

Мы уже рассказали вам о хранилище Avito, картинках, медиапикере, но главный вопрос так и оставался нераскрытым: какая она, архитектура платформы, из каких компонентов состоит и какой стек использует. Вы просили рассказать об аппаратной составляющей Avito, используемой системе виртуализации, СХД и так далее — ну что же, отвечаем.
Аппаратная часть
Долгое время наши серверы стояли в датацентре Basefarm в Швеции, но в январе-феврале прошлого года мы справились с масштабной задачей по переезду в московский датацентр Dataspace. Про миграцию, если это будет интересно, расскажу в отдельной статье (про перенос базы мы уже рассказывали на Highload 2016).
Переезд был вызван несколькими причинами. Во-первых, нашумевшим законом №242-ФЗ о хранении персональных данных граждан РФ. Во-вторых, мы получили больше контроля над своим железом — не всегда расторопные работники шведского датацентра могли выполнять простейшие заявки по несколько дней; здесь же персонал делает всё быстро, да и в любом случае мы всегда можем лично приехать в ДЦ и поучаствовать в решении возникших проблем.
Серверы
Серверы разделены на несколько функциональных групп, в каждой группе своя конфигурация железа. Например, серверы для PHP-бекэнда выполняют также роль первого уровня хранилища картинок (про картинки подробнее ниже), на них немного оперативной памяти, небольшие диски, но производительные процессоры. На серверах для Redis-кластера, наоборот, много оперативной памяти, а процессоры не такие мощные, и так далее. Такие специфические конфигурации позволили нам заметно снизить стоимость серверов по сравнению с тем, что было раньше, когда многие серверы были универсальной конфигурации, и какие-то ресурсы в них всегда были не утилизированы.
Сеть
Наша сеть построена по классической двухуровневой схеме: ядро плюс уровень доступа. Для отказоустойчивости каждый коммутатор уровня доступа подключается по оптике к двум разным корневым коммутаторам; поверх этих двух линков делается LACP-линк (один виртуальный линк поверх нескольких физических, позволяет полностью утилизировать все физические линки и добавляет устойчивость к отказу физических линков).
Программная часть
Виртуализация
Аппаратная виртуализация как таковая у нас не используется, а вот виртуализация на уровне операционной системы (aka контейнеры) — очень даже. В основном это LXC (когда-то давно использовалась OpenVZ), но сейчас мы с интересом смотрим на Docker (с Kubernetes) и потихоньку перебираемся на него, а новые микросервисы запускаем сразу в кластере Kubernetes.
О том, как мы используем Kubernetes, мы рассказывали на профильном митапе и Codefest 2017:
- “Kubernetes в Avito” — Евгений Ольков (Kubernetes meetup, 2017)
- “Helm: пакетный менеджер для Kubernetes” — Сергей Орлов (Kubernetes meetup, 2017)
- “Kubernetes как платформа для микросервисов” — Сергей Орлов и Михаил Прокопчук (Codefest, 2017)
Хранилище картинок
История хранилища картинок подробно описана в статье. Сейчас оно имеет двухуровневую структуру: первый уровень — маленькие картинки (те, что используются в поисковой выдаче и, соответственно, часто запрашиваются; разрешением до 640x640) плюс кэш больших картинок, второй уровень — большие картинки, которые доступны только из карточки объявления. Прямого доступа извне к серверам второго уровня нет, всё проходит через первый уровень (и таким образом оседает в кэше). Ввиду разного профиля нагрузки на разные уровни, конфигурация и количество серверов в каждом уровне также различаются: на первом уровне много серверов с дисками небольшого объёма, а на втором уровне немного (~ в пять раз меньше) серверов с дисками большого объёма.
Все необходимые разрешения картинок генерируются на бэкэнде при загрузке. Картинки некоторых непопулярных размеров не хранятся на серверах, а генерируются nginx’ом на лету. Аналогично с ватермарками: для большинства разрешений они накладываются бекэндом сразу же, но некоторые разрешения мы отдаём партнёрам без ватермарок (а на сайт — с ватермарками), поэтому они накладываются nginx’ом на лету.

Если вдаваться в подробности, то у нас есть по 100 виртуальных картиночных нод первого и второго уровня, которые равномерно раскиданы по физическим серверам соответствующих уровней. Привязка виртуальных нод к физическим регулируется с помощью CNAME-записей в DNS и, в случае с первым уровнем, внешних IP на серверах.
Для снижения нагрузки на наши серверы и экономии трафика и электроэнергии мы используем CDN, однако наша платформа обладает достаточными ресурсами для того, чтобы работать самостоятельно, и мы не завязаны на конкретном провайдере.
Устройство платформы
Входящий трафик балансируется на разных уровнях: L3, L4, L7.
