
Привет, я Александр Лукьянченко, руководитель разработки PaaS Авито. Возможно, вы уже читали или слышали про нашу внутреннюю платформу для разработчиков. Мы уже писали про нее в этой статье.
Я расскажу о платформенном продукте в целом, продуктовых процессах, и обзорно пробегусь по инструментам и возможностям, которые касаются разных этапов в жизненном цикле разработки. Покажу тот уровень сервиса, который мы предоставляем.

Что такое платформенный продукт
Классический подход к разработке с несколькими командами выглядит так

Каждая продуктовая команда разработки пишет отдельные части бизнес-логики. Чтобы доставить их в продакшен, кто-то из команды обращается к релиз-менеджеру. То есть разработка и доставка в продакшен разделены. То же самое касается и непосредственно эксплуатации: доступ есть у выделенных инфра-инженеров, а разработчики не задумываются о том, что происходит после написания кода.
DevOps-подход меняет эту парадигму и позволяет разработчикам владеть полностью всем жизненным циклом продукта:

Каждая команда сама доставляет свою часть бизнес-логики в продакшен. Этот подход убирает из процессов доставки и эксплуатации релиз-менеджера, инженеров эксплуатации, которые могут быть узким местом. В итоге навыки и нужные инструменты для выката в продакшен есть у каждого разработчика.
Этот подход хорошо работает, пока продукт не начинает активно масштабироваться. Как только компания перерастает точку в пару десятков команд, появляется проблема: большому количеству разработчиков нужно покрывать весь жизненный цикл, иметь все необходимые навыки и опыт работы с инфраструктурой. Это означает более высокие требования к инженерам и рост порога входа в команду. Растёт и вероятность ошибок.
На этом этапе стоит взглянуть на разработку с другого ракурса и построить взаимодействие в компании в формате Platform Engineering:

В этом случае появляется централизованная платформа со всеми механизмами, которые нужны продуктовому инженеру, чтобы доставлять бизнес-логику в продакшен.
В такой схеме каждому разработчику не нужно глубоко погружаться в реализацию инфраструктуры. Вместо этого платформа предоставляет высокоуровневый интерфейс, который помогает достаточно просто решать повседневные задачи.

Под платформой скрывается большое количество инфраструктурных решений, каждое из которых имеет свой интерфейс, особенности. Суть платформенного продукта — дать пользователям не множество отдельных компонентов, а единый интерфейс. Это может быть CLI-утилита или графический интерфейс, который скрывает всю сложность под капотом.
Мы в Авито используем термин PaaS — «платформа как сервис». В последнее время набирает популярность терминология Internal Developer Platform (IDP) — «внутренняя платформа разработки». Он лучше отражает, что ключевые потребители сервиса — именно разработчики.
Вызов в построении платформенного продукта
Одна из ключевых сложностей при построении платформенного продукта — удержать баланс между гибкостью и простотой решения.
Мы хотим дать разработчикам простой интерфейс, через который можно выполнять все основные задачи. Но может случиться, что из-за этого не хватит гибкости и инструмент станет неудобным. А может случиться перекос в обратную сторону. Если инструмент очень гибкий, то он становится сложным: приходится изучать настройки, разбираться, как он работает.
Золотую середину между этими двумя состояниями нужно искать опытным путем. Есть несколько маркеров, на которые стоит ориентироваться.

Догоняющие метрики. Когда вы уже внедрили инструмент, можно оценить, как изменился объем запросов в техподдержку. Если инструмент получился слишком гибкий, то будет много вопросов, как именно его использовать. Если инструмент простой и ограничивает разработчиков, то будут запросы на новые возможности и функциональность.

