Вряд ли найдётся тот, кто ещё не знаком с ChatGPT, Midjourney, StableDiffusion — такая популярность говорит сама за себя. Хайп вокруг генеративного искусственного интеллекта (далее — ИИ) не утихает и уже начинает немного надоедать. Но мы, как разработчики, должны оставаться в курсе событий и принимать реальность такой, какая она есть.
А реальность такова:
Использование Copilot и его аналогов, ChatGPT и других генеративных нейросетей увеличивает вашу продуктивность.
Бизнес активно ищет возможности оптимизировать процессы или внедрить новые фичи на основе генеративного ИИ.
Давайте разберём каждое из этих утверждений.
Использование Copilot и аналогов, ChatGPT и других генеративных ИИ увеличивает вашу продуктивность.
По исследованию от GitHub, которое включало в себя не только опрос, но и контролируемый эксперимент, в котором участвовало 95 профессиональных разработчиков, скорость разработки HTTP-сервера на JavaScript была выше на 55% у тех программистов, кто использовал Copilot. Да, на сложных проектах Copilot может иногда и мешать. Но с написанием семантически подходящего boilerplate кода подобные генеративные ИИ справляются на ура.
И совсем не обязательно использовать именно Copilot, тем более, из России это сделать проблематично. Есть много доступных и бесплатных аналогов. Например, Codeium.
С помощью GPT-4 можно написать 300+ строк хороших, качественных юнит-тестов всего за 40 минут, и это реальный кейс в моей работе. 70% кода было написано GPT-4. Мне же оставалось «заревьювить» код, написанный ChatGPT, и дополнить некоторые сценарии тестирования.
С плагинами и возможностью поиска в интернете, а также возможностью анализа pdf-файлов, теперь гораздо проще найти ответ по какому-либо библиотечному API. Или быстро узнать, можно ли использовать библиотеку/модель/фреймворк в коммерческой разработке, скормив GPT-4 текст лицензионного соглашения.
Microsoft уже начала давать доступ на мультимодальный ввод для их бота. Скоро можно будет проверить, сможет ли по картинке макета страницы бот сгенерировать HTML и CSS.
Но стоит отметить, с СhatGPT и Copilot возникает проблема. Туда нельзя сливать чувствительный код, который, например, содержит endpoints вашего RestAPI, адреса серверов и прочее. В таком случае, Copilot я отключаю, а для ChatGPT меняю названия, связанные с инфраструктурой, на заглушки «postMethod1, serverName1, command1» и так далее. Проблему приватных данных я затрону более подробно во втором разделе статьи.
Также всегда стоит помнить, что любая LLM может галлюцинировать и «выдумывать» ответы на ходу. На 100% доверять языковым моделям нельзя. Злоумышленники уже нашли способ использовать способность ChatGPT 3.5 предлагать в своем коде несуществующие пакеты. Как они это делают: сначала выявляются несуществующие пакеты, которые часто предлагает GPT 3.5 в своих ответах. А затем, злоумышленник добавляет в NPM этот несуществующий пакет, но уже со своим вредоносным кодом. Будьте аккуратны и всегда проверяйте, какие библиотеки и пакеты предлагает вам использовать ChatGPT (особенно, версии 3.5).
Вы, конечно, можете решить, что ваших собственных навыков и интеллекта вполне достаточно, и вам не нужны все эти новые технологии. Это вполне уважаемый выбор, и каждый имеет право на своё мнение. Однако, я предпочитаю использовать все доступные инструменты для повышения своей продуктивности.
Бизнес начинает активно искать возможности оптимизировать процессы или внедрить новые фичи на основе генеративного ИИ.
И на этом этапе всё становится ещё интереснее. Если вы, как и я, признаете, что с помощью генеративного ИИ уже сейчас можно делать классные вещи, то можно пойти дальше простого использования ChatGPT и подумать, а как вы можете помочь своей компании внедрить новые технологии в процессы или в новые фичи. Здесь у нас есть два пути.
Первый путь — можно попытаться выучить Machine Learning с 0. Идея неплохая, если у вас есть достаточно много свободного времени, а главное, есть желание и упорство. В таком случае, могу порекомендовать классные гайды (часть 1, часть 2) от автора канала «Техножрица». А вот бесплатный курс от Google. Также можно присоединиться к профессиональному сообществу по ML. Еще могу порекомендовать канал с качественными статьями по ML.