Внутреннее устройство платформы можно описать как “находится в процессе перехода с монолита на микросервисы”. Функциональность поделена на куски, которые мы называем “сервисами” — это ещё не микросервисы, но уже не монолит.
Устройство сервиса типовое: фронтенд на nginx, бекэнд — собственно сервис, и некоторый набор прокси до всех необходимых источников данных — БД, кэшей, других сервисов.
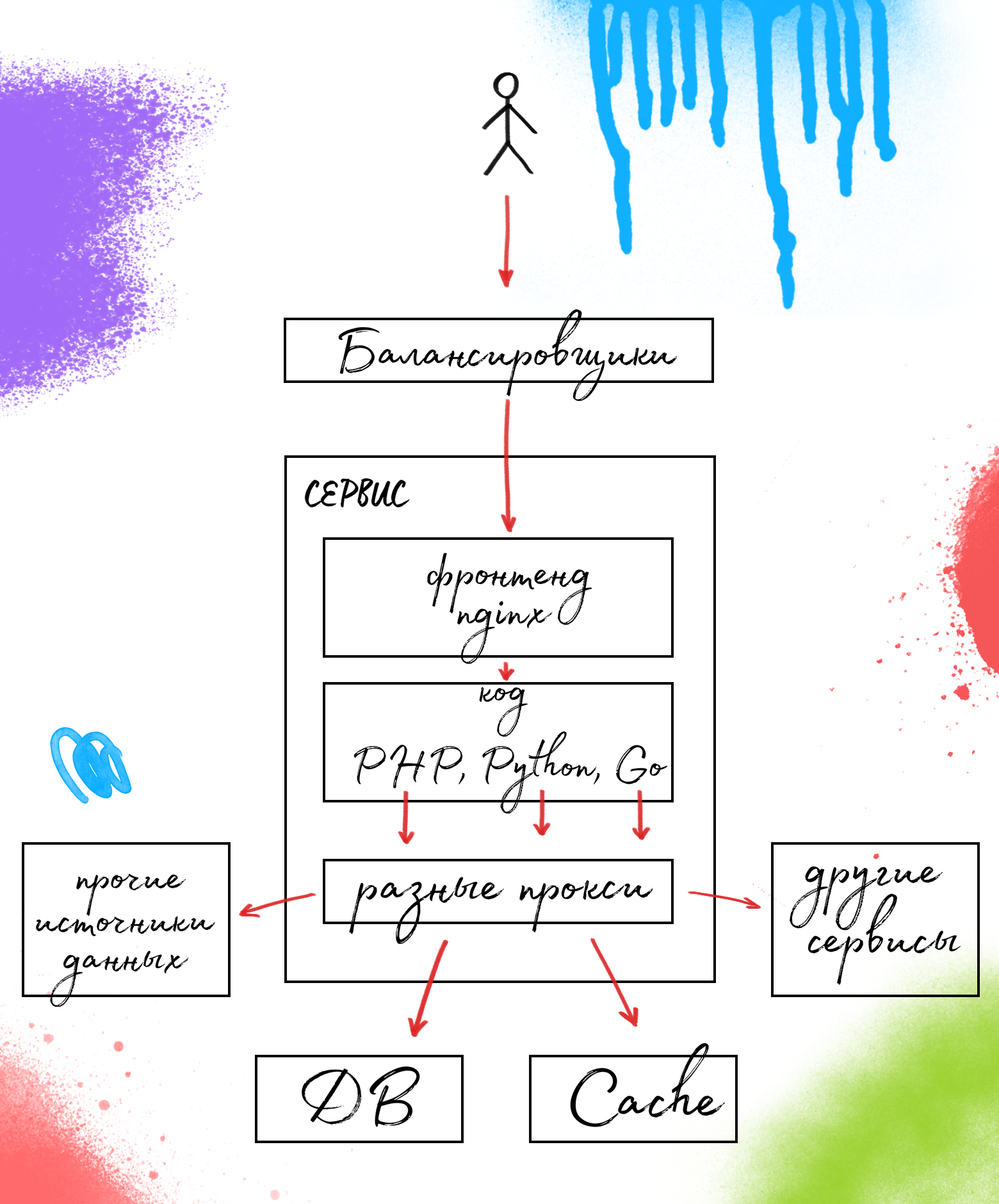
Некоторые подробности об используемых прокси можно узнать из моего выступления на Highload Junior 2016.
Заключение
Часто от высоконагруженных проектов ждут сложной архитектуры, пятиэтажных решений, требующих непрерывной поддержки. Это неправильно — чем сложнее система, тем больше неприятностей может породить самый незначительный баг. Поэтому мы за простоту. Мы придерживаемся принципа KISS, не плодим сущности и не усложняем то, что должно быть простым — и в разработке, и в поддержке, и в администрировании.
Такое устройство платформы позволяет нам легко её масштабировать, а значит избегать множества проблем. Сейчас мы находимся в переходном