Метрики этапа внедрения. Злейший враг любой платформы — слишком большое количество возможностей, фич, дополнительных продуктов. Поэтому ещё на этапе внедрения или даже раньше нужно сформировать метрики, которые покажут эффективность конкретного инструмента.
Например: одна из фич особо не снижает время на разработку или количество инцидентов. Тогда её можно убрать и не тратить ресурсы на поддержку.
Ценность и цена платформы для бизнеса
Четыре ключевых профита от использования платформы:
повышение скорости разработки в целом по компании;
команды фокусируются на донесении бизнес ценности, потому что разработчикам не нужно тратить время на рутинные задачи;
система становится стабильнее и качественнее благодаря общим для всех команд инструментам, сервисам и шаблонам. Лучшие практики распространяются централизованно;
централизованный контроль за технологиями и подходами к разработке, которые используются в компании.
Естественно, за пользу нужно платить. Я выделяю три ключевых момента:
Стоимость разработки платформы. Чтобы получить продукт нужного уровня по качеству, удобству и безопасности, нужно вложить в него довольно много ресурсов. При этом на старте требуются ощутимо бóльшие ресурсы, не всегда пропорциональные размеру всей инженерной команды.
Есть вероятность получить проблемы поддержки или развития платформы в будущем, если неаккуратно подойти к выбору технологий и конечного интерфейса. Нужно заранее продумывать, как реализовать компоненты, чтобы в будущем с ними не возникло проблем.
Выбирая технологию, на основе которой у вас будет работать вся система, надо ответственно подходить к выбору и оценивать потенциал, текущую распространенность и технический стек, на котором технология реализована. Яркие примеры технологий — оркестратор, система контрактов между микросервисами и подобные. В случае потери популярности скорее всего придется переезжать, либо поддерживать своими силами.
Второй момент: важно на самом раннем этапе стараться скрыть конкретные реализации за общим интерфейсом. К примеру, тот же оркестратор Docker Swarm можно легко заменить на k8s, если пользователь работает не напрямую с сущностями Docker Swarm, а с общими абстракциями.
Внедрение платформы требует времени. Если в компании раньше не использовали Platform Engineering-подход и централизацию инструментов, миграция может быть долгой и трудной. У нас это заняло примерно два года.
Продуктовые процессы для построения зрелой платформы
На высоком уровне платформа мало чем отличается от других продуктов. Те процессы, которые работают, например, для построения ценного и качественного продукта конечного сервиса Авито, также применимы и для платформы.
Мы используем набор ключевых механик, которые покрывают как аспекты создания новых фичей и подпродуктов, так и развитие уже существующих зрелых механизмов:
унифицированный единый саппорт пользователей платформы;
единое окно сбора фидбэка и запросов по болям, с которыми встречаются пользователи;
системный сбор метрик удовлетворенности;
discovery-процесс.
Коротко пробежимся по каждому из них в разрезе ценности и конкретной реализации.
Унифицированный единый саппорт пользователей платформы
Неважно, на какой стадии развития находится продукт. Один из ключевых показателей качества — отстроенный процесс поддержки. Он помогает оперативно решать горящие инциденты и повседневные вопросы в рамках жизненного цикла разработки.
Процесс — набор механик, которые позволяют дать хорошее качество и даже улучшить сам платформенный продукт:
Единое окно по всей платформе. На первой линии идёт уточнение деталей, ответ на стандартные вопросы и определение тематики для роутинга на нужного дежурного инженера, если будет сложная проблема.
Сбор аналитики по зонам. Это позволяет понимать, в какую зону надо инвестировать больше времени, чтобы упростить интерфейсы, автоматизировать процессы и более радикально переделать конкретные системы.
Агрегация времени ответа и удовлетворенности. Только на базе метрик можно понимать, насколько процесс работает слаженно и не является бутылочным горлышком в разработке.
База знаний и её системное наполнение. Саппорт отлично показывает проблемы документации, её отсутствие в нужных зонах или сложность навигации и поиска.
Единое окно сбора фидбэка
Часто важные и влияющие на дальнейшее развитие продукта запросы и боли обсуждаются в чатах саппорта, кулуарных дискуссиях. Проблема в том, что не остаётся системный след, с которым было бы удобно работать. В итоге приоритезация, построение роадмапов развития часто не учитывают потребности пользователей.
