Широкое распространение параллельных архитектур вычислительных систем вызывает повышение интереса к средствам разработки программного обеспечения, способного максимально полно использовать аппаратные ресурсы данного типа.
Однако к текущему моменту имеется определенный разрыв между имеющимися на потребительском рынке технологиями аппаратной реализации параллелизма и программными средствами их поддержки. Так, если многоядерные компьютеры общего назначения стали нормой в середине текущего десятилетия, то появление OpenMP — популярного стандарта разработки программ для подобных систем — отмечено почти десятью годами ранее [1]. Практически в то же время возник и стандарт MPI, описывающий способы передачи сообщений между процессами в распределенной среде [2].
Развитие обоих данных стандартов, выражающееся только в расширении функциональности без адаптации парадигм к объектно-ориентированному подходу, приводит к тому, что они оказываются несовместимы с современными платформами программирования, такими как Microsoft .NET Framework. Поэтому разработчикам этих платформ приходится прилагать дополнительные усилия по внедрению средств параллелизма в свои продукты.
В [3] автором была рассмотрена одна из таких технологий, Microsoft Parallel Extensions, позволяющая достаточно простым способом внедрять параллелизм в изначально последовательный управляемый код для компьютеров с общей памятью. Там же была показана возможность и целесообразность использования платформы .NET Framework для проведения научных расчетов. Тем не менее, остается открытым вопрос о применимости данной платформы для разработки программ, используемых для проведения сложных расчетов на системах с распределенной памятью, например, вычислительных кластеров. Данные системы базируются на совокупности соединенных между собой вычислительных узлов, каждый из которых является полноценным компьютером со своим процессором, памятью, подсистемой ввода/вывода, операционной системой, причем каждый узел работает в собственном адресном пространстве.
MPI поддерживает работу с языками Fortran и C. MPI-программа — это множество параллельных взаимодействующих процессов. Все процессы порождаются один раз, образуя параллельную часть программы. Каждый процесс работает в своем адресном пространстве, никаких общих переменных или данных в MPI нет. Основным способом взаимодействия между процессами является явная посылка сообщений от одного процесса другому. [4]
Несмотря на то, что MPI-программы показывают высокий уровень производительности, сама технология имеет ряд недостатков:
Тем не менее, начиная с третьей версии, .NET Framework включает в себя Windows Communication Foundation (WCF) — унифицированную технологию создания всех видов распределенных приложений на платформе Microsoft [5]. К сожалению, данная технология зачастую понимается только как каркас для работы с Web-службами на основе XML, что напрасно мешает рассматривать WCF как эффективное средство для организации параллельных вычислений.
Чтобы клиент мог передать службе информацию, он должен знать “АПК”: адрес, привязку и контракт.
Адрес определяет, куда следует отправлять сообщения, чтобы оконечная точка их получила.
Привязка определяет канал для коммуникаций с оконечной точкой. По каналам передаются все сообщения, циркулирующие в приложении WCF. Канал состоит из нескольких элементов привязки (binding element). На самом нижнем уровне элемент привязки – это транспортный механизм, обеспечивающий доставку сообщений по сети. Элементы привязки, расположенные выше, описывают требования к безопасности и транзакционной целостности. WCF поставляется с набором готовых привязок. Например, привязка basicHttpBinding применима для доступа к большинству Web-служб, созданных до 2007 года; привязка netTcpBinding реализует высокоскоростной обмен данными по протоколу TCP для коммуникаций между двумя .NET-системами; netNamedPipeBinding предназначен для коммуникаций в рамках одной машины или между несколькими .NET--системами. Поддерживается и построение приложений для работы в пиринговых сетях, для этого существует привязка netPeerTcpBinding.
Контракт определяет набор функций, предоставляемых оконечной точкой, то есть операции, которые она может выполнять, и форматы сообщений для этих операций. Описанные в контракте операции отображаются на методы класса, реализующего оконечную точку, и включают в частности типы параметров, передаваемых каждому методу и получаемых от него. WCF поддерживает синхронные и асинхронные, односторонние и дуплексные операции с произвольными типами данных, что является достаточным для построения распределенных приложений на базе .NET Framework с целью решения больших вычислительных задач. Тем не менее, представленная информация не помогает оценить практическую применимость и эффективность технологии WCF в данном случае.
