Возможно, вы уже пользуетесь Grazie — плагином для среды разработки Intellij IDEA, который проверяет естественные языки на грамматические, пунктуационные и прочие виды ошибок. Сейчас команда проекта работает над плагином для Chrome, который будет делать то же самое, но уже в браузере. С частью задач им помогают стажеры — студенты профильных программ из разных вузов. Например, Ольга Шиманская учится на третьем курсе бакалавриата «Современное программирование» в СПбГУ и на практике кодила для Grazie Chrome Plugin. За весенний семестр Оля реализовала парсинг языков разметки (LaTeX и Markdown) в обычный текст и попыталась подступиться к задаче подсветки синтаксиса выбранного языка в браузере. Что у нее получилось, а что нет, читайте под катом.
Пара слов о себе

Всем привет! Меня зовут Оля Шиманская, и я учусь на 3-м курсе программы «Современное программирование» в СПбГУ. Сюда я поступила из-за маленького набора (всего 30 человек) и высокого уровня подготовки. В последнем я была уверена, т.к. программа была основана частью преподавателей из АУ в 2018 году. Сейчас мой курс самый старший, и мне тут очень нравится.
Я интересуюсь двумя направлениями: веб-разработкой и машинным обучением. До Grazie у меня уже был опыт веб-разработки на летней стажировке Google и на предыдущем университетском проекте от лаборатории LAMBDA ВШЭ. В весеннем семестре нам предложили много разных проектов, и я решила пройти отбор в Grazie: меня заинтересовала идея проекта, мне предложили интересные и новые задачи, и мне понравилась сама команда.
Что такое Grazie Chrome Plugin
Изначально Grazie — это плагин для среды разработки Intellij IDEA. Он осуществляет проверку естественных языков на грамматические, пунктуационные и прочие виды ошибок. Сейчас команда Grazie делает плагин для Chrome. «Но зачем?», — спросите вы. — «Ведь есть Grammarly и другие аналоги». Отличие Grazie в том, что он изначально ориентирован на программистов и IT-терминологию, а Grammarly помечает специализированные термины как ошибки. Также разработчики используют языки разметки: Markdown, LaTeX и т.д — при написании документации, статей и design-документов, которые тоже нужно грамотно обрабатывать. Со всем этим и поможет Grazie Chrome Plugin.
Note: На данный момент Chrome плагин доступен только для сотрудников JetBrains, но могу по секрету сказать, что он классный.
Чем я занималась
Я занималась этим проектом в течение семестра. Мне нужно было придумать, как:
Реализовать парсинг языка разметки в обычный текст и добавить маппинг индексов из естественного текста в исходный текст.
Определять язык разметки и выбирать соответствующий парсер.
Поддержать подсветку синтаксиса выбранного языка в редакторе.
Весь проект написан на TypeScript, использует сборщик Webpack и статический анализатор ESlint.
Во время работы над проектом у меня были еженедельные встречи с менторами, code review и чат для вопросов. Мне помогали разбираться в коде проекта и предлагали/дополняли способы решения поставленных задач.
Парсинг языка разметки
Свою работу я начала с парсера языка Markdown. Для этого нашла замечательное семейство библиотек и тулзов от unified. Разумеется, Markdown очень популярный язык разметки, и мои руководители не хотели, чтобы я писала велосипед. Да и выбор библиотек из npm был огромен.
Я остановилась на этих библиотеках по следующим причинам:
Популярность remark-parse — 5 млн. скачиваний в неделю.
Этот парсер делает AST и для каждой ноды прописывает индексы в тексте (позиция старта и конца). Это было необходимо для индексации из итогового текста в исходный.
Богатый набор методов для прохода по дереву.
Я успела разобраться в самом проекте и внедрить этот парсер за две недели.
Парсер LaTeX
Дальше мне предложили несколько вариантов задач: парсер LaTeX, детектор языка разметки или добавить подсветку для Markdown. Я решила заняться парсером LaTeX, потому что он быстрее добавил бы Grazie Plugin возможность проверять тексты в Overleaf/Papeeria, в чем нуждается большинство пользователей данных сервисов. Например, Grammarly, насколько мне известно, в принципе не запускает проверку в редакторе Overleaf’a.
Изначально я думала, что смогу достаточно быстро выполнить эту задачу и приступить к реализации подсветки для Markdown, более сложной и от этого интересной. Но реализация парсера для LaTeX оказалась сложнее, потому что LaTeX не имеет контекстно-свободной грамматики. Например, здесь неплохое объяснение с примером того, что грамматика является тьюринг-полной и не является хотя бы контекстно-зависимой). В этой статье можно подробней прочитать про данные грамматики и какую иерархию они образуют. Это проблема, поскольку большинство контекстно-зависимых грамматик нельзя парсить за гарантированно полиномиальное время (задача разрешимости, то есть принадлежности строки языку, для КЗ языков является PSPACE-полной). Многие парсеры делают допущение, что он контекстно-свободный, а для реализации подсветки пишут токенайзеры. Генераторы парсеров также предполагают, что поданная на вход грамматика будет контекстно-свободной. Конечно, для нашей задачи не требовалось полноценного парсера, достаточно было просто научиться извлекать из LaTeX’a естественный текст и проверять его на грамматические, пунктуационные и прочие виды ошибок.