Тут поможет простой и понятный процесс сбора фидбэка и болей. Чтобы системно работать с ними, важно сделать единое окно для описания текущей ситуации. При этом собирать нужно не feature request, а именно боли, так как конкретные идеи на реализацию могут вести к решению не той проблемы, которая на самом деле существует.
В нашей форма сбора запросов несколько полей:
Описание проблемы;
Потенциальный охват;
Контактные лица для custdev и уточнения подробностей;
Идеи по решению (опционально).
Это позволяет вытащить именно боли и продумать подходящее платформенное решение. А ещё сделать агрегацию и понять, можно ли одним решением закрыть сразу пачку разных запросов.
Чтобы для пользователей процесс был прозрачным, мы сформировали две линии. На первой мы в течение двух недель гарантированно даём ответ о перспективах решения обозначенной проблемы. Далее ещё в течение двух недель фиксируем конкретные шаги в виде Discovery, кусочка роадмапа или конкретной задачи. При этом многие запросы заканчиваются отклонением, так как для них уже есть решение, либо проблему надо решать с другой стороны.
Системный сбор метрик удовлетворенности
Многие знакомы с термином Developer Experience. Если простыми словами, он описывает, насколько разработчику комфортны, удобны и понятны инструменты, чтобы быстро делать бизнес-задачи и нигде не тратить время впустую.
Измерение DevX — задача сложная и идеальный подход пока не придумали. Есть метрики, которые показывают в целом скорость доставки ценности, время, затраченное на конкретные этапы. Например, набор метрик DORA. Но на самом деле сами по себе они вряд ли дадут необходимые инсайты. Поэтому мы пользуемся опросами, которые позволяют прощупать все основные зоны соприкосновения пользователя с платформой.
Сбор фидбэка делится на два направления:
Системный сбор NPS по зонам периодическим опросом на всех пользователей.
Instant feedback, в котором пользователь оценивает операцию сразу после её завершения. Например, релиза микросервиса в прод. Или после добавления нового RPC метода через нашу CLI утилиту.
Общий NPS с текстовым фидбэком позволяет получить так называемый helicopter view и понять, где самая западающая зона и какой проект стоит сформировать на развитие. А instant feedback генерирует отличные метрики, за которыми стоит следить во времени и точечно обрабатывать проблемы или неудобства конкретных пользовательских сценариев в системе. Даже самых небольших.
В итоге на выходе при системной работе с удовлетворенностью мы получаем:
observability удобства пользования инструментами,
понимание, как дальше развивать уже работающую функциональность.
Discovery-процесс
Это история про создание нового. У платформы есть ярко выраженная особенность: её разработчики — её же пользователи, понимающие бизнес-часть продукта. С одной стороны, это огромный плюс — можно общаться с пользователями на одном языке, формировать стратегию, исходя из своего видения. Но с другой стороны это рождает и перекос: вместо зрелой продуктовой работы действует только экспертное мнение. А оно порождает не всегда востребованные и удобные решения.
Для борьбы с этим есть механика Discovery, которая состоит из нескольких ключевых аспектов:
Описание проблемы и её валидация: проведение custdev с пользователями, чтобы подтвердить существование проблемы на прошлом опыте.
Выделение заказчиков и заинтересованных лиц. Без этого будет сложно найти early adopter’ов, снять первичный фидбэк.
Метрики успеха и влияния. Важно определить, что именно прокачивает: новый проект или крупная фича. На раннем этапе начать собирать метрики, если их ещё нет. Иначе будет сложно понять в будущем эффект и отказаться от неудачных решений.
Варианты решения и их сложность. Это уже заходит в плоскость конкретных имплементаций и в целом архитектуры. Мы здесь описываем базовые наброски, чтобы можно было вкупе оценить, стоит ли идти в реализацию на раннем этапе. Тут бывает сразу понятно, что изменение не стоит свеч.
Пользовательские сценарии, Customer Journey Map, интерфейсы. На этом этапе в идеале ещё до реализации показать наброски конечным пользователям, чтобы оценить применимость и удобство. Это значительно повлияет на результат.
Фазы зрелости платформы
Представим композитную метрику, которая состоит из удобства, скорости и стабильности нашей платформы.