Второй путь — на достаточном уровне разобраться в теме. При этом, не стоит тратить время на то, чтобы научиться с нуля обучать нейронные сети. Надо понять, на что способны Generative AI, их ограничения и недостатки. Как локально развернуть модель. Как модель обернуть в API. Какие задачи можно уже сейчас решать с помощью фреймворка LangСhain. И я считаю, что этот путь намного выгоднее для опытных программистов. Приведу в подтверждение своих слов частичный перевод этой статьи.
:: Перевод ::
Найти специалистов по Data Science и ML довольно просто. Они стоят денег, но на рынке труда есть предложение.
ML‑специалисты могут создать хороший прототип, который понравится бизнесу. Однако дальше получается следующее: прототип запускается в production, и вдруг начинают происходить странные вещи: запутанный код, ломающийся API, проблемы с Out‑Of‑Memory и производительностью.
Между созданием прототипа и разработкой надёжной работающей системы — настоящая пропасть. Вот несколько вещей, которые становятся неожиданностью для команд, занимающихся только ML:
1. Версионирование схем (API и схемы данных)
2. Качество кода и паттерны проектирования
3. Время работы
4. Пропускная способность и задержка
5. Развёртывание и масштабирование
6. Интеграция
7. CI/CD и автоматизация процессов
8. A/B тестирование
9. Телеметрия, мониторинг, протоколирование и наблюдаемость.
На этом этапе компании начинают метаться, пытаясь нанять ML Engineers/ML Ops:
— людей, которые не знают, как обучить модель;
— людей, которые знают о моделях достаточно, чтобы быть в состоянии интегрировать их в бизнес‑системы (ML Engineers) и эксплуатировать их в производстве (ML Ops);
— людей, которые могут поддерживать команды ML и обучать их хорошим инженерным практикам по мере необходимости.
Чем больше людей становятся специалистами только в области ML, тем выше спрос на всесторонне развитых (T-Shape) инженеров, способных поддержать этих специалистов.
Короче говоря, если вы инженер с опытом создания или эксплуатации программных систем, не тратьте свой талант и время на то, чтобы стать специалистом по ML с нуля. Просто добавьте немного знаний в области ML, чтобы ваши навыки сразу же стали применимы в этой области.
