
Одним из самых важных факторов, влияющих на скорость разработки и успех запуска проекта, является правильная декомпозиция идеи продакт-менеджера в задачи для непосредственно программирования. Как правильно это делать? Взять сценарий работы новой фичи от продакта и сразу начать кодить? Сначала написать приёмочные тесты, а потом – код, который будет обеспечивать их прохождение? А, может, переложить всё на плечи разработчиков – и пусть они в ходе скрам-покера сами решают?
Давайте подумаем и обозначим проблемы, которые могут возникнуть в процессе разделения задач, и способы их решения. В этом посте будут рассмотрены основные принципы декомпозиции задач при работе в команде. Меня зовут Илья Агеев, я – глава QA в Badoo. Сегодня расскажу, как workflow влияет на декомпозицию, насколько отличаются тестирование и выкладка задач, которые появляются в результате декомпозиции, и каких правил стоит придерживаться, чтобы процесс разработки проходил гладко для всех участников.
Почему это важно?
Необходимо помнить о том, что процесс разработки – это не только непосредственно сеанс написания кода. Когда мы говорим о разработке, я призываю смотреть на весь процесс целиком, начиная от постановки задачи и заканчивая стабильной работой фичи у наших пользователей. Если не брать в расчёт все этапы, которые предшествуют кодированию и следуют за ним, то очень легко можно попасть в ситуацию, когда все что-то делают, выполняют свои KPI, получают бонусы, а результат получается плачевный. Бизнес загибается, конкуренты «душат», но при этом все – молодцы.
Почему так происходит? Всё просто: человеческая психология заставляет людей смотреть на ситуации с точки зрения собственного комфорта. Разработчику не всегда хочется думать о том, что будет с кодом после его написания. Решил задачу – и хорошо. Его крайне редко это интересует (именно поэтому мы, айтишники, и работаем в этой отрасли – наша мотивация в основном держится на интересности задач), ведь в отношениях с людьми столько неопределённости. Гораздо более комфортно многие разработчики чувствуют себя, сидя за компьютером и сосредоточившись на решении своей собственной интересной задачи – блокчейнах с нейросетями – им совсем не хочется отвлекаться и думать о каких-то продакт-менеджерах, дедлайнах, пользователях, которые потом будут использовать их гениальное произведение (а то ещё и критиковать начнут!).
Это не плохо и не хорошо – мы ценим разработчиков именно за вдумчивое и грамотное решение технических задач. Но узкий взгляд на проблемы часто останавливает развитие. И речь о развитии не только конкретных людей, но и компании в целом. Ведь рост компании и совершенствование корпоративной культуры возможны только с ростом каждого сотрудника. Поэтому нам важно иногда вылезать из «кокона» и заставлять себя смотреть на проблемы шире, чтобы этот рост стимулировать.
И, разумеется, если такой важный этап, как декомпозиция, поручить человеку, который смотрит на всё исключительно с точки зрения собственного удобства, есть реальный риск огрести кучу проблем на последующих этапах: при слиянии результатов его работы с результатами других, при code review, при тестировании, выкладке в продакшн, и т. д.
Таким образом, определяя для себя, как правильно разбить ту или иную задачу, прикидывая, с чего следует начать и куда в итоге прийти, важно учитывать как можно больше факторов, а не смотреть на проблему только «со своей колокольни». Иногда для того чтобы всё работало быстрее и эффективнее на следующих этапах, приходится делать что-то сложнее и медленнее на том этапе, за который отвечаете вы.
Хороший пример – написание юнит-тестов. Зачем мне тратить своё драгоценное время на написание тестов, если у нас есть тестировщики, которые потом и так всё протестируют? А затем, что юнит-тесты необходимы не только для облегчения процесса кодинга – они нужны также и на последующих этапах. И нужны как воздух: с ними процесс интеграции и проверки регрессии ускоряется в десятки, сотни раз, на них базируется пирамида автоматизации. И это даже если не брать в расчёт ускорение вашей собственной работы: ведь «потрогав» код в каком-то месте, вам самому нужно убедиться в том, что вы ненароком что-нибудь не сломали. И один из самых быстрых способов это сделать – прогнать юнит-тесты.