Пока конечный продукт маленький, инженеров мало и команды небольшие, проблем не будет. На этом этапе обычно хватает пайплайна Gitlab CI или любой другой системы, нескольких базовых шаблонов и библиотек. Но со временем команды становятся больше, продукт растёт и композитная метрика начинает деградировать. Так происходит, потому что нет необходимых общих механик, которые бы отслеживали актуальность стека, размер технического долга, предоставляли удобные рельсы для прохождения тестов, релизного цикла и прочих необходимых в разработке инструментов.
Понятно, что деградация качества и скорости разработки будет медленной и не скатится в ноль за недели или месяцы. Кроме того, есть способы влиять на метрики без единой платформы. Но со временем масштабировать разработку станет сложно.
В то же время использование платформы постепенно улучшает композитную метрику. Это не быстрый процесс, но с платформой качество и скорость разработки вырастут.

В жизненном цикле платформы я выделяю три ключевые фазы:
Essential features. В первое время после запуска IDP команды получают огромный профит от её использования. Допустим, в командах разработки нет единых пайплайнов. Это явная проблема, которую мы хотим решить с помощью централизованного инструмента выкатки. Естественно, когда платформа начинает работать, проблема решается и эффект от этого сразу заметен.
Adoption. Процесс миграции всех команд на платформу обычно долгий, но важный. Я выделяю его специально, потому что это та фаза, в которой важно определить ключевые возможности платформы. При переезде будет огромное количество запросов на разные возможности и необходимо строго модерировать какие возможности нужны 95% потребителей, а какие слишком нишевые и лучше переделать конечную систему или вообще не тащить сервис в платформу.
Evolution. Когда платформу использует больше 90% разработчиков, она переходит в фазу инкрементального развития. IDP уже работает, выполняет свои задачи, покрывает основные потребности и в дальнейшем её можно поддерживать и развивать так же, как любой другой продукт.
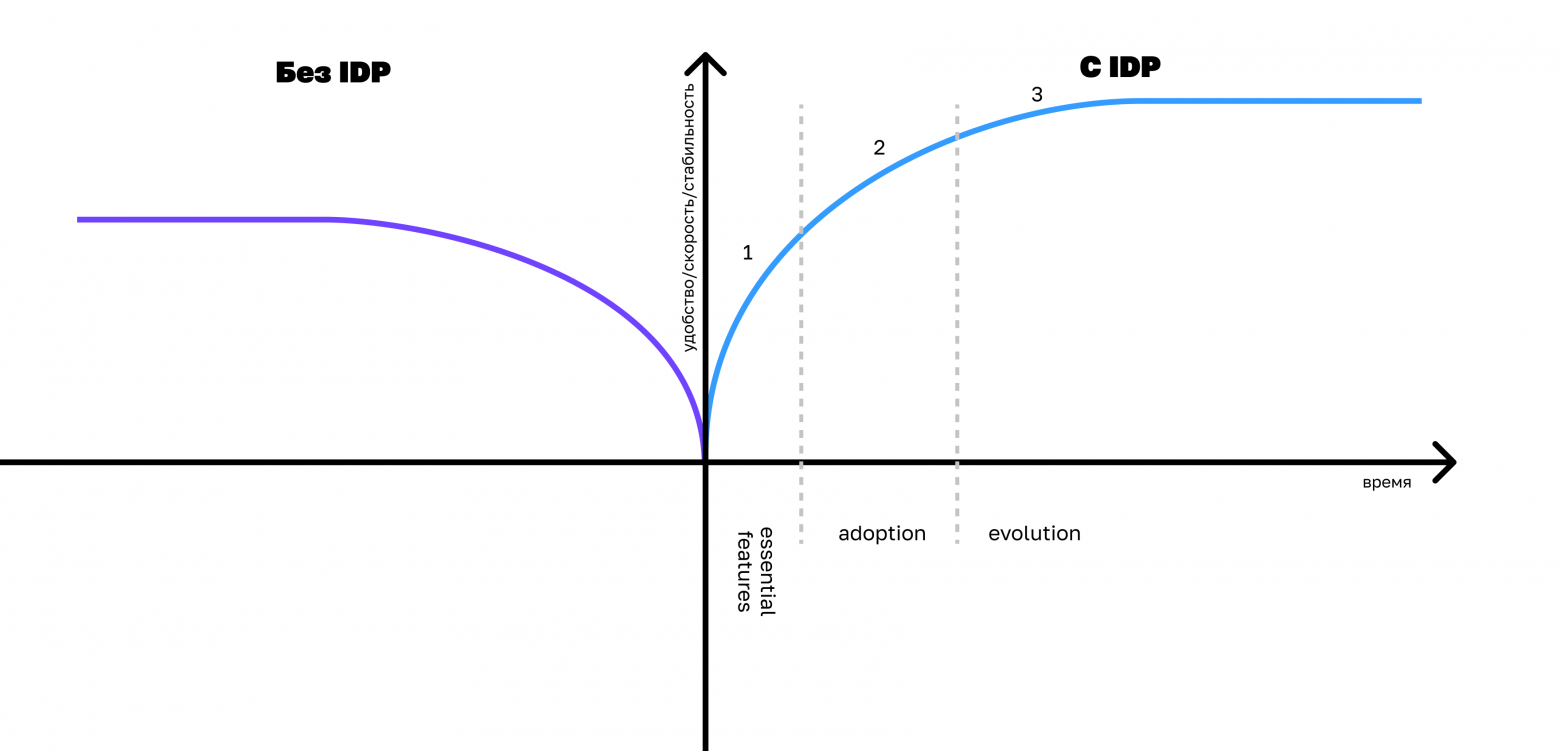