В качестве иллюстрации возможности, а так же оценки сложности разработки приложений для вычислительных задач с использованием WCF предлагается реализовать с её помощью некоторые демонстрационные алгоритмы, описанные на официальном ресурсе MPI [6].
Для тестирования производительности решений используются две ЭВМ с четырьмя и двумя процессорными ядрами равной производительности соответственно. Коммуникация осуществляется посредством сети Ethernet 100Mbit. Тестирование WCF производится на ОС Microsoft Windows 7, для построения кластера MPI применяется Pelican HPC [7] на ядре ОС Linux 2.6.30 с использованием Open MPI 1.3.3.
Для его работы требуется наличие двух MPI-процессов, между которыми идет обмен массивами элементов типа double размерами от 1 до 1048576 элементов с использованием команд MPI_Recv () и MPI_Ssend. Здесь стоит отметить влияние указанных ранее недостатков MPI:
Далее описывается класс, реализующий логику серверного приложения, принимающего от клиентского приложения массив вещественных чисел и отправляющего его обратно:
Реализуется основной метод серверного приложения, регистрирующий АПК. При этом поведение серверного приложения может конфигурироваться согласно настройкам как в коде, так и в .config-файле приложения.
Клиентское приложение выглядит следующим образом, где класс CallBackHandler реализует соответствующий, описанный ранее интерфейс, а класс Client предоставляет статический метод, играющий роль точки входа:
В программе выполняется несколько итераций, каждая из которых заключается в вызове удаленного метода SendArray с передачей ему массива данных и ожидании вызова метода SendArrayFromServer, которому поступают вернувшиеся с сервера данные.
Представленный код обладает несколькими важными достоинствами относительно MPI, а именно:
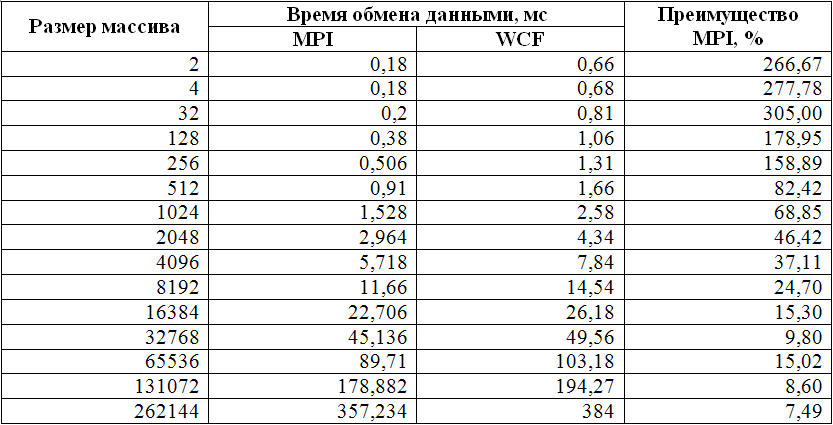
Из данной таблицы следует, что, к сожалению, технология WCF не пригодна для разработки программ, требующих частого межпроцессного обмена данными малого объема.
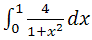 . Обнаружить параллелизм данного алгоритма весьма легко: интервал интегрирования разбивается на столько частей, сколько вычислительных узлов будет задействовано в вычислениях. Программа на C++ для MPI, решающая поставленную задачу, выглядит следующим образом:
. Обнаружить параллелизм данного алгоритма весьма легко: интервал интегрирования разбивается на столько частей, сколько вычислительных узлов будет задействовано в вычислениях. Программа на C++ для MPI, решающая поставленную задачу, выглядит следующим образом:
Код весьма лаконичен, однако ему свойственны все перечисленные выше недостатки MPI. Для WCF серверная часть на языке C# выглядит следующим образом:
Выделение серверной части не только облегчает понимание кода, но и дает возможность его повторного использования без привязки к какому-либо конкретному клиенту. Сам же клиент может быть реализован следующим образом (асинхронно вызывается удаленный метод CalculatePiChunk с собственным набором параметров на каждом вычислительном узле):
Результаты замеров производительности представлены ниже:

По данным результатам можно судить, что применение технологии WCF среды .NET Framework для построения распределенных вычислительных приложений с малым числом межпроцессных коммуникаций показывает хорошие результаты: относительно низкая скорость обмена данными компенсируется качественной оптимизацией JIT-кода [3] таким образом, что управляемая .NET-программа во многих ситуациях оказывается производительнее.
