
Привет, Хабр!
К сожалению, на данном этапе развития веб-программирования в нашей стране рефакторинг проекта чаще воспринимается как работа программиста в режиме «все плохо» и проводится только в тот момент, когда сайт уже находится в критическом состоянии. С подобной ситуацией нам пришлось столкнуться в 2012 году, когда к нам на обслуживание пришел один крупный российский интернет-магазин со следующей проблемой: начиная с 10 утра сайт каждые полчаса падал на 5-10 минут и поднимался или с большим трудом, или после жесткого ребута. После ребутов сайт немного работал, а затем падал опять. Особую остроту проблеме придавал тот факт, что приближался Новый год, высокий сезон для всех продающих сайтов, и в данном случае фраза «за 10 минут компания теряет десятки тысяч долларов» была не шуткой.

Давайте немного отвлечемся от нашей истории и поговорим о том, что разработчики теперь исключительно счастливые люди. Наконец-то серверные мощности стали настолько дешевыми, что любую систему при нехватке ресурсов можно легко масштабировать до нужного размера. Что-то не так напрограммировали? Повысилась нагрузка на проц? Отлично, давайте добавим процов серверу. Не хватает оперативы? Давайте добавим оперативы. Проблема нехватки ресурсов — не проблема.
Многие из вас прекрасно помнят то время, когда люди сидели по диалапу, вдумчиво слушали звук модема, с первых нот определяя, удалось ли законнектиться или нужно переподключиться. В то время медленный сайт просто закрывался через минуту, потому что ждать его было очень дорого (в прямом смысле этого слова). Сегодня же медленный сайт — это сайт, который открывается дольше 3 секунд без учета скорости канала. Мир наращивает скорость, время стоит дорого. А что делать, если сайту не хватает скорости? Есть замечательные акселераторы и более мощные и очень дешевые при этом сервера, есть веб-кластер от того же 1С-Битрикса, например, а в крайнем случае и море всякого ПО для тех же целей. Кажется, что можно больше не следить за качеством кода, резко понизить уровень разработчиков и существенно сэкономить бюджет компании.
Однако это только кажется. В нашей реальности, реальности веб-разработчиков, на любое самое мощное железо есть свой бесконечный цикл и замечательный фреймворк. И часто возникают ситуации, когда даже самое мощное железо не вытягивает написанный код.
Так было и в случае с нашим клиентом, крупным интернет-магазином, упомянутым в начале. Мы увидели у него шесть мощных серверов, по каждому из которых можно было свободно масштабироваться. Самым логичным и быстрым действием в тот момент было добавление еще пары серверов, что мы сразу же и сделали. Однако сайт все равно продолжал падать как по расписанию.
Чтобы получить какой-то таймаут для нормальной работы, мы решили сначала хоть как-то стабилизировать проект, чтобы он смог пережить Новый год, а затем уже проводить его глобальный реинжиниринг и рефакторинг.
Что мы имели на входе?
Мы знали, что графики нагрузки на разные части системы должны быть достаточно плавными. Например, такими:
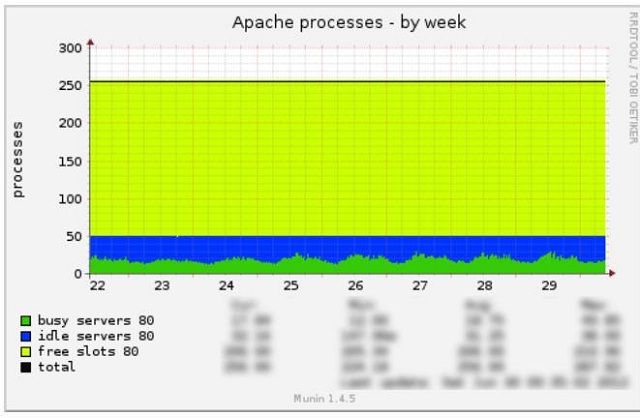
Это связано с тем, что очень редко в одну секунду бывает ноль пользователей на сайте, а в следующую — все 110 000 пользователей пиковой нагрузки.