Workflow
Многие команды, чтобы как-то формализовать отношения между участниками процесса, договариваются о правилах работы в коллективе: согласовывают стандарты кодирования, общий workflow в системе контроля версий, устанавливают расписание релизов и т. д.
Стоит ли говорить, что если изначально договориться о процессе, не принимая во внимание весь жизненный цикл фичи, то можно получить замедление и «грабли» в будущем? Особенно если учесть рост проекта и компании. О преждевременной оптимизации не забываем, но если есть процесс, который хорошо работает на разных масштабах, то почему бы его не использовать изначально?
Говоря о workflow разработки, многие, кто использует Git, сразу вспоминают (всуе) о некоем «стандартном git-flow», считая его идеальным, правильным, и часто внедряют его у себя. Даже на конференциях, где я выступал, рассказывая про workflow в Badoo, меня несколько раз спрашивали: «Зачем вы изобрели своё, почему не используете стандартный git-flow?» Давайте разбираться.
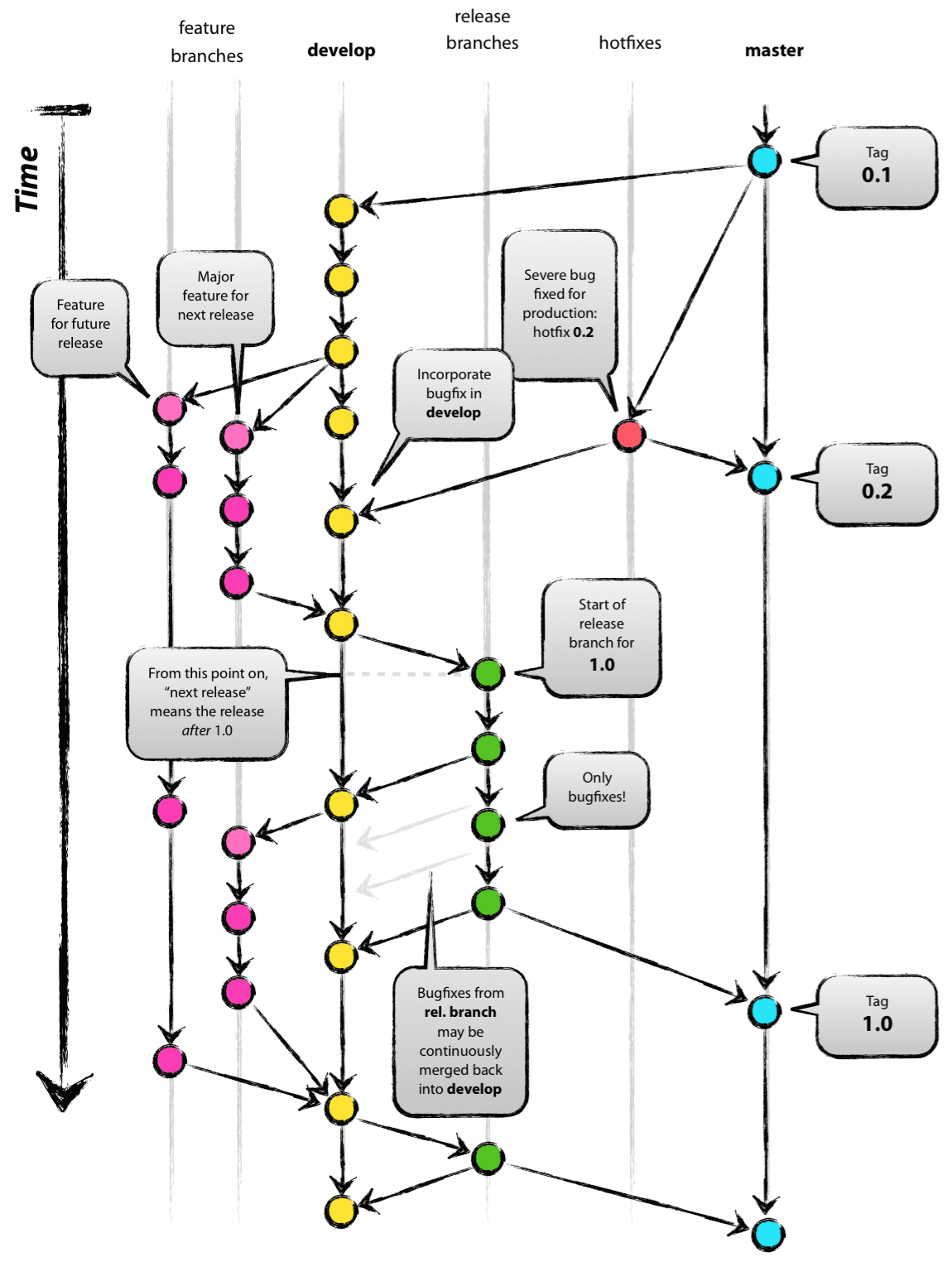
Во-первых, обычно, говоря про этот флоу, имеют в виду вот эту картинку. Я взял её из статьи Vincent Driessen “A successful Git branching model”, в которой описывается схема, довольно успешно работавшая на нескольких его проектах (было это в далёком 2010 году).