Дальше мы посмотрим на нашу платформу, которая находится в фазе evolution.
Платформа покрывает все этапы, которые разработчик проходит в компании: начиная с онбординга и заканчивая доставкой и эксплуатацией продукта. Я расскажу об основных возможностях платформы на каждом этапе, фокусируясь на стыке непосредственно с разработкой.
Прежде чем перейдём к конкретике, стоит сказать об общих подходах, используемых при построении платформы:
One button-интерфейсы. Всё, что можно свести к полной автоматизации без ущерба эффективности или необходимым возможностям, мы стараемся скрывать за простыми интерфейсами.
Zero configuration. Такой подход заставляет задуматься: действительно необходим ли тот набор настроек или действий, который мы запрашиваем от пользователя? Зачастую значения по умолчанию покрывают большинство кейсов.
Явное разделение ролей platform и end users. Эта парадигма позволяет явно разделить интерфейсы и сфокусировать platform-инженеров на создании простых и удобных интерфейсов. Чуть ниже этот подход будет хорошо иллюстрировать спецификация OAM.
Закладывание best practices на уровне архитектуры платформы и интерфейсов. Например, технически закрываем возможность ходить в одно хранилище из нескольких сервисов. Так не будет жёсткой связанности и сервисы можно будет развивать независимо.


Старт работы с платформой и создание сервисов
Старт и онбординг. Платформа работает по принципу One Button Start — локальную среду и весь необходимый инструментарий можно развернуть одним действием. Для развертывания локального оркестратора мы используем minikube.
Также мы начали использовать Lima — проект, который позволяет запустить локальное окружение на Mac с ARM-процессорами и предоставить docker, k8s без docker for mac.
Создание сервисов. Используем тот же подход, в небольшом визарде разработчик выбирает название, нужный шаблон и платформенный механизм создаёт все необходимые ресурсы: репозиторий сервиса Boilerplate, механики по мониторингу, CI-пайплайны и другие необходимые ресурсы.

На картинке изображен cookiecutter как один из возможных вариантов реализации. У нас это собственный провиженер, который отрабатывает сагу по всем необходимым ресурсам.
C точки зрения разработчика самая интересная часть на этом этапе — Boilerplate. В шаблон встроено всё необходимое:
структура микросервиса;
базовые конфигурации (app.toml, nfr, autocanary, alert, actions);
метрики, логи, трейсинг, healthcheck, pprof и sentry;
решение по управлению зависимостями (go.mod);
точки входа (сервис, worker, cron);
схемы взаимодействия сервисов (RPC и async events);
кодогенерация (server, client, consumer, producer, toggle).
Все они тоже работают по принципу One Button Start, без конфигурирования. Такие шаблоны заготовлены под все технологии, которые мы используем.
Разработка с помощью платформы
Наша платформа построена на базе оркестратора kubernetes. Это отличный инструмент, который позволяет автоматизировать работу с огромной инфраструктурой, легко масштабировать любые сервисы и гибко настраивать их под требования. Однако для разработчика набор сущностей kubernetes, внутренние особенности не представляют из себя простой и удобный интерфейс. Написание манифестов обычно ведет к потере времени (как на изучение, так и на написание).
Мы стараемся для всех инструментов, с которыми сложно работать напрямую, предоставлять высокоуровневые конфигурационные файлы или и вовсе скрывать настройки. Например, для Kubernetes мы создаем готовую конфигурацию, чтобы настраивать только то, что относится к конкретному сервису.
К этому подходу мы пришли около пяти лет назад и успели реализовать свою имплементацию. Но среди Open Source решений есть инструмент, который очень похож на наш по концепции — Open Application Model.