По результатам представленного краткого тестирования можно сделать следующие выводы:
ЛИТЕРАТУРА
1. OpenMP Reference. OpenMP Architecture Review Board, 2008 r.
2. MPI 2.1 Reference. University of Tennessee, 2008 r.
3. Параллельное программирование в .NET. Тихонов, И. В. Иркутск, 2009. Труды XIV Байкальской Всероссийской конференции «Информационные и математические технологии в науке и управлении».
4. Антонов, А. С. Параллельное программирование с использованием технологии MPI. М.: Издательство МГУ.
5. Резник, Стив, Крейн, Ричард и Боуэн, Крис. Основы Windows Communication Foundation для .NET Framework 3.5. М.: ДМК Пресс, 2008.
6. The Message Passing Interface (MPI) standard. www.mcs.anl.gov/research/projects/mpi
7. PelicanHPC GNU Linux. pareto.uab.es/mcreel/PelicanHPC
Однако к текущему моменту имеется определенный разрыв между имеющимися на потребительском рынке технологиями аппаратной реализации параллелизма и программными средствами их поддержки. Так, если многоядерные компьютеры общего назначения стали нормой в середине текущего десятилетия, то появление OpenMP — популярного стандарта разработки программ для подобных систем — отмечено почти десятью годами ранее [1]. Практически в то же время возник и стандарт MPI, описывающий способы передачи сообщений между процессами в распределенной среде [2].
Развитие обоих данных стандартов, выражающееся только в расширении функциональности без адаптации парадигм к объектно-ориентированному подходу, приводит к тому, что они оказываются несовместимы с современными платформами программирования, такими как Microsoft .NET Framework. Поэтому разработчикам этих платформ приходится прилагать дополнительные усилия по внедрению средств параллелизма в свои продукты.
В [3] автором была рассмотрена одна из таких технологий, Microsoft Parallel Extensions, позволяющая достаточно простым способом внедрять параллелизм в изначально последовательный управляемый код для компьютеров с общей памятью. Там же была показана возможность и целесообразность использования платформы .NET Framework для проведения научных расчетов. Тем не менее, остается открытым вопрос о применимости данной платформы для разработки программ, используемых для проведения сложных расчетов на системах с распределенной памятью, например, вычислительных кластеров. Данные системы базируются на совокупности соединенных между собой вычислительных узлов, каждый из которых является полноценным компьютером со своим процессором, памятью, подсистемой ввода/вывода, операционной системой, причем каждый узел работает в собственном адресном пространстве.
MPI. Основная идея и недостатки
В мире функционального программирования наиболее распространенной технологией создания программ для параллельных компьютеров такого типа является MPI. Основным способом взаимодействия параллельных процессов в данном случае выступает передача сообщений от одного узла другому. Стандарт MPI фиксирует интерфейс, который должен соблюдаться как системой программирования на каждой вычислительной платформе, так и пользователем при создании своих программ.MPI поддерживает работу с языками Fortran и C. MPI-программа — это множество параллельных взаимодействующих процессов. Все процессы порождаются один раз, образуя параллельную часть программы. Каждый процесс работает в своем адресном пространстве, никаких общих переменных или данных в MPI нет. Основным способом взаимодействия между процессами является явная посылка сообщений от одного процесса другому. [4]
Несмотря на то, что MPI-программы показывают высокий уровень производительности, сама технология имеет ряд недостатков:
- низкий уровень (программирование на MPI часто сравнивают с программированием на ассемблере), необходимость детального управления распределением массивов и витков циклов между процессами, а также обменом сообщениями между процессами – все это приводит к высокой трудоемкости разработки программ;
- необходимость избыточной спецификации типов данных в передаваемых сообщениях, а так же наличие жестких ограничений на типы передаваемых данных;
- сложность написания программ, способных выполняться при произвольных размерах массивов и произвольном количестве процессов – делает практически невозможным повторное использование имеющихся MPI-программ;
- отсутствие поддержки объектно-ориентированного подхода.