Однако то, что мы увидели на проекте клиента, противоречило всей нашей практике: все графики прыгали и вели беспорядочную жизнь.
Выглядело это примерно так:
Apache:
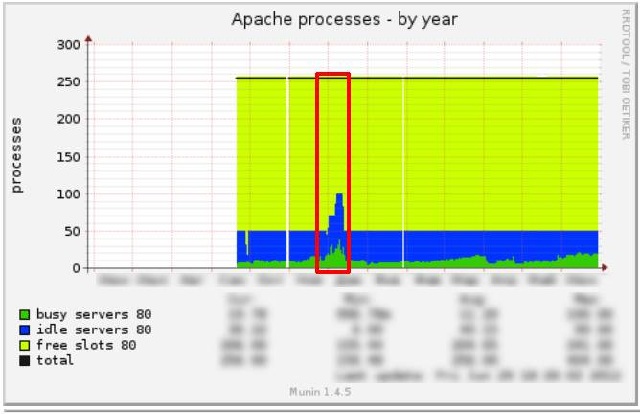
Возможно, стоило бы порадоваться возросшей по графикам нагрузке — больше посетителей, больше денег — но Google Analytics говорил, что количество посетителей не только не выросло, а даже упало.
Как правило, в стабильном и корректном состоянии системы увеличение нагрузки на Apache коррелируется с увеличением нагрузки на MySQL. Но в нашем случае выглядело все иначе.
MySQL:
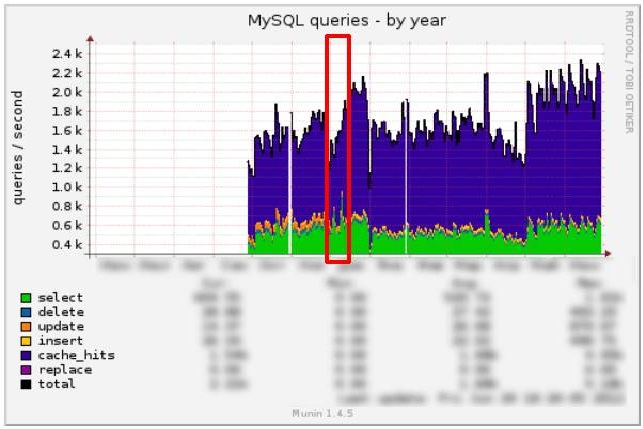
А теперь давайте сопоставим графики MySQL и Apache:
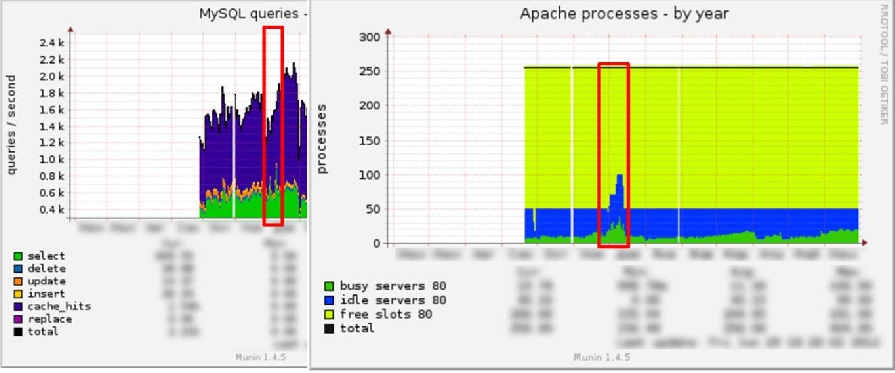
Что-то явно пошло не так. И мы начали искать проблему.
Что же мы обнаружили?
