
Хабр Курсы для всех
РЕКЛАМА
Практикум, Хекслет, SkyPro, авторские курсы — собрали всех и попросили скидки. Осталось выбрать!
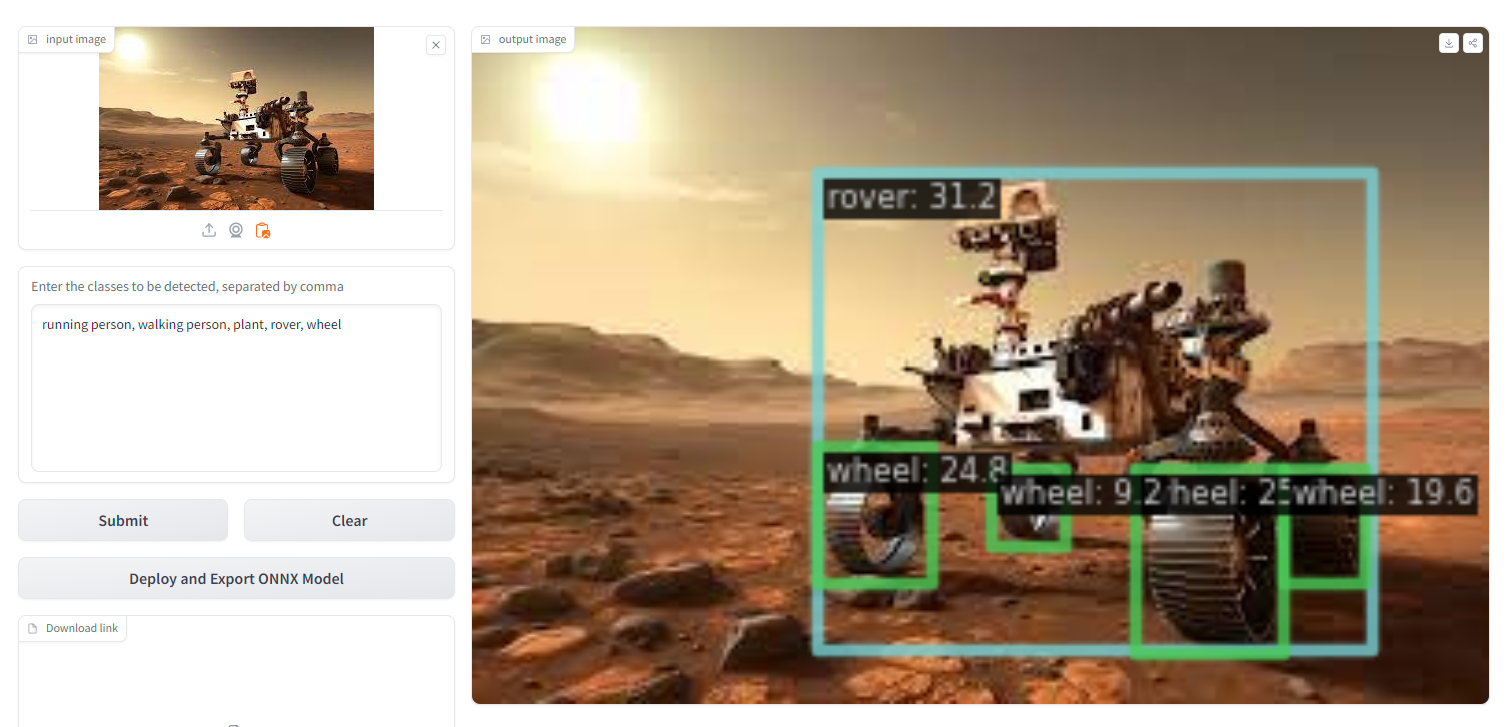
что-то я не врубился как оно работает с открытым словарём и как должно распознавать то, чему не учили. Подсунул ей картинку марсохода, добавил даже в словарь новых слов (выделил оранжевым). Всё, что она увидела на картинке - это часы, которых там нет.