:: Конец перевода ::
Andrej Karpathy (Андрей Карпаты) предложил новый термин для такого специалиста: AI Engineer.
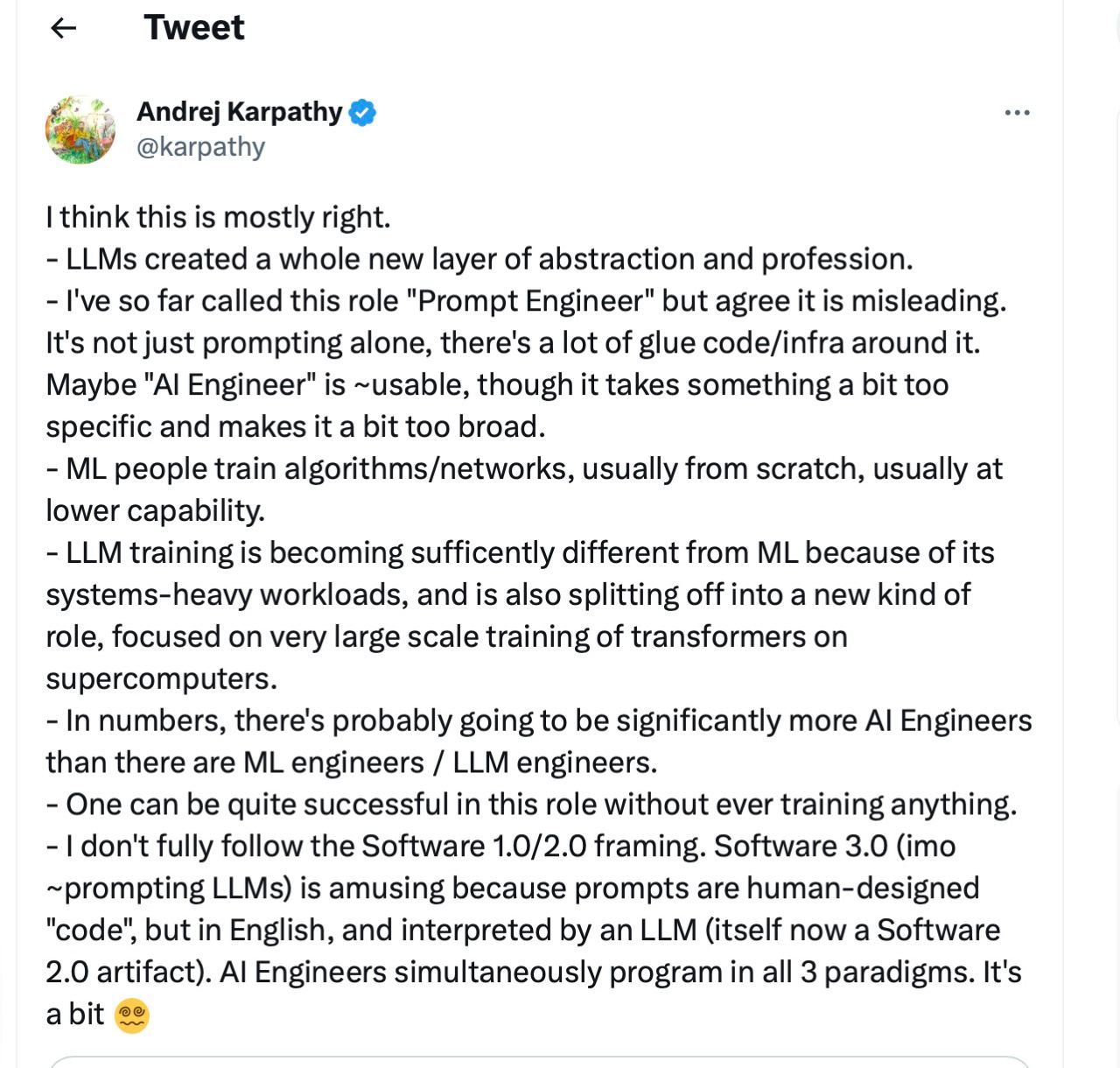
Перевод
Я думаю, что это в основном правильно.
- Большие языковые модели (LLM) создают совершенно новый уровень абстракции и профессии.
- До сих пор я называл эту роль "Prompt-инженером", но согласен, что это вводит в заблуждение. Это не просто формулирование задач для LLM (prompts), вокруг этой роли много связующего кода/инфраструктуры. Может быть, "AI-инженер" тут подойдет, хотя этот термин подразумевает что-то слишком специфичное и одновременно является слишком широким.
- Специалисты по машинному обучению (ML) тренируют алгоритмы/сети обычно с нуля, с меньшими возможностями.
- Обучение LLM начинает сильно отличаться от ML из-за высоконагруженных систем. Появляются новые роли, фокусом которых является крупномасштабное обучение трансформеров на суперкомпьютерах.
- Количественно, вероятно, будет значительно больше AI-инженеров, чем инженеров ML / инженеров LLM.
- В этой роли можно быть весьма успешным, даже ничего никогда не тренируя лично.
- Я не полностью разделяю концепцию Software 1.0/2.0. Концепция Software 3.0 (по моему мнению - возможно promting LLMs) забавна, потому что promts - это созданный людьми "код", только на английском языке, и интерпретируемый большой языковой моделью (причем она сама является Software 2.0). AI-инженеры одновременно программируют в трех этих парадигмах. Это как-то слишком
Теперь давайте подробнее рассмотрим второй путь.
Сразу скажу, воспринимайте эту статью как направление. Её будет недостаточно, чтобы хотя бы минимально разобраться в ML, но достаточно, чтобы знать, куда смотреть и что изучать.
Сначала разберёмся с некоторыми определениями.
Генеративный ИИ - это подкласс искусственного интеллекта, который способен производить новые, уникальные данные. В отличие от дискриминативного ИИ, который преимущественно занимается анализом и классификацией, генеративные ИИ алгоритмы, такие как ChatGPT, могут создавать различные типы контента включая аудио, код, изображения, текст и видео.