Во-первых, мы обнаружили измененное ядро CMS «1С-Битрикс», причем изменено оно было в тех частях, которые работают с кэшем, что означало потенциально неправильную работу с ним. В принципе, в этом была некоторая логика — если кэш сбоит и сбрасывается, то в эти моменты будут всплески на Апаче. Но тогда должны были быть еще и всплески на MySQL, а их не было.
Во-вторых, из-за измененного ядра CMS проект не обновлялся уже несколько лет, так как любое обновление ломало сайт.
В-третьих, сервер был настроен некорректно. Поскольку наша история о рефакторинге, на данном пункте подробно останавливаться не будем.
В-четвертых, проект создавался примерно в 2005-2006 году и рассчитывался совсем на другую нагрузку — раз в 10 меньше текущей. Архитектура проекта и код совершенно не были рассчитаны на возросшую нагрузку. Запросы, которые при старой нагрузке выполнялись в пределах терпимых 0.5 — 1 секунды, при новой нагрузке выполнялись уже 4-15 секунд и попадали в slow log.
И в-пятых: в процессе сотрудничества заказчика с разными подрядчиками за годы существования проекта в нем появилось много дублированного кода, лишние циклы и неэффективный кэш.
Собственно, немного дебаггера, пару гигабайт логов, живой аналитик весом не менее 60 кг, посолить, поперчить, перемешать — там мы получили отличный рецепт быстрой стабилизации проекта. Он смог пережить пик нового года и приобрел маленький, но все-таки запас прочности.
Как исправляли все остальное?
Напомним, что проект был на «1С-Битриксе». Сначала мы обновили версию CMS до последней, что привело, как мы предположили в начале, к тому, что значительная часть функционала перестала работать, её нужно было восстанавливать. После базовой аналитики выяснилось, что в ядре и в стандартных компонентах было изменено более 1000 файлов. После обновления первым этапом нам пришлось восстанавливать сайт до полнофункциональной версии. Зато это позволило нам подключить модуль Веб-кластера со всеми плюшками.
Вторым этапом мы проанализировали архитектуру проекта, запросы к БД и код и обнаружили, что из-за специфического построения архитектуры с одной каталожной страницы генерируется от 3000 до 4000 запросов к БД без кэша, с кэшем—около двухсот запросов. При этом он сбрасывался неоптимально и при любом обновлении контента.
Для оптимизации запросов к БД нам пришлось модифицировать структуру инфоблоков: денормализировать часть данных и вынести часть данных в отдельные таблицы. Это позволило избавиться от наиболее тяжелых джоинов со скоростью выполнения 30-40с и заменить их на несколько быстрых селектов. Также мы проставили индексы на наиболее используемые данные и убрали лишние, оставшиеся от старой структуры. Все это позволило значительно увеличить общую скорость выполнения запросов.
Также мы добавили бонус для последующих разработчиков проекта: для того, чтобы в дальнейшем код легко читался, мы разбросали многотысячные простыни кода на отдельные классы и файлы, прокомментировали их и почистили лишние устаревшие файлы.
Что в итоге получилось?
На последовательное проведение всех перечисленных работ у нас ушло около 6 месяцев. Затем мы провели нагрузочное тестирование на сайт. Тесты были как из внешней сети, так и изнутри кластера (чтобы нивелировать влияние скорости канала на тест).
