неэффективная работа Transfer Learning. Это связано с тем, что каждый шаг зависит от предыдущего, и изменение архитектуры может повлиять на работу модели.
Трансформеры, в свою очередь, позволяют преодолеть эти недостатки и достичь более эффективной обработки последовательностей.
Трансформеры TNN (Transformer Neural Networks)
Задачи, которые хорошо решают трансформеры:
Обработка длинных последовательностей.
Связывание контекста и запоминание долгосрочных зависимостей.
Перевод и генерация текста.
Первое упоминание архитектуры трансформеров относится к 2017 “Attention Is All You Need”.
Механизм внимания
Механизм внимания является неотъемлемой частью в реализации трансформеров. Он обычно демонстрируются на примере задачи машинного перевода. Механизм внимания способен выявлять связи между словами в разных контекстах и помогает модели перевода правильно ассоциировать токены во входной и выходной последовательностях. В первом предложении показано, как слово "animal" во входной последовательности связывается с словом "it" в выходной последовательности. Это означает, что в данном контексте "it" относится к "animal". На втором предложении показано, что в другом контексте "it" более подходит к слову "street":

Механизм внимания не ограничивается только задачами обработки естественного языка (NLP), его также применяют в других областях и сценариях, таких как компьютерное зрение и распознавание речи. Визуализация механизма внимания часто представляется в виде схем, где главной особенностью является возможность подавать данные на вход параллельно и обрабатывать их одновременно:

Архитектура трансформеров состоит из кодировщика и декодировщика, которые в свою очередь состоят из нескольких трансформерных блоков Nx, как показано на схеме. Каждый блок трансформера содержит механизм внимания, который позволяет модели сосредоточиться на важных областях входных данных и учитывать зависимости между различными частями данных, а не только локальные закономерности.

Трансформеры могут быть следующих типов:
Encoder-only (только кодировщик): Эта архитектура трансформера состоит только из кодировщика, который преобразует входные последовательности во внутреннее представление. Такие трансформеры используются, например, для классификации текстов или анализа эмоциональной окраски текстов.
Decoder-only (только декодер): В этой версии трансформера используется только декодер, который генерирует последовательность на основе внутреннего представления или контекста. Такой тип трансформера часто используется в задачах генерации текста, например, в модели GPT.
Encoder + Decoder (кодировщик + декодировщик): Это наиболее распространенная архитектура трансформера, в которой присутствуют и кодировщик, и декодер. Эта архитектура используется в задачах машинного перевода.
При обучении трансформеров есть несколько преимуществ:
Возможность использования различных текстовых данных без необходимости предварительной разметки.
Обработка последовательностей как целого: TNN способны обрабатывать последовательности данных целиком, вместо шаг за шагом, как в рекуррентных нейронных сетях (RNN).
TNN используют механизм внимания, который помогает сети фокусироваться на наиболее важных частях последовательности и устанавливать взаимосвязи между различными элементами данных.
Transfer Learning: модели TNN, предварительно обученные на больших наборах данных, могут быть использованы для решения задач в других областях.
Т.о. получается, что трансформеры являются на сегодняшний день самой эффективной архитектурой для решения практических задач.
Сверточные нейросети CNN (Convolutional neural networks)
Первые архитектуры сверточных нейросетей появились еще в 80-х годах прошлого века. Сейчас с помощью сверточных сетей решаются следующие актуальные задачи: распознавание изображений и видео, поиск объектов и сегментация изображений, компьютерное зрение и алгоритмы в беспилотных автомобилях, распознавание объектов на рентгеновских снимках и МРТ, идентификация людей и генерация дипфейков.
Алгоритм работы сверточных сетей на примере анализа изображений:
Все сверточные сети состоят из двух частей – сверточной части, которая выделяет признаки из изображения и классификатор, который по этим признакам распознает изображение.
Изображение проходит через последовательность сверточных слоев. На каждом слое применяется набор фильтров (также называемых ядрами свертки), каждый из которых сканирует изображение с определенным шагом (шаг свертки) и выделяет признаки изображения, такие как границы или текстуры. Как результат, для каждого фильтра получается карта признаков, которая передается на следующий слой для уменьшения размерности.
Для уменьшения размерности карты признаков применяется слой субдискретизации (subsampling) или пулинга (pooling).
Далее обычно следует еще несколько сверточных слоев и слоев уменьшения размерности, которые извлекают все более абстрактные признаки из изображения.
В конце полученные карты признаков передаются в классификатор, который является обычным многослойным персептроном.
В CNN выделение признаков тоже является автоматическим процессом, что делает всю сеть нейронной.
Далее приведена визуализация алгоритма работы сверточной сети для распознавания лиц. На ней интересно посмотреть, как выглядят признаки, которые выделяет нейросеть на каждом шаге свертки:
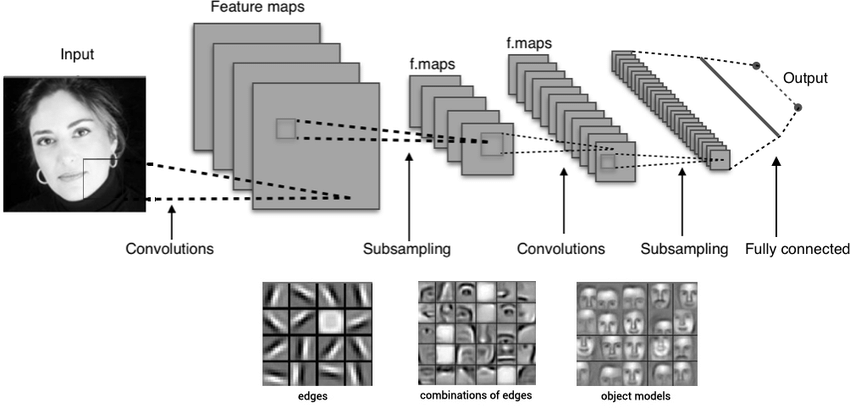
В CNN сетях эффективно применяется Transfer Learning. При использовании Transfer Learning, предварительно обученная модель фиксируется (замораживается), чтобы веса и параметры уже обученных слоев не изменялись. Затем, добавляются новые слои, которые будут адаптироваться к новому набору данных. Эти новые слои обычно обучаются на небольшом количестве данных, что экономит время и вычислительные ресурсы.
Рассмотрим пример сети AlexNet, которая была натренирована на общедоступном наборе изображений ImageNet, который содержит миллионы изображений различных категорий. Затем, эту предварительно обученную AlexNet модель натренировали для решения задачи распознавания различных типов недвижимости: коммерческой, жилой или промышленной:

Генерация изображений по текстовому описанию (Text-to-Image)
Генерация изображений по текстовому описанию является задачей NLP, в которой сначала надо понять смысл запроса, а потом сгенерировать изображение. Сейчас существует три основные модели:
Midjourney - основана на принципе генеративно-состязательных сетей (GAN).
Dall-E 2 и Stable Diffusion основаны на алгоритмах диффузи.
Хочется выделить сеть Stable Diffusion - эта модель имеет открытый исходный код, что позволяет всем изучать ее и использовать.
Генеративные состязательные сети GANs (Generative Adversarial Networks), Автоэнкодеры (Autoencoder), гибридные и мультимодальные нейросети
Для полноты картины упомяну еще несколько архитектур нейросетей
GAN (Generative Adversarial Networks) относится к семейству нейросетей, которые состоят из двух сетей, работающих вместе, где одна из сетей генерирует данные (“генератор”), а вторая — анализирует (“дискриминатор”). Используются для задач генерации изображений или музыки.
Автоэнкодер (Autoencoder) - специальный тип нейросетей, которые используются для задач автоматического обучения задачам кодирования (encoding) входных данных и последующим их декодированием (decoding) в выходные данные. Характерная черта автоэнкодеров в том, что размерность входного слоя совпадает с размерностью выходного. Применяются для задач в которых надо преобразовать входной сигнал в такой же выходной, но с новыми свойствами, например, избавиться от шума в изображении или музыке.
Гибридные сети
Нейросети, состоящие из нескольких сетей, например, трансформер + CNN, используются для сложных задач познания или моделирования реальности.
Мультимодальные сети
Мультимодальные сети - это нейронные сети, которые объединяют информацию из разных типов источников, таких как видео, текст, звук и другие, для решения сложных задач анализа данных, например, распознавание объектов в видео с аудиодорожкой или анализ эмоций в мультимодальных данных.
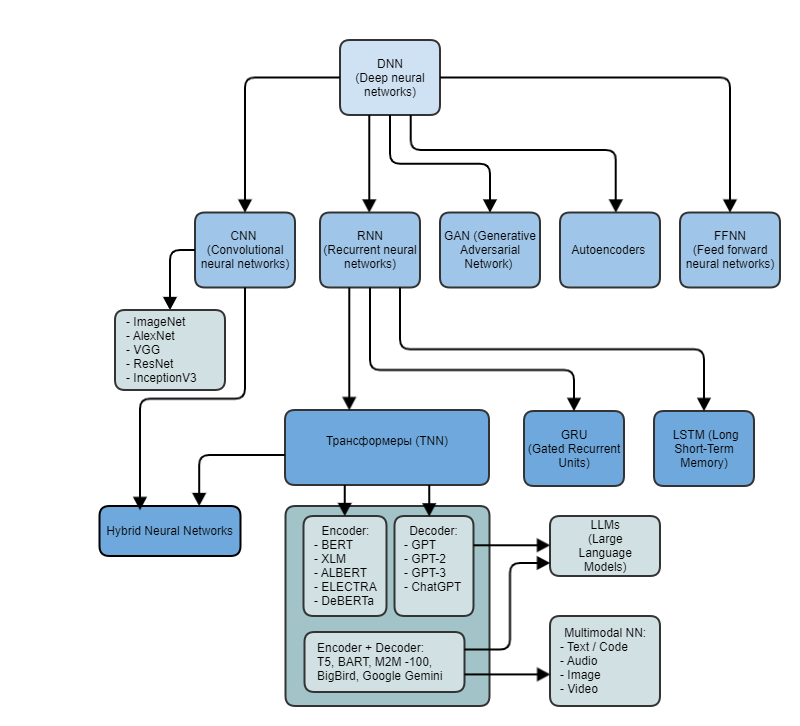
Иерархия нейросетей
Если поместить сети на одну схему, получится такая иерархия нейросетей с примерами сетей:
Заключение
Трансформеры являются на сегодняшний день самой эффективной архитектурой для решения практических задач. С помощью них можно строить large language model (LLM) и мультимодальные сети. Но чудес не бывает и нейросети требуют ясного определения задачи, которую нужно решить. Здесь важна роль человека, чтобы понять проблему, сформулировать цель и установить ожидания от сети, но это уже совсем другая история.