LLM — Large Language Model — Большая языковая модель.
Fine‑tune — дообучение LLM, но не обязательно всех ее слоёв.
LoRA — это прорывная технология дообучения моделей, которая модифицирует только маленькую часть модели. Это позволило людям дообучать немаленькие LLM вроде LLaMA прямо у себя на машинах.
Вектора/матрицы embeddings — семантическое представление слов.
Галлюцинации — модель отвечает правдоподобно, но на самом деле творчески заполняет лакуны в знаниях своими придумками.
Семантический поиск — способ поиска информации, основанный на использовании контекстного (смыслового) значения запрашиваемых фраз, вместо поиска точных совпадений ключевых слов.
Промт — формулировка задания для языковой модели.
Теперь разберёмся, как ориентироваться в бесконечном потоке новостей по типу «GPT-4 дала 100% верных ответов и прошла экзамен в MIT» или «Посмотрите на нашу OpenSource модель, которая ничуть не хуже GPT-4?». Ситуация на данный момент такова:

Если это статья по исследованию, то всегда надо обращать внимание на дизайн этого исследования. Например, рассмотрим это исследование по Copilot. Здесь выборка из 42 человек, участвующих в опросе - это мало. На малых выборках, при подсчёте средних значений, будет высокий уровень вариабельности. Делать из такого исследования какие-то значимые выводы нельзя. Или вот пример статьи про то, что GPT-4 решила 100% задач из экзаменов для получения диплома в MIT. Уже сама цифра 100% смущает. Конечно же GPT-4 не может справиться с экзаменами в MIT.
Если это очередная LLM — проверьте рейтинги и бенчмарки. Приведу несколько различных рейтингов:
Рейтинг ChatBot Arena.
Рейтинг Hugging Face.
Рейтинг SuperGlue.
А также есть BigBench — набор из 204 задач для тестирования возможностей LLM, который составили 444 автора из 132 институтов. Полезным будет изучить эту статью с 5-ю методами оценки LLM.
Если это очередной сервис, который отвечает по вашему pdf — проверьте его качество. Можно взять знакомый для вас pdf‑файл и задать конкретные вопросы. Я проверила два плагина для GPT-4 на статье с ранее упоминавшимся исследованием. Плагин ChatWithPDF с ответами на точные вопросы справился. А вот плагин AskYourPDF с ответами на точные вопросы систематически не справлялся.
Я задала вопрос по диаграмме № 5 из исследования:

ChatWithPDF — ответил правильно.

AskYourPDF — вообще не дал никаких цифр.
Вопрос по диаграмме №8:
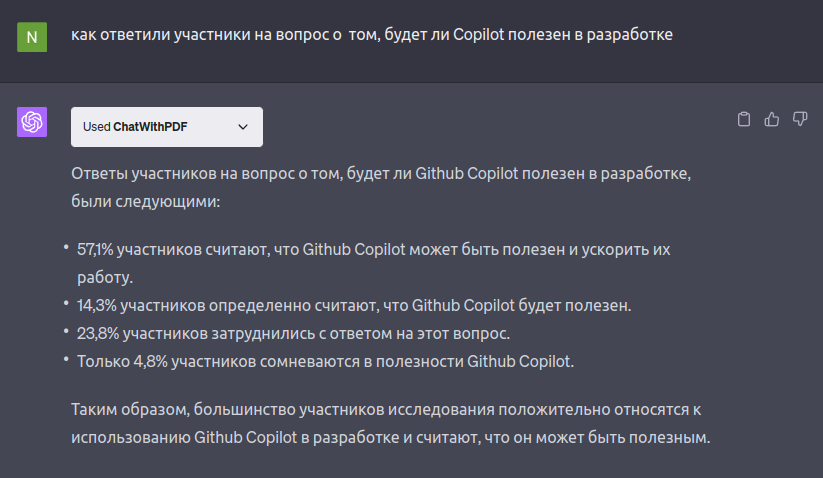
ChatWithPDF — ОК, всё верно.