Сегодня некоторые крупные игроки на рынке хостинга кода вообще предлагают свой флоу, критикуя «стандартный git-flow» и описывая его недостатки; дают свои схемы, рекомендации, приёмы.
Если же поискать на git-scm.com (хорошо бы вообще погуглить), то с удивлением можно обнаружить, что никакого рекомендованного (и уж тем более «стандартного») workflow не существует. Всё потому, что Git – это, по сути, фреймворк для систем хранения версий кода, и то, как вы организуете это самое хранение и совместную работу, зависит только от вас самих. Всегда нужно помнить о том, что, если какой-то флоу «взлетел» на каких-то проектах, это вовсе не означает, что вам он тоже полностью подойдёт.
Во-вторых, даже у нас в компании у разных команд разный флоу. Флоу разработки серверного кода на PHP, демонов на С/ С++ и Go, флоу мобильных команд – они разные. И пришли мы к этому не сразу: пробовали разные варианты, прежде чем остановиться на чём-то конкретном. К слову, отличается в этих командах не только workflow, но ещё и методологии тестирования, постановки задач, релизы и сам принцип доставки: то, что поставляется на ваши личные серверы и на компьютеры (смартфоны) конечных пользователей, не может разрабатываться одинаково по определению.
В-третьих, даже принятый workflow является скорее рекомендацией, чем непререкаемым правилом. Задачи у бизнеса бывают разные, и хорошо, если вам удалось выбрать процесс, покрывающий 95% случаев. Если же ваша текущая задача не вписывается в выбранный флоу, имеет смысл посмотреть на ситуацию с прагматической точки зрения: если правила мешают вам сделать эффективно, к чёрту такие правила! Но обязательно посоветуйтесь с вашим менеджером перед принятием окончательного решения – иначе может начаться бардак. Вы можете банально не учесть какие-то важные моменты, которые известны вашему руководителю. А, возможно, всё пойдёт как по маслу – и вы сумеете изменить существующие правила так, что это приведёт к прогрессу и станет залогом роста для всех.
Если всё так сложно, да ещё и флоу – это не догма, а всего лишь рекомендация, то почему бы не использовать одну ветку для всего: Master для Git или Trunk для SVN? Зачем усложнять?
Тем, кто смотрит на проблему однобоко, этот подход с одной веткой может показаться очень удобным. Зачем мучиться с какими-то ветками, париться со стабилизацией кода в них, если можно написать код, закоммитить (запушить) в общее хранилище – и радоваться жизни? И правда, если в команде работает не очень много человек, это может быть удобно, поскольку избавляет от необходимости слияния веток и организации веток для релиза. Однако данный подход имеет один очень существенный недостаток: код в общем хранилище может быть нестабильным. Вася, работающий над задачей №1, может легко сломать код других задач в общем хранилище, залив свои изменения; и пока он их не исправит/ не откатит, код выкладывать нельзя, даже если все остальные задачи готовы и работают.
Конечно, можно использовать теги в системе контроля версий и код-фриз, но очевидно, что подход с тегами мало отличается от подхода с ветками, как минимум потому что усложняет изначально простую схему. А уж код-фриз тем более не добавляет скорости работе, вынуждая всех участников останавливать разработку до стабилизации и выкладки релиза.
Так что первое правило хорошей декомпозиции задач звучит так: задачи нужно разбивать так, чтобы они попадали в общее хранилище в виде логически завершённых кусочков, которые работают сами по себе и не ломают логику вокруг себя.