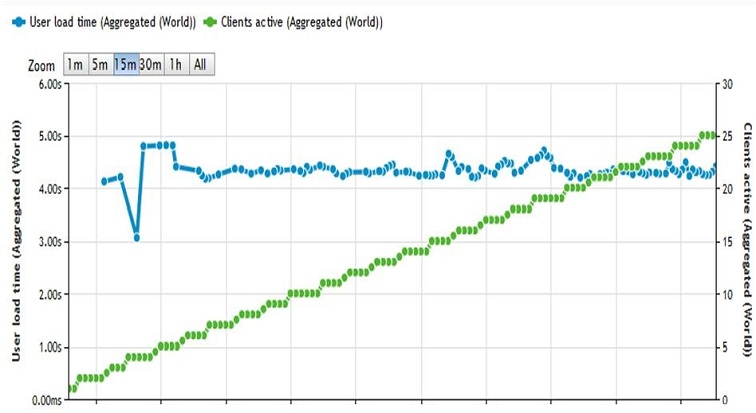
На графиках теста извне видно, что до рефакторинга и реинжиниринга системы при нагрузке в 25 одновременных пользователей страница грузится около 8с, а после нее – только 4,2с.
До:
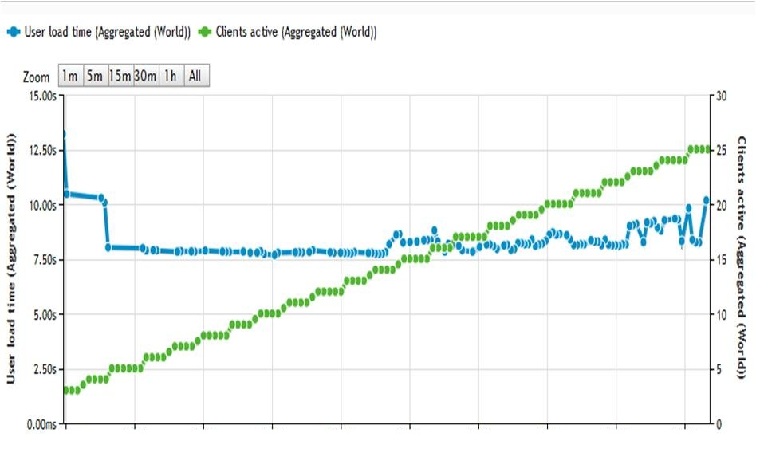
После:
На графиках тестов изнутри кластера видно, что, например, главная страница до рефакторинга при 200 000 посетителях грузилась 40с, а стала грузиться 1,9с.
До:
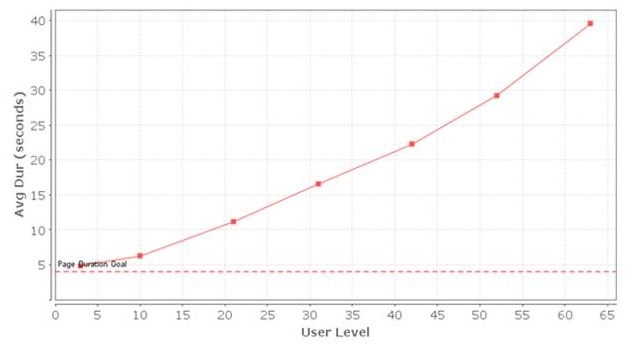
После:
Чем мы порадовали своих разработчиков?
Мы сократили количество запросов к БД как с кэшем, так и без него. Увеличили читабельность кода. Упростили внутреннюю структуру проекта. Удалили устаревшие данные. Изменили больше 14 000 файлов. Упростили масштабирование проекта. И в финале — дали значительный запас проекту для наращивания нагрузки.
Чтобы мы хотели в завершении статьи посоветовать всем веб-разработчикам:
- Пользуйтесь мониторингами состояния серверов. Обычно там все видно.
- Пользуйтесь дебаггерами, следите за самыми ресурсоемкими операциями и циклами.
- Кэшируйте все, что используется постоянно. Скидывайте кэш частями, а не полностью.
- Следите за количеством запросов к БД как с кэшом, так и без кэша
- Профилируйте запросы, следите за количеством данных, передаваемых от БД к апачам. Следите за логикой и оптимальностью выполнения запроса.
- Расставляйте индексы на таблицы в БД.
- Обновляйте CMS.
Наталья Чиликина, руководитель отдела bitrix-разработки ADV/web-engineering