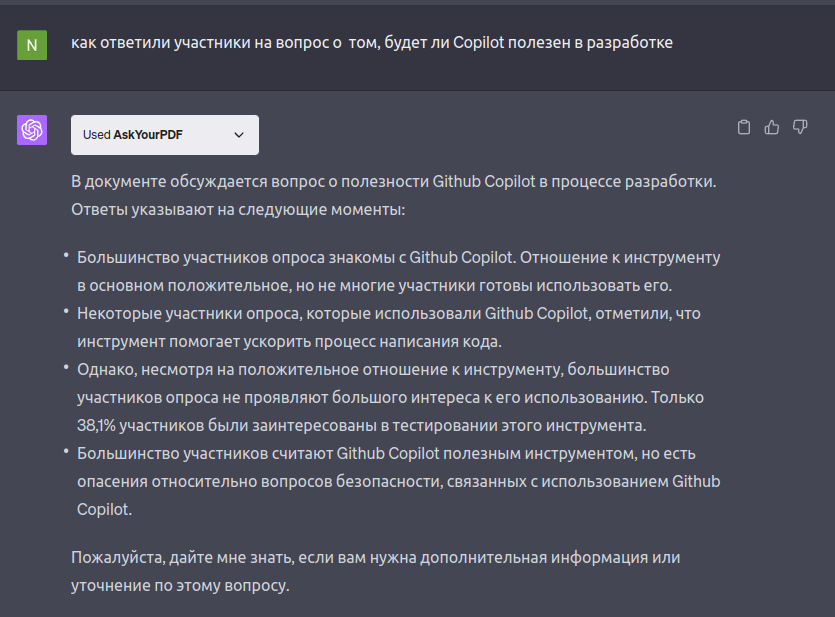
AskYourPDF — дал одну цифру, и то, неправильную.
И, наконец, поговорим о том, что мы можем предложить бизнесу. Какие задачи можно пробовать автоматизировать уже сейчас, используя Generative AI.
Документирование кода, составление шапок методов, файлов.
Автоматизация создания файлов для локализации.
Добавление к тексту определенного стиля, например, стиля корпоративной переписки.
Поиск и исправление семантических ошибок в тексте.
Sentiment analysis. Можно анализировать отзывы пользователей. Или цензурировать токсичные комментарии.
Локальный аналог Copilot.
Улучшение процессов code review.
Q&A (вопросы и ответы) по локальной базе знаний.
Быстрый рендер фасадов на основе StableDiffusion, если важна скорость, а не точность.
Вы также можете изучить, какой набор задач можно решить, используя фреймворки LangChain и LLamaIndex.
Опишу, как можно решить некоторые задачи из этого списка.
Задачи № 1-4 можно решить простым prompt-engineering’ом и техниками zero-shot, few-shot. Здесь хороший гайд по prompt‑engineering. В основном, в этом случае, используют API OpenAI, что для России не всегда подходит. В России бизнес будет делать больший уклон на использование локальных LLM или же LLM от Яндекса/Сбера.
При использовании любого стороннего API возникает угроза утечки данных. Поэтому для проприетарного кода или закрытой базы знаний подойдут только локально развёрнутые модели. Следовательно, уже сейчас можно пробовать разворачивать OpenSource модели у себя локально. И применять техники prompt-engineering для локальных моделей. Для такого подхода модель должна быть дообучена на инструкциях. По ссылке пример instruct-модели.
Где брать модели, как понять, «потянет» ли ваша система выбранную модель и как их разворачивать у себя на инфраструктуре? OpenSource модели традиционно публикуются на сервисе HuggingFace. Понять, потянет ли ваша система модель, можно с помощью этого ресурса. Запустить модель у себя локально можно с помощью этой инструкции.
Задачи № 6, 7 можно решить с помощью OpenSource моделей, обученных в том числе на коде и дообученных уже на ваших репозиториях с кодом. Приведу ссылки на несколько OpenSource Code LLM моделей:
Для дообучения могу посоветовать такой гайд (для текстового гайда нужен VPN). Либо, можно использовать существующие сервисы, которые позволяют развернуть их модели локально, что предотвратит угрозу утечки данных, но возникнут проблемы оплаты таких сервисов из России. Ниже приведена табличка с аналогами Copilot, где указано, какие из них можно разворачивать у себя локально на своей инфраструктуре.