Тем не менее, начиная с третьей версии, .NET Framework включает в себя Windows Communication Foundation (WCF) — унифицированную технологию создания всех видов распределенных приложений на платформе Microsoft [5]. К сожалению, данная технология зачастую понимается только как каркас для работы с Web-службами на основе XML, что напрасно мешает рассматривать WCF как эффективное средство для организации параллельных вычислений.
Структура WCF
Для определения возможности использования WCF в качестве средства разработки программ для систем с распределенной памятью рассмотрим основы данной технологии. Служба WCF – это множество оконечных точек (endpoints), которые предоставляет клиентам некие полезные возможности. Оконечная точка – это просто сетевой ресурс, которому можно посылать сообщения. Чтобы воспользоваться предоставляемыми возможностями, клиент посылает сообщения оконечным точкам в формате, который описывается контрактом между клиентом и службой. Службы ожидают поступления сообщений на адрес оконечной точки, предполагая, что сообщения будут записаны в оговоренном формате.Чтобы клиент мог передать службе информацию, он должен знать “АПК”: адрес, привязку и контракт.
Адрес определяет, куда следует отправлять сообщения, чтобы оконечная точка их получила.
Привязка определяет канал для коммуникаций с оконечной точкой. По каналам передаются все сообщения, циркулирующие в приложении WCF. Канал состоит из нескольких элементов привязки (binding element). На самом нижнем уровне элемент привязки – это транспортный механизм, обеспечивающий доставку сообщений по сети. Элементы привязки, расположенные выше, описывают требования к безопасности и транзакционной целостности. WCF поставляется с набором готовых привязок. Например, привязка basicHttpBinding применима для доступа к большинству Web-служб, созданных до 2007 года; привязка netTcpBinding реализует высокоскоростной обмен данными по протоколу TCP для коммуникаций между двумя .NET-системами; netNamedPipeBinding предназначен для коммуникаций в рамках одной машины или между несколькими .NET--системами. Поддерживается и построение приложений для работы в пиринговых сетях, для этого существует привязка netPeerTcpBinding.
Контракт определяет набор функций, предоставляемых оконечной точкой, то есть операции, которые она может выполнять, и форматы сообщений для этих операций. Описанные в контракте операции отображаются на методы класса, реализующего оконечную точку, и включают в частности типы параметров, передаваемых каждому методу и получаемых от него. WCF поддерживает синхронные и асинхронные, односторонние и дуплексные операции с произвольными типами данных, что является достаточным для построения распределенных приложений на базе .NET Framework с целью решения больших вычислительных задач. Тем не менее, представленная информация не помогает оценить практическую применимость и эффективность технологии WCF в данном случае.
Методика оценки эффективности WCF
Проведем оценку применимости WCF со следующих позиций:- Возможность и сложность разработки распределенных приложений для решения вычислительных задач.
- Эффективность обмена данными между компонентами распределенного приложения.
- Общая эффективность выполнения распределенных вычислений с использованием WCF.
В качестве иллюстрации возможности, а так же оценки сложности разработки приложений для вычислительных задач с использованием WCF предлагается реализовать с её помощью некоторые демонстрационные алгоритмы, описанные на официальном ресурсе MPI [6].
Для тестирования производительности решений используются две ЭВМ с четырьмя и двумя процессорными ядрами равной производительности соответственно. Коммуникация осуществляется посредством сети Ethernet 100Mbit. Тестирование WCF производится на ОС Microsoft Windows 7, для построения кластера MPI применяется Pelican HPC [7] на ядре ОС Linux 2.6.30 с использованием Open MPI 1.3.3.