Во-первых, спасибо за активный интерес к модели, очень рад ответить на возникшие вопросы!
Думаю, во многом я ответил на них в комментарии к предыдущему вопросу. Могу добавить, что для особо нетривиальных кейсов(рисунок марсохода, безусловно, к таковым отнести можно) для более точного распознавания я бы рекомендовал обучать традиционные варианты детекторов с фиксированными классами, особенно если число таких классов невелико.
При обучении OVD детекторов находить паттерны текст-картинка, хоть и использовались десятки тысяч различных пар, но все же они были основаны на классах общедоступных датасетов(ImageNet, LVIS и другие). Такие датасеты содержат некие базовые классы, поэтому "сложные" сопоставления(без дообучения) детекторы вряд ли будут находить.
Для данного кейса, я также убрал все лишнее и теперь вместо класса clock он стал находить корректный класс wheel:

Всё же она ищет среди знакомых ей классов (чуда не случилось). В чём идея обнаружения незнакомых классов и как это должно работать?

В конце пайплайна модель пытается сопоставить эмбеддинги отдельных боксов на изображении c эмбеддингами текстов из офлайн словаря. По факту, для того чтобы с высокой вероятностью правильно классифицировать объект, она должна сформировать эти векторы так, чтобы они относительно точно определяли друг друга. Но этого эффекта можно достичь, если модель в ходе обучения видела хотя бы примерно похожие сопоставления.
Например, для класса "колесо" ей нужно видеть не только колеса классических авто, но и какие-то конструкции, хотя бы отдаленно напоминающие колеса марсохода.
Таким образом, однозначно заявлять о работе модели с совсем неизвестными классами нельзя. В ходе обучения, она, как минимум, должна усвоить основные паттерны сопоставления. Но уникальность таких OVD моделей как раз в том, что они способны формировать эти паттерны, в то время как традиционные детекторы работают со строго фиксированной выборкой классов.
Касательно данного примера, то если вы точно знаете наименования классов, которые хотите искать, то имеет смысл оставить только их, формируя тем самым "максимально" подходящий офлайн словарь.

Ну, то есть, она ищет среди фиксированного набора известных ей классов (а как иначе?). А раньше, в какой-нибудь yolo5 или yolo8 было как-то иначе? Что принципиально поменялось?
Благодаря этому они могут находить даже те классы, которые не были явно заданы заранее
Давайте на каком-нибудь примере посмотрим как она найдёт некий класс, который не был явно задан заранее. Я думал, марсоход, как раз такой пример.
Чуда ожидать не стоит, но все же...
Вас же не удивляет, что всякие диффузеры генерят осмысленную картинку? Значит в целом нейросети уже научились определять, что именно на картинке изображено. В случае stable diffusion этим занимается сетка clip - она по картинке делает эмбеддинг, и по фразе делает эмбеддинг и сличает, насколько эти эмбединги похожи. При генерации меняет картинку так, что бы ее эмбединг был сильнее похож на текстовый.
Тут собственно почти тоже самое, что мешает натренировать сеть искать кусок изображения, который при свертке clip даст эмбеддинг максимально похожий на текстовый?
Clip при этом тренировалась не на классах, а на картинках с описанием. Конечно, если нигде в этом наборе объект который вы ищете не встречался, то clip и yola из статьи не сработает. И сейчас все сетки с открытым множеством находят много лишнего, но думаю еще не много и это доделают.
Вот тут еще пример такой сетки
https://ashkamath.github.io/mdetr_page/
Спасибо!
Про произвольное число, да ещё и без обучения, да ещё и в реальном времени - ерунда какая-то. Даже читать такое не хочется.
Извините за возможно обывательский вопрос, а с помощью такой сети можно детектить:
Действие, скажем человек воспользовался кофеваркой
Человека, который воспользовался кофеваркой
Или это долее широкий пайп лайн, например мы задетеклили что кто то взял капсулу и вставил в кофемашину, потом передаем это фото на следующий этпе где уже другими технологиями сличаем с базой известных лиц?
YOLO-World: распознавание произвольного числа объектов с высокой точностью и скоростью