В эту таблицу не попал ещё один интересный сервис - MetaBob.
И подробнее всего опишу задачу №8 - Q&A по локальной базе знаний.
Во‑первых, сразу обозначу, с какими проблемами вы точно столкнетесь:
Любая LLM может и будет галлюцинировать.
Вам потребуется индексировать данные.
LLM в большинстве своем лучше всего понимают английский язык и хуже русский.
Подобную задачу можно решить двумя способами:
Использовать цепочку Retrieval+Rerank+LLM (Этот вариант предпочтителен).
Fine‑tune LLM.
Retrieval — это процесс извлечения знаний с помощью семантического поиска по векторной базе данных. Для начала ваши, скажем, статьи в confluence, нужно поделить на маленькие chunks, затем перевести эти чанки в вектора embeddings. Запросы от пользователей мы тоже переводим в embeddings. И, далее, выполняем семантический поиск по векторной базе данных на основе запроса пользователя.
Rerank — процесс семантического ранжирования найденных на этапе Retrieval результатов. Пользователь может задать вопрос, вообще никак не относящийся к вашей базе знаний. Но поиск по векторной БД будет всегда отдавать какие-либо результаты. Этот этап позволит отсечь нерелевантные по семантике результаты, что еще больше уменьшит вероятность галлюцинаций.
LLM — на этом этапе формируется ответ пользователю. Найденные и отранжированные вектора embeddings мы переводим обратно в текст, помещаем их в prompt в качестве контекста и добавляем туда же текстовый запрос пользователя. И уже prompt с контекстом и вопросом по этому контексту отправляем в LLM. В идеале, все найденные chunks надо связать с исходными документами. Чтобы пользователь видел, на основе каких источников был сформирован ответ.
Приведу схему описанного выше варианта: здесь этап Retrieval+Rerank выполняется в верхней части схемы, а этап LLM - в нижней.
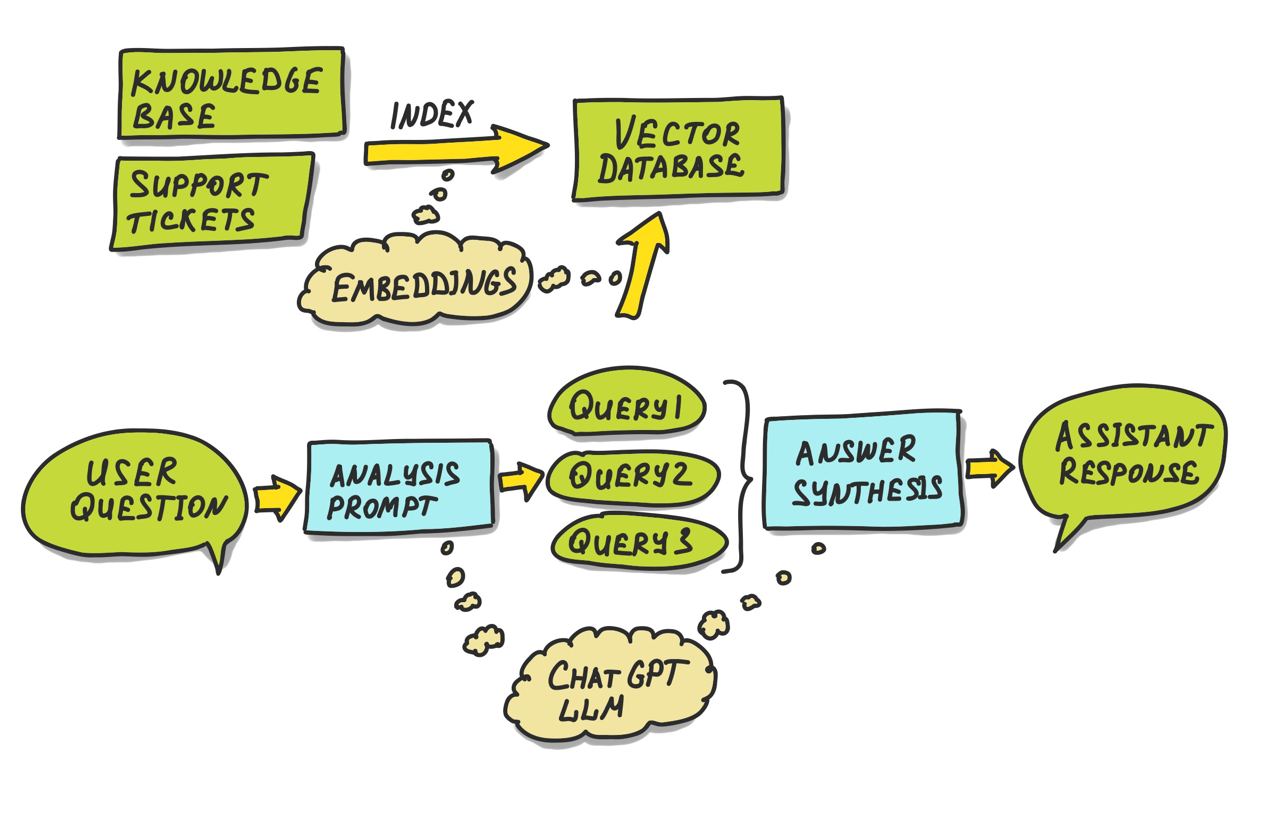
Такой подход даст нам бОльшую точность в ответах, а также возможность получить от LLM «цепочку размышлений».
Здесь можно отметить, что для первых двух этапов подходит модель SBERT. Архитектура этой модели отличается от GPT. Особенность этой модели в "двунаправленном" чтении. Такая модель при своих небольших размерах намного лучше понимает контекст, чем классические декодеры на базе трансформера (GPT).
Варианты моделей SBERT на HuggingFace:
для этапа Rerank советуют использовать эту модель