OAM – это спецификация, у неё есть популярная реализация kubevela.
Open Application Model даёт разработчикам единый манифест Application и указывает, как описать сервис с помощью компонентов и трейтов. Компонентами могут быть, например, API, worker, переменные окружения. А трейты — это особенности того, как именно нужно выкатить сервис.
Такие манифесты помогают убрать сложность при конфигурировании и администрировании сервисов. Платформенная команда определяет какие высокоуровневые возможности необходимы разработчикам и предоставляют их в лаконичном виде. В стандартных кейсах разработчику необходимо прописать лишь пару специфичных его сервису настроек. Это также положительно влияет на количество инцидентов, которые случаются по причине мисконфигурации. Этот подход позволяет такого избегать.
Так манифест Application может выглядеть в имплементации KubeVela:
apiVersion: core.oam.dev/v1beta1
kind: Application
metadata:
name: first-app
spec:
components:
- name: helloworld
type: webservice
properties:
image: oamdev/helloworld-python:v1
env:
- name: "TARGET"
value: "KubeVela"
port: 8080
traits:
- type: ingress
properties:
domain: localhost
http:
/: 8080В нашей платформе мы используем манифест app.toml, из которого генерируем все остальные манифесты. В нём есть только движимые части, специфичные сервису: переменные окружения, параметры масштабирования и подобные.
app.toml
name = "wordcounter"
description = "Counts the number of words in text"
replicas = 3
[env_vars]
WORKERS_COUNT = "3"
ANOTHER_ONE = "1"
[envs.staging]
replicas = 2
[envs.local]
replicas = 1При локальной разработке развернуть сервис можно одной командной. Для этого используем собственную утилиту avito:

Любой сервис одной командой разворачивается в локальном окружении в настроенном kubernetes кластере. Такой подход обеспечивает стопроцентную повторяемость. Однако с точки зрения производительности это не всегда хороший вариант, так как сильно влияет на нагрузку локальной машины.
Поэтому самый популярный способ — запуск непосредственно на хостовой системе. Утилита с помощью app.toml автоматически создаёт из набора переменных окружения специальный файл .env.paas. Затем внутренняя библиотека экспортирует переменные окружения из этого файла и запускает локально — ровно в той же конфигурации, как будто мы запускаем его в контейнере в предподготовленном окружении. Далее запуск не требует никакой настройки. Можно запустить сервис, его тесты из любой IDE или без неё.
Ещё один наш подход к разработке — Zero Configuration Init. Например, у нас есть база данных redis. Чтобы её инициализировать, нужно знать параметры подключения. Вместо них мы со стороны платформы добавляем специальные переменные окружения, которые известны платформенной библиотеке. Библиотека считывает их и настраивает клиент, который можно инициализировать без передачи параметров.

Мы активно используем микросервисный подход — сейчас в Авито больше 2000 сервисов. Со стороны клиента и сервера всегда есть контракты, на основе которых генерируется код:

Разработчику не нужно вручную реализовывать популярные reliability-паттерны, обработку ошибок, механики retries. Это экономит время на таких рутинных задачах.
При таком количестве сервисов важно поддерживать актуальность технологического стека. Некоторые сервисы не требуют доработок по функциональности, но стек в них постепенно устаревает.
Чтобы все инструменты были актуальными, мы используем систему рассылки обновлений библиотек. Для этого есть готовое решение Dependabot, а в Авито — своя реализация Depender. Любые минорные обновления рассылаются автоматом, разработчику нужно только смержить подготовленный Pull Request.
Безопасность платформы
Ключевые механики безопасности, которые напрямую влияют на разработку продукта Авито:
Менеджмент секретов. Многие сервисы хранят секреты для доступа к базам данных или внешним API. Поэтому мы даём разработчику высокоуровневый интерфейс, куда он вписывает все нужные секреты. Всё что нужно – в GUI задать в формате key value какие переменные окружения будут необходимы в production окружении.