Feature branches
При всём многообразии вариантов workflow у нас в компании у них есть общая черта – они все основаны на отдельных ветках для фич. Такая модель позволяет нам работать независимо на разных этапах, разрабатывать разные фичи, не мешая друг другу. А ещё мы можем тестировать их и сливать в общее хранилище, только убедившись, что они работают и ничего не ломают.
Но и такой подход имеет свои недостатки, основанные на самой природе фичебранчей. В конце концов, после изоляции результат вашей работы нужно будет слить в общее для всех место. На этом этапе можно огрести немало проблем, начиная от мерж-конфликтов и заканчивая очень длительным тестированием/ багфиксингом. Ведь отделяясь в свою ветку кода, вы изолируете не только общее хранилище от ваших изменений, но и ваш код – от изменений других разработчиков. В результате, когда приходит время слить свою задачу в общий код, даже если она проверена и работает, начинаются «танцы с бубном», потому что Вася и Петя в своих ветках затронули одни и те же строки кода в одних и тех же файлах – конфликт.
Современные системы хранения версий кода имеют кучу удобных инструментов, стратегий слияния и прочее. Но избежать конфликтов всё равно не удастся. И чем больше изменений, чем они витиеватее, тем сложнее и дольше эти конфликты разрешать.
Ещё опаснее конфликты, связанные с логикой кода, когда SCM сливает код без проблем (ведь по строкам в файлах конфликтов нет), но из-за изоляции разработки какие-то общие методы и функции в коде изменили своё поведение или вообще удалены из кода. В компилируемых языках проблема, как может показаться, стоит менее остро – компилятор валидирует код. Но ситуации, когда сигнатуры методов не поменялись, а логика изменилась, никто не отменял. Такие проблемы сложно обнаруживать, и они ещё более отдаляют счастливый релиз и заставляют перетестировать код много раз после каждого слияния. А когда разработчиков много, кода много, файлов много и конфликтов много, всё превращается в сущий ад, ибо пока мы исправляли код и перепроверяли его, основная версия кода уже ушла далеко вперёд, и надо всё повторять заново. Вы всё ещё не верите в юнит-тесты? Хе-хе-хе!
Чтобы этого избежать, многие стараются как можно чаще сливать результаты общей работы в свою ветку. Но даже соблюдение этого правила, если фичебранч будет достаточно большим, не поможет избежать проблем, как бы мы ни старались. Потому что чужие изменения вы к себе в код получаете, но ваши изменения при этом никто не видит. Соответственно, необходимо не только почаще заливать чужой код в свою ветку, но и свой код в общее хранилище – тоже.
Отсюда – второе правило хорошей декомпозиции: фичебранчи должны содержать как можно меньше изменений, чтобы как можно быстрее попадать в общий код.
Параллельная работа
Хорошо, но как же тогда работать в отдельных ветках, если несколько программистов трудятся над одной и той же задачей, разбитой на части? Или если им нужны изменения в общих для разных задач частях кода? И Петя, и Вася используют общий метод, который в рамках задачи Пети должен работать по одному сценарию, а в задаче Васи – по другому. Как им быть?
Тут многое зависит от вашего цикла релизов, потому что моментом завершения задачи мы считаем момент попадания её на продакшн. Ведь только этот момент гарантирует нам, что код стабилен и работает. Если не пришлось откатывать изменения с продакшна, конечно.
Если цикл релизов быстрый (несколько раз в день вы выкладываетесь на свои серверы), то вполне можно сделать фичи зависимыми друг от друга по стадиям готовности. В примере с Петей и Васей выше создаём не две задачи, а три. Соответственно, первая звучит как «меняем общий метод так, чтобы он работал в двух вариантах» (или заводим новый метод для Пети), а две другие задачи – это задачи Васи и Пети, которые могут начать работу после завершения первой задачи, не пересекаясь и не мешая друг другу.
Если же цикл релизов не позволяет вам выкладываться часто, то пример, описанный выше, будет непомерно дорогим удовольствием, ведь тогда Васе и Пете придётся ждать дни и недели (а в некоторых циклах разработки и года), пока они смогут начать работать над своими задачами.