Для этапа LLM из OpenSource русскоязычных моделей можно использовать FRED-T5-LARGE_text_qa или SAIGA.
PrivateGPT - пример реализации всей описанной выше цепочки.
LLM галлюцинирует больше, когда ей приходится доставать информацию из знаний, полученных во время обучения. Галлюцинирует меньше, если данные есть в контексте. Поэтому если поиск по embeddings найдёт неверные документы, а верные не извлечёт (что бывает при простых методах индексирования документов вроде "а давайте нарежем текст кусками по 100 слов"), то плохое качество ответов практически гарантировано.
Если же просто зафайнтюнить предобученную LLM на вашей базе знаний (это способ №2) — никакой цепочки размышлений не будет. Равно как и ссылок на источники. Хотя можно попробовать использовать первый вариант, но с локальной fine-tuned LLM, то есть продолжать "скармливать" уже дообученной модели в контекст данные, полученные на этапах Retrieval+Rerank. Благодаря дообучению модель сможет лучше работать с предметной областью. Но, как говорил Andrej Karpathy в MS Build 2023, после fine-tuning модели становятся несколько "глупее" (падает энтропия на ответах).
Перед завершением хочу поделиться ещё несколькими полезными ресурсами:
Канал в телеграм «LLM под капотом». Спасибо автору канала за отзывчивость и помощь в проверке фактов.
Канал в телеграм «Сиолошная».
Выводы:
Личное использование ChatGPT и подобных LLM может повысить вашу продуктивность.
Не обязательно изучать ML с нуля, чтобы быть в курсе последних тенденций в мире генеративных нейросетей. Достаточно активно изучать возможности генеративных нейросетей, их области применения и ограничения.
Чем больше людей становятся специалистами только в области ML, тем выше спрос на всесторонне развитых (T-Shape) инженеров, способных поддержать этих специалистов.
В этой статье я предлагаю лишь некоторые идеи применения генеративных нейросетей и даю источники, с которыми было бы неплохо ознакомиться, если захотите попробовать реализовать какие-то из этих предложений.
А какие идеи для применения генеративных моделей есть у вас? Делитесь ими в комментариях!
В заключении хочу сказать, что не нужно забрасывать развитие собственного интеллекта и пытаться делать всё только с помощью генеративного ИИ. Учитесь, саморазвивайтесь, и это точно даст свои плоды.
Автор: инженер-программист Валентина Дмитриева.