Интерфейс записывает секреты в хранилище Vault. При старте сервиса специальная утилита проставляет переменные окружения с нужными данными. Разработчику не нужно задумываться, как именно имплементировать интеграцию с хранилищем, vault полностью скрыт за интерфейсом.
Межсервисное взаимодействие происходит на уровне инфраструктуры с помощью service mesh технологии — в самих сервисах нет необходимости думать о шифровании, механиках авторизации. mTLS и авторизация происходят независимо от кодовой базы сервиса, на уровне proxy sidecar, которые занимаются шифрованием и расшифровкой трафика, проверкой авторизационных политик.
IDP-авторизация. На платформе используются стандартные практики контроля доступа, основанные на ролях. Мы используем инструмент Open Policy Agent. С его помощью можно гибко описать правила доступа для разных уровней пользователей. Все правила инкапсулируются внутри и доступны в виде удобных заготовленных ролей.
Тестирование на платформе
PaaS поддерживает инструменты тестирования — от простейших до сложных. Начиная с линтеров и юнит-тестирования, и до канареечных релизов в продакшн и chaos-тестирования.

На иллюстрации представлен основной набор проверок, тестов и защитных механизмов, которые проходит каждый сервис.
На фазе Linters мы используем инструмент Avito actions, похожий по подходу на Github actions. Во время разработки любой сервис проходит несколько фаз, в том числе форматирование кода, проверку code style, линтинг, кодогенерацию. Конфигурация выглядит примерно так:
[[actions]]
on = ["fmt"]
runner = "docker@avito/actions-golang:1.21"
run = "fmt"
# https://github.com/mvdan/gofumpt
[[actions]]
mandatory = true
on = ["fmt"]
runner = "docker@avito/actions-golang:1.21"
run = "fmt-gofumpt v0.4"
[[actions]]
on = ["fmt"]
runner = "docker@avito/actions-brief-fmt:1.0.0"
run = "brief-fmt"
[[actions]]
on = ["lint", "ci-lint"]
runner = "docker@avito/actions-golang:1.21"
run = "lint v1.50"Под капотом также зашит набор базовых проверок, которые мы обязательно проводим для всех сервисов в Авито. Этот подход выполнен в модульном виде и помимо платформенных проверок многие команды пишут свои решения и некоторые затем масштабируются на всю компанию. Это позволяет в том числе учесть специфику конкретных команд.
Для End-2-End-тестирования мы используем интересную механику: выкатываем только сервис, который нужно протестировать, а не весь контур. Дальше с помощью механизмов Service Mesh перенаправляем трафик на тестовую версию сервиса.

Он позволяет экономить ресурсы и даёт значительно более стабильное окружение.
Доставка сервисов
Для доставки мы используем Kubernetes, который развёрнут в нескольких дата-центрах. У нас есть пайплайн с окружениями и возможностью выкатывать кастомные релизы на ограниченное время.

У всех сервисов есть унифицированные готовые сборки, им не нужно придумывать что-то своё. Выкатывать сервис можно одной кнопкой (One Button Deploy). При этом есть возможность использовать любую стратегию: canary, blue/green, shadow (мы называем его custom release в production). Есть поддержка Continuous deployment. Разработчик выбирает, на какие ключевые метрики нужно смотреть автоматике. При релизе система сама постепенно промотирует нагрузку на большее количество пользователей, постоянно наблюдая за здоровьем так называемых «проберов». Если что-то идет не так, система релизов самостоятельно останавливает релиз и откатывает на предыдущую версию.
Также на платформе реализован Problem Detector, который анализирует проблемы в Kubernetes при релизе. Мы встроили в платформу много эвристик, которые детектируют типичные проблемы — например, падения контейнеров или деградация Worker Node. Это позволяет быстрее находить проблемы при релизах.
Эксплуатация сервиса
Каждый сервис Авито принадлежит конкретной команде разработки. Данные о владельцах сервисов хранятся в едином реестре. Чтобы создать такой реестр, можно использовать фреймворк Backstage. Мы же в Авито используем собственное решение.
Там же храним множество информации о сервисе: тип, описание, процент тестового покрытия, последние релизы, потребление ресурсов, связи с другими сервисами.
Ещё советую обратить внимание на подход «документация как код». Мы складываем всю техническую документацию в разметке Markdown в репозитории. Специальный механизм определяет, что произошло изменение документации и публикует ее в единую систему, по которой можно пользоваться глобальным поиском и в красивом виде просматривать документацию.
Документация выводится в удобном виде с помощью MkDocs, индексируется целиком и для каждого репозитория отдельно. Благодаря этому подходу можно выполнять code review документации и быстро находить недокументированные фичи прямо в процессе просмотра Pull Request. Нет разрыва между реализацией и документацией.
Для Capacity Management мы используем стандартные механики:
вертикальный автоскейлинг,
квотирование по организационной структуре,
автоматический поиск устаревших сервисов.
Платформа поддерживает автоматический сбор метрик, логов и трекинг исключений (sentry) в специализированные системы.