Я использовала Tree-sitter, который советовал тимлид ещё для Markdown. Tree-sitter по файлу с грамматикой (в формате .js) генерирует инкрементальный(!) парсер на C. Также для него на гитхабе нашлась хорошая грамматика для LaTeX, которую я немного доработала: привела вершины в AST с текстом к одному типу, убрала некоторые недочеты той грамматики — например, она парсила текст не кусками (предложениями/абзацами), а по словам, и еще у нее не было поддержки некоторых команд. В итоге получился быстрый и хорошо работающий парсер. Но, к сожалению, потом пришлось искать новый генератор парсеров, потому что мы столкнулись с проблемой.
… и какие трудности у меня с ним возникли
Как я уже написала, Tree-sitter генерирует парсер на C. Для использования в JavaScript у него есть биндер, который генерирует .wasm файл, и его уже можно запускать в браузере. Тут-то и крылась самая большая проблема: мы с руководителями не знали, что почти все популярные сайты запрещают запускать такие файлы, потому что это опасно (Google CSP запрещает eval и WASM файлы могут быть использованы для вредоносных целей).
У меня было три варианта, как справиться с этой проблемой:
Сделать дыру в безопасности, разрешив запускать этот файл для нашего плагина. Но в этом случае Google будет проверять каждое обновление плагина на безопасность намного дольше из-за наличия .wasm файла.
Запускать его на сервере, но это бы сильно увеличило время парсинга, поскольку пришлось бы тратить время на сериализацию/десериализацию AST и отправку/получение данных.
Написать новый парсер.
Новый парсер LaTeX!
Я выбрала последний вариант и переписала грамматику из .js в .g4 для ANTLR4. Он генерирует лексер, парсер и визитер на JS, а с помощью antlr4ts можно это всё сгенерировать на TypeScript. Проблема была в том, что одна страница латеха обрабатывалась около 700 мс, а после упрощения грамматики получилось ускорить всего в 2 раза. С такой скоростью обработки страница сайта зависала после каждого введенного символа.

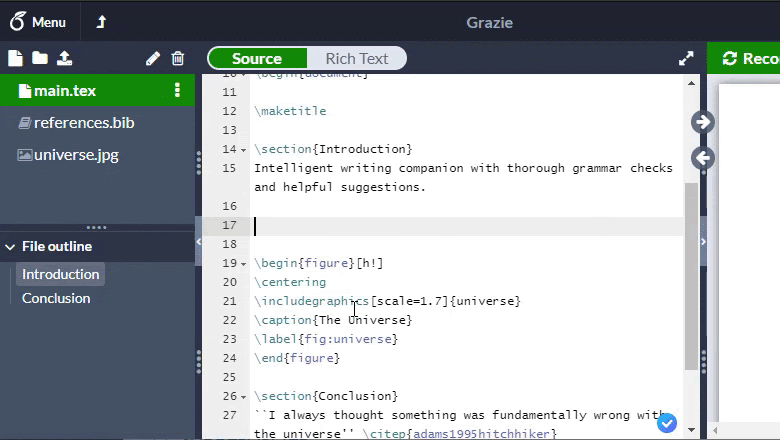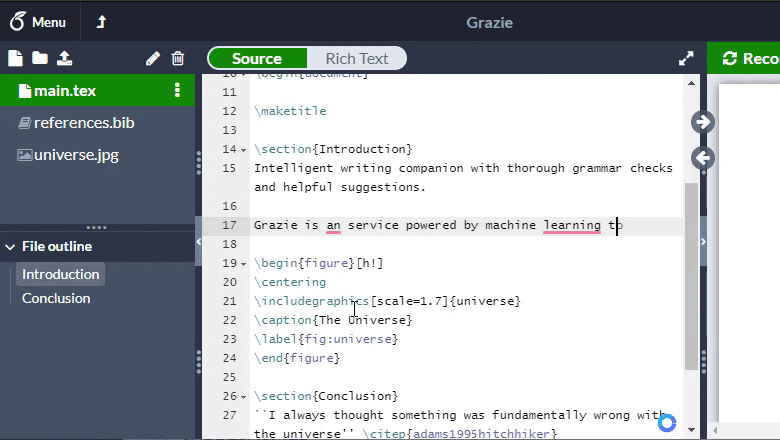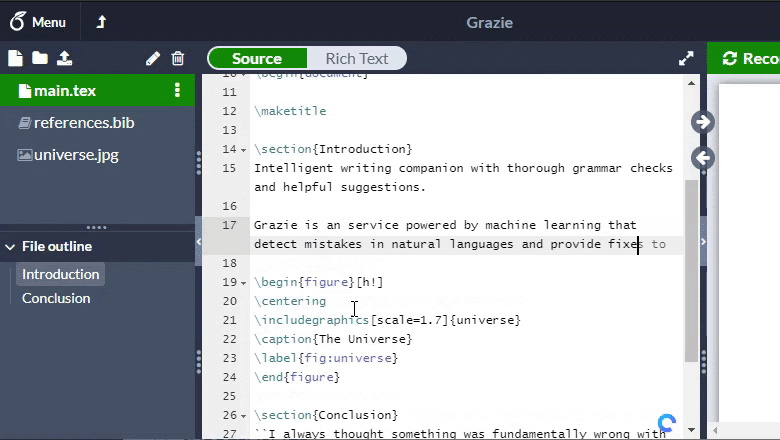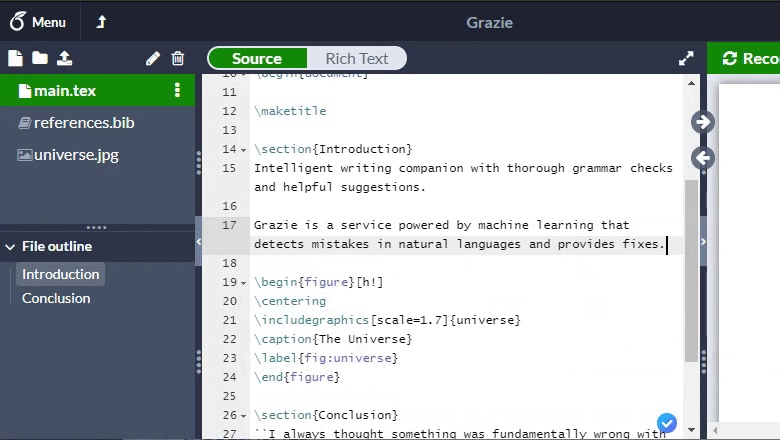
В итоге было принято решение отказаться от написания парсера и построения AST. Вместо этого было бы достаточно удалять синтаксические конструкции с помощью регулярных выражений и таким образом получать естественный текст. Единственная тонкость — не забыть оставить текст, содержащийся в некоторых командах в качестве аргумента, как, например, «Some title» в \title{Some title} (Другие примеры таких команд: \text, \author, \date).
Благодаря этому получилось добиться обработки за 5 мс на страницу:
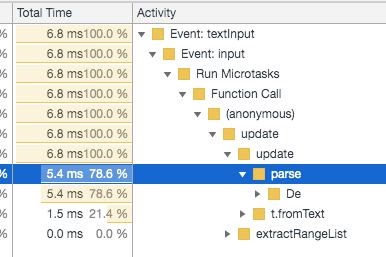
Подсветка синтаксиса в браузере
В этой задаче мы сталкиваемся со следующими проблемами:
1. Менять DOM-дерево сайта плохо/сложно/непонятно.
Почему? Допустим, мы хотим выделить какую-то ошибку в editor’e с помощью CSS свойства background-color. Мы могли бы поменять содержимое editor’a, обернув нужный кусок текста в <span> и добавив нужные нам стили. Но таким образом мы повлияем на внутреннее состояние элемента и теперь, например, копируемый текст будет содержать созданные нами стили. (Не знаю как вас, но меня бесит, когда копируешь текст с какого-то сайта, а вместе с ним копируется его фон)
Также в случае с textarea и input не получится манипулировать состоянием, так как оно инкапсулировано с shadow-root.
Можно решить задачу с выделением текста, расположив над ним div в форме прямоугольника и обновлять/удалять его при изменении содержимого редактора.
2. Хотим менять цвет, наклон, толщину текста.
Была идея посмотреть на mix-blend-mode и понять, можно ли с его помощью как-то поменять цвет текста. Свойство очень интересное и полезное, но если мы хотим менять цвет текста, то, во-первых, его нужно применять к элементу, в котором он находится. Во-вторых, нельзя добиться произвольного цвета текста. Например, если текст черного цвета, то мы сможем получить максимум оттенки серого.
Другой, более хардкорный вариант, сделать этот div цвета фона редактора и в нем написать аналогичный кусок текста. Несомненный плюс — можно менять его цвет. Минусы — всё остальное. При каждом изменении текста надо всё обновлять: учитывать переносы строк, следить за тем, чтобы наш текст в div’e совпадал по стилям с настоящим. Также не так просто будет сделать шрифт наклонным или дать ему другую толщину, так как ширина итоговой строки будет отличаться.
В итоге мы пришли к тому, что решить данную задачу с помощью простого HTML-элемента и CSS-стиля не получится. Остаётся два возможных варианта: canvas и CSS Paint. C их помощью можно попиксельно отрисовывать текст. Например, сделать canvas в форме прямоугольника, поставить его над нужным текстом и поменять в нем все пиксели цвета текста на другой цвет. Пока не очень понятно, будет ли это работать достаточно быстро и будет ли работать вообще. Видимо, это предстоит выяснить следующему стажеру...
Результаты
В итоге у меня получилось добавить в плагин поддержку Markdown и LaTeX. К сожалению, из-за проблем с парсером LaTeX’a у меня почти не осталось времени на последнюю и самую интересную задачу по подсветке синтаксиса, поэтому не могу сказать, что я довольна результатом. Но очень здорово, что получилось успеть сделать что-то полезное и нужное пользователям.