Простая программа обмена информацией
Самый простой тест, призванный показать эффективность обмена данными между компонентами вычислительной сети, заключается в отправке массива вещественных чисел двойной точности с одного узла на другой и обратно с фиксацией времени, затраченного на выполнение данных операций. Код на языке C++ для MPI выглядит следующим образом:#define NUMBER_OF_TESTS 10
int main( argc, argv )
int argc;
char **argv;
{
double *buf;
int rank, n, j, k, nloop;
double t1, t2, tmin;
MPI_Status status;
MPI_Init( &argc, &argv );
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
if (rank == 0)
printf( "Kind\t\tn\ttime (sec)\tRate (MB/sec)\n" );
for (n=1; n<1100000; n*=2) {
if (n == 0) nloop = 1000;
else nloop = 1000/n;
if (nloop < 1) nloop = 1;
buf = (double *) malloc( n * sizeof(double) );
tmin = 1000;
for (k=0; k<NUMBER_OF_TESTS; k++) {
if (rank == 0) {
t1 = MPI_Wtime();
for (j=0; j<nloop; j++) {
MPI_Ssend( buf, n, MPI_DOUBLE, 1, k, MPI_COMM_WORLD );
MPI_Recv( buf, n, MPI_DOUBLE, 1, k, MPI_COMM_WORLD,
&status );
}
t2 = (MPI_Wtime() - t1) / nloop;
if (t2 < tmin) tmin = t2;
}
else if (rank == 1) {
for (j=0; j<nloop; j++) {
MPI_Recv( buf, n, MPI_DOUBLE, 0, k, MPI_COMM_WORLD,
&status );
MPI_Ssend( buf, n, MPI_DOUBLE, 0, k, MPI_COMM_WORLD );
}
}
}
if (rank == 0) {
double rate;
if (tmin > 0) rate = n * sizeof(double) * 1.0e-6 /tmin;
else rate = 0.0;
printf( "Send/Recv\t%d\t%f\t%f\n", n, tmin, rate );
}
free( buf );
}
MPI_Finalize( );
return 0;
}
Для его работы требуется наличие двух MPI-процессов, между которыми идет обмен массивами элементов типа double размерами от 1 до 1048576 элементов с использованием команд MPI_Recv () и MPI_Ssend. Здесь стоит отметить влияние указанных ранее недостатков MPI:
- Разделение функциональности обоих процессов базируется исключительно на номере (rank) процесса, что усложняет восприятие листинга программы.
- Перед отправкой данных (MPI_Ssend) необходимо быть уверенным в том, что принимающая сторона явно инициализировала их прием (MPI_Recv), что усложняет процесс разработки.
- Спецификация типов передаваемых данных (MPI_DOUBLE) вместе с самими данными с рациональной точки зрения является излишней, что так же может приводить к логическим ошибкам в программе.
- Кроме того, неприятным моментом, связанным с организацией языка программирования, является необходимость ручного выделения и освобождения памяти.
[ServiceContract(CallbackContract = typeof(IClientCallback))] public interface IServerBenchmark
{
[OperationContract(IsOneWay = true)] void SendArray(double[] array);
}
public interface IClientCallback
{
[OperationContract(IsOneWay = true)] void SendArrayFromServer(double[] array);
}
Далее описывается класс, реализующий логику серверного приложения, принимающего от клиентского приложения массив вещественных чисел и отправляющего его обратно:
public class ServerBenchmark : IServerBenchmark
{
public void SendArray(double[] array)
{
OperationContext.Current.GetCallbackChannel<IClientCallback>().SendArrayFromServer(array);
}
}
Реализуется основной метод серверного приложения, регистрирующий АПК. При этом поведение серверного приложения может конфигурироваться согласно настройкам как в коде, так и в .config-файле приложения.