Все эти системы имеют также собственные GUI, специфичные метрики и огромное множество представлений данных. Несмотря на такую развесистую систему, в которой можно найти любую интересующую метрику или трейс, это имеет и обратную сторону: разобраться, куда смотреть во время инцидента, бывает непросто. Поэтому мы сделали инструмент под названием observer, который «за ручку» проводит от высокоуровневых метрик до конкретных трейсов и красных узлов, из-за которых идет деградация. Сейчас мы активно внедряем этот подход и инструмент.
Нефункциональные требования мы описываем декларативно, указываем нагрузку и latency по системе. Из них автоматически вычисляем SLI для каждого сервиса и затем отображаем статистику и значение SLI в дашборде. Например, показываем уровень доступности сервиса.
Также ретроспективно показываем предупреждение о том, что SLI выходит за рамки SLO. Это позволяет организовать предсказуемый процесс по непрерывной работе со стабильностью системы.
Нефункциональные требования прописываются в файле nfr.toml, который формируется по единому шаблону для всех сервисов.
nfr.toml
version = "2.0"
[service]
slo = 99.9
[default.all]
error_codes = ["5**"]
rpm = 1
latency = "100ms"
[[rest]]
path = "/subscribe"
skip = "true"
[[rest]]
path = "/read"
skip = true
[[rpc]]
method = "/createQueue"
rpm = 100
error_codes = ["5**"]
latency = "200ms"Self-healing сервисы в рамках платформы
Для самовосстановления сервисов мы используем общепринятые подходы:
descheduling для балансировки инфраструктуры по нагрузке;
автоматическое пересоздание tcp сессий на уровне инфраструктуры (service mesh driven);
outlier detection на уровне прокси в инфраструктуре;
автоматический поиск unhealthy node.
Для работы Service Discovery мы автоматически передаем в сервисы переменные окружения. Под капотом с помощью service mesh происходит выбор локальных IP для похода в нужный сервис. Если один из сервисов деградирует, то трафик к нему автоматически перенаправляется в другую зону.

Для балансировки сервисов и API Gateway мы используем готовые решения со всеми необходимыми компонентами. Для разработчиков стандартные возможности доступны в платформе без дополнительных действий.

Какой в итоге получилась платформа
В целом, у платформы есть множество других возможностей для разработчиков. Большинство из них не требует специальных знаний, понимания инфраструктуры, доступны буквально в одно-два действия. При этом мы постарались сохранить баланс между удобством и гибкостью. Поэтому у команд есть возможность донастраивать платформу под собственные нужды, если стандартных функций недостаточно для конкретного сервиса.
Техническая платформа — это такой же продукт, как и любой другой. Важно использовать полноценные продуктовые подходы, которые позволят создать тот самый опыт, который необходим разработчикам для быстрой и удобной работы.
В конечном счете это приносит выгоду. Компания получает ускорение и прокачивание TTM, лучшее качество и уверенность в будущем. Продуктовые разработчики могут сфокусироваться на аспектах построения архитектуры конечных систем, реализации бизнес-логики, а не тратить время на неверно собранные образы, не запускающиеся сервисы и подобные проблемы.
Наш опыт мы постарались объединить в генерализованном решении под названием Plato, которое позволяет получить большинство возможностей из коробки, основываясь на проверенных open-source решениях.
Предыдущая статья: Как мы выдержали x20 рост нагрузки на сервис Авито Автозагрузка