В этом случае можно использовать промежуточную ветку, общую для нескольких разработчиков, но ещё недостаточно стабильную, чтобы быть выложенной на продакшн (Master или Trunk). В нашем флоу для мобильных приложений такая ветка называется Dev, на схеме Vincent Driessen она называется develop.
Важно иметь в виду, что любое изменение в коде, даже слияние веток, вливание общих веток в стабильный Master и т. д., обязательно должно быть протестировано (помните про конфликты по коду и логике, да?). Поэтому если вы пришли к выводу, что вам необходима общая ветка кода, то нужно быть готовым к ещё одному этапу тестирования – после момента слияния необходимо тестировать, как фича интегрируется с другим кодом, даже если она уже протестирована в отдельной ветке.
Тут вы можете заметить, что можно ведь тестировать только один раз – после слияния. Зачем тестировать до него, в отдельной ветке? Верно, можно. Но, если задача в ветке не работает или ломает логику, этот неработоспособный код попадёт в общее хранилище и мало того, что помешает коллегам работать над своими задачами, ломая какие-то участки продукта, так ещё и может подложить бомбу, если на неправильных изменениях кто-то решит базировать новую логику. А когда таких задач десятки, очень тяжело искать источник проблемы и чинить баги.
Также важно понимать, что, даже если мы используем промежуточную разработческую ветку кода, которая может быть не самой стабильной, задачи или их кусочки в ней должны быть более-менее завершёнными. Ведь нам необходимо в какой-то момент зарелизиться. А если в этой ветке код фич будет ломать друг друга, то выложиться мы не сможем – наш продукт работать не будет. Соответственно, протестировав интеграцию фич, нужно как можно скорее исправить баги. Иначе мы получим ситуацию, похожую на ту, когда используется одна ветка для всех.
Следовательно, у нас появляется третье правило хорошей декомпозиции: задачи должны разделяться так, чтобы их можно было разрабатывать и релизить параллельно.
Feature flags
Но как же быть в ситуации, когда новое изменение бизнес-логики – большое? Только на программирование такой задачи может уйти несколько дней (недель, месяцев). Не будем же мы сливать в общее хранилище недоделанные куски фич?
А вот и будем! В этом нет ничего страшного. Подход, который может быть применён в этой ситуации, – feature flags. Он основан на внедрении в код «выключателей» (или «флагов»), которые включают/ выключают поведение определённой фичи. К слову, подход не зависит от вашей модели ветвления и может использоваться в любой из возможных.
Простым и понятным аналогом может быть, например, пункт в меню для новой страницы в приложении. Пока новая страница разрабатывается по кусочкам, пункт в меню не добавляется. Но как только мы всё закончили и собрали воедино, добавляем пункт меню. Так же и с фичефлагом: новую логику оборачиваем в условие включённости флага и меняем поведение кода в зависимости от него.
Последней задачей в процессе разработки новой большой фичи в этом случае будет задача «включить фичефлаг» (или «добавить пункт меню» в примере с новой страницей).
Единственное, что нужно иметь в виду, используя фичефлаги, – это увеличение времени тестирования фичи. Ведь продукт необходимо протестировать два раза: с включённым и выключенным фичефлагом. Сэкономить тут можно, но действовать следует крайне деликатно: например, тестировать только то состояние флага, которое выкладывается пользователю. Тогда в процессе разработки (и выкладки по частям) задачи её тестировать вообще не будут, а проведут тестирование только во время проверки последней задачи «включить фичефлаг». Но тут надо быть готовым к тому, что интеграция кусков фичи после включения флага может пройти с проблемами: могут обнаружиться баги, допущенные на ранних этапах, и в этом случае поиск источника проблемы и устранение ошибок могут дорого стоить.
Заключение
Итак, при декомпозиции задач важно помнить три простых правила:
- Задачи должны быть в виде логически завершённых кусочков кода.
- Эти кусочки кода должны быть маленькими и должны максимально быстро попадать в общий код.
- Эти кусочки должны разрабатываться параллельно и выкладываться независимо друг от друга.
Куда уж проще? Кстати, независимая выкладка, на мой взгляд, — самый важный критерий. Из него так или иначе проистекают остальные пункты.
Желаю удачи в разработке новых фич!