class Program
{
static void Main(string[] args)
{
ServiceHost serviceHost = new ServiceHost();
NetTcpBinding binding = new NetTcpBinding();
serviceHost.AddServiceEndpoint(typeof(IServerBenchmark), binding, "");
serviceHost.Open();
Console.ReadLine();
serviceHost.Close();
}
}
Клиентское приложение выглядит следующим образом, где класс CallBackHandler реализует соответствующий, описанный ранее интерфейс, а класс Client предоставляет статический метод, играющий роль точки входа:
public class CallbackHandler : IServerBenchmarkCallback
{
private static EventWaitHandle _waitHandle = new EventWaitHandle(false, EventResetMode.AutoReset);
static int _totalIterations = 10;
public static DateTime _dateTime;
public void SendArrayFromServer(double[] array)
{
_waitHandle.Set();
}
class Client
{
private static InstanceContext _site;
static void Main(string[] args)
{
_site = new InstanceContext(new CallbackHandler());
ServerBenchmarkClient client = new ServerBenchmarkClient(_site);
double[] arr = new double[Convert.ToInt32(args[0])];
for (int index = 0; index < arr.Length;index++ )
arr[index] = index;
_dateTime = DateTime.Now;
for (int index = 0; index < _totalIterations; index++)
{
client.SendArray(arr);
_waitHandle.WaitOne();
}
Console.WriteLine((DateTime.Now - _dateTime).TotalMilliseconds / _totalIterations);
Console.ReadKey();
}
}
}
В программе выполняется несколько итераций, каждая из которых заключается в вызове удаленного метода SendArray с передачей ему массива данных и ожидании вызова метода SendArrayFromServer, которому поступают вернувшиеся с сервера данные.
Представленный код обладает несколькими важными достоинствами относительно MPI, а именно:
- Единообразное и однократное описание форматов передаваемых данных, реализуемое в интерфейсе (контракте).
- Простая реализация вызов удаленных методов.
- Использование объектно-ориентированного подхода к разработке.
Из данной таблицы следует, что, к сожалению, технология WCF не пригодна для разработки программ, требующих частого межпроцессного обмена данными малого объема.
Пример распределенных вычислений
Рассмотрим теперь возможность построения распределенного приложения, не требующего активного обмена данными между узлами. За основу возьмем ещё один пример с ресурса [6] – расчет числа Pi. В данном примере Pi рассчитывается как. Обнаружить параллелизм данного алгоритма весьма легко: интервал интегрирования разбивается на столько частей, сколько вычислительных узлов будет задействовано в вычислениях. Программа на C++ для MPI, решающая поставленную задачу, выглядит следующим образом:int main(argc,argv)
int argc;
char *argv[];
{
int done = 0, n, myid, numprocs, i;
double PI25DT = 3.141592653589793238462643;
double mypi, pi, h, sum, x;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
while (!done)
{
if (myid == 0) {
printf("Enter the number of intervals: (0 quits) ");
scanf("%d",&n);
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
if (n == 0) break;
h = 1.0 / (double) n;
sum = 0.0;
for (i = myid + 1; i <= n; i += numprocs) {
x = h * ((double)i - 0.5);
sum += 4.0 / (1.0 + x*x);
}
mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0,
MPI_COMM_WORLD);
if (myid == 0)
printf("pi is approximately %.16f, Error is %.16f\n",
pi, fabs(pi - PI25DT));
}
MPI_Finalize();
return 0;
}
Код весьма лаконичен, однако ему свойственны все перечисленные выше недостатки MPI. Для WCF серверная часть на языке C# выглядит следующим образом:
[ServiceContract] public interface IPiService
{
[OperationContract] double CalculatePiChunk(int intervals, int processId, int processesCount);
}
public class PiService : IPiService
{
public double CalculatePiChunk(int intervals, int processId, int processesCount)
{
double h = 1.0 / (double)intervals;
double sum = 0.0;
double x;
for (int i = processId + 1; i <= intervals; i += processesCount)
{
x = h * (i - 0.5);
sum += 4.0 / (1.0 + x * x);
}
return h * sum;
}
}
public class Service
{
public static void Main(string[] args)
{
ServiceHost serviceHost = new ServiceHost(typeof(PiService));
serviceHost.AddServiceEndpoint(typeof(IPiService), new NetTcpBinding(), "");
serviceHost.Open();
Console.ReadLine();
serviceHost.Close();
}
}
Выделение серверной части не только облегчает понимание кода, но и дает возможность его повторного использования без привязки к какому-либо конкретному клиенту. Сам же клиент может быть реализован следующим образом (асинхронно вызывается удаленный метод CalculatePiChunk с собственным набором параметров на каждом вычислительном узле):
class Client
{
private static double _pi;
private static DateTime _startTime;
static int _inProcess = 0;
static void Main(string[] args)
{
_pi = 0;
int intervals = Convert.ToInt32(args[0]);
List<String> endPoints = new List<string>();
for (int index = 1; index<args.Length;index++)
endPoints.Add(args[index]);
double pi = 0;
_inProcess = endPoints.Length;
PiServiceClient[] clients = new PiServiceClient[endPoints.Length];
for (int index = 0; index < endPoints.Length; index++)
clients[index] = new PiServiceClient("NetTcpBinding_IPiService", "net.tcp://" + endPoints[index] + "/EssentialWCF");
_startTime = DateTime.Now;
for (int index = 0; index< endPoints.Length; index++)
clients[index].BeginCalculatePiChunk(intervals, index, endPoints.Length, GetPiCallback, clients[index]);
Console.ReadKey();
}
static void GetPiCallback(IAsyncResult ar)
{
double d = ((PiServiceClient)ar.AsyncState).EndCalculatePiChunk(ar);
lock(ar)
{
_pi += d;
_inProcess--;
if (_inProcess == 0)
{
Console.WriteLine(_pi);
Console.WriteLine("Calculation ms elasped: " + (DateTime.Now - _startTime).TotalMilliseconds);
}
}
}
}
Результаты замеров производительности представлены ниже:
По данным результатам можно судить, что применение технологии WCF среды .NET Framework для построения распределенных вычислительных приложений с малым числом межпроцессных коммуникаций показывает хорошие результаты: относительно низкая скорость обмена данными компенсируется качественной оптимизацией JIT-кода [3] таким образом, что управляемая .NET-программа во многих ситуациях оказывается производительнее.
По результатам представленного краткого тестирования можно сделать следующие выводы:
- Разработка приложений на платформе .NET Framework для решения вычислительных задач на системах с распределенной памятью является возможной.
- Технология WCF, предназначенная для построения приложений такого рода, обеспечивает гораздо более простой способ межпроцессной коммуникации, нежели это реализовано в MPI.
- В свою очередь эта простота приводит к существенному падению производительности процессов обмена данными: в некоторых случаях MPI быстрее WCF более чем в два с половиной раза.
- Таким образом, WCF не подходит для решения задач, требующих интенсивного обмена малыми группами данных между вычислительными узлами.
- Однако использование данной технологии вполне оправдано в случае более редкой межпроцессной коммуникации: кроме более простого способа разработки по сравнению с MPI, .NET Framework предоставляет и другие преимущества для организации научных вычислений, такие как интероперабельность получаемых программ, автоматическое управление памятью, межъязыковое взаимодействие, поддержка функционального программирования. [3]
ЛИТЕРАТУРА
1. OpenMP Reference. OpenMP Architecture Review Board, 2008 r.
2. MPI 2.1 Reference. University of Tennessee, 2008 r.
3. Параллельное программирование в .NET. Тихонов, И. В. Иркутск, 2009. Труды XIV Байкальской Всероссийской конференции «Информационные и математические технологии в науке и управлении».
4. Антонов, А. С. Параллельное программирование с использованием технологии MPI. М.: Издательство МГУ.
5. Резник, Стив, Крейн, Ричард и Боуэн, Крис. Основы Windows Communication Foundation для .NET Framework 3.5. М.: ДМК Пресс, 2008.
6. The Message Passing Interface (MPI) standard. www.mcs.anl.gov/research/projects/mpi
7. PelicanHPC GNU Linux. pareto.uab.es/mcreel/PelicanHPC